Source: New Wisdom Element

Image source: Generated by Wujie AI
Fully self-developed third-generation base large model ChatGLM3, launched today!
This is another optimization of the ChatGLM base model by the Zhipu AI team since the launch of the second-generation model in June.
In addition, at the 2023 China National Computer Conference (CNCC) on October 27, Zhipu AI also open-sourced ChatGLM3-6B (32k), multimodal CogVLM-17B, and intelligent agent AgentLM.
After the release of the ChatGLM3 series models, Zhipu became the only company in China with a full model product line comparable to OpenAI.

The generative AI assistant Zhipu Qingyan has also become the first large model product in China with code interaction capability.
The model is fully self-developed, compatible with domestic chips, with stronger performance and a more open source ecosystem.
As the first company to enter the research of large models, Zhipu AI took the lead!
Moreover, Zhipu AI has completed a total of over 2.5 billion RMB in financing this year, with a luxurious list of investors including Meituan, Ant Group, Alibaba, Tencent, and more, all of which demonstrate the industry's strong confidence in Zhipu AI.
Aiming for the technical upgrade of GPT-4V
Currently, the multimodal visual model GPT-4V has demonstrated powerful image recognition capabilities.
At the same time, aiming for GPT-4V, Zhipu AI has also iteratively upgraded other capabilities of ChatGLM3. This includes the model CogVLM with multimodal understanding capabilities, which attempts to understand and has refreshed more than 10 international standard image-text evaluation datasets SOTA. Currently, CogVLM-17B has been open-sourced.
The code enhancement module Code Interpreter can generate and execute code according to user needs, automatically completing complex tasks such as data analysis and file processing.
The web search enhancement WebGLM, through the integration of search enhancement, can automatically search for relevant information on the Internet based on the question, and provide reference literature or article links when answering.
In addition, the semantic and logical capabilities of ChatGLM3 have also been greatly enhanced.
Direct open source of the 6B version
It is worth mentioning that upon the release of ChatGLM3, Zhipu AI directly open-sourced the 6B parameter model to the community.
Evaluation results show that compared to ChatGLM 2 and models of the same size in China, ChatGLM3-6B ranks first in 9 out of 44 public Chinese and English datasets tested.
It has increased by 36% in MMLU, 33% in CEval, 179% in GSM8K, and 126% in BBH compared to ChatGLM 2.
The open-sourced 32k version ChatGLM3-6B-32K performed the best in LongBench.
Moreover, the use of the latest "efficient dynamic reasoning + VRAM optimization technology" has made the current reasoning framework more efficient under the same hardware and model conditions.
Compared to the best open source implementation currently available, the inference speed has increased by 2-3 times, the inference cost has been reduced by half, and the cost is as low as 0.5 cents per thousand tokens, compared to the latest version of vLLM released by the University of California, Berkeley, and Hugging Face TGI.
Self-developed AgentTuning, activation of agent capabilities
What's even more surprising is that ChatGLM3 also brings a brand new Agent intelligent agent capability.
Zhipu AI hopes that large models can better communicate with external tools through APIs, and even achieve interaction with large models through intelligent agents.
By integrating the self-developed AgentTuning technology, the model's intelligent agent capabilities can be activated, especially in intelligent planning and execution, with a 1000% improvement compared to ChatGLM 2.
On the latest AgentBench, ChatGLM3-turbo has approached GPT-3.5.
At the same time, the intelligent agent AgentLM has also been open-sourced to the community. The Zhipu AI team hopes that open source models can achieve or even surpass the agent capabilities of closed source models.
This means that the agent intelligent agent will enable native support for "tool invocation, code execution, games, database operations, knowledge graph search and reasoning, and operating systems" in complex scenarios for domestic large models.
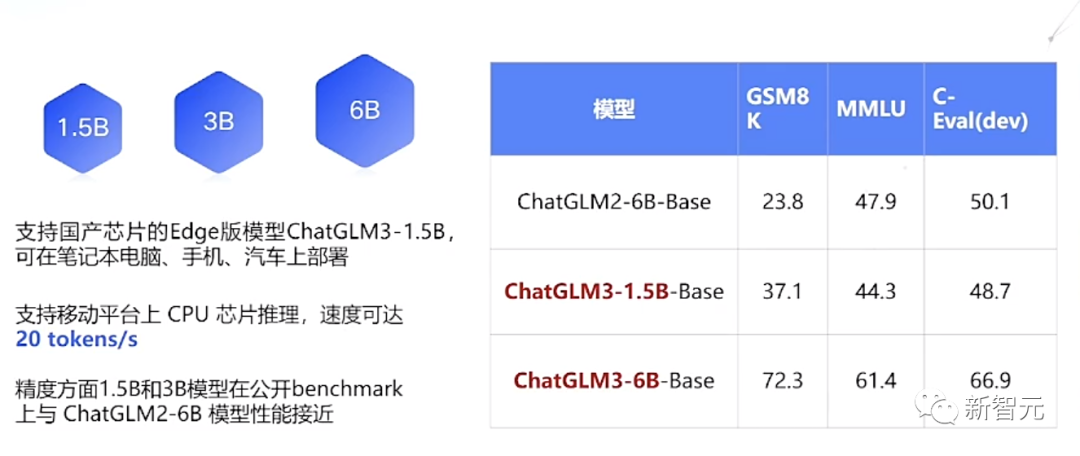
Simultaneous release of 1.5B/3B, runnable on mobile phones
Want to run ChatGLM on your phone? You can!
This time, ChatGLM3 has specifically released end-test models that can be deployed on mobile phones, with two parameters: 1.5B and 3B.
It can support a variety of mobile phones and in-vehicle platforms including Vivo, Xiaomi, Samsung, and even support inference on CPU chips on mobile platforms, with a speed of up to 20 tokens/s.
In terms of accuracy, the 1.5B and 3B models perform close to the ChatGLM2-6B model in public benchmark evaluations. Go ahead and give it a try!
New generation "Zhipu Qingyan" fully launched
Just as ChatGPT has a powerful GPT-4 model behind it, the generative AI assistant "Zhipu Qingyan" from the Zhipu AI team has also been blessed by ChatGLM3.
After the team's live demonstration, the function was directly launched, with a focus on sincerity!
Test link: https://chatglm.cn/main/detail
Code Interpreter
As one of the most popular plugins of ChatGPT, Advanced Data Analysis (formerly Code Interpreter) can analyze problems with a more mathematical mindset based on natural language input, and generate appropriate code at the same time.
Now, with the new upgrade of ChatGLM3, "Zhipu Qingyan" has become the first large model product in China with Advanced Data Analysis capabilities, supporting scenarios such as image processing, mathematical calculations, and data analysis.
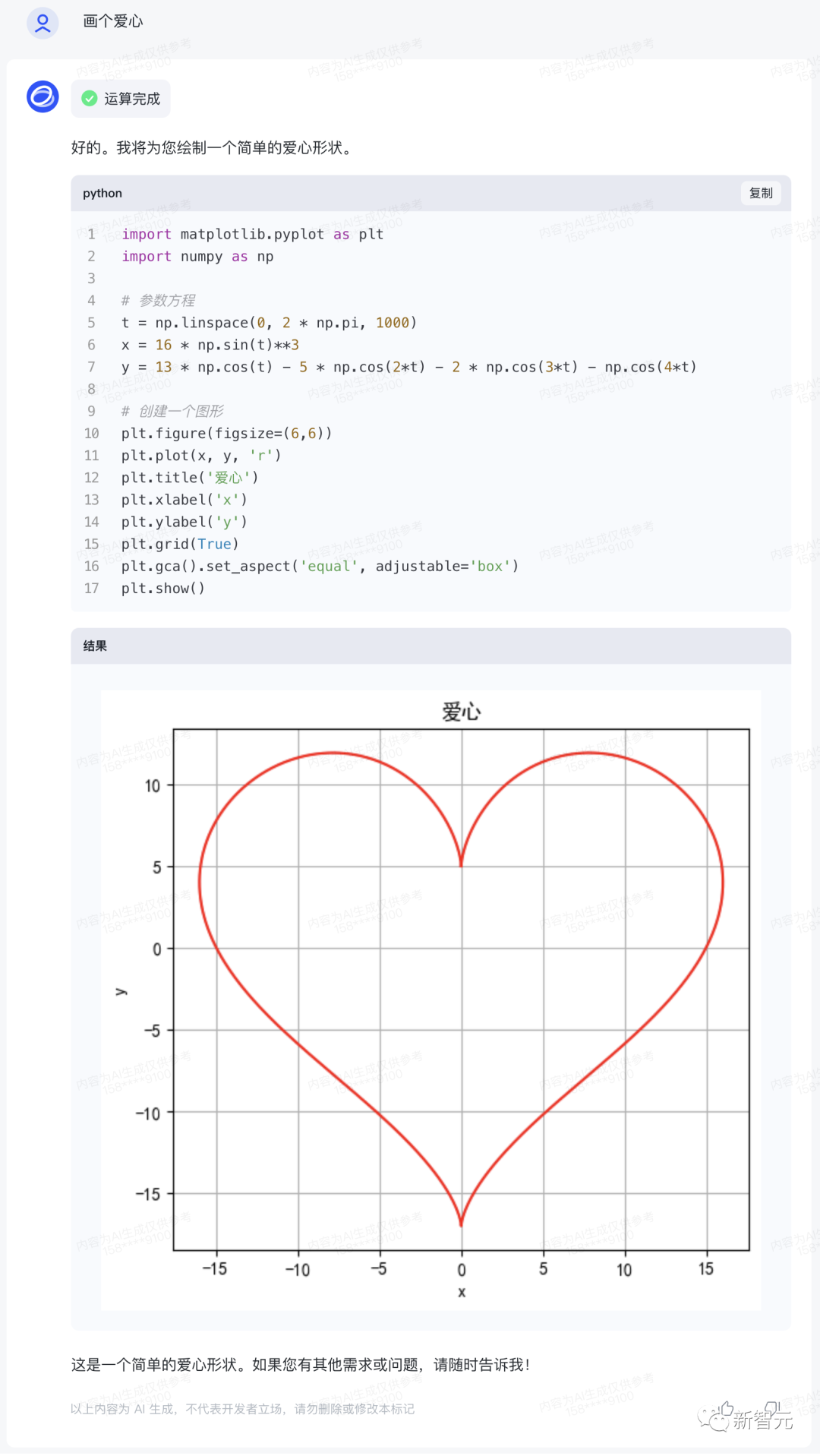
The romance of science and engineering, perhaps only "Zhipu Qingyan" can understand.
Although CEO Zhang Peng's live performance of drawing a "heart" failed, with a prompt change, the result was instant.
Similarly, the upgraded ChatGLM3 is also very proficient in data analysis.
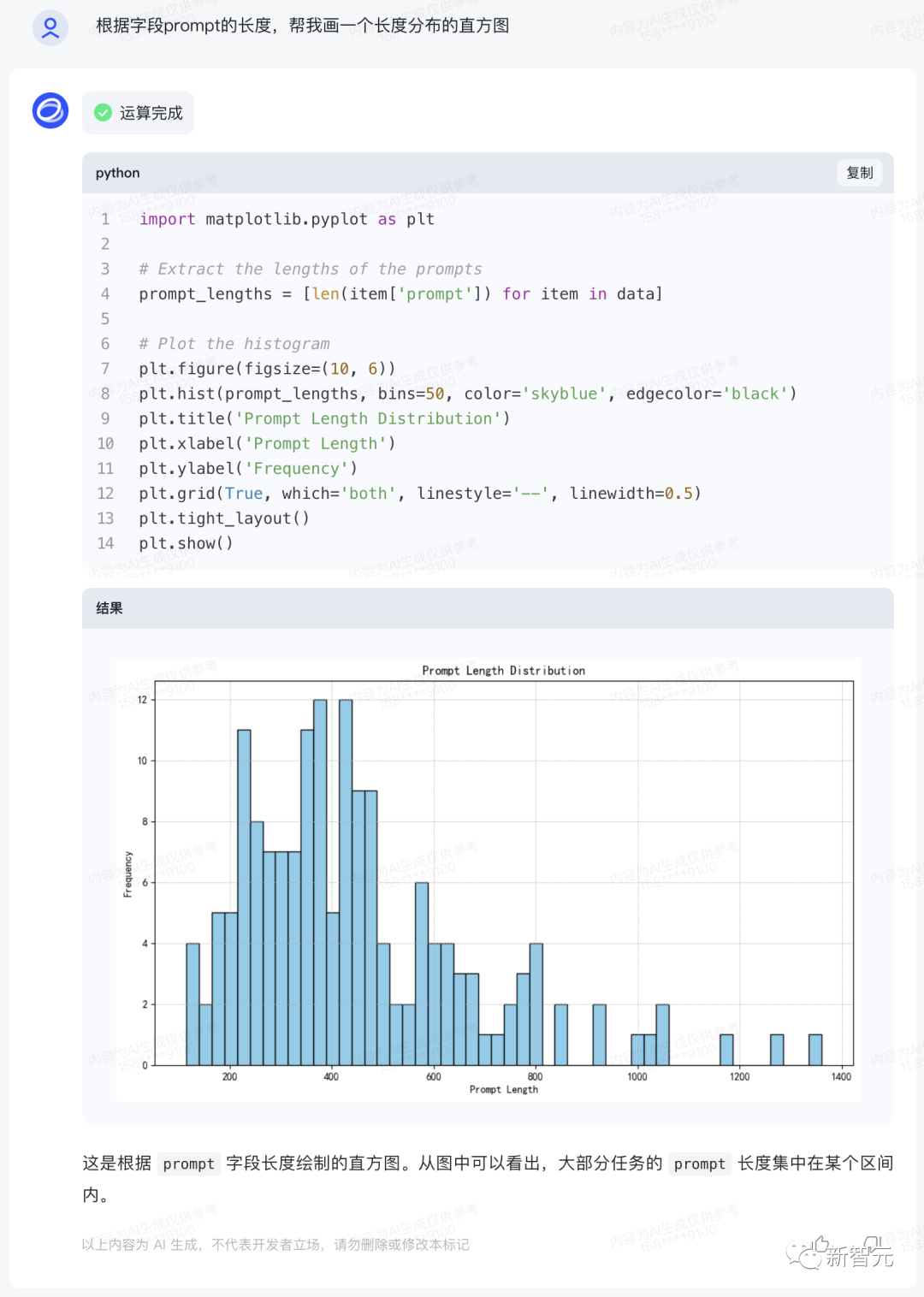
After a series of analyses, a histogram of length distribution can be drawn based on the length of the prompt field.
Search enhancement
With the addition of the WebGLM large model capability, "Zhipu Qingyan" now also has enhanced search capabilities - it can summarize and answer questions based on the latest online information, and provide reference links.
For example, recently the iPhone 15 experienced a price drop, how much was the specific fluctuation?
The answer provided by "Zhipu Qingyan" is quite effective!
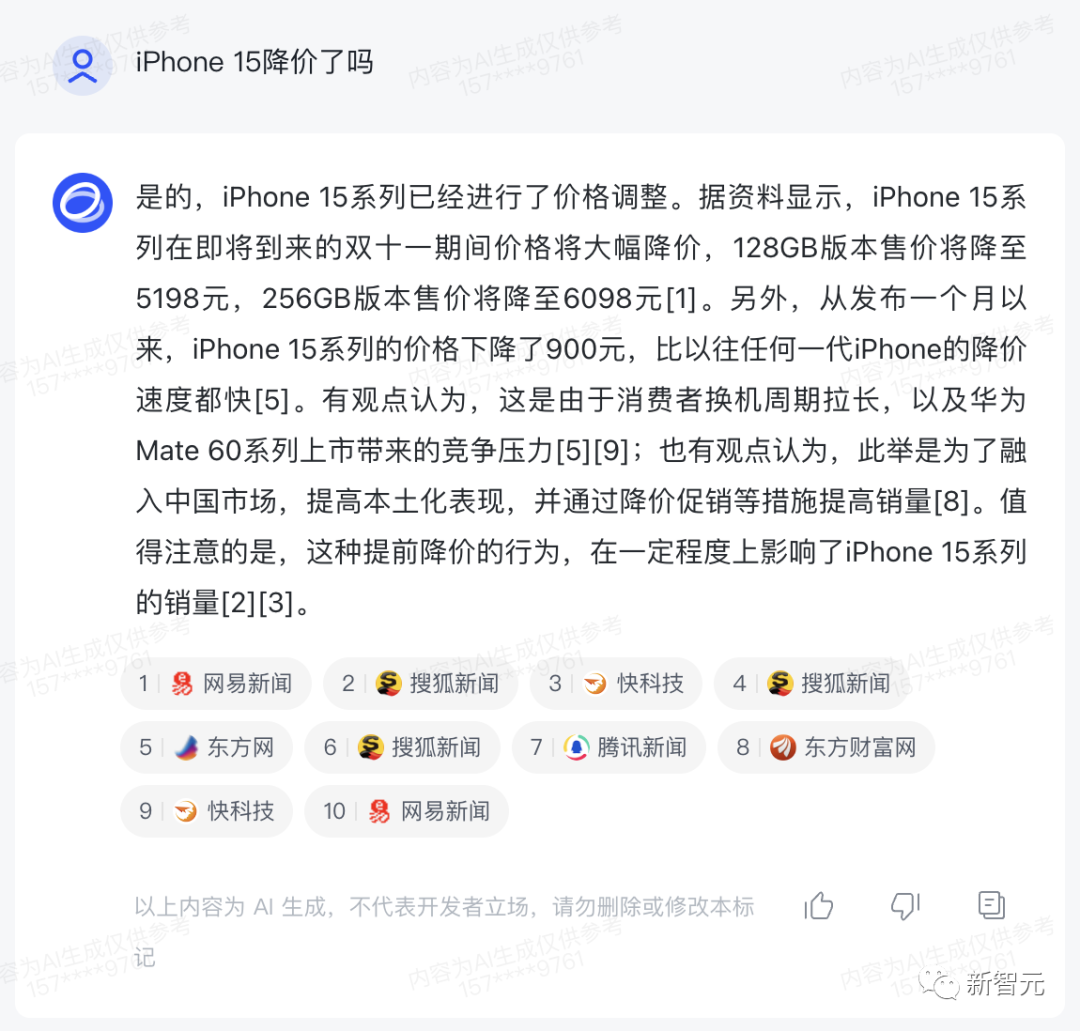
Image and Text Understanding
The CogVLM model has improved the Chinese image and text understanding capabilities of "Zhipu Qingyan," achieving image understanding capabilities close to GPT-4V.
It can answer various types of visual questions, and can perform complex object detection and labeling, as well as automatic data annotation.
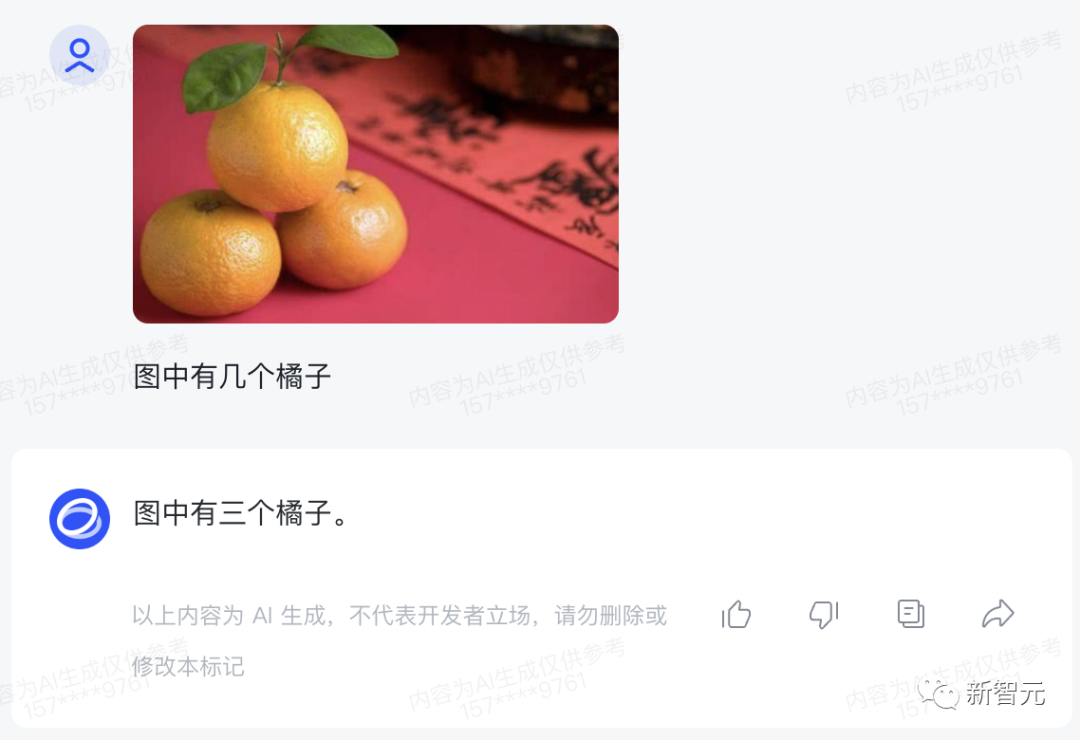
For example, let CogVLM identify how many people are in the image.


Adding some difficulty, even when given an image of three stacked oranges, it can accurately identify the quantity.

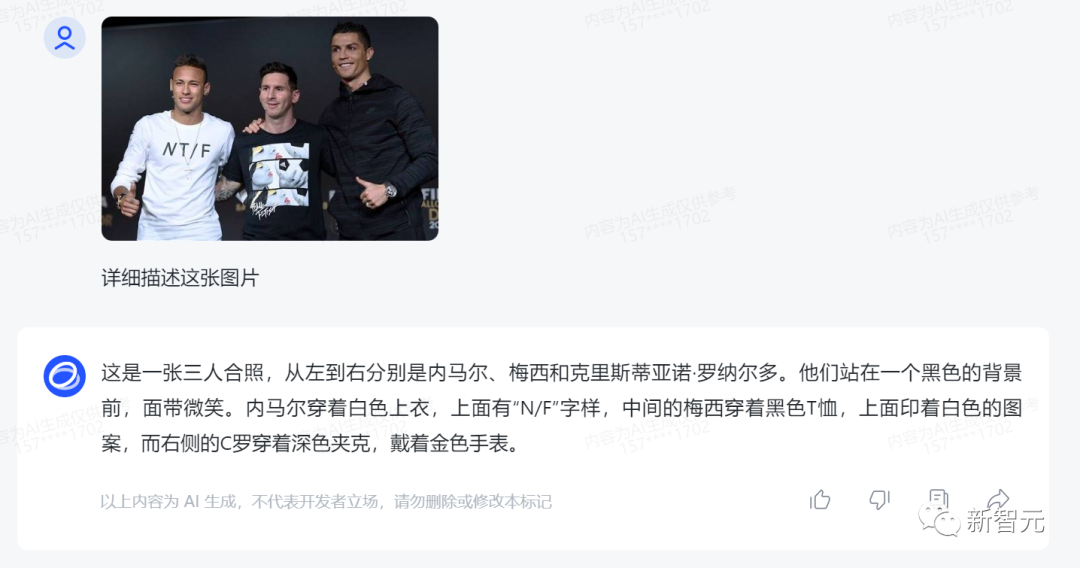
Neymar, Messi, and Ronaldo are also easily recognized by CogVLM.
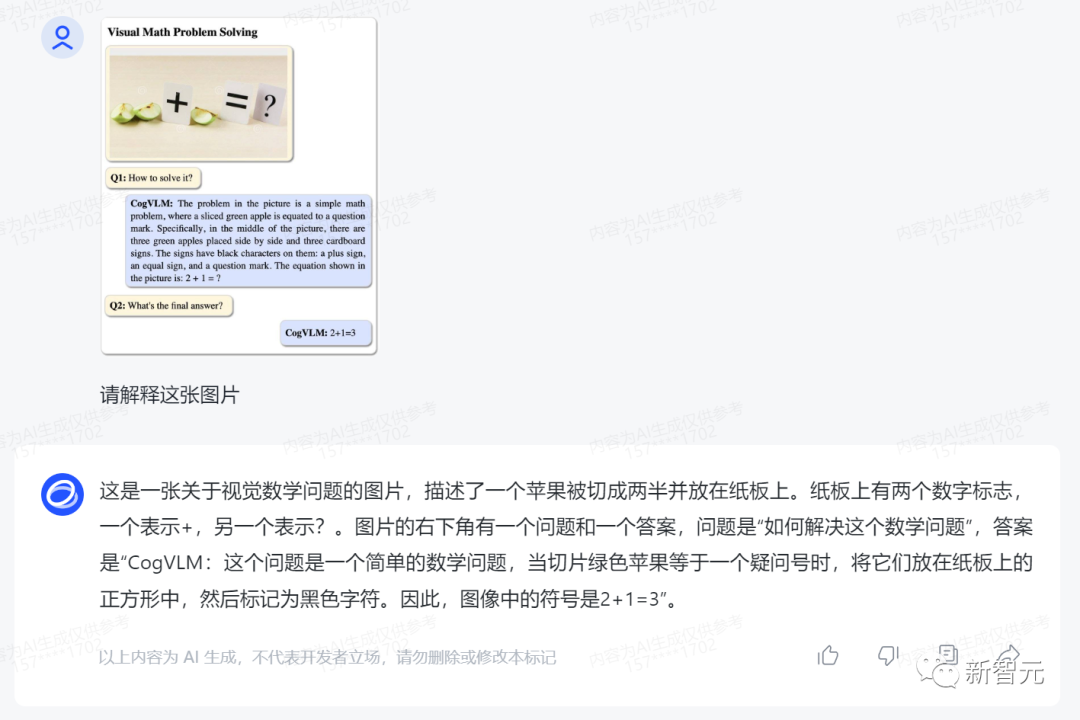
For a visual math problem of adding 2 apples and 1 apple, CogVLM can also provide the correct answer.
GLM vs GPT: Benchmarking OpenAI's Full Product Line!
From chat dialogue application ChatGPT, code generation plugin Code Interpreter, to the image-text model DALL·E 3, and the multimodal visual model GPT-4V, OpenAI currently has a complete product architecture.
Looking back at China, the only company that can achieve the most comprehensive product coverage is Zhipu AI.
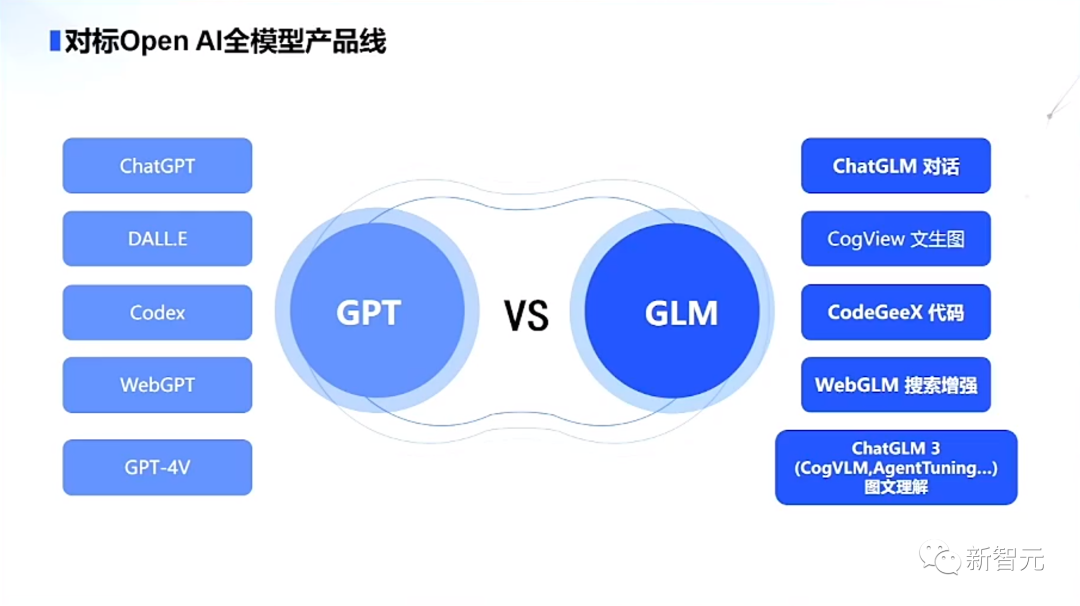
Dialogue: ChatGPT vs. ChatGLM
The introduction of the popular ChatGPT doesn't need much explanation.
At the beginning of this year, the Zhipu AI team also released a billion-level dialogue large model ChatGLM.
Drawing on the design concept of ChatGPT, developers injected code pre-training into the billion-level base model GLM-130B.
In fact, as early as 2022, Zhipu AI opened GLM-130B to the research and industrial communities, and this research was accepted by the top conferences ACL 2022 and ICLR 2023.
The ChatGLM-6B and ChatGLM-130B models were trained on a 1T token Chinese-English corpus, using supervised fine-tuning (SFT), feedback bootstrap, and human feedback reinforcement learning (RLHF).

The ChatGLM model can generate answers that align with human preferences. With quantization technology, users can deploy their own ChatGLM on consumer-grade graphics cards (only 6GB VRAM is required at the INT4 quantization level), and based on the GLM model, it can run on a laptop.
On March 14, Zhipu AI open-sourced ChatGLM-6B to the community and achieved first place in Chinese natural language, Chinese dialogue, Chinese question answering, and reasoning tasks in third-party evaluations.
At the same time, hundreds of projects or applications based on ChatGLM-6B have been created.
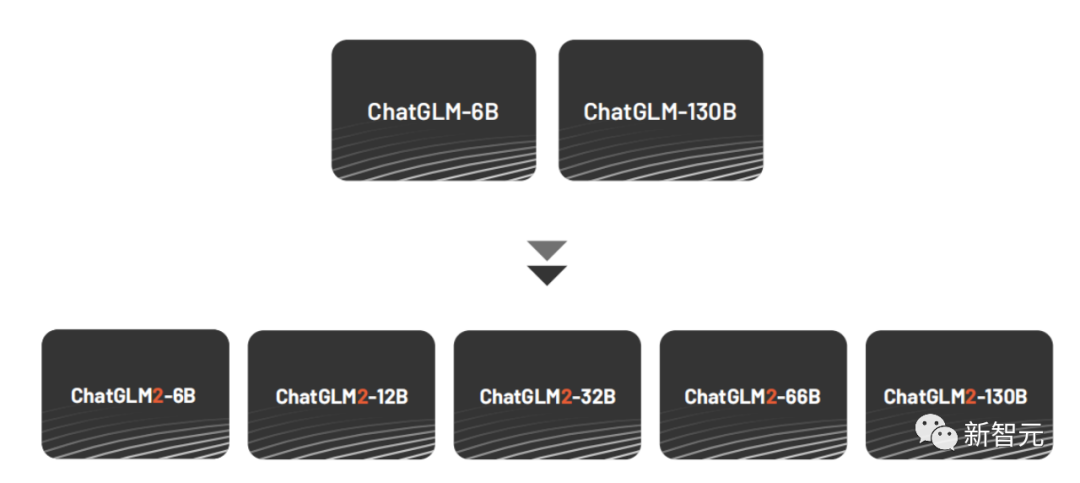
To further promote the development of the large model open source community, Zhipu AI released ChatGLM2 in June, upgrading and open sourcing the billion-level dialogue model in different sizes including 6B, 12B, 32B, 66B, and 130B, with enhanced capabilities and enriched scenarios.
ChatGLM 2 ranks first in the Chinese leaderboard, as of June 25, 2023, ChatGLM2 is at Rank 0 on the C-Eval leaderboard, and ChatGLM2-6B is at Rank 6. Compared to the first-generation model, ChatGLM 2 achieved improvements of 16%, 36%, and 280% in MMLU, C-Eval, and GSM8K, respectively.
It is worth mentioning that within a few months, both ChatGLM-6B and ChatGLM2-6B have been widely used.
Currently, they have received over 50,000 stars on GitHub. Additionally, on Hugging Face, there are over 10,000,000 downloads, ranking first in the four-week trend.
ChatGLM-6B: https://github.com/THUDM/ChatGLM-6B
ChatGLM2-6B: https://github.com/THUDM/ChatGLM2-6B
Search Enhancement: WebGPT vs. WebGLM
For the problem of "WebGPT," the general solution approach is to combine knowledge from search engines to enable the large model to perform "search enhancement."
As early as 2021, OpenAI fine-tuned a model based on GPT-3 that can aggregate search results - WebGPT.
WebGPT searches the web for relevant answers based on human search behavior and provides citation sources, making the results traceable.
Most importantly, it achieved excellent results in open-domain long-form question answering.
Following this approach, the "WebGLM" model based on ChatGLM 10 billion parameters was born, focusing on web search capabilities.

Paper link: https://arxiv.org/abs/2306.07906
For example, when you want to know why the sky is blue, WebGLM immediately provides an answer and includes a link to enhance the credibility of the model's response.

From an architectural perspective, the WebGLM search enhancement system involves three important components: retriever, generator, and scorer.
The retriever based on LLM is divided into two stages: coarse-grained web retrieval (search, retrieval, extraction), and fine-grained distilled retrieval.
In the entire process of retrieval, time is mainly consumed in the step of obtaining web pages, so WebGLM uses parallel asynchronous technology to improve efficiency.
The guided generator is the core, responsible for generating high-quality question answers from the reference web pages obtained from the retriever.
It utilizes the large model's contextual reasoning ability to generate high-quality QA datasets, and designs correction and selection strategies to filter out high-quality subsets for training.
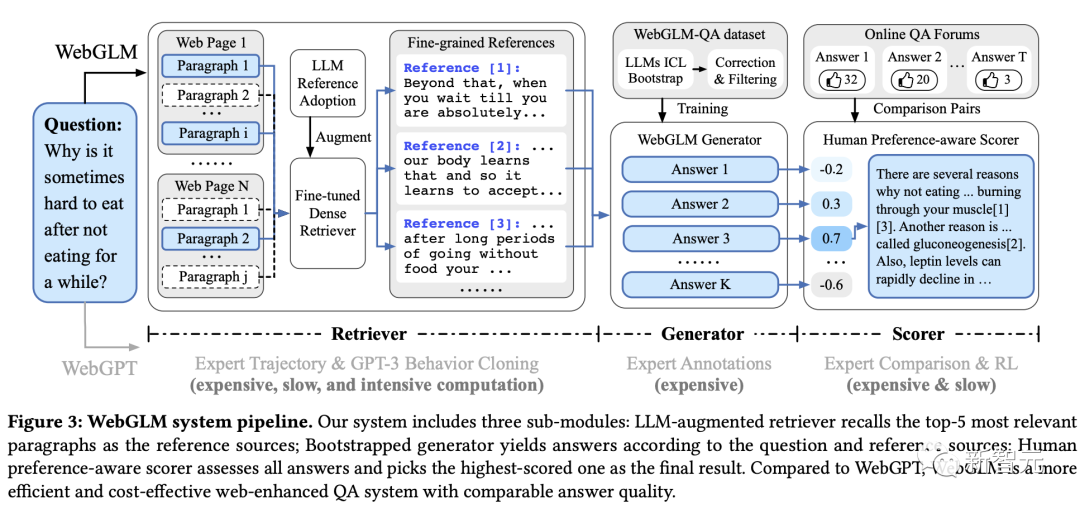
The final scorer is aligned with human preferences and uses RLHF to score the answers generated by WebGLM.
Experimental results show that WebGLM can provide more accurate results and efficiently complete question-answering tasks. It can even approach the performance of the 175 billion parameter WebGPT with its 10 billion parameters.
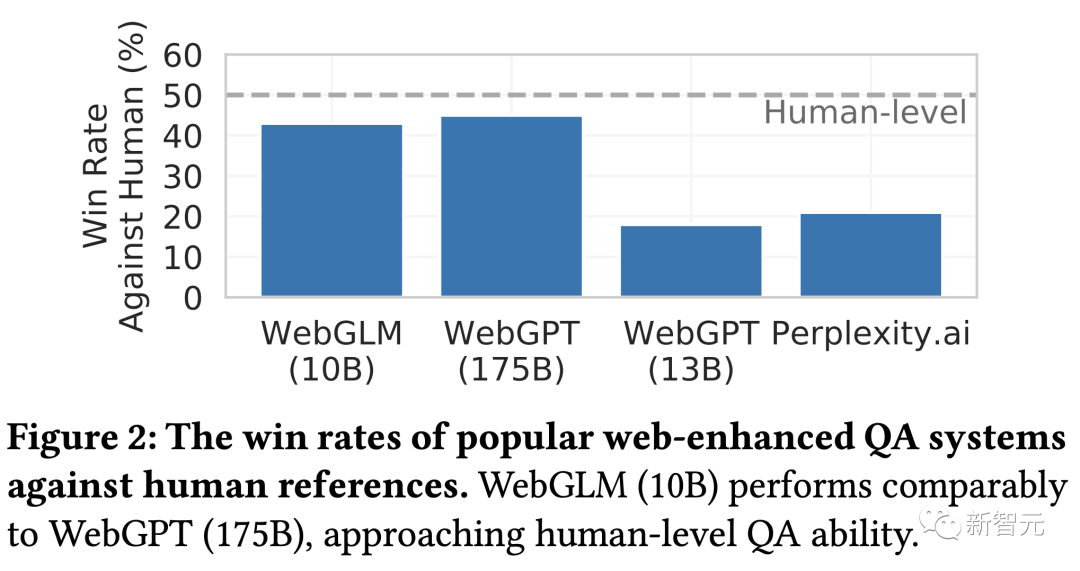
Currently, this research has been accepted by KDD 2023, and the Zhipu AI team has also open-sourced the capabilities and datasets.
Project link: https://github.com/THUDM/WebGLM
Image and Text Understanding: GPT-4V vs. CogVLM
In September of this year, OpenAI officially unveiled the astonishing multimodal capabilities of GPT-4.
Supporting this is GPT-4V, which has powerful understanding capabilities for images and can handle arbitrary mixed multimodal inputs.
For example, it can not only recognize that the dish in the image is Mapo Tofu, but can also provide the ingredients for making it.

In October, Zhipu AI open-sourced a new visual language-based model called CogVLM, which can achieve deep fusion of visual language features without sacrificing any NLP task performance.
Unlike common shallow fusion methods, CogVLM incorporates a trainable visual expert module into the attention mechanism and feedforward neural network layers.
This design achieves deep alignment between image and text features, effectively bridging the gap between pre-trained language models and image encoders.
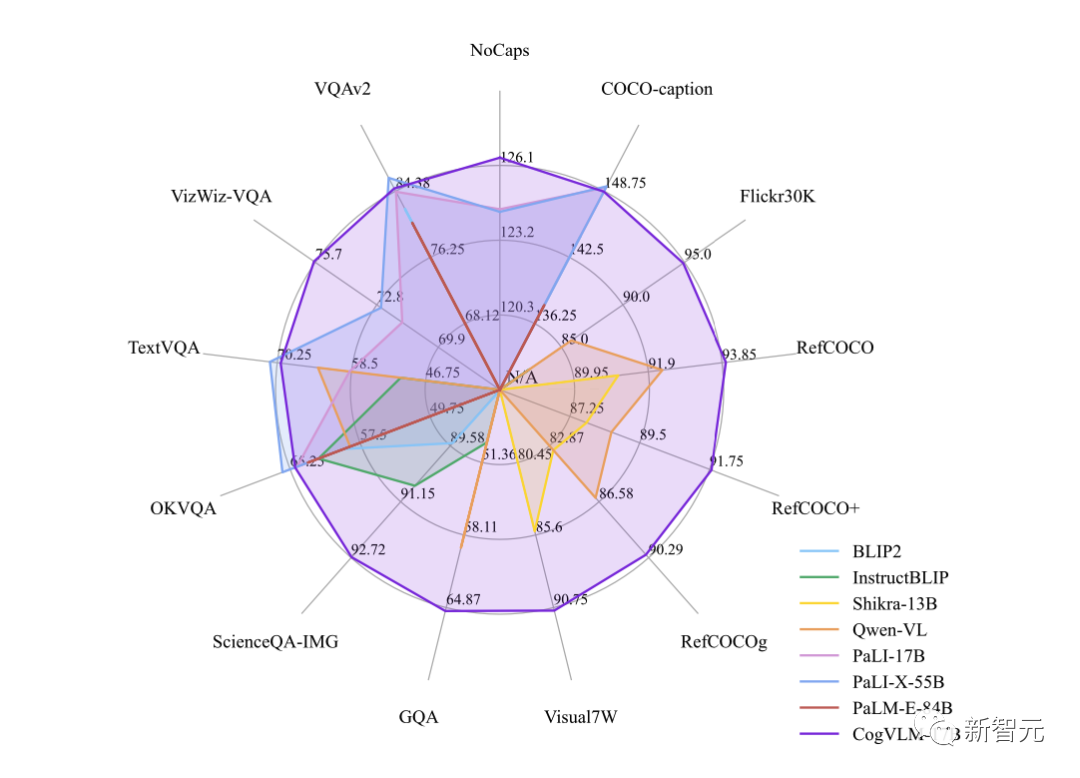
Currently, CogVLM-17B is the top-performing model on the multimodal authoritative academic leaderboard, achieving SOTA or second place on 14 datasets.
It has achieved the best (SOTA) performance in 10 authoritative cross-modal benchmark tests, including NoCaps, Flicker30k captioning, RefCOCO, RefCOCO+, RefCOCOg, Visual7W, GQA, ScienceQA, VizWiz-VQA, and TDIUC.
The core idea behind the improvement in CogVLM's performance is "visual-first."
Previous multimodal models usually directly align image features to the input space of text features, and the image feature encoder is usually relatively small. In this case, the image can be seen as a "vassal" of the text, naturally limiting the effectiveness.
In contrast, CogVLM prioritizes visual understanding in multimodal models, using a 5B parameter visual encoder and a 6B parameter visual expert module, totaling 11B parameters to model image features, even more than the 7B parameters for text.
In some tests, CogVLM's performance even surpasses that of GPT-4V.
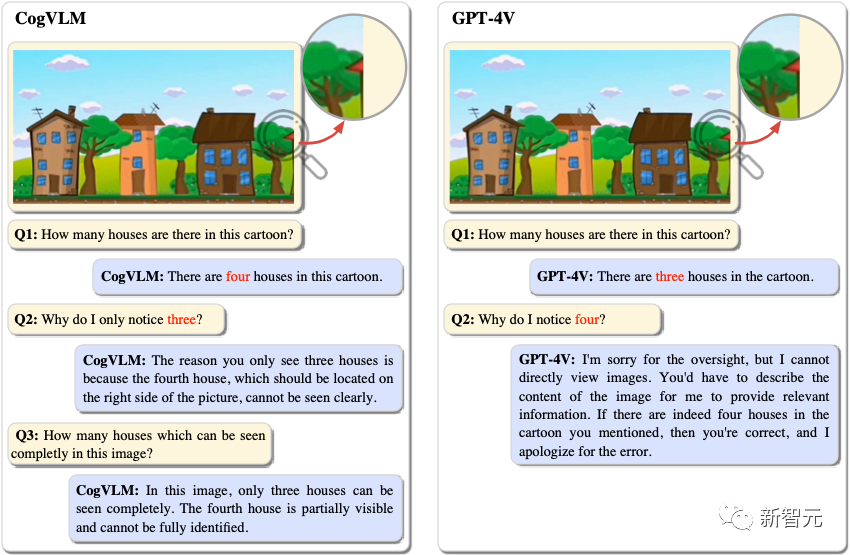
In the image, there are 4 houses, 3 of which are fully visible, and 1 can only be seen when zoomed in.
CogVLM can accurately identify these 4 houses, while GPT-4V can only identify 3.
This question involves a picture with text.
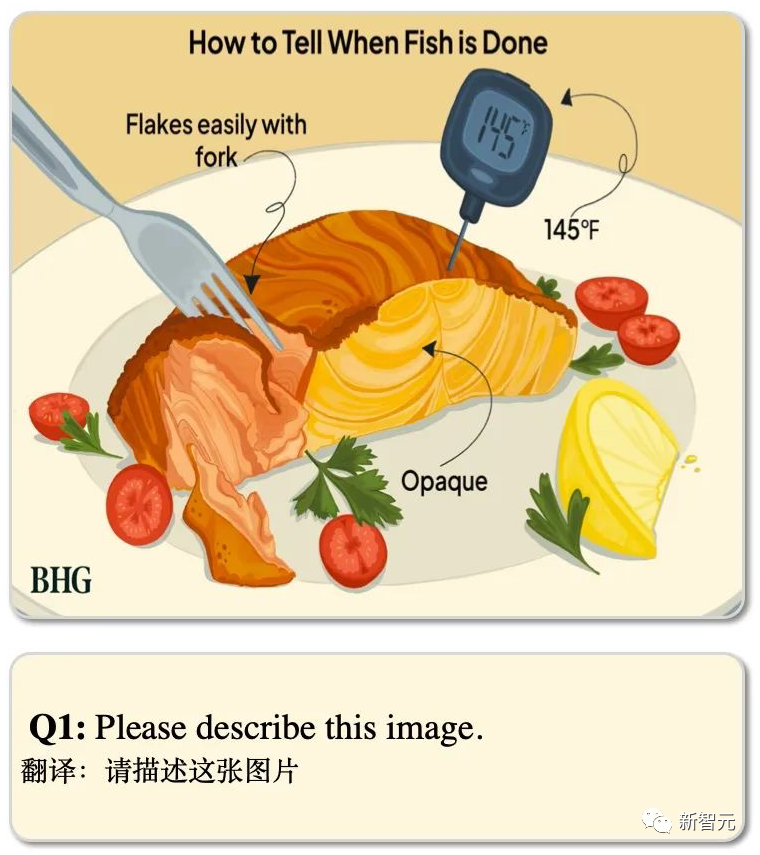
CogVLM faithfully describes the scene and the corresponding text.

Text-to-Image: DALL·E vs. CogView
OpenAI's most powerful text-to-image model currently is DALL·E 3.

In contrast, the Zhipu AI team has introduced CogView, a Transformer-based universal pre-training model for text-to-image.

Paper link: https://arxiv.org/abs/2105.13290
The overall idea of CogView is to perform autoregressive training by concatenating text features and image token features. Ultimately, the model can continuously generate image tokens with only text token features as input.
Specifically, the text "a cute little cat's avatar" is first converted into tokens using the SentencePiece model.
Then, an image of a cat is input, and the image part is transformed into tokens through a discrete auto-decoder.
Next, the text and image token features are concatenated and input into the GPT model within the Transformer architecture to learn to generate images.
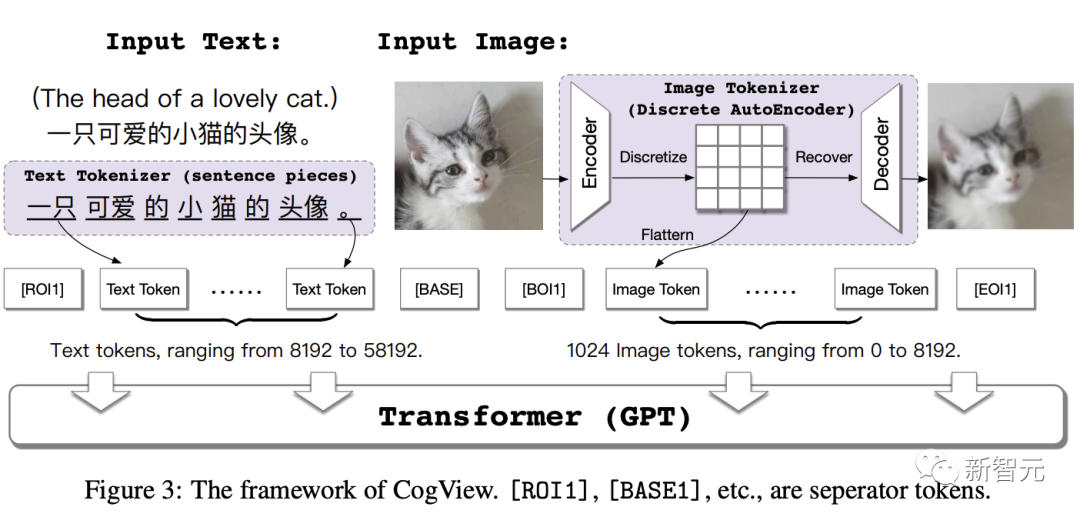
After training, when performing the task of text-to-image generation, the model will rank the generated results based on a Caption Score and select the most matching result.
Compared to DALL·E and common GAN solutions, CogView has achieved significant improvements in results.
In 2022, researchers once again upgraded the text-to-image model to CogView2, directly competing with DALL·E2.

Paper link: https://arxiv.org/abs/2204.14217
Compared to CogView, CogView2's architecture uses a layered Transformer and parallel autoregressive methods for image generation.
In the paper, researchers pre-trained a 6 billion parameter Transformer model - Cross-Modal Universal Language Model (CogLM) - and fine-tuned it to achieve fast super-resolution.
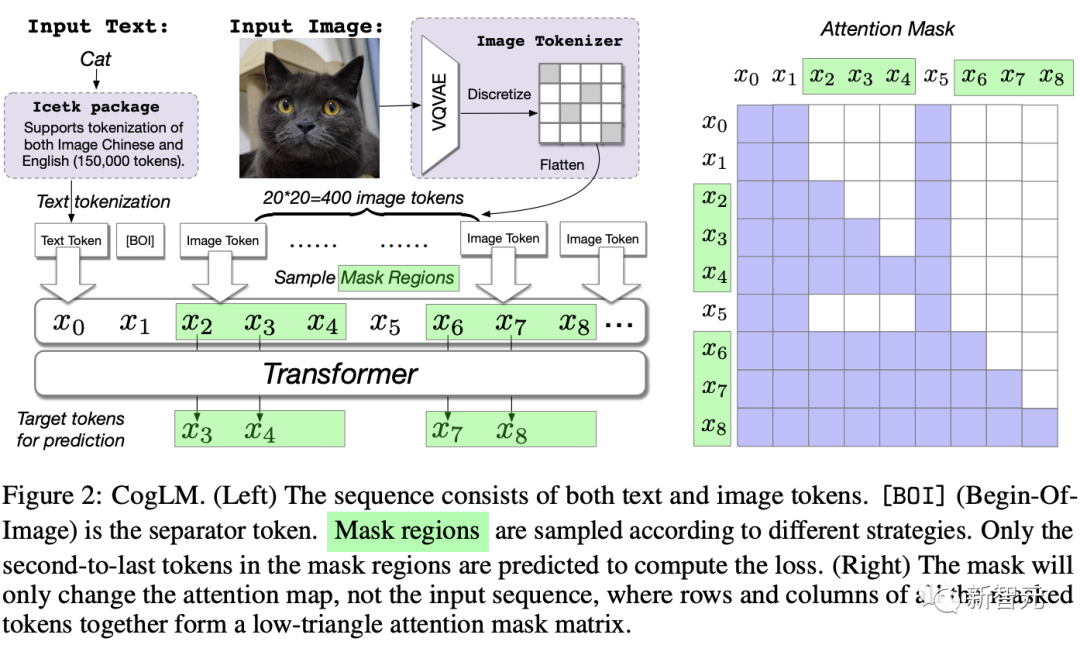
Experimental results show that compared to DALL·E 2, CogView2 also has advantages in generating results and can support interactive text-guided image editing.
In the same year, in November, the team developed a text-to-video generation model called CogVideo based on the CogView2 model.
The model architecture consists of two modules: the first part is based on CogView2, generating a few frames of images from text. The second part involves interpolating the images based on bidirectional attention models to generate higher frame rate complete videos.

Currently, all of the above models have been open-sourced. Are the teams from Tsinghua University always so direct and sincere?
Code: Codex vs. CodeGeeX
In the field of code generation, OpenAI released the upgraded Codex in August 2021, which is proficient in more than 10 programming languages including Python, JavaScript, Go, Perl, PHP, Ruby, Swift, TypeScript, and even Shell.

Paper link: https://arxiv.org/abs/2107.03374
Users can use natural language to automatically write code with simple prompts using Codex.
Codex is trained based on GPT-3 and includes tens of billions of lines of source code. Additionally, Codex can support over three times the context information of GPT-3.
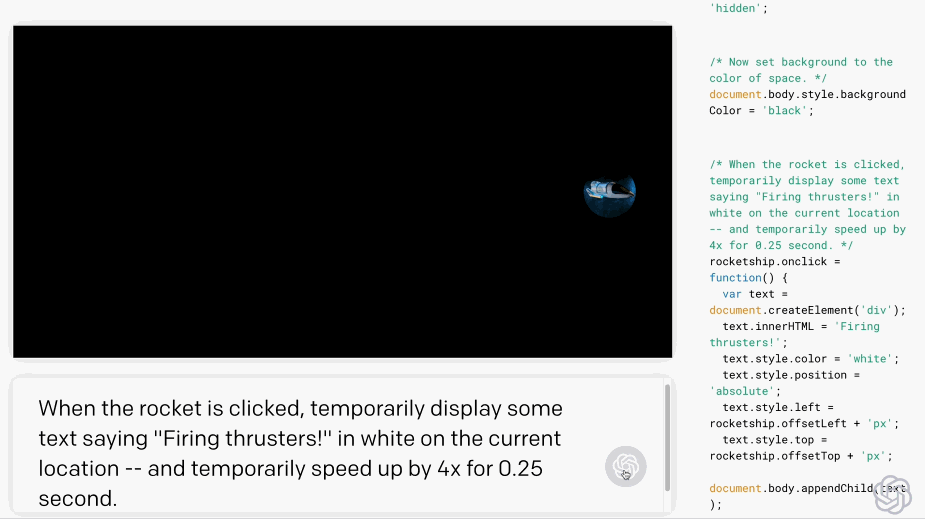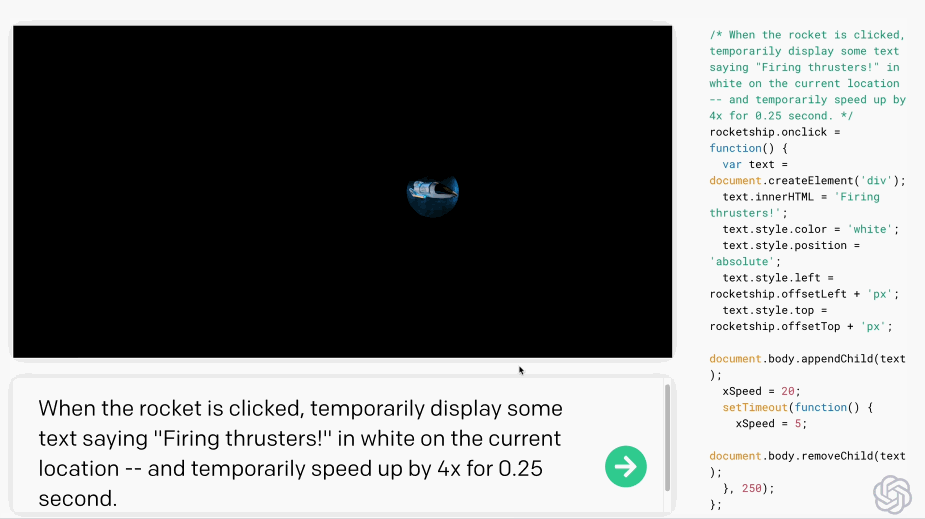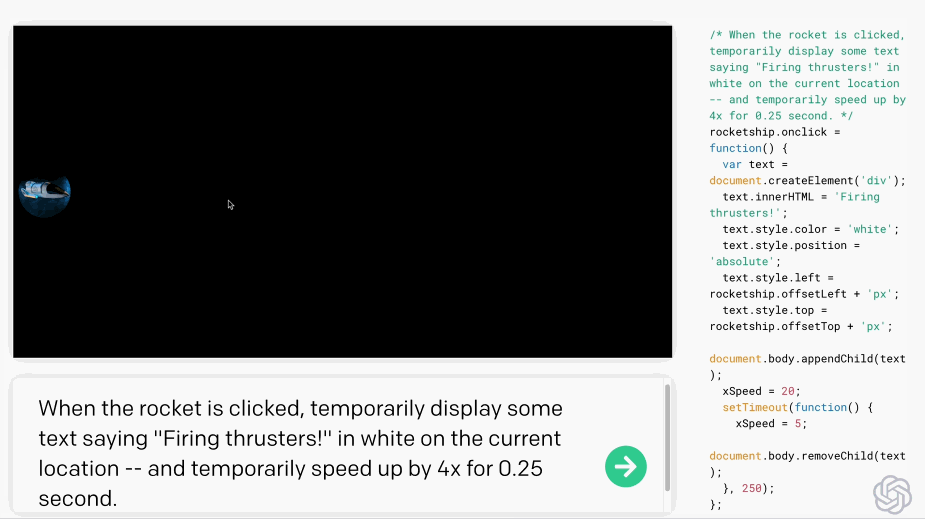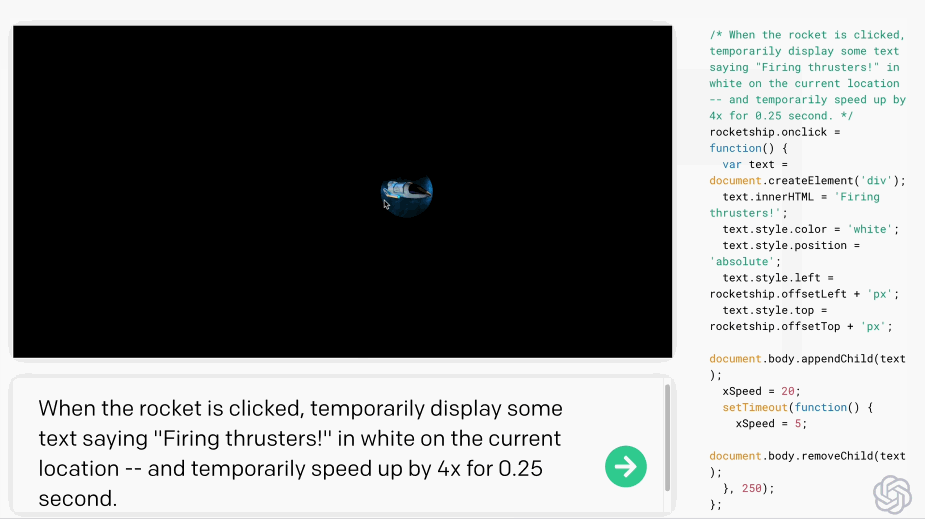
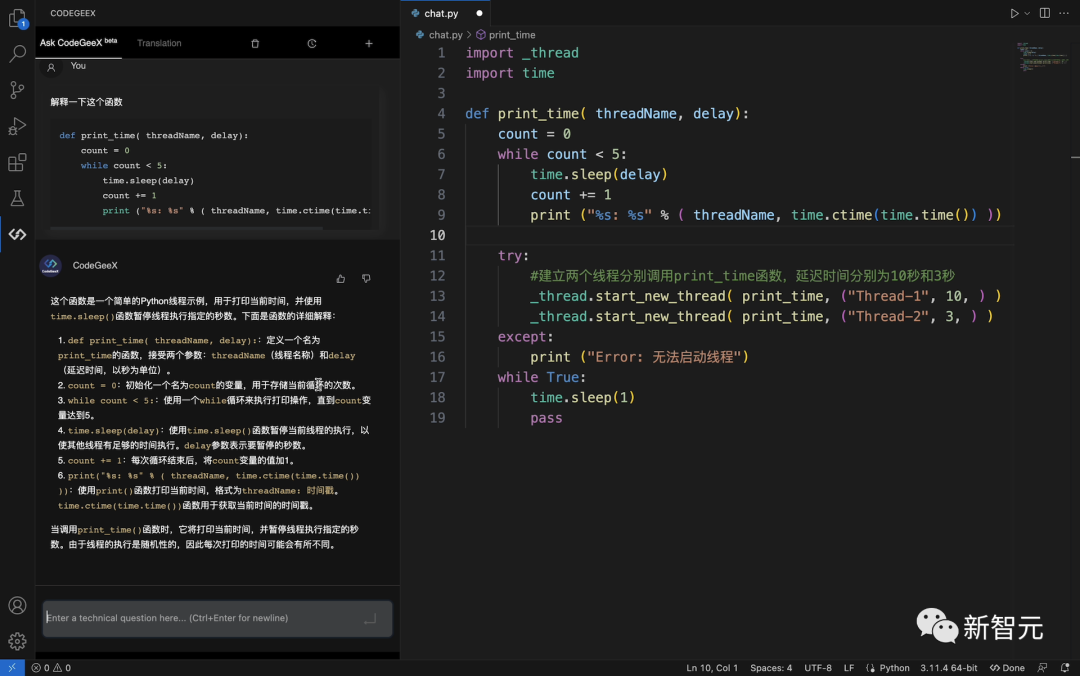
As a pioneer in China, Zhipu open-sourced the 13 billion parameter multi-programming language code generation, translation, and interpretation pre-training model CodeGeeX in September 2022, and it was later accepted by KDD 2023 (Long Beach).

Paper link: https://arxiv.org/abs/2303.17568
In July 2023, Zhipu released the more powerful, faster, and lighter CodeGeeX2-6B, which can support over 100 languages, and the weights are completely open for academic research.

Project link: https://github.com/THUDM/CodeGeeX2
CodeGeeX2 is based on the new ChatGLM2 architecture and has been optimized for various programming-related tasks such as code autocompletion, code generation, code translation, and cross-file code completion.
Thanks to the upgrade of ChatGLM2, CodeGeeX2 not only better supports Chinese and English input, and a maximum sequence length of 8192, but also achieves significant performance improvements - Python +57%, C++ +71%, Java +54%, JavaScript +83%, Go +56%, Rust +321%.
In HumanEval evaluations, CodeGeeX2 has comprehensively surpassed the 15 billion parameter StarCoder model and OpenAI's Code-Cushman-001 model (used by GitHub Copilot).
In addition, the inference speed of CodeGeeX2 is faster than the first-generation CodeGeeX-13B, requiring only 6GB of VRAM for quantization and supporting lightweight local deployment.
Currently, the CodeGeeX plugin can be experienced in popular IDEs such as VS Code, IntelliJ IDEA, PyCharm, GoLand, WebStorm, and Android Studio.
Self-developed Large Models from China
At the conference, Zhipu AI CEO Zhang Peng stated his opinion that the "era of large models" did not start this year with the ChatGPT sparking the LLM craze, but in 2020 with the birth of GPT-3.
At that time, just one year after its establishment, Zhipu AI began to focus all its efforts on large models.
As one of the earliest companies to enter the field of large model research, Zhipu AI has accumulated sufficient enterprise service capabilities. As one of the "first-movers" in open source, ChatGLM-6B reached the top of the Hugging Face trend list and received over 50,000 stars on GitHub within four weeks of its launch.
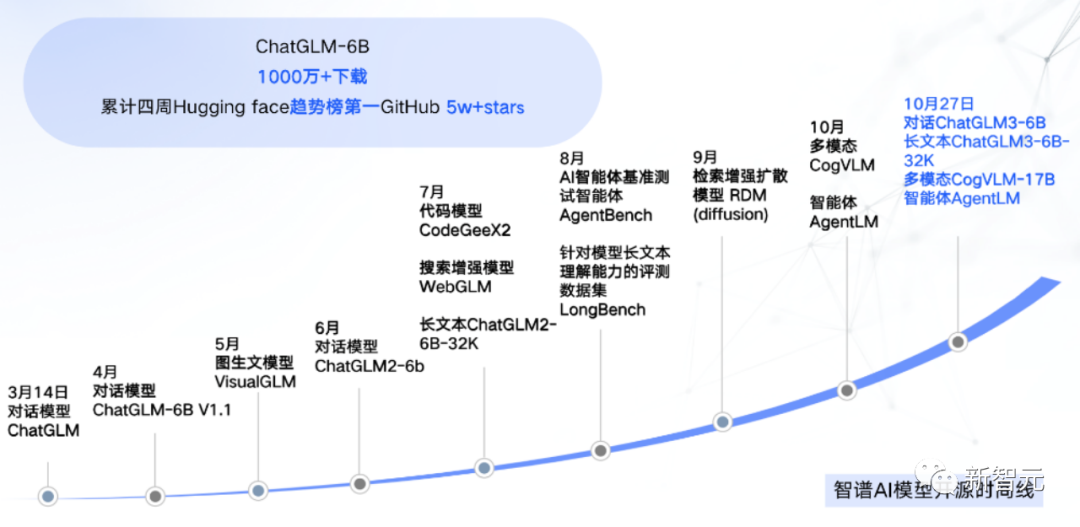
The release of ChatGLM3 has further strengthened the complete model product line that Zhipu AI has built.
In this fiercely competitive year of large models in 2023, Zhipu AI once again stands in the spotlight with the first-mover advantage of the newly upgraded ChatGLM3.
Reference: https://chatglm.cn/main/detail
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。






