Source: Quantum Bit

Image Source: Generated by Wujie AI
Tech Giant Tencent's Big Model, with a New Way to Play!
Less than two months after its release, Tencent's Hybrid Big Model has quickly launched a new version. In addition to upgrading the language model, it quietly launched the hottest feature of AIGC - Wenshengtu.
Similar to the language model, Wenshengtu can also be experienced directly through the WeChat mini program.
However, unlike Midjourney's independent drawing, the Wenshengtu of Hybrid does not interfere with the conversation function, allowing you to chat and draw at the same time, similar to the experience of DALL·E 3.
For those who have already applied for testing, you can dive in right away.
For those still in line, don't worry. We have quickly tested a wave of hot images, and we'll release them for everyone to see first.
Hybrid Wenshengtu Hands-on Test
According to Tencent, the three biggest advantages of the Hybrid Big Model's Wenshengtu are realism, understanding of Chinese, and diverse styles.
Next, let's try it out one by one to see how well it performs.
Let's start with drawing people, replicating the previously popular Midjourney "realistic 90s Beijing couple" and see.
Please output a photo in a photography style, in 1990s Beijing, with a male and a female, smiling, sitting on the roof, wearing jackets and jeans, with many buildings, realistic feeling.

It can be seen that the realistic style of portraits is still very skillful, with reasonable character poses, and the portrayal of Asian faces is more natural compared to foreign AI.
Note that there is a small trick here. If you want a realistic style, it's best to use "generate a picture of…" to trigger it. If you use "draw a picture of…", you will probably get an illustration style.
Realistic style portraits are good, now let's see how it draws landscapes.
In addition to general landscape descriptions, the Hybrid Big Model supports specifying a real existing scenic spot, such as "Guilin landscape" or "the Great Wall".
After all, it's AI-generated, and it won't be exactly the same as the real landscape, but it still feels on point.


Next, let's raise the difficulty and "combine" these two scenes:
Generate a picture of Guilin landscape, but with the Great Wall on the shore, in a photography style, with a realistic feeling and high detail.

It has drawn such an outrageous demand, and there are even ripples on the water surface. It seems that it's not just a simple reproduction of training data, but it has its own understanding of the concept.
So, how about more complex concepts?
Once, AI caused a wave of jokes because it didn't understand Chinese dish names.
After six months of development, "Lion's Head in Brown Sauce" no longer has a lion's head, and "Sliced Beef and Ox Tongue in Chili Sauce" won't turn into a horror movie, and it even looks quite appetizing.


More challenging than dish names are ancient poems. Since we've seen enough of the realistic style, let's change the taste.
Generate a picture: An old man in a straw rain cape, alone fishing in a cold river with snow, in ink painting style.
Overall, it's not bad. The only downside is that one picture doesn't have a "boat", and in another picture, there are two "old men" on the boat, so it loses the sense of solitude.
It seems that condensed poetry like this is still difficult.

But, don't forget that the Hybrid Assistant also has the ability to chat and supports multi-turn conversations.
With the help of the powerful language model, we also found a solution.

Next, just use "these requirements" or "the above requirements" to refer to the above answer, and you can link the two functions together.
Drawing will be more stable, and it adds the detail of snowflakes falling.
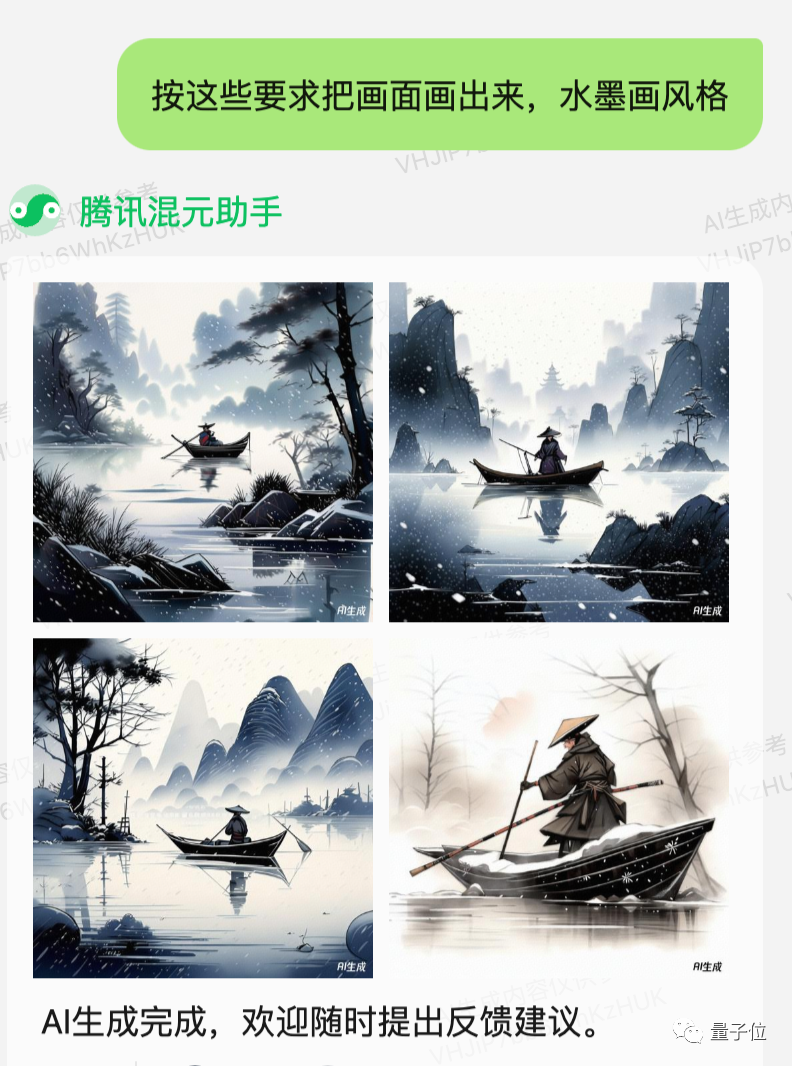
Remember this little trick, it will be used next.
In fact, in the Tencent Hybrid Assistant, a save as command function is specifically prepared for this.

Once saved, it can be quickly called from the magic wand icon on the right side of the chat box, and only the content to be described needs to be changed.

It's also convenient to share directly to WeChat, allowing friends to help choose from four images at once, without the need for back and forth screenshots.
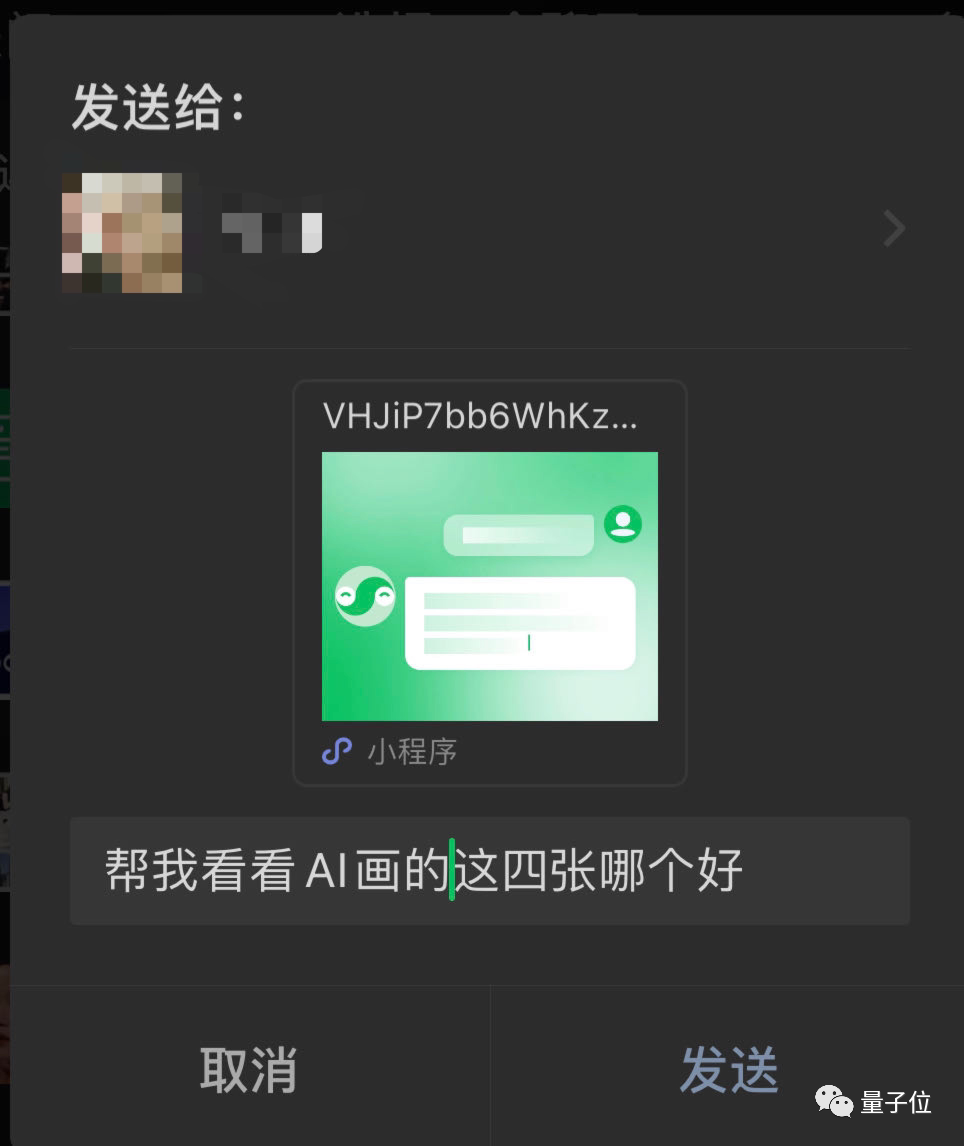
Just open the shared link to zoom in and view the four images, and you can start a new conversation!

After understanding the Chinese understanding ability of the Hybrid Big Model, let's try the last feature, diverse styles.
Since it's a Tencent product, game illustrations are definitely indispensable, such as the popular cyberpunk style.

It feels a bit, but it still seems to be missing something.
You can use the above technique to link the language model to clarify the characteristics of the cyberpunk style.

Add a little more manually, and it will be more to your taste.

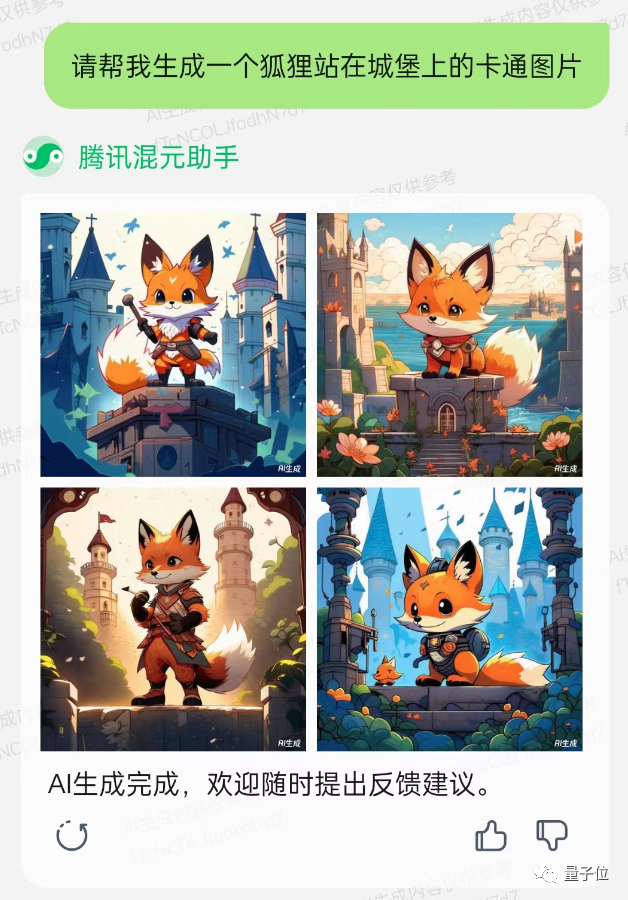
The difference in art styles of different games is huge. Testing has shown that the Hybrid Assistant can indeed handle a lot, from 3D to 2D and even pixel art.

Even with the same topic and style constraints, it can display different art styles, much to the delight of furry enthusiasts (doge).
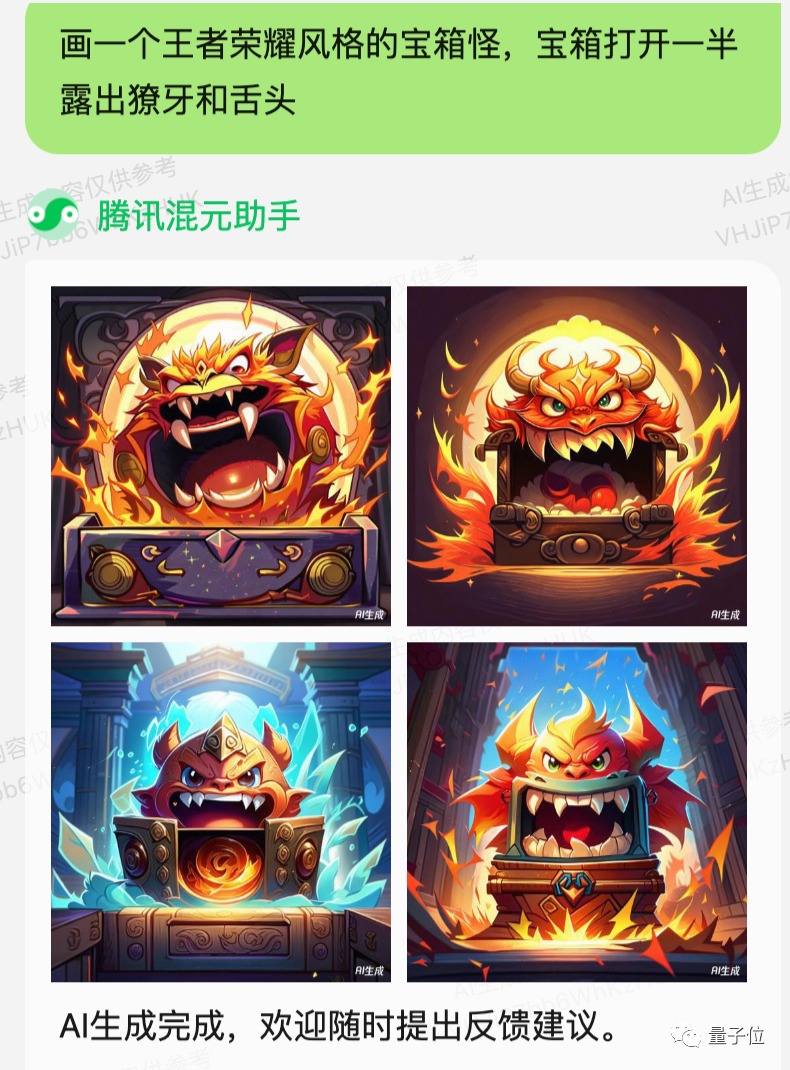
In fact, Tencent has revealed that the Hybrid Big Model's Wenshengtu capability has been used in multiple internal scenarios.
Although we don't know exactly how it's used, we tested using "King of Glory" as a style constraint word, and the Hybrid Assistant understood it.
In addition to gaming, there are also advertising scenarios, where the advantage of the realistic feeling of the Hybrid Big Model's Wenshengtu mentioned earlier can be brought into play.
And don't forget that Tencent also has a large content business, so it's no problem to create illustrations for fantasy novels.

With such Wenshengtu effects, what is the underlying principle behind it?
Before this, the industry actually had many open-source models for Wenshengtu.
Did Tencent build it based on a certain solution from the industry, or did they develop it from scratch?
With all these questions, we had a chat with Lu Qinglin, the technical lead of the Tencent Hybrid Big Model's Wenshengtu, to understand the technical details behind it.
Fully self-developed model, refined with 20 billion+ image-text pairs
"From algorithms, data systems to engineering platforms, everything is developed from scratch."
Lu Qinglin said that this is also considered an advantage of the Tencent Hybrid Big Model's Wenshengtu function. This way, from the freedom of generation to data security, everything can be fully controlled, making the generated images "more in line with user needs."

First, in the algorithm area.
The current Wenshengtu models generally face three difficulties: poor semantic understanding, unreasonable composition, and lack of texture in the images.
Poor semantic understanding means that the model doesn't understand human language, especially mixed Chinese and English.
The industry generally uses the open-source CLIP algorithm, but it doesn't model Chinese language, so inputting Chinese can only rely on translation, leading to problems like "Lion's Head in Brown Sauce" actually generating a lion (doge); another issue is the poor alignment of image-text during training.
Unreasonable composition refers to problems with the generated human body structure and image structure, resulting in "alien" creations.
If directly based on existing open-source diffusion models in the industry to generate images, this problem is likely to occur, such as "three hands" or various strange image structures.

Lack of texture in the images means poor image clarity. Many datasets currently have low image resolution and quality, which can lead to low-quality open-source model training.
To address these three difficulties, the Tencent Hybrid team used a combination of three types of models to "tackle each one."
For semantic understanding, Tencent independently developed a cross-modal pre-training large model, which not only allows it to model both Chinese and English, but also strengthens the connection between text and image fine-grained features, in simple terms, the "cross-modal alignment" of Chinese, English, and images.
For composition generation, Tencent independently developed an architecture that combines a diffusion model and Transformer, especially using the currently popular rotation position encoding in Transformers.
Rotation position encoding is usually used to increase the context length of large models, but here Tencent cleverly used it to depict human body structure, allowing the model to grasp both global information (human skeleton) and understand local information (facial details).
Finally, for image texture, Tencent independently developed a super-resolution model, combined with multiple algorithms to optimize different details of the images, making the final generated images even more "viewable."
This model architecture not only generates higher-quality images (resolution 1024×1024), but with just a slight adjustment to the architecture, it can also become an image-to-image or even a text-to-video model.
Next, it's the crucial data part.
For Wenshengtu, the quality of the generated images largely depends on the quality of the data. In the DALL·E 3 paper, OpenAI emphasizes the importance of data for instruction following throughout.
Tencent also attaches great importance to the importance of data for the model and has independently developed three aspects of technology.
For data quality, due to the problem of datasets scraped from the internet often having concise text descriptions that do not fully match the generated content, the team improved the "text" part of the image-text dataset, refining the Chinese text descriptions to enhance the relevance of the image-text data.
For data effectiveness, the team has implemented a "gold, silver, bronze" hierarchical grading for the training data. The higher the grade, the more finely the data is cleaned.
Among them, the "bronze data" of over 20 billion uncleaned data is used for "rough processing" of all models, which is pre-training;
The "silver data" of over 600 million is used for further processing of the generation model to improve the quality of generation;
The carefully cleaned "gold data" of over 1.12 billion is used for "fine processing" of the model, which is a precise and intensive training to ensure the model's quality is even better.

In terms of data efficiency, in order to speed up the training process, especially in optimizing the model based on user feedback, Tencent has also established a data flywheel to automate the construction of training data and accelerate model iteration, further improving the accuracy of model generation.
According to Lu Qinglin, the data flywheel technology is also the key to solving the problem of long-tail data scenarios.
Because there are always new trendy terms appearing in our lives, such as "Lina Bell," these kinds of terms are often not commonly seen in the dataset, but users may use them in their input, so they often need to be updated in the training data as soon as possible.
With the data flywheel, this process can be further improved in efficiency, avoiding the model taking a long time to generate corresponding images after encountering new terms.
Finally, with algorithms and data, there needs to be an engineering platform to combine them for fast training.
To this end, Tencent has independently developed the Angel machine learning platform, including the training framework AngelPTM and the inference framework AngelHCF.
In terms of training, the most important thing for large models is parallel capability. To achieve this, Tencent has implemented rapid training of the trillion-parameter Hybrid Big Model based on 4D parallelism and the ZeROCache mechanism.
Visually, the AngelPTM training framework has achieved a speed increase of more than 1x compared to the mainstream framework DeepSpeed-Chat.
For inference, AngelHCF has achieved support for multiple parallel capabilities, support for service deployment and management, and self-developed model lossless quantization, achieving a speed increase of more than 1.3x compared to the mainstream framework.
It is worth mentioning that with the support of the Angel machine learning framework and platform, Tencent's Hybrid language model has also undergone an upgrade, especially with a significant improvement in its coding capability.
We also conducted a simple test of Tencent's Hybrid Big Model's updated coding capability.
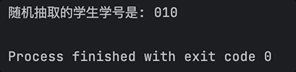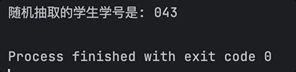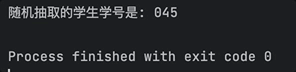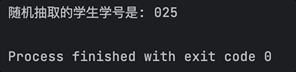
First, let's try writing some code, using the example of helping a teacher write a "random roll call program" (hand doge).

The Hybrid Big Model quickly generated a complete code with comments:
Upon testing, it runs smoothly, and each time it can draw different "lucky" students to answer questions:
Then we also found that the Hybrid Big Model can actually help find code bugs, truly a handy tool for programmers.

Of course, whether it's Wenshengtu or coding capability, both can now be experienced in the Tencent Hybrid Assistant.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。








