Source: AIGC Open Community

Image Source: Generated by Wujie AI
Midjourney and Stable Difusion have achieved great success in commercial realization and scenario-based implementation, which has opened up new business opportunities for OpenAI and is one of the important reasons for the release of DALL·E 3.
Last week, OpenAI announced the full opening of the DALL·E 3 model in ChatGPT Plus and Enterprise Edition users, and also released a research paper, which is rare.
Compared with the previous two generations, DALL·E and DALL·E 2, DALL·E 3 has made a qualitative leap in semantic understanding, image quality, image modification, image interpretation, and long-text input, especially when combined with ChatGPT, it has become a new ace application for OpenAI.
Paper link: https://cdn.openai.com/papers/dall-e-3.pdf

Next, "AIGC Open Community" will interpret the main technical principles and functions of each module of DALL·E 3 based on its research paper.
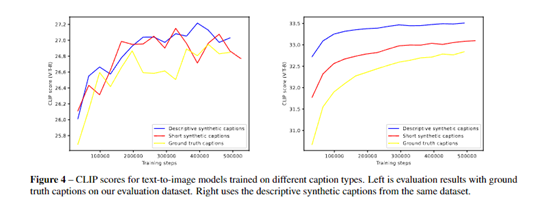
Researchers found that text-to-image generation models often face various challenges in following detailed image descriptions, ignoring words in the prompts or confusing their meanings, and the fundamental reason is the poor quality of image descriptions in the training dataset.
To verify this hypothesis, researchers first trained a model to generate detailed and accurate descriptions for images. After careful training, the model can generate detailed and accurate descriptions for images.

After using this model to regenerate descriptions for the training dataset, researchers compared multiple text-to-image generation models trained on the original and newly generated descriptions.
The results showed that models trained on the new descriptions were significantly better at following prompts than the models trained on the original descriptions. Subsequently, this method was used to train DALL-E 3 on a large-scale dataset.

From the technical architecture of DALL-E 3, it is mainly divided into two major modules: image description generation and image generation.
Image Description Generation Module
This module uses the CLIP (Contrastive Language-Image Pretraining) image encoder and GPT language model (GPT-4) to generate detailed textual descriptions for each image.
Researchers significantly increased the amount of information in the output of the module by constructing a small-scale main body description dataset, a large-scale detailed description dataset, and setting generation rules, providing strong support for subsequent image generation. The main functions of each module are as follows:
1) CLIP Image Encoder
CLIP is a pre-trained image-text matching model that can encode an image into a fixed-length vector containing semantic information about the image. DALL-E 3 uses CLIP's image encoder to encode training images into image feature vectors, which are used as part of the input for conditional text generation.
2) GPT Language Model
DALL-E 3 is built on the GPT architecture to establish a language model that learns to generate coherent textual descriptions by maximizing the joint probability of randomly sampled text sequences.
3) Conditional Text Generation
By combining the above two, the image feature vector and the previous word sequence are input into the GPT language model together to achieve conditional text generation for images. Through training, this module learns to generate detailed and descriptive descriptions for each image.
4) Training Optimization
Although the basic architecture of DALL-E 3 has been completed, the results of direct training are not ideal and cannot generate rich detailed descriptions. Therefore, researchers made the following technical optimizations:

- Construct a small-scale dataset specifically collecting detailed descriptions of main objects, fine-tune the language model to focus on describing the main body of the image.
- Construct a large-scale detailed description dataset, describing various aspects such as the main body, background, color, and text, and further improve the quality of descriptions through fine-tuning.
- Set rules for generating descriptions in terms of length, style, etc., to prevent the language model from deviating from human style.
Image Generation Module
This module first compresses high-resolution images into low-dimensional vectors using VAE to reduce the learning difficulty. Then, it uses the T5 Transformer to encode text into vectors and injects them into the diffusion model through the GroupNorm layer to guide image generation.
Researchers believe that the additional Diffusion model significantly enhances the effect of generating image details. The specific process is as follows:
1) Image Compression
High-resolution images are first compressed into low-dimensional vectors using the VAE model to reduce the difficulty of image generation. DALL-E 3 uses 8x downsampling, compressing 256px images into 32x32 size latent vectors.
2) Text Encoder
Networks such as T5 Transformer are used to encode text prompts into vectors for injection into the image generation model.

3) Latent Diffusion
This is the core technology for image generation, decomposing the image generation problem into small-scale perturbations of noise vectors, gradually approaching the target image. The key is to design appropriate forward and backward processes.
4) Text Injection
The encoded text vector is injected into the Latent Diffusion model through the GroupNorm layer to guide the direction of image generation for each iteration.
5) Training Optimization
Researchers found that training another Diffusion model on the compressed image latent space can further improve the quality of detail generation. This is also one of the reasons why DALL-E 3 generates better image quality than the previous two generations.
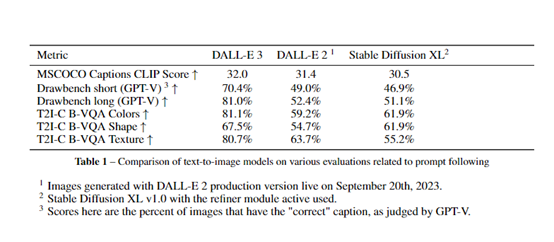
CLIP Evaluation Data
Researchers first used the CLIP model to calculate the similarity between the images generated by DALL-E 3 and the original descriptive text, i.e., the CLIP score. They randomly selected 4096 image descriptions from the MSCOCO dataset as prompts, had DALL-E 2, DALL-E 3, and Stable Diffusion XL generate corresponding images, and then calculated the average CLIP scores for the three.
The results showed that DALL-E 3 achieved a CLIP score of 32.0, higher than DALL-E 2's 31.4 and Stable Diffusion XL's 30.5.
This indicates that the images generated by DALL-E 3 have a higher degree of conformity with the original descriptive text, and the effect of text-guided image generation is better.
Drawbench Evaluation Data
The performance of each model was compared on the Drawbench dataset. This dataset contains many fragile text prompts, testing the model's understanding of the prompts.
Researchers used the GPT-V, a language model equipped with visual capabilities, to automatically judge the correctness of the generated images.
In the subtest with short text prompts, DALL-E 3 achieved a 70.4% proportion of correctly generated images, significantly surpassing DALL-E 2's 49% and Stable Diffusion XL's 46.9%.
In the long text prompts, DALL-E 3 also achieved an accuracy rate of 81%, continuing to lead other models.
T2I-CompBench Evaluation
Through the relevant subtests in T2I-CompBench, the model's ability to handle composite prompts was examined. In the color binding, shape binding, and texture binding tests, DALL-E 3's correct binding proportion ranked first among all models, fully demonstrating its strong ability to understand composite prompts.
Human Evaluation
Researchers also invited human evaluators to judge the generated samples in terms of following prompts, style consistency, and other aspects. In the evaluation of 170 prompts, DALL-E 3 was significantly superior to Midjourney and Stable Diffusion XL.

免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







