Training a text-to-image model comparable to MJ only costs $26,000.

Image source: Generated by Wujie AI
Original source: Synced
Currently, the most advanced text-to-image (T2I) models require a large amount of training cost (e.g., millions of GPU hours), which severely hinders the basic innovation of the AIGC community and increases carbon dioxide emissions.
Now, researchers from Huawei Noah's Ark Lab and other research institutions have jointly proposed the groundbreaking text-to-image (T2I) model PixArt-α, which only requires 10.8% of the training time of Stable Diffusion v1.5 (about 675 vs about 6250 A100 GPU days), saving nearly $300,000 ($26,000 vs $320,000). Compared to the larger SOTA model RAPHAEL, PixArt-α's training cost is only 1%, and it supports direct generation of high-resolution images up to 1024×1024 resolution.
The PixArt-α model not only significantly reduces training costs, but also significantly reduces carbon dioxide emissions, while providing high-quality image generation close to commercial application standards. The emergence of PixArt-α provides a new perspective for the AIGC community and startups to accelerate the construction of their own high-quality and low-cost generation models.

- Paper link: https://arxiv.org/abs/2310.00426
- Homepage: https://pixart-alpha.github.io/
- Project link: https://github.com/PixArt-alpha/PixArt-alpha
In general, PixArt-α is a Transformer-based T2I diffusion model, whose image generation quality can rival state-of-the-art image generators (e.g., Imagen [1], SDXL [2], and even Midjourney [3]), reaching close to commercial application standards. In addition, it supports direct generation of high-resolution images up to 1024×1024 resolution, with low training costs, as shown in Figure 1.

Figure 1. Samples generated by PixArt-α demonstrate its outstanding quality, characterized by high-precision and accurate image generation.
To achieve this goal, the study proposes three core designs:
- Decomposed training strategy: The study designs three unique training steps to optimize pixel dependencies, text-image alignment, and image aesthetic quality, respectively;
- Efficient T2I Transformer structure: The study integrates cross-attention modules into the Diffusion Transformer (DiT) [6] to inject text information and simplify the computation of class-conditional branches;
- High information density data: The study emphasizes the importance of concept density in text-image pairs and uses a large visual language model to automatically label dense pseudo-text labels to assist in text-image alignment learning.
A large number of experiments show that PixArt-α performs well in terms of image quality, artisticness, and semantic control. The research team hopes that PixArt-α can provide new ideas for the AIGC community and startups to accelerate the construction of their own high-quality and low-cost generation models.
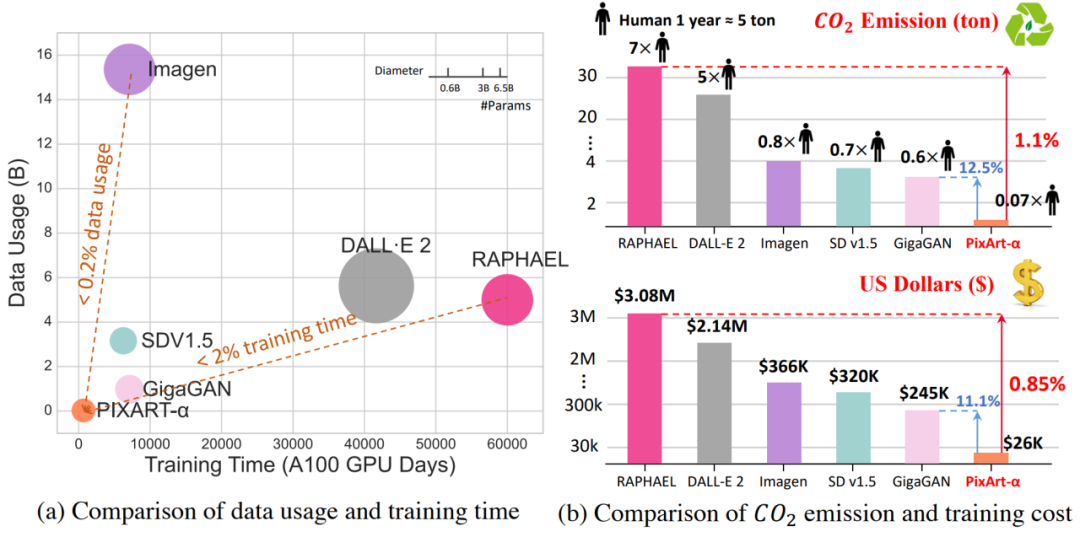
Figure 2. Comparison of carbon dioxide emissions and training costs between T2I methods. PixArt-α achieves extremely low training costs, only $26,000. Compared to RAPHAEL, PixArt-α's carbon dioxide emissions and training costs are only 1.1% and 0.85%, respectively.
Looking at the essence from the phenomenon: Re-examining the text-to-image task from the perspective of training process and data
Starting from the existing training process: The text-to-image (T2I) generation task can be decomposed into three aspects: modeling pixel relationships, precise alignment of text and images, and high aesthetic quality generation. However, existing methods mix these three problems together and directly use a large amount of data to train from scratch, resulting in low training efficiency.
Starting from the training data: As shown in Figure 3, existing text-image pairs often have problems such as misalignment of text and images, insufficient descriptions, containing a large number of uncommon vocabulary, and containing low-quality data. These problems make training difficult and require millions of iterations to achieve stable alignment between text and images. To address this challenge, the study introduces an innovative automatic labeling process to generate precise image captions.

Figure 3. Comparison between native titles of LAION [6] and fine titles of LLaVA. LLaVA provides text with higher information density, helping the model to grasp more concepts in each iteration, improving the efficiency of text-image alignment.
Decoupling training strategies: Acquiring different data, reinforcing different abilities
1. Learning pixel dependencies
Current class-conditional methods [7] have shown outstanding performance in generating semantically coherent and logically reasonable images. Training a class-condition image generation model that conforms to the natural image distribution is not only relatively simple but also cost-effective. The study also found that proper initialization can greatly improve the training efficiency of the image generation model. Therefore, the PixArt model adopts a pre-trained ImageNet model as a foundation to enhance the model's performance. In addition, the study also proposes reparameterization to be compatible with pre-trained weights to ensure the best algorithmic effect.
2. Text-image alignment
The main challenge in transitioning from a pre-trained class-conditional image generation model to a text-based image generation model is how to achieve precise alignment between text concepts and images. This alignment process is both time-consuming and challenging. To effectively promote this process, the study constructs a dataset consisting of high-concept-density precise text-image pairs. By using precise and information-rich data, the model is able to effectively learn more concepts in a single training iteration, while encountering significantly less ambiguity compared to the previous dataset. This strategic approach endows PixArt-α with the ability to efficiently align text descriptions with images.
3. Image aesthetic quality
In the third phase, the study fine-tuned the model, utilized high-quality aesthetic data, and increased the model's resolution, enabling it to generate high-quality images. It is worth noting that the research team observed a significant acceleration in the model's convergence speed in this phase, mainly due to the strong prior knowledge learned in the first two phases.
Simplify and Efficient T2I Transformer Architecture
PixArt-α adopts the Diffusion Transformer (DiT) as the basic architecture, as shown in Figure 4, and innovatively proposes several specialized design schemes to handle the T2I task:
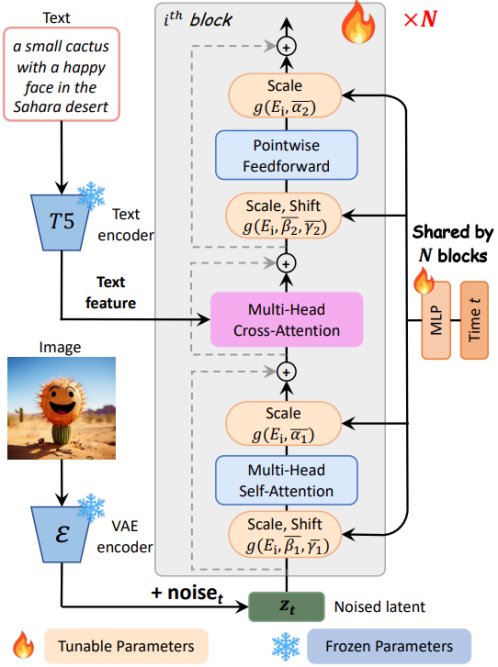
Figure 4. PixArt-α model architecture.
Cross-Attention layer The study added a multi-head cross-attention layer in the DiT module. It is located between the self-attention layer and the feed-forward layer, allowing the model to interact flexibly with text features extracted from the language model. To utilize pre-trained weights, the study initialized the output projection layer weights of the cross-attention layer to zero, effectively serving as an identity mapping to preserve the input for subsequent layers.
AdaLN-single The study found that in the adaptive layer normalization (adaLN) of DiT, the linear projection (MLP) accounted for a large portion (27%) of the parameters. The research team proposed the adaLN-single module to reduce the model's parameter count. It only uses time feature embeddings as input for independent control before noise enters the model's first layer, as shown on the right side of Figure 4, and is shared across all layers. The research team set layer-specific learnable feature embeddings for each layer, which adaptively adjust the scale and shift parameters in different layers.
Reparameterization The study proposed reparameterization techniques to maintain compatibility with pre-trained weights.
Experiments show that by integrating global MLP and hierarchical embeddings to handle time step information, and using cross-attention layers to process text information, the model's generation capability can be effectively reduced while maintaining the model's generation capability.
Data Construction: New Automated Image-Text Pair Annotation Tool
The study found a large number of simple product sample images in the LAION dataset and chose to use the SAM dataset [8], designed for diverse object segmentation, which contains rich and diverse objects, i.e., higher information/concept density, more in line with the previous discussion that high information density data can help with image-text alignment. The annotation process is shown in Figure 5.
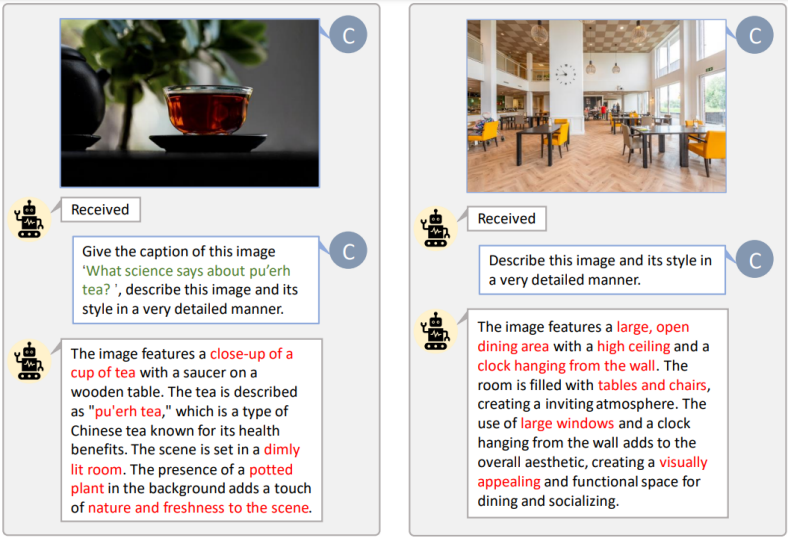
Figure 5. Custom prompt automatic annotation for LAION (left) and SAM (right). The green highlighted vocabulary in the image represents the original titles in LAION, while the red annotations are the detailed information annotated by LLaVA.
The research team conducted noun statistics on the LAION and SAM datasets, as shown in Figure 6. The noun statistics for LAION show that although the total number of different nouns is as many as 2451K, the proportion of effective nouns is only 8%, which means that more than 91% of the nouns are uncommon, which may lead to unstable model training. In contrast, the statistics for LAION-LLaVA show an increase in the proportion of effective nouns, with a significant increase in the total number of nouns and the average number of nouns per image. This indicates that the labels generated by LLaVA can cover as many objects and concepts in each image as possible. Similarly, in the actual SAM data and internal data used, all indicators show a greater improvement compared to LAION-LLaVA, demonstrating the importance of higher concept density data in training.
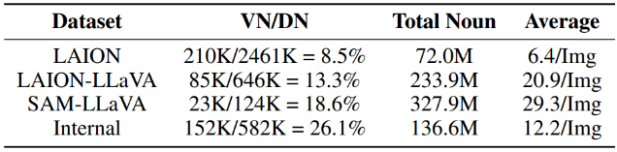
Figure 6. Noun concept statistics for different datasets. VN: Effective different noun types (appearing more than 10 times); DN: Total different noun types; Average: Average number of nouns per image.
Quantitative Metric Validation: Capability under Metrics
The study ultimately validated the capabilities of PixArt-α on three metrics: User study, T2ICompBench [9], and MSCOCO Zero-shot FID. For more evaluation results and discussions, please refer to the original paper.
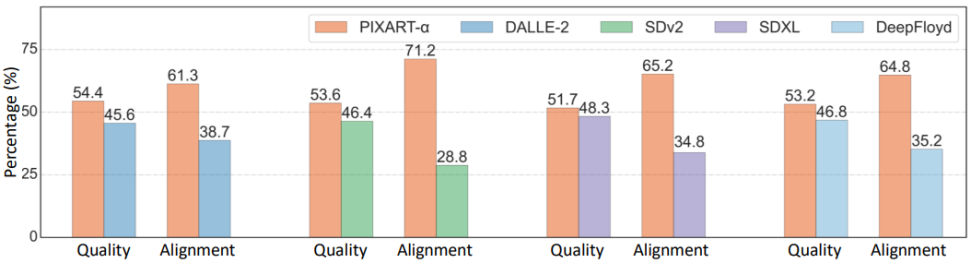
Figure 7. User experience study based on 300 fixed prompts for Ernie-vilg 2.0 [10], with the proportion values indicating the percentage of users preferring the corresponding model. PixArt-α demonstrates excellent performance in quality and alignment compared to other models.
As shown in Figure 8, in the alignment evaluation on T2I-CompBench, PixArt-α demonstrates outstanding performance in attribute binding, object relations, and complex combinations, indicating its superior combined generation capability. The best values are highlighted in blue, and the second-best values are highlighted in green. Baseline data is from T2ICompBench.
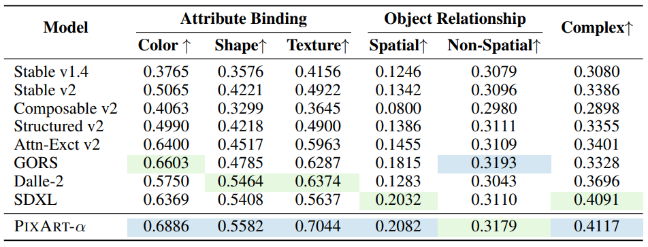
Figure 8
The study comprehensively compared PixArt-α with recent T2I models, considering several key factors: model size, total training images, COCO FID-30K score (Zero-shot), and computational cost (GPU days), as shown in Figure 9. The efficient method proposed by PixArt-α significantly reduces resource consumption, including training data usage and training time. Baseline data is from GigaGAN [11].
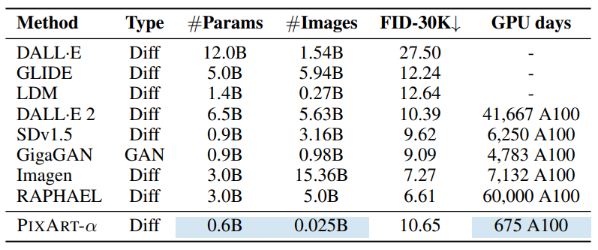
Figure 9
Visual Validation: No cherry-pick battle
The images and text used for visualization are all randomly generated in this article, without any cherry-picking.
1. Comparison with Midjourney
Comparison with Midjourney in Figure 10: The comparison uses prompts randomly sampled from the internet. To ensure a fair comparison, the research team selected the first results generated by two models for comparison.

Figure 10
2. Comparison with more text-to-image methods
Figure 11 Comparison of PixArt-α with recent representative methods such as Stable Diffusion XL [2], DeepFloyd [12], DALL-E 2 [13], ERNIE-ViLG 2.0 [10], and RAPHAEL [5]. All methods use the same prompts as in RAPHAEL, with the words that human artists want to preserve in the generated images highlighted in red. Specific prompts for each row are provided below the illustration.

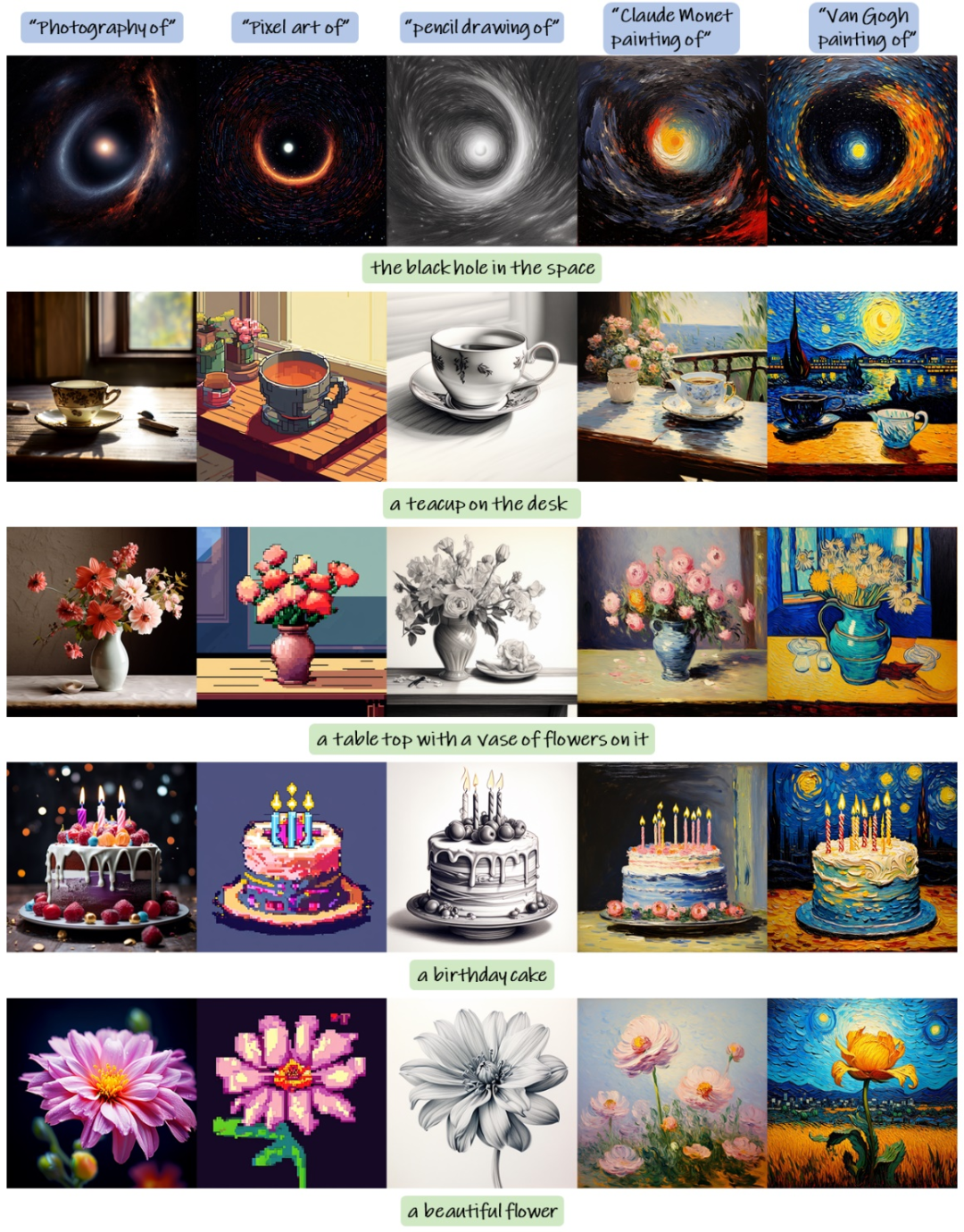
Figure 12 Prompt blending: PixArt-α is able to directly control image style through text prompts. Using style to control objects, PixArt-α generates five output samples. For example, in the second image from the left corner in the first example, the prompt used is "Pixel Art of the black hole in the space".
Method Scalability: ControlNet & Dreambooth
As shown in Figure 13, PixArt-α can be combined with Dreambooth [14]. With just a few images and text prompts, PixArt-α can generate high-fidelity images that demonstrate natural interaction with the environment (a) and precise object color modifications (b). This demonstrates PixArt-α's ability to generate high-quality images and its strong capability in custom extensions.

Figure 13
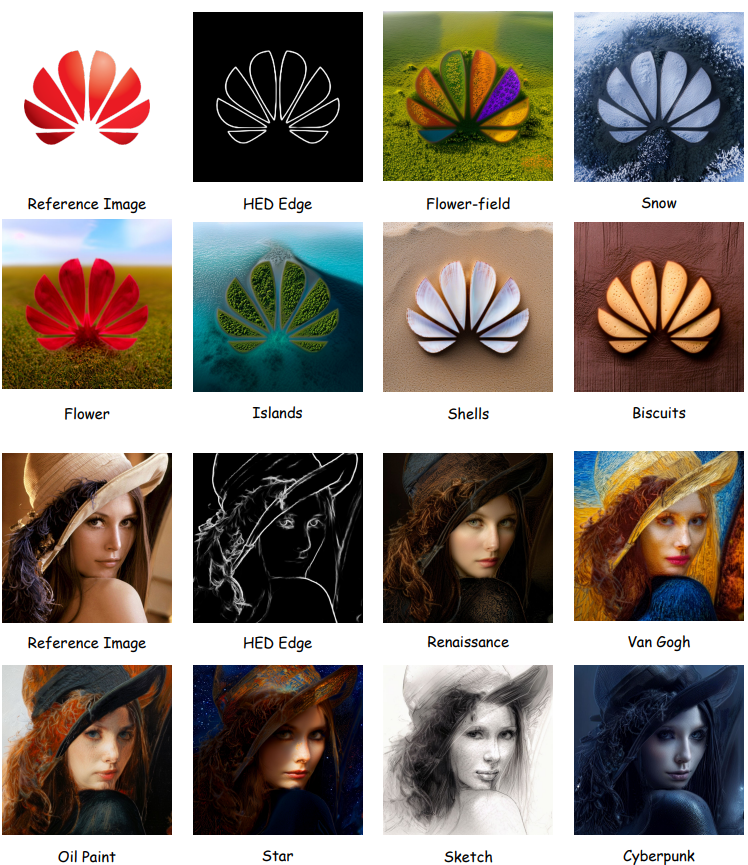
Figure 14: PixArt-α+ControlNet [15] customized samples. This study uses input images to generate corresponding HED edge images and uses them as control signals for PixArt-α ControlNet.
Summary
Overall, this study introduces PixArt-α, a Transformer-based text-to-image (T2I) diffusion model that achieves superlative image generation quality while significantly reducing training costs and carbon emissions. The three core designs of PixArt-α, including the decomposition of training strategies, efficient T2I Transformer architecture, and high-information data, all contribute to the success of PixArt-α. Through extensive experiments, the study demonstrates that PixArt-α achieves close to commercial standards in image generation quality. With these designs, PixArt-α provides a new perspective for the AIGC community and startups to build their own high-quality and low-cost T2I models. The research team hopes that this work will inspire further innovation and progress in this field.
[1] Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding. In NeurIPS, 2022.
[2] Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Muller, Joe ¨ Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis. In arXiv, 2023.
[3] Midjourney. Midjourney, 2023. URL https://www.midjourney.com.
[4] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bjorn Ommer. High-resolution image synthesis with latent diffusion models. In CVPR, 2022.
[5] Zeyue Xue, Guanglu Song, Qiushan Guo, Boxiao Liu, Zhuofan Zong, Yu Liu, and Ping Luo. Raphael: Text-to-image generation via large mixture of diffusion paths. In arXiv, 2023b.
[6] Christoph Schuhmann, Richard Vencu, Romain Beaumont, Robert Kaczmarczyk, Clayton Mullis, Aarush Katta, Theo Coombes, Jenia Jitsev, and Aran Komatsuzaki. Laion-400m: Open dataset of clip-filtered 400 million image-text pairs. In arXiv, 2021.
[7] William Peebles and Saining Xie. Scalable diffusion models with transformers. In ICCV, 2023.
[8] Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. In ICCV, 2023.
[9] Kaiyi Huang, Kaiyue Sun, Enze Xie, Zhenguo Li, and Xihui Liu. T2i-compbench: A comprehensive benchmark for open-world compositional text-to-image generation. In ICCV, 2023.
[10] Zhida Feng, Zhenyu Zhang, Xintong Yu, Yewei Fang, Lanxin Li, Xuyi Chen, Yuxiang Lu, Jiaxiang Liu, Weichong Yin, Shikun Feng, et al. Ernie-vilg 2.0: Improving text-to-image diffusion model with knowledge-enhanced mixture-of-denoising-experts. In CVPR, 2023.
[11] Minguk Kang, Jun-Yan Zhu, Richard Zhang, Jaesik Park, Eli Shechtman, Sylvain Paris, and Taesung Park. Scaling up GANs for text-to-image synthesis. In CVPR, 2023.
[12] DeepFloyd. Deepfloyd, 2023. URL https://www.deepfloyd.ai/
[13] OpenAI. DALL-E 2, 2023. URL https://openai.com/dall-e-2.
[14] Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In arXiv, 2022.
[15] Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In ICCV, 2023.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。






