Endgame of Layer2
The current Layer2 track is extremely competitive, with optimistic rollups such as Arbitrum, Optimism, and Base in the front, and ZKP rollups such as Scroll, zkSync, Starkenet, Scroll, Polygon zkEVM, Taiko, and Linea in the rear. It seems that there is a wide variety of competition in Layer2, but in fact, they all use the idea of off-chain computation and on-chain proof in engineering principles. Whether it's optimistic fraud proof or ZKP circuit proof, the core difference in engineering practice lies in the different on-chain proof methods, while the other principles are quite similar. Therefore, Optimism has chosen a special path, that is, modularizing Layer2 and decoupling various components logically. When OPstack implements the decoupling of Layer2 modules, a seemingly imaginative but logical idea is opened up, that is, ZKP on OP Stack, changing the challenger of OP Stack from Optimistic Proof to Zero Knowledge Proof. OpStack will become a universal Layer2 architecture that supports multiple proofs!
ZKP on OP Stack
The discussion all started from an RFP from Optimism, https://github.com/ethereum-optimism/ecosystem-contributions/issues/61.
Now, let me introduce the problems and development direction proposed in this RFP.
Intent: Implement zero-knowledge proofs to prove Optimism's error-proofing program (supported by the instruction set compiled by Golang compiler)
How to implement: Implementing zero-knowledge proofs (ZKP) for OP chain is a prerequisite for secure and low-latency communication between L2 and L1. A ZKP that supports the instruction set can prove Optimism's error-proofing program, including any OP Stack blockchain. In addition to proving the standard execution trace of ISA, the fault-proofing program also introduces additional requirements.
Specifically, the fault-proofing program introduces the concept of a "pre-image oracle," which uses special system calls to load external data into the program. Each fault-proofing virtual machine is responsible for implementing a mechanism, through which the hash of certain data is placed in a specific location in memory, a system call is executed, and then the pre-image of that hash is loaded into memory for the program to use. The pre-image oracle is also used to bootstrap the program using initial input. For more details, please refer to the "pre-image oracle" section in the fault-proofing program documentation.
In short, the proposal aims to leverage the highly modular nature of OP Stack to switch the error-proofing method based on optimistic proof to using zero-knowledge proofs. Furthermore, because OP currently compiles GETH into Mini Geth through MIPS, the zero-knowledge proof of OP Stack can be understood as ZKMips, which is a zero-knowledge proof based on the Mips virtual machine.
Why ZKP?
Currently, isn't OP Stack running well based on optimistic proof? Both Optimism and Arbitrum, based on optimistic proof, have gained extremely good community and developer support. Why does OP Stack still need to explore zero-knowledge proofs? The author believes there are several reasons here:
- OP Stack abstracts the modules of Layer2 highly, and introducing ZKP only means introducing a different error-proofing method, not necessarily abandoning optimistic proof. Developers using OP Stack can freely choose different proofing methods.
- Optimism and Arbitrum, based on optimistic proof, still do not support error-proofing. Essentially, OP and ARB are two single-chain systems that cannot be refuted.
- The final confirmation speed of optimistic proof, 7 days, is too slow. When ZKP Layer2 occupies the market, the significantly faster proofing speed of ZKP, up to 30 minutes, will form a significant advantage, and end users will choose the higher security of ZKP Layer2.
Therefore, it is only a matter of time before Optimism supports ZKP. A bold guess is that in the future, OP Stack will support two sets of error-proofing systems, optimistic proof and zero-knowledge proof. OP Stack is a universal Layer2 architecture that continues to iterate. To help everyone understand why OP Stack can switch between different proofing systems, the following section will detail the disassembly of OP Stack.
Core Modules of OP Stack
(This image is from Optimism's GitHub)
For OP Stack, the important modules are as follows:
- op-node
- op-geth
- op-batcher
- op-proposer
- op-program
- Cannon
- op-challenger
These modules are all independent programs and communicate through standard HTTP interfaces, which means that if developers want to modify some features of OP Stack, they only need to modify specific modules to customize their own Layer2. The following sections will specifically introduce each module of OP Stack and the overall architecture of OP Stack.
op-node
op-node is the most important module in OP Stack. On one hand, as a Sequencer, op-node contains the consensus client implementation of the blockchain, which can be compared to Lighthouse and Prysm in Ethereum, to sort the transactions submitted by users. On the other hand, as a rollup driver, op-node is responsible for deriving the Layer2 chain from the data of the L1 block.
After the Sequencer collects and sorts user transactions, op-batcher generates a batch. Before the batch is submitted to L1, in order to reduce the latency in the Rollup network, the Sequencer can generate Layer2 blocks in advance and propagate them through P2P in the Rollup network. Blocks directly generated in L2 are considered unsafe and need to wait for the batch to be submitted to L1 for derivation to be considered safe. However, under normal circumstances (no block reorganization, fraud, etc.), blocks directly generated in L2 are the same as those derived from L1. Exchanges like Binance only wait for a certain number of Layer2 blocks to consider transactions as confirmed, without waiting for the batch to be submitted to L1, indicating a very low probability of error.
The process of deriving L2 blocks is handled by the driver, which continuously tracks the synchronization process between the L1 head block and the L2 chain, obtains deposit transactions and L2 transaction data from L1, and their corresponding receipts, and generates payload attributes, which are then passed to the execution engine to calculate the L2 block. L2 blocks depend entirely on the blocks of the L1 chain, and the L2 chain extends whenever an L1 block containing an L2 batch is generated. In addition, when an L1 block is reorganized, the L2 block is also reorganized.
op-geth
op-geth is the execution client implementation of OP Stack, with minor modifications to go-ethereum to meet the needs of OP Stack. The consensus client op-node drives the execution client op-geth through the Engine API. Using payload attributes, op-geth can calculate output information and generate L2 blocks.
op-batcher
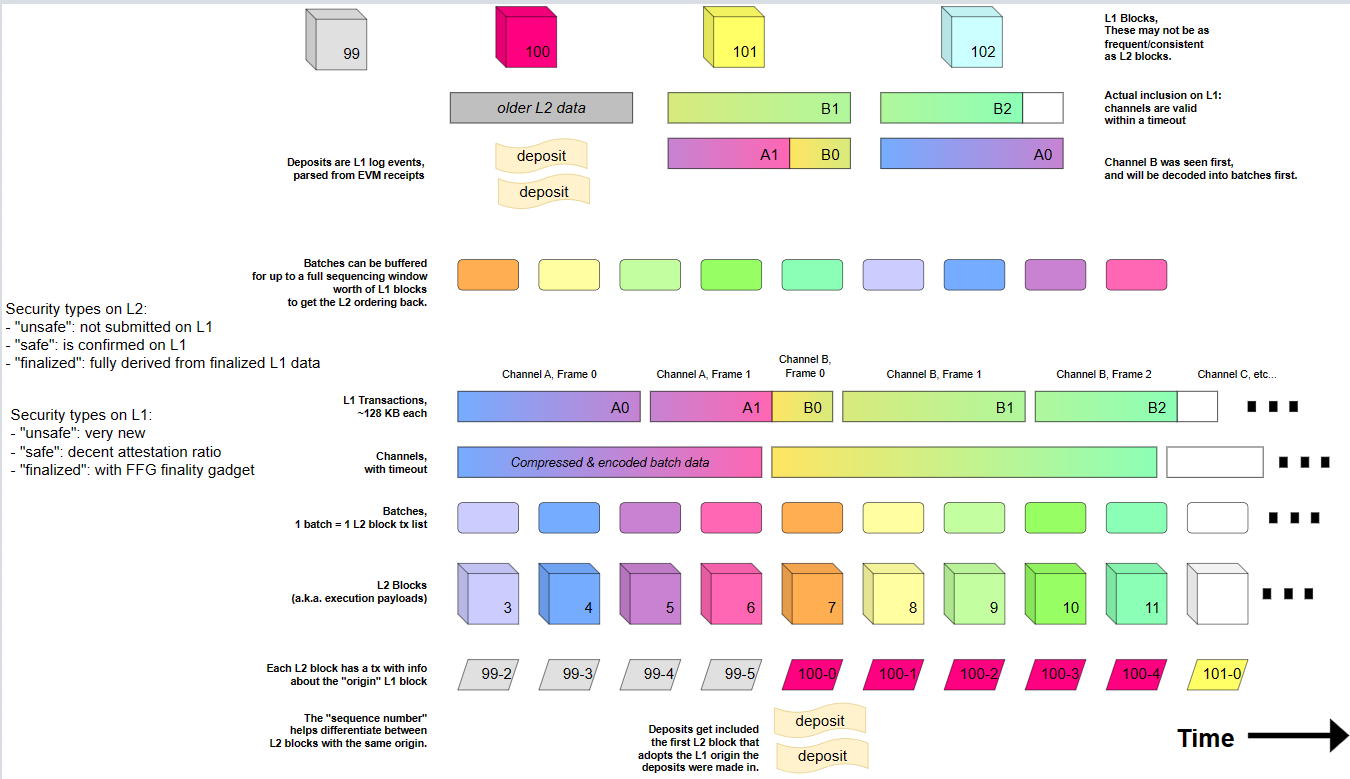
The batcher, also known as the batch submitter, mainly has two tasks. One is to compress L2 sequencer data into batches, and the other is to submit the batches to L1 for verifiers to use for verification.
The batcher submits batcher transactions to the DA layer, and the transactions contain one or more channel frames. A channel consists of a series of sequencer batches to achieve a higher compression rate. Specifically, the batcher currently uses zlib for data compression. Since the size of the channel may exceed the upper limit that a batcher transaction can accommodate, the channel is divided into one or more channel frames. A batcher transaction can include one or more channel frames (which can come from different channels).
source: Optimism
This design provides the batcher with a high degree of flexibility, and in the future, OP Stack will support the batcher to use multiple signers to submit multiple channels in parallel.
op-proposer
The op-proposer is responsible for submitting the new state commitment (currently in the form of Output Merkle Root) generated by op-geth's execution of L2 blocks to L1. The Output Root does not take effect immediately and needs to wait for the dispute period to pass before it can be considered finalized.
The above are the parts of OP Stack that have been implemented. The following content related to Fault Proof modules has not been completed and is only discussed according to the documentation specifications.
OP Fraud Proof consists of three components:
- Program: Given the commitment and dispute of Rollup Inputs (L1 Batch tx Data), it verifies the dispute statelessly (by reproducing the same calculation process using the Inputs provided by the PreImageOracle).
- VM: Given a stateless Program and Inputs, it tracks any instruction (thus it is stateful) and proves it on L1.
- Interactive Dispute Game: It divides the dispute into a single instruction and uses the VM to solve this base case.
op-program
op-program is a reference implementation of the Program, developed based on op-node and op-geth, as a stateless middleware to verify the Claim about L2 state transitions.
To verify the Claim about the L2 state, the program first applies L1 data to the finalized L2 state, reconstructing the latest L2 state. This process is similar to the work of op-node, but the difference is that op-node retrieves data from RPC, applies state changes to disk, while the Program retrieves data from the Pre Image Oracle, applies state changes to memory. The Program streams data from the Oracle and performs streaming state changes until it reaches EOF or an early termination condition. After reconstructing the L2 state, it returns the verification result based on whether the state matches the claim.
Cannon
Cannon is an implementation of the VM, which includes two main components:
- OnchainMIPS.sol: EVM implementation to verify the execution of a single MIPS instruction.
- Offchainmipsevm: Go implementation to produce a proof for any MIPS instruction to verify onchain.
Onchain, MIPS.sol implements the big-endian 32-bit MIPS instruction set, simulating the minimal subset of the Linux kernel, providing support for Go programs, but does not include system calls related to concurrency.
Offchain, mipsevm uses Go to simulate the execution process of MIPS.sol,
- It's Go code
- …that runs an EVM
- …emulating a MIPS machine
- …running compiled Go code
- …that runs an EVM
In short, Cannon on-chain is running MIPS in EVM to run MINI Geth (GETH's MIPS compilation), which is the Golang version of ETH.
op-challenger
op-challenger is responsible for handling the processes related to the dispute game.
The challenge begins by questioning the state root after executing a tx, which is then broken down into multiple instructions, each of which produces a new state, forming a sequence of S1, S2, … Sn states.
To improve efficiency, the challenging parties take turns to execute steps, divided into Attack and Defend categories.
- Attack: The previous state of the dispute is used as input, and the disputed state is expected as output. The DAG must have a commitment to the previous state.
- Defend: The disputed state is used as input, and the state after the dispute is used as output. The DAG must have a commitment to the subsequent state.
For example, assuming there are 1-9999 instructions, producing the S1-S10000 state sequence, the 5000th state is first checked. If it is the same, an attack step is taken, and a binary search to the left is initiated; if it is different, a defend step is taken, and a binary search to the right is initiated.
Ultimately, the dispute is narrowed down to the states before and after a single instruction using binary search, and then handed over to the VM to verify the state of the single instruction.
Workflow of the Modules
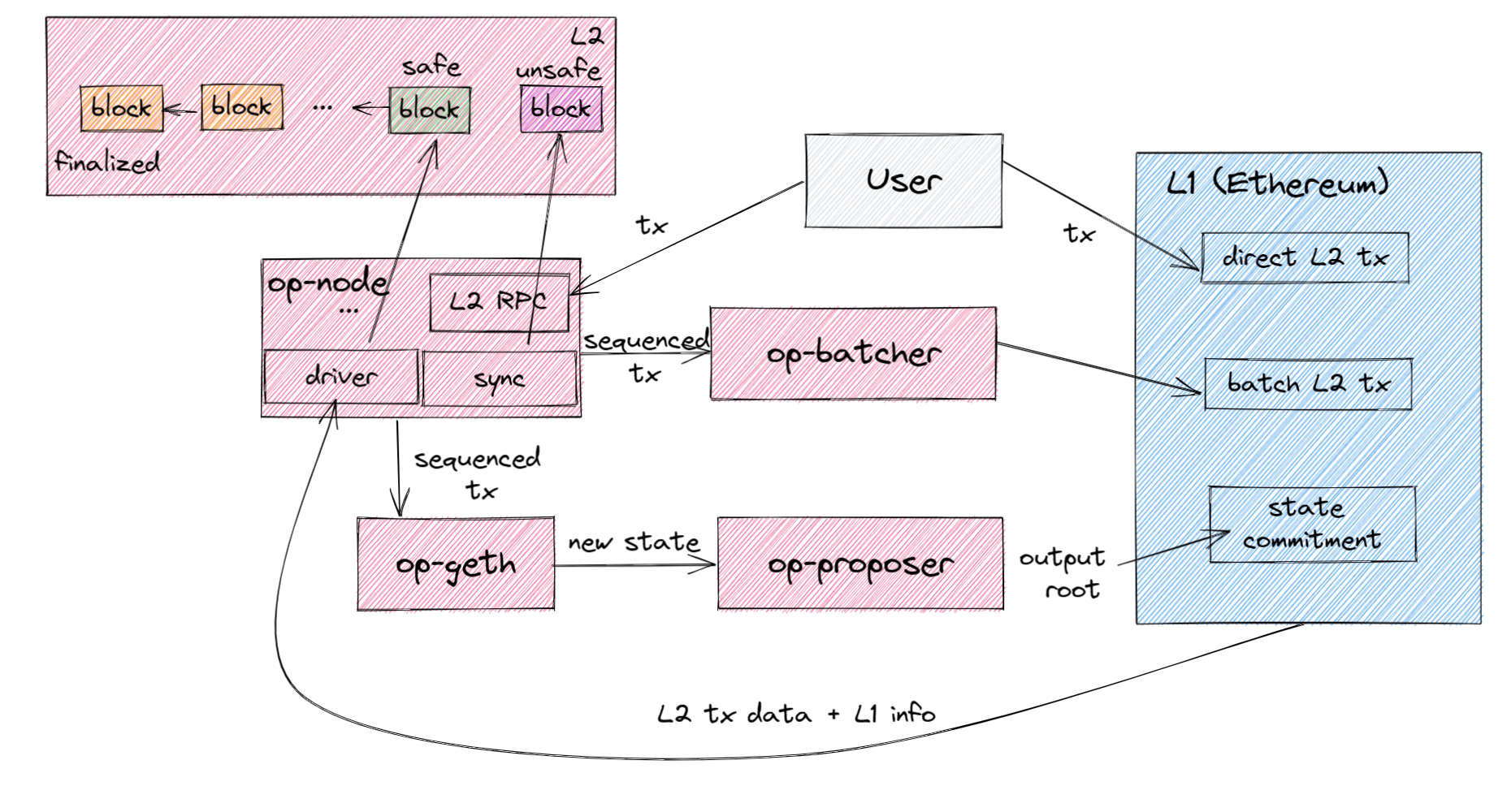
Normal Flow (Excluding Challenge)
source: Cypher Capital
- Users can submit transactions by submitting them on L2 through L2 RPC, or by submitting them directly on L1 (which can bypass op-batcher, providing stronger resistance to censorship and serving as an emergency escape mechanism).
- The RPC server started by op-node receives transactions, sorts them, and sends them to op-batcher and op-geth.
- op-batcher compresses sequenced transactions into batches and submits them to the DA layer (L1).
- op-geth executes sequenced transactions and passes the new state after execution to op-proposer.
- op-proposer sends the L2 output root as a commitment to the L2 state to be stored on L1. When the challenge period ends, the state is considered finalized.
- The driver in op-node retrieves transaction data and other information from L1, derives a canonical L2 block, and considers the L2 block derived from finalized batch tx in L1 as finalized. The L2 block derived from batch tx confirmed but not finalized in L1 is considered safe to reduce latency. L2 blocks generated directly by L2 can be propagated in advance through P2P and are considered unsafe.
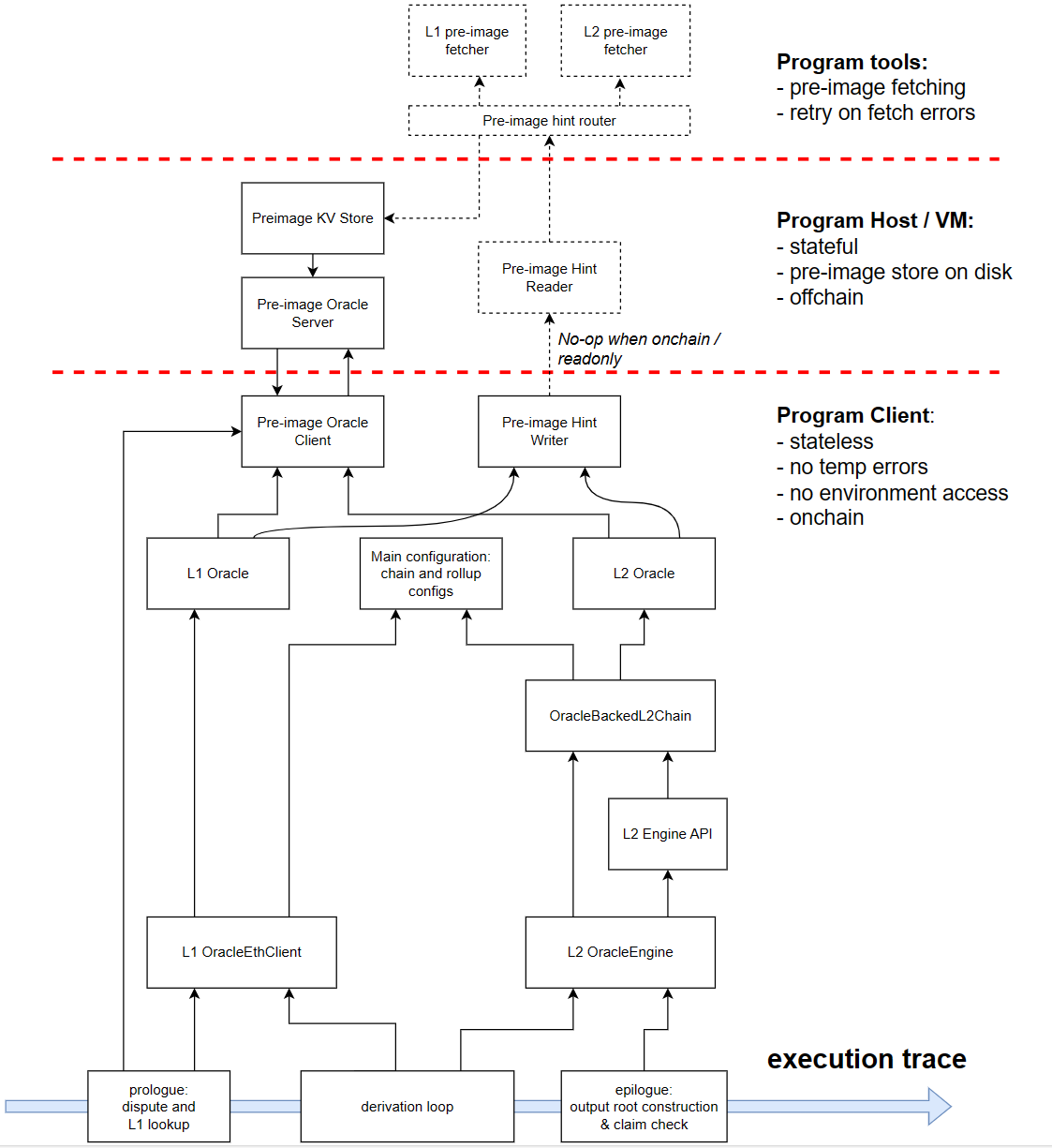
Challenge Process
source: optimism
- Users initiate the interactive dispute game.
- Cannon (VM) runs op-program on the MIPS virtual machine (written in Go) to track the state changes of each step.
- op-program reproduces the calculation process of the L2 state based on the commitment of Rollup Inputs provided by PreImageOracle, records the execution trace, and verifies the dispute statelessly.
- op-challenger uses binary search to narrow the dispute down to a single instruction.
- Cannon generates a proof for the state changes before and after executing that instruction, and verifies it on the smart contract MIPS.sol on L1.
OP Stack + ZKP
Based on the above process introduction, it is easy to see that the Challenge module has low coupling with other modules and has minimal impact on the basic transaction process. Its intervention is only required in cases of fraudulent behavior (which has not occurred since the launch of OP Mainnet in December 2021).
In order to shorten the seven-day withdrawal confirmation time of the current Optimism and provide more modular choices for OP Stack, Optimism actively embraces ZKP technology, hoping to bring ZKP that can prove the Optimism fault-proof program and support well-known ISAs to OP Stack. The solution proposed by O(1) Labs and Risc-0 team through the Foundation Mission (RFP) Application has been approved.
O(1) Labs Solution
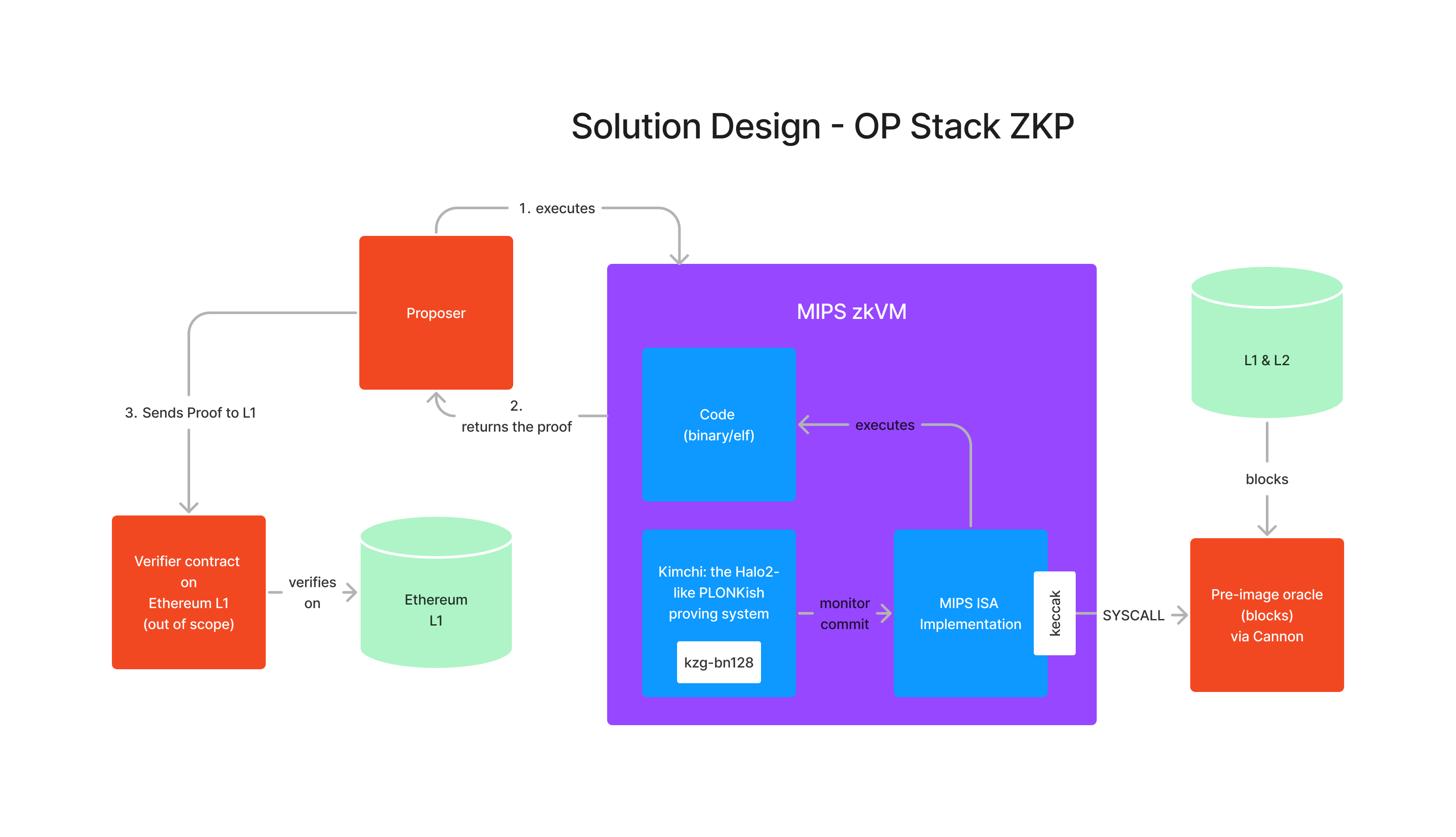
source: O(1) Labs
O(1) Labs, as the development team of Mina Protocol, plans to use Kimchi, the proof system for the MIPS VM, adopted by Mina Protocol, with only minor modifications.
Kimchi is a Halo2-like PLONKish system currently configured with an inner-product-argument style polynomial commitment scheme. It supports verifiable computation using traditional Turing-machine-based instruction sets.
The backend of Kimchi is interchangeable, and the current implementation is defined on Pasta curves using an inner-product-argument-based polynomial commitment scheme (Pasta-IPA), which is incompatible with the cryptographic system used by EVM, resulting in high verification costs on EVM. Therefore, O(1) Labs plans to change Pasta-IPA to the KZG commitment scheme using the bn128 curves (bn128-KZG), which can use the existing EVM precompile and is more efficient.
The inputs to the fault-proof MIPS system are now input into the bn128-kzg Kimchi system, and the ZK-Prove execution path. The pre-image system calls continue to use Cannon in OP Stack, and the final proof is sent to the smart contract on L1 for verification.
RISC Zero Solution
The RISC Zero team plans to use the zkVM based on the RISC-V ISA with the Groth16 backend, augmented with accelerated co-processors for common cryptographic tasks including hashing and ECDSA signature verification. They will modify the Ethereum ZK Client based on Reth to further adapt it to Optimism and implement L1-L2 derivation logic in zkVM to prove that the transaction sequence is generated by the Optimism sequencer.
The ZK Client consists of two parts: zkVM guest program and host library, similar to op-program and cannon in the O(1) Labs solution. The zkVM guest program is responsible for computing state transitions, and the host library is responsible for obtaining the data required for the state transition, coordinating the execution of the zkVM guest program, and generating the zkp for the transaction execution state transition.
O(1) Labs
RISC Zero
Performance
44B MIPS instruction-steps for an Optimism block
2B zkVM cycles for an Optimism block
Latency
2 days for an Optimism block without parallelization
10-20min for an Optimism block with parallelization
Complexity
Kimchi: 35kloc change 5-10kloc
ZKP framework: 10kloc of Rust zkVM: 54kloc of Rust
Robustness
Mina has been secured by Kimchi for 2 years.
Extensive automated testing
Security
The kzg-bn128-based EVM-friendly snark system requires a trusted setup.
The zkVM emits STARK-based proofs that require no trusted setup. On-chain verification is based on STARK->SNARK conversion.
OP Stack Compatibility
No fundamental change
No change
Exploration of ZKP Possibilities for OP Stack
Currently, a team called ZKM has implemented ZKMIPs for EVM, which translates EVM into the MIPS instruction set and provides zero-knowledge proofs. The feedback so far is that it is slow but usable. Link to the discussion
Considering the relatively mature development and experience of Mina and Risc0, we have reason to believe that OP Stack's support for ZKP is only a matter of time. However, considering that the development of ZKP for OP Stack started late and is not natively supported, the future performance is still unpredictable.
OP Stack, a Universal Architecture for Layer2
OP Stack has been adopted by many well-known teams due to its excellent code implementation, permissive open-source protocol, and modular architecture design. The only criticism is the long deterministic time of the adopted Optimistic Rollup technology, which is not as technologically advanced as ZK Rollup. Now, with the help of third-party professional teams, OP Stack has begun its attempt to move towards a ZKP future. Considering that OP Stack does not yet support Fault Proof, it is possible for OP Stack to skip the Fault Proof stage and directly use ZK Proof to achieve faster determinism and higher security.
For future Layer2 developers, OP Stack will become a universal Layer2 architecture. When developers start their own Layer2, they can flexibly choose between optimistic proofs or zero-knowledge proofs based on the security and efficiency required by the application. It is foreseeable that Layer2 based on optimistic proofs will be more cost-effective, while Layer2 based on zero-knowledge proofs will be more secure.
Reference: Building a Fault Proof System
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







