Proof of storage can enable Ethereum to emerge as an identity and asset ownership layer, rather than just a settlement layer.
Written by: LongHash Ventures
Translated by: DeepTech TechFlow
What if you lost your memory every hour and had to constantly ask others to tell you what you've done? This is the current state of smart contracts. On a blockchain like Ethereum, smart contracts cannot directly access state beyond 256 blocks. This problem is even more severe in a multi-chain ecosystem, where retrieving and verifying data across different execution layers is even more difficult.
In 2020, Vitalik Buterin and Tomasz Stanczak proposed a method for accessing data across time. While this EIP proposal has stalled, its demand has reemerged in the Roll-up-centric multi-chain world. Today, proof of storage has become a cutting-edge field, empowering smart contracts with awareness and memory.
Ways to access on-chain data
Dapps can access data and state in various ways. All of these methods require the application to trust human/entities, cryptographic economic security, or code to a certain extent, and each has its own trade-offs:
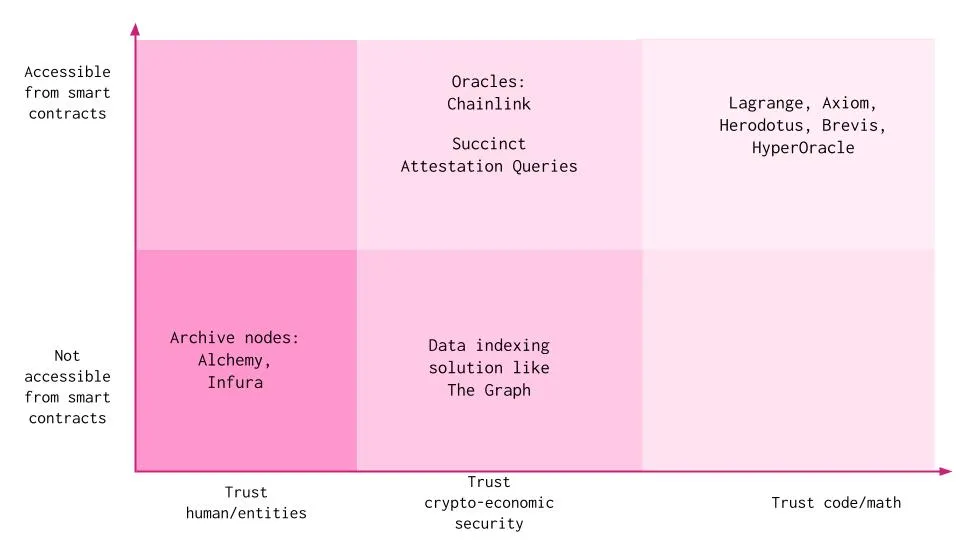
Trust in human/entities:
Archive nodes: Operators can run their own archive nodes or rely on archive node service providers like Alchemy and Infura to access all data from the genesis block. They provide the same data as full nodes, including all historical state data of the entire blockchain. Off-chain services like Etherscan and Dune Analytics use archive nodes to access on-chain data. Off-chain participants can prove the validity of this data, and on-chain smart contracts can verify that the data is signed by trusted participants/committees. However, the integrity of the underlying data cannot be verified. This method requires Dapps to trust archive node service providers to run the infrastructure correctly without any malicious intent.
Trust in cryptographic economic security:
Indexers: Indexing protocols organize all data on the blockchain, allowing developers to build and publish open APIs for applications to query. Individual indexers are nodes operated by staking tokens to provide indexing and query processing services. However, disputes may arise when the provided data is incorrect, and the arbitration process takes time. Additionally, data from indexers like The Graph cannot be directly utilized in the business logic of smart contracts but is used for web2-based data analysis.
Oracle: Oracle service providers use data aggregated from many independent node operators. The challenge here is that the data obtained from oracles may not be frequently updated and has limited scope. Oracles like Chainlink usually only maintain specific states, such as price information, and are not feasible for application-specific states and historical data. Additionally, this method also introduces a certain degree of bias in the data and requires trust in node operators.
Trust in code:
Special variables and functions: Blockchains like Ethereum have special variables and functions primarily used to provide information about the blockchain or general utility functions. Smart contracts can only access the block hash of the most recent 256 blocks. Not all block hashes are available for scalability reasons. Access to historical block hashes would be very useful as it would allow for verification proofs against them. There are no opcodes in the EVM execution environment that can access old block contents, previous transaction contents, or receipt outputs, so nodes can safely forget this content and still process new blocks. This method is also limited to a single blockchain.
Given the challenges and limitations of these solutions, there is clearly a need for explicit demand for on-chain storage and provision of block hashes. This is where proof of storage comes into play. To better understand proof of storage, let's take a quick look at data storage in the blockchain.
Data storage in the blockchain
The blockchain is a public database updated and shared among many computers in the network. Data and state are stored in a continuous series of blocks, each block referencing its parent block by storing the hash of the previous block header.
Taking Ethereum blocks as an example, Ethereum uses a special Merkle tree called the "Merkle Patricia Tree" (MPT). The Ethereum block header contains the roots of four different Merkle-Patricia trees, namely the state tree, storage tree, receipt tree, and transaction tree. These four trees encode mappings containing all Ethereum data. Merkle trees are used due to their efficiency in data storage. Through recursive hashing, only the root hash needs to be stored, saving a significant amount of space. They allow anyone to prove the existence of elements in the tree by proving recursive hash nodes leading to the same root hash. Merkle proofs allow light clients on Ethereum to answer questions such as:
Does this transaction exist in a specific block?
What is the current balance of my account?
Does this account exist?
Unlike downloading every transaction and every block, "light clients" only download block headers and use Merkle proofs to verify information. This makes the entire process very efficient. Refer to Vitalik and Maven11's research blog post for a better understanding of the implementation, advantages, and challenges related to Merkle trees. Blog link: https://vitalik.ca/general/2021/06/18/verkle.html
Proof of storage
Proof of storage allows us to use cryptographic proofs to prove that something is recorded in a database and is valid. If we can provide such proof, it is a verifiable claim that something has occurred on the blockchain.
What can proof of storage achieve?
Proof of storage allows for two main functionalities:
Access historical on-chain data beyond the last 256 blocks, all the way back to the genesis block
Access on-chain data (historical and current) on one blockchain from another blockchain, with the help of consensus verification or L2 bridging (for L2)
How does proof of storage work?
Simply put, proof of storage checks whether a specific block is part of the canonical history of the blockchain and then verifies whether the requested specific data is part of the block. This can be achieved through:
On-chain processing: Dapps can obtain the initial trusted block and pass the block as Calldata to access the previous block, traversing all the way back to the genesis block. This requires a significant amount of on-chain computation and a large amount of Calldata. Due to the massive on-chain computation required, this method is completely impractical. Aragon attempted to use an on-chain method in 2018, but it was not feasible due to the high on-chain costs.
Using zero-knowledge proofs: Similar to on-chain processing, the difference is that complex computations are moved off-chain using zero-knowledge proofs.
Accessing data on the same chain: Zero-knowledge proofs can be used to assert that any historical block header is one of the ancestors of the most recent 256 block headers accessible in the execution environment. Another method is to index the entire history of the source chain and generate zero-knowledge proofs to prove that the indexing was done correctly. This proof will be periodically updated with new blocks from the source chain.
Accessing cross-chain data: Providers collect block headers from the source chain on the target chain and use zero-knowledge consensus proofs to prove the validity of these block headers. Existing cross-chain messaging solutions such as Axelar, Celer, or LayerZero can also be used to query block headers.
Maintaining a cache of block header hashes from the source chain on the target chain, or the root hash of an off-chain block hash accumulator. This cache is periodically updated and used to efficiently prove the existence of a given block on-chain and its cryptographic linkage to the most recent block hash accessible from the state. This process is called proving chain continuity. It is also possible to use a dedicated blockchain to store all block headers from the source chain.
Based on the Dapp's request on the target chain, access historical data/blocks from off-chain indexing or on-chain caching (depending on the complexity of the request). Cached block header hashes are maintained on-chain, while actual data may be stored off-chain.
Check if specific data exists in a specified block through Merkle inclusion proofs and generate a zero-knowledge proof for this. This proof is combined with a correctly indexed zero-knowledge proof or zero-knowledge consensus proof and provided on-chain for trustless verification.
The Dapp can then verify this proof on-chain and perform the required operations using the data. In addition to verifying the zero-knowledge proof, public parameters (such as block number and block hash) are also checked against the maintained on-chain block header cache.
Projects adopting this approach include Herodotus, Lagrange, Axiom, HyperOracle, Brevis Network, and the nil Foundation. While significant efforts are being made to enable applications to have state awareness across multiple blockchains, IBC (Inter-Blockchain Communication) stands out as an interoperability standard, supporting applications to use features like ICQ (Inter-Chain Queries) and ICA (Inter-Chain Accounts) through IBC. ICQ allows applications on Chain A to query the state of Chain B by including a query in a simple IBC packet, while ICA allows one blockchain to securely control accounts on another blockchain. Combining them can support interesting cross-chain use cases. RaaS providers like Saga default to using IBC to provide these features for all application chains.
Proof of storage can be optimized in various ways to find the best balance between memory consumption, proof time, verification time, computational efficiency, and developer experience. The entire process can be roughly divided into three main sub-processes:
Data access;
Data processing;
Generation of zero-knowledge proofs for data access and processing.
Data access: In this sub-process, service providers natively access block headers from the source chain at the execution layer or through maintaining on-chain caching. For cross-chain data access, source chain consensus needs to be verified on the target chain. The methods and optimizations used include:
Existing Ethereum blockchain: The existing structure of the Ethereum blockchain can be used to prove the value of any historical storage slot relative to the current block header using zero-knowledge proofs. This can be seen as a large inclusion proof. In other words, given the most recent block header X at height b, there exists a block header Y at height b-k that is an ancestor of X. This is based on the security of Ethereum consensus and requires an efficient proof system. This is the method adopted by Lagrange.
On-chain Merkle Mountain Ranges (MMR) cache: Merkle Mountain Range can be seen as a list of Merkle trees that are combined when two trees reach the same size. Individual Merkle trees in MMR are combined by adding the parent node to the previous root of the tree. MMR is similar to Merkle trees but has some additional advantages, such as efficient appending of elements and efficient data querying, especially for reading sequential data from large datasets. Appending new headers to the Merkle tree requires passing all sibling nodes at each level. To efficiently append data, Axiom uses MMR to maintain a cache of block header hashes on-chain. Herodotus stores the root hash of the MMR block hash accumulator on-chain. This allows them to check the obtained data against these block header hashes using inclusion proofs. This method requires regular cache updates and may introduce liveness issues if not decentralized.
To optimize efficiency and computational costs, Herodotus maintains two different MMRs. The accumulator can be customized with different hash functions based on specific blockchains or layers. For proof generation on Starknet, a poseidon hash may be used, while a Keccak hash may be used for EVM chains.
Off-chain MMR cache: Herodotus maintains a cache of previous queries and results obtained off-chain to speed up data retrieval when requested again. This requires more infrastructure than just running archive nodes. Optimizations on off-chain infrastructure have the potential to reduce costs for end-users.
Dedicated blockchain for storage: Brevis relies on a dedicated zero-knowledge rollup to store all block headers of all chains for its proofs. Without this rollup, each chain would need to store block headers of every other chain, leading to O(N2) "connections" for N chains. By introducing the rollup, each blockchain only needs to store the state root of the rollup, reducing the overall connections to O(N). This layer is also used to aggregate proofs of multiple block headers/query results and submit a single verification proof on each connected blockchain.
L1-L2 messaging: Since L2 supports native messaging to update L2 contracts through L1, source chain consensus verification can be avoided. The cache can be updated on Ethereum, and L1-L2 messaging can be used to send off-chain compiled block hashes or tree roots to other L2s. Herodotus is adopting this approach, but it is not feasible for alt L1.
Data processing:
In addition to accessing data, smart contracts should also be able to perform arbitrary computations on the data. While some use cases may not require computation, it is an important value-added service for many other use cases. Many service providers support computation on data in the form of zero-knowledge proofs and provide this proof on-chain for verification of its validity. Since existing cross-chain messaging solutions such as Axelar, LayerZero, and Polyhedra Network may be used for data access, data processing may become a differentiating point for proof of storage service providers.
For example, HyperOracle allows developers to define custom off-chain computations using JavaScript. Brevis has designed an open zero-knowledge query engine marketplace, accepting data queries from Dapps and processing them using proofed block headers. Smart contracts send data queries, which are obtained by verifiers in the marketplace. Verifiers generate proofs based on the query input, relevant block headers (from the Brevis rollup layer), and results. Lagrange introduces a zero-knowledge big data tech stack for proving distributed programming models such as SQL, MapReduce, and Spark/RDD. These proofs are modular and can be generated by any block header from existing cross-chain bridging and messaging protocols. The first product of Lagrange's zero-knowledge big data tech stack is zero-knowledge MapReduce, which is a distributed computing engine for proving computation results involving a large amount of multi-chain data (based on the famous MapReduce programming model). For example, a single zero-knowledge MapReduce proof can prove liquidity changes in a DEX deployed on 4-5 chains within a specified time window. For relatively simple queries, computation can also be done directly on-chain, as currently done by Herodotus.
Proof generation:
Updatable Proofs: When it is necessary to compute and maintain proofs for moving block streams and effective contract variable proofs, updatable proofs can be used. When new blocks are created, existing proofs can be efficiently updated to maintain moving average proofs for contract variables (such as token prices) without the need to recalculate new proofs from scratch. To parallelize the computation of dynamic on-chain state data, Lagrange has built a batched vector commitment on top of MPT, called Recproof, which is updated in real-time and dynamically computed. By recursively creating Verkle trees on top of MPT, Lagrange is able to efficiently compute a large amount of dynamic on-chain state data.
Verkle Trees: Unlike Merkle trees, which require providing nodes for all shared parent nodes, Verkle trees only require the root path. This path is much smaller compared to all sibling nodes in a Merkle tree. Ethereum is also considering using Verkle trees in future versions to minimize the amount of state that full Ethereum nodes need to hold. Brevis utilizes Verkle trees to store proofed block headers and query results in the aggregation layer. This significantly reduces the size of inclusion proofs, especially when the tree contains a large number of elements, and supports efficient inclusion proofs for batched data.
Memory Pool Monitoring for Accelerated Proof Generation: Herodotus recently released turbo, which allows developers to specify data queries with a few lines of code in smart contract code. Herodotus monitors the memory pool of smart contract transactions interacting with the turbo contract. The proof generation process begins when the transaction is in the memory pool itself. Once the proof is generated and verified on-chain, the result is written to the on-chain turbo swap contract. The result can only be written to the turbo swap contract after being authenticated through storage proofs. Once this happens, a portion of the transaction fee is shared with the sequencer or block producer, incentivizing them to wait longer to collect fees. For simple data queries, the requested data may already be available on-chain before being included in a user's transaction in a block.
Applications of State/Storage Proofs
State and storage proofs can unlock many new use cases for smart contracts at the application layer, middleware, and infrastructure layers. Some of these are:
Application Layer:
Governance:
Cross-chain voting: On-chain voting protocols can allow users on Chain B to prove ownership of assets on Chain A. Users do not need to bridge their assets to gain voting rights on a new chain. For example: SnapshotX on Herodotus.
Governance token distribution: Applications can distribute more governance tokens to active users or early adopters. For example: RetroPGF on Lagrange.
Identity and Reputation:
Ownership proofs: Users can prove ownership of an NFT, SBT, or asset on Chain A to perform certain actions on Chain B. For example, a gaming application chain can decide to launch its NFT collection on other chains with existing liquidity like Ethereum or any L2. This would allow the game to leverage liquidity existing elsewhere without actually needing cross-chain NFTs.
Usage proofs: Users can receive discounts or premium features based on their historical usage on the platform (proof that the user traded X amount on Uniswap).
OG proofs: Users can prove that they have an active account that has been active for more than X days.
On-chain credit scoring: A cross-chain credit scoring platform can aggregate data from multiple accounts of an individual user to generate a credit score.
All of the above proofs can be used to provide customized experiences to users. Dapps can offer discounts or privileges to retain experienced traders or users and provide a simplified user experience for new users.
DeFi:
Cross-chain lending: Users can lock assets on Chain A and obtain loans on Chain B without the need to bridge tokens.
On-chain insurance: Fault determination can be done by accessing historical on-chain data, and insurance payouts can be fully completed on-chain.
Time-weighted average price of assets in pools: Applications can calculate and obtain the average price of assets in an AMM pool over a specified time period. For example: Uniswap TWAP Oracle on Axiom.
Option pricing: On-chain options protocols can use the volatility of assets over the past n blocks on decentralized exchanges to price options.
The last two use cases will require updating proofs when new blocks are added on the source chain.
Middleware:
Intent: Storage proofs will allow users to be more expressive and explicit about their intent. While the job of the solver is to execute the necessary steps to fulfill the user's intent, users can specify conditions more clearly based on on-chain data and parameters. The solver can also prove the validity of on-chain data used to find the best solution.
Account abstraction: Users can set rules based on data from other chains using storage proofs. For example, every wallet has a nonce. We can prove that a year ago the nonce was a specific number, and currently it is the same. This can be used to prove that the wallet has not been used at all, and then access to the wallet can be delegated to another wallet.
On-chain automation: Smart contracts can automatically execute certain operations based on pre-defined conditions that rely on on-chain data. Automation programs need to call smart contracts regularly to maintain optimal price flows for AMMs or to maintain the health of lending protocols by avoiding bad debts. HyperOracle supports automation as well as on-chain data access.
Infrastructure:
Trustless on-chain oracles: Decentralized oracle networks aggregate responses from individual oracle nodes within the oracle network. The oracle network can eliminate this redundancy and utilize cryptographic security to achieve on-chain data. The oracle network can aggregate data from multiple chains (L1, L2, and alt L1) onto a single chain and simply prove the existence of data elsewhere using storage proofs. Major DeFi solutions making significant progress can also use custom solutions. For example, the largest staking provider Lido Finance has partnered with Nil Foundation to fund the development of zkOracle. These solutions will enable trustless data access to EVM historical data and protect the $15 billion in staked Ethereum liquidity of Lido Finance.
Cross-chain messaging protocols: Existing cross-chain messaging solutions can increase the expressiveness of their messages by collaborating with storage proof service providers. This is a method proposed by Lagrange in its modular paper.
Conclusion
Awareness allows tech companies to better serve their customers. From user identity to purchasing behavior to social relationships, tech companies leverage awareness to unlock features such as precise targeting, customer segmentation, and viral marketing. Traditional tech companies require explicit permission from users and must handle user data with caution. However, on permissioned blockchains, all user data is public and may not necessarily reveal user identities. Smart contracts should be able to leverage publicly available data to better serve users. The development and adoption of a more professional ecosystem will make cross-time and cross-chain state awareness an increasingly important issue. Storage proofs can enable Ethereum to emerge as an identity and asset ownership layer, not just a settlement layer. Users can maintain their identity and key assets on Ethereum, which can be used across multiple blockchains without the need to bridge assets constantly. We are excited about the new possibilities and use cases that will be unlocked in the future.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







