Source: New Wisdom Element
Summary: Stanford scholars have found that GPT-4's review comments on papers from Nature and ICLR have over 50% similarity with those of human reviewers. It seems that having large models help us review papers is not just a fantasy.
GPT-4 has successfully become a reviewer!
Recently, researchers from institutions such as Stanford University threw thousands of top conference papers from Nature, ICLR, etc., to GPT-4, asking it to generate review comments, modification suggestions, and then compared them with those given by human reviewers.

Paper link: https://arxiv.org/abs/2310.01783
As a result, GPT-4 not only performed this task perfectly, but even better than humans!

In its comments, over 50% were consistent with at least one human reviewer.
Moreover, over 82.4% of the authors stated that the feedback from GPT-4 was quite helpful.

Paper author James Zou concluded: "We still need high-quality human feedback, but LLM can help authors improve their paper drafts before formal peer review."
GPT-4's feedback may be better than that of humans
So, how do you get LLM to review your paper?
It's very simple, just extract the text from the paper PDF, feed it to GPT-4, and it will immediately generate feedback.
Specifically, we need to extract and parse the title, abstract, figures, table titles, and main text from a PDF of the paper.
Then tell GPT-4 that you need to follow the review feedback format of top journals and conferences in the industry, including four parts—whether the results are important, whether they are novel, reasons for paper acceptance, reasons for paper rejection, and improvement suggestions.

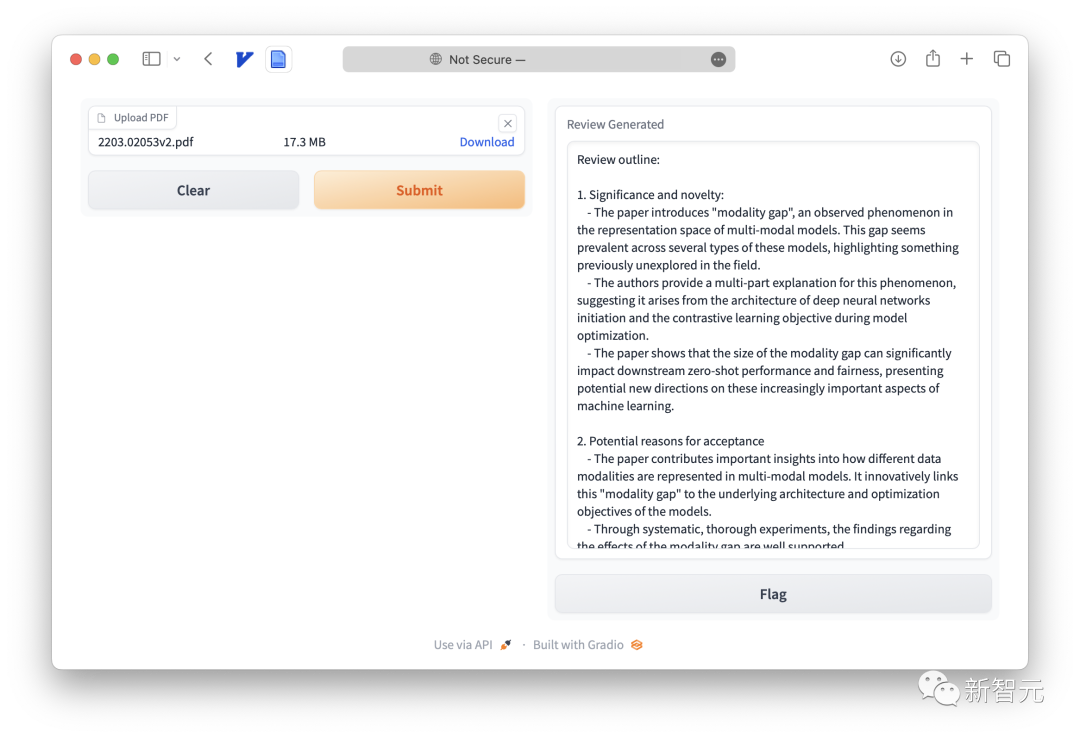
From the figure below, GPT-4 provided very constructive feedback, including four parts.
What are the shortcomings of this paper?
GPT-4 pointed out directly: Although the paper mentions the phenomenon of modal gap, it does not propose a method to narrow the gap, nor does it prove the benefits of doing so.

Researchers compared human feedback and LLM feedback on 3,096 Nature series papers and 1,709 ICLR papers.
The two-stage comment matching pipeline will extract comment points from LLM and human feedback separately, and then perform semantic text matching to match common comment points between LLM and human feedback.
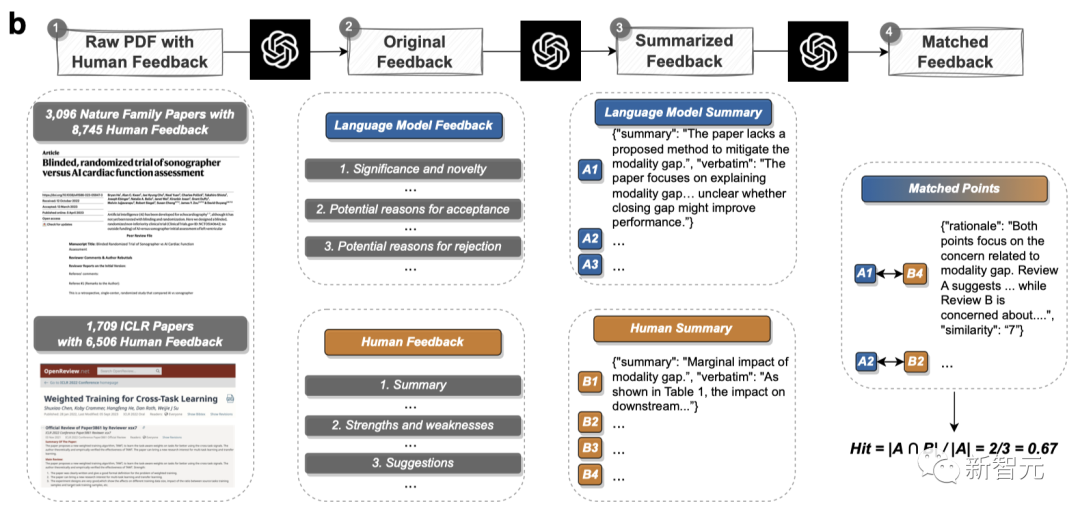
The figure below shows a specific two-stage comment matching pipeline.
For each paired comment, a similarity rating will be given.
The researchers set the similarity threshold to 7, and weakly matched comments will be filtered out.
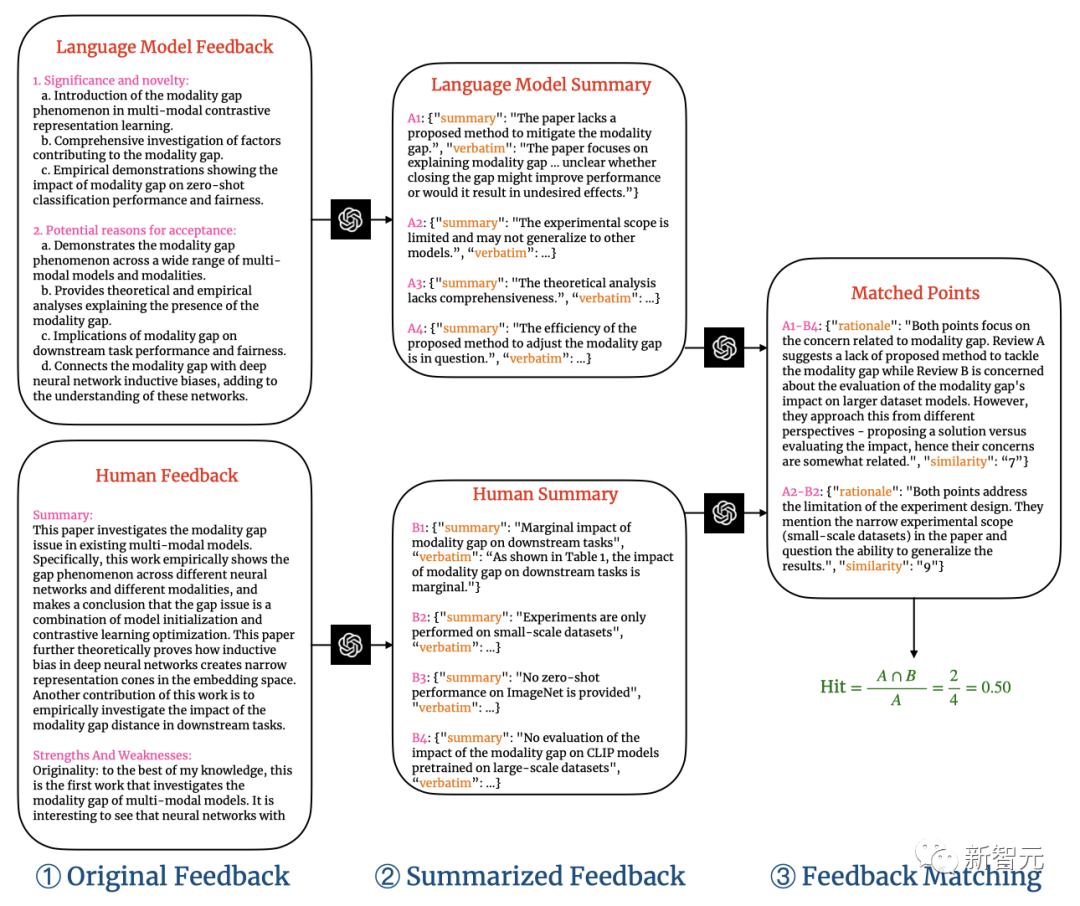
In the Nature and ICLR datasets, the average token lengths of papers and human comments are as follows.

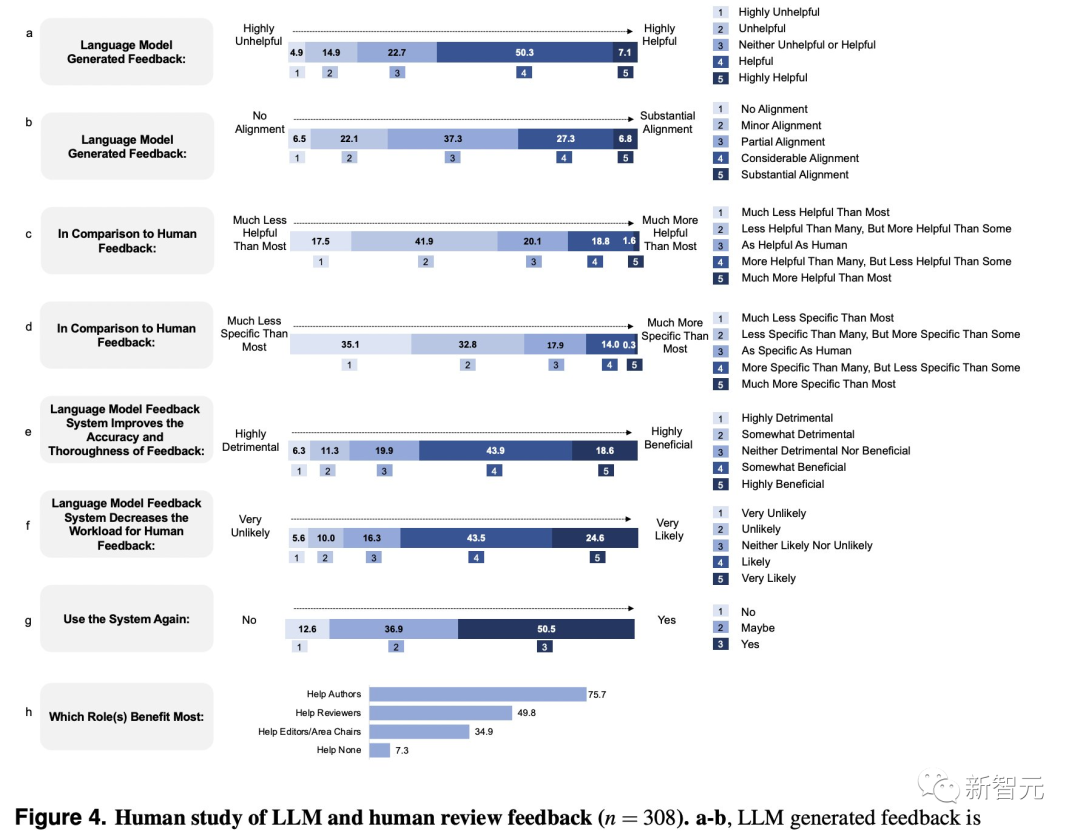
This study involved 308 researchers from 110 AI institutions and computational biology institutions in the United States.
Each researcher uploaded their own paper, reviewed LLM feedback, and then filled out their evaluation and feelings about the LLM feedback.
The results showed that researchers generally believe that the feedback generated by LLM has a significant overlap with human review results and is usually very helpful.
If there are any shortcomings, it is slightly less specific.

As shown in the figure below, for papers submitted to Nature, approximately one-third (30.85%) of GPT-4's feedback coincides with human reviewer feedback.
In ICLR papers, over one-third (39.23%) of GPT-4's feedback coincides with human reviewer feedback.
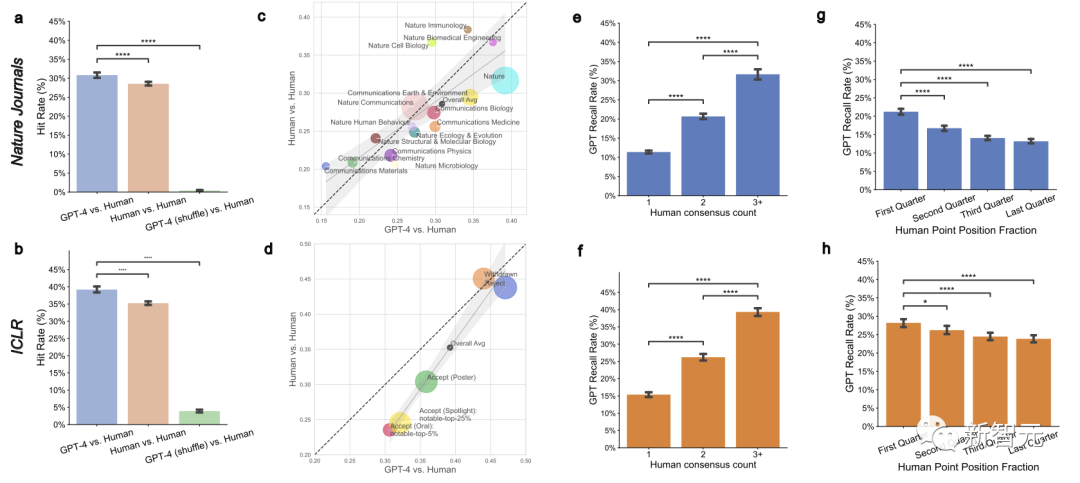
LLM vs. human reviewers, slightly different emphasis
Below are the LLM comments and human comments on the same ICLR paper, showing that LLM's perspective is very incisive and the comments are very to the point.

For example, in comparison with previous research, human reviewers stated:
The comparison is flawed. Especially, the label consistency and center consistency loss of the GNN method were not considered. A fairer comparison should use GNN methods that consider both losses.
While GPT-4's evaluation is:
The paper lacks a thorough comparison with existing methods. Although the authors compared some methods as baselines, a more comprehensive comparison is still needed.

On the reliability of the theory, human reviewers provided the following comments—
To be frank, the theoretical proof is too trivial. The ultimate conclusion is that if the similarity is appropriate, the predicted action is accurate. Since the model is learning the correct similarity, it is equivalent to saying that if the model h is well trained, the output is correct. This is obvious.
GPT-4's opinion, on the other hand, is:
The authors should provide more theoretical analysis to compare the connection between information transmission and consistency constraints, which would make it easier for readers to understand.

In terms of the reproducibility of the research, human reviewers hope that the paper can provide code so that other readers can also reproduce the experiments.
GPT-4 also expressed the same opinion: "The authors should provide more detailed information about the experimental setup to ensure the reproducibility of the research."


The users involved in the survey generally believe that LLM feedback can help improve the accuracy of reviews and reduce the workload of human reviewers. Most users also intend to use the LLM feedback system again.
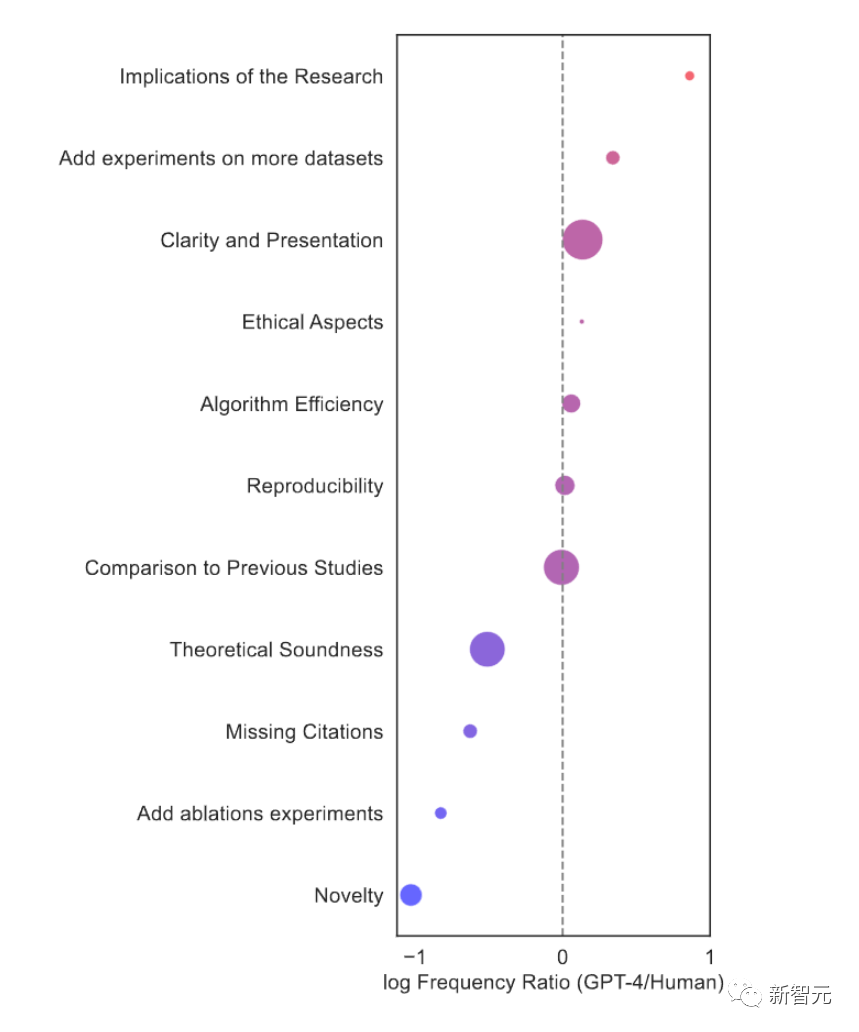
Interestingly, compared to human reviewers, LLM reviewers have their own unique characteristics.
For example, it mentions the frequency of impact factors, which is 7.27 times that of human reviewers.
Human reviewers are more likely to request additional ablation experiments, while LLM tends to focus on conducting experiments on more datasets.
Netizens have expressed their admiration for this work!
Some have said, "Actually, I've been doing this for a long time. I've been using various LLMs to help me summarize and improve papers."
Someone asked, "So, will GPT reviewers be biased to cater to today's peer review standards?"
Others have raised the question, "Is the metric of quantifying the overlap between GPT and human review opinions useful?"
It should be noted that ideally, reviewers should not have too many overlapping opinions, as the original intention of selecting them is to provide different perspectives.
At the very least, this study has shown us that LLM can indeed be used as a tool to improve papers.
Three Steps to Get LLM to Review Your Paper
- Create a PDF parsing server and run it in the background:
conda env create -f conda_environment.yml
conda activate ScienceBeam
python -m sciencebeam_parser.service.server --port=8080 # Make sure this is running in the background
- Create and run the LLM feedback server:
conda create -n llm python=3.10
conda activate llm
pip install -r requirements.txt
cat YOUR_OPENAI_API_KEY > key.txt # Replace YOUR_OPENAI_API_KEY with your OpenAI API key starting with "sk-"
python main.py
- Open a web browser and upload your paper:
Open http://0.0.0.0:7799 and upload your paper to receive feedback generated by LLM in approximately 120 seconds.
Author Information
Weixin Liang

Weixin Liang is a Ph.D. student in the Computer Science Department at Stanford University and a member of the Stanford Artificial Intelligence Lab (SAIL), under the guidance of Professor James Zou.
Prior to this, he obtained a Master's degree in Electrical Engineering from Stanford University, under the supervision of Professor James Zou and Professor Zhou Yu; and a Bachelor's degree in Computer Science from Zhejiang University, under the supervision of Professor Kai Bu and Professor Mingli Song.
He has interned at Amazon Alexa AI, Apple, and Tencent, and has collaborated with Professor Daniel Jurafsky, Professor Daniel A. McFarland, and Professor Serena Yeung.
Yuhui Zhang

Yuhui Zhang is a Ph.D. student in the Computer Science Department at Stanford University, under the guidance of Professor Serena Yeung.
His research focuses on building multimodal artificial intelligence systems and developing creative applications that benefit from multimodal information.
Prior to this, he completed his undergraduate and master's studies at Tsinghua University and Stanford University, and has collaborated with outstanding researchers such as Professor James Zou, Professor Chris Manning, and Professor Jure Leskovec.
Hancheng Cao

Hancheng Cao is a sixth-year Ph.D. student in the Computer Science Department at Stanford University (with a minor in Management Science and Engineering), and a member of the NLP group and the Human-Computer Interaction group at Stanford University, under the guidance of Professor Dan McFarland and Professor Michael Bernstein.
He graduated with honors from the Department of Electronic Engineering at Tsinghua University in 2018.
Starting in 2015, he served as a research assistant at Tsinghua University, under the supervision of Professor Yong Li and Professor Vassilis Kostakos (University of Melbourne). In the fall of 2016, he worked under the guidance of Distinguished University Professor Hanan Samet at the University of Maryland. In the summer of 2017, he worked as an exchange student and research assistant in the Human Dynamics group at the MIT Media Lab, under the guidance of Professor Alex 'Sandy' Pentland and Professor Xiaowen Dong.
His research interests include computational social science, social computing, and data science.
References:
https://arxiv.org/abs/2310.01783
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。








