Source: AIGC Open Community

Image Source: Generated by Wujie AI
Alibaba Cloud officially open-sourced the Qwen-14B and Qwen-14B-Chat models, which can automatically generate text/code, summarize text, translate, and analyze code through text-based question-answering.
It is reported that Qwen-14B is stably pre-trained on 3 trillion high-quality tokens, allowing commercialization, and supports a maximum context window length of 8k. It has surpassed equivalent-scale models in multiple authoritative evaluations, with some indicators comparable to Llama2-70B.
Not long ago, Alibaba Cloud open-sourced the Qwen-7B series models, and the download volume exceeded 1 million in just over a month, becoming one of the most powerful open-source large Chinese models. This time, Qwen-14B has been comprehensively enhanced in training data, parameters, etc., helping enterprises and individual developers to create exclusive generative AI assistants.

Modelscope Links: Qwen-14B-Chat, Qwen-14B
HuggingFace Links: Qwen-14B, Qwen-14B-Chat
Github Link: Qwen
Free Online Experience: Qwen-14B-Chat-Demo
Paper: QWENTECHNICALREPORT.pdf
Highlights of Qwen-14B Technical Features
High-quality training data: Qwen-14 uses over 3 trillion tokens of data for pre-training, including high-quality Chinese, English, multilingual, code, mathematics, etc., covering general and professional training corpora. At the same time, the pre-training corpus distribution has been optimized through a large number of comparative experiments.
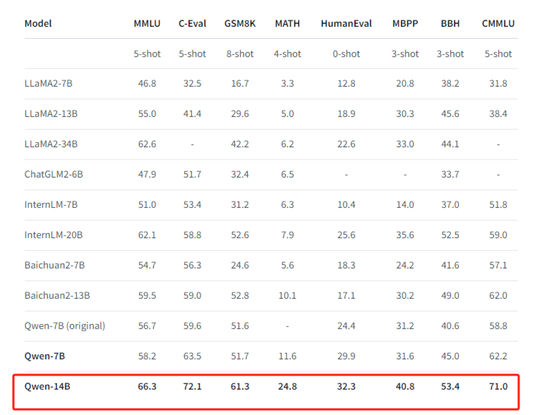
Powerful performance: Qwen-14B significantly surpasses equivalent-scale open-source models in multiple downstream evaluation tasks in both Chinese and English, covering common sense reasoning, code, mathematics, translation, etc., and even has strong competitiveness in some indicators compared to larger models.
More comprehensive vocabulary coverage: Compared to currently predominant open-source models with mainly Chinese and English vocabularies, Qwen-14B uses a vocabulary of approximately 150,000 tokens. This vocabulary is more friendly to multilingualism, facilitating the enhancement and expansion of capabilities for some languages without expanding the vocabulary.
Performance Evaluation
Qwen-14B selected popular evaluation platforms such as MMLU, C-Eval, GSM8K, MATH, HumanEval, MBPP, BBH, CMMLU, etc., to comprehensively evaluate the model's knowledge capabilities in Chinese and English, translation, mathematical reasoning, code, etc.
Qwen-14B achieved the best performance among equivalent open-source models in all evaluation platforms.
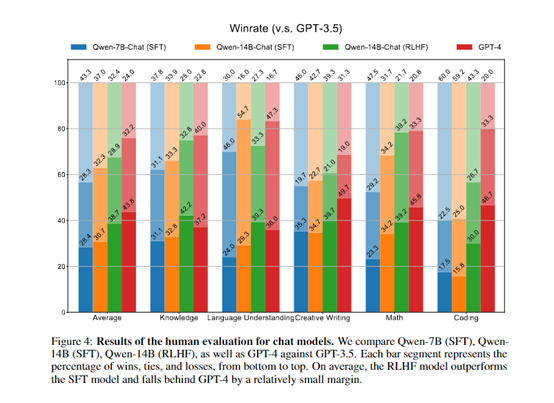
In addition, Alibaba Cloud provides evaluation scripts (link) to facilitate the reproduction of model effects. Note: Minor fluctuations in reproduction results due to hardware and framework-induced rounding errors are considered normal.
Qwen-14B Model Technical Details
In the implementation of positional encoding, FFN activation function, and normalization, Alibaba Cloud adopts the currently most popular practices, namely RoPE relative positional encoding, SwiGLU activation function, RMSNorm (optional installation of flash-attention acceleration).
In terms of tokenizers, compared to currently predominant open-source models with mainly Chinese and English vocabularies, Qwen-14B uses a vocabulary of over 150,000 tokens.
Based on the BPE vocabulary cl100k_base used by GPT-4, this vocabulary has been optimized for Chinese and multilingualism. It is more friendly to some languages, facilitating the enhancement of capabilities for some languages without expanding the vocabulary. The vocabulary splits numbers into single-digit units and uses the efficient tiktoken tokenizer for tokenization.
Alibaba Cloud randomly selected 1 million document corpora for some languages to compare the encoding compression ratio of different models (with the support for 100 languages of XLM-R as the baseline value 1, the lower the better).
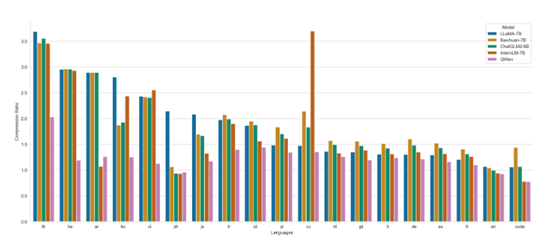
It can be seen that while maintaining efficient decoding of Chinese, English, and code, Qwen-14B has achieved a high compression ratio for languages that are widely used by some user groups (Thai th, Hebrew he, Arabic ar, Korean ko, Vietnamese vi, Japanese ja, Turkish tr, Indonesian id, Polish pl, Russian ru, Dutch nl, Portuguese pt, Italian it, German de, Spanish es, French fr, etc.), making the model also highly scalable and efficient in training and inference for these languages.
In terms of pre-training data, the Qwen-14B model utilizes some open-source general corpora and accumulates a massive amount of web-wide corpora and high-quality textual content. After deduplication and filtering, the corpus exceeds 3 trillion tokens, covering texts from the entire web, encyclopedias, books, code, mathematics, and various vertical fields.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。






