Original Title: Blockchain Interoperability Part III: Storage Proofs, Powering new cross-chain usecases
Author: Jacob, Superscrypt
Translation: bayemon.eth, ChainCatcher
In the second part about interoperability, we discussed how consensus proofs as a new trust-minimized method can facilitate bridging between blockchains.
In this article, we will explore storage proofs, which adopt the concept of trust-minimized verification and extend it to historical transaction records on the blockchain. By verifying historical transactions and user activities through storage proofs, a wide range of cross-chain use cases can be unlocked.
In the second part, we introduced consensus proofs, a trust-minimized method for bridging funds across blockchains. As bridging users typically want transactions to be completed instantly without delay, consensus proofs are highly effective. This is because they can continuously check the latest state of the blockchain during the process of continuous synchronization.
The concept of "trust-minimized bridging" can also be applied in reverse, i.e., retracing history using zero-knowledge proofs to verify transactions and data in old blocks. These "historical storage proofs" can enable a variety of different cross-chain use cases. In this article, we will introduce the definition, principles, and use cases of storage proofs.
Retrieving Historical Data
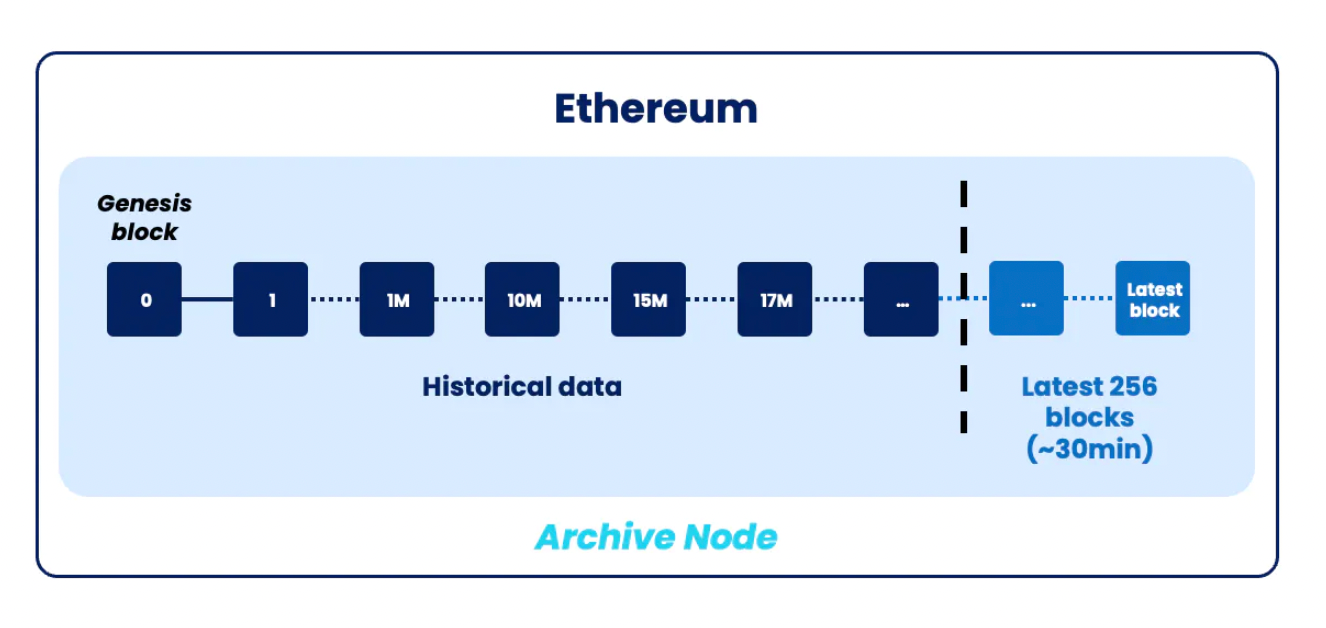
Blockchain historical data serves various purposes. It can prove asset ownership, record user behavior and transaction history, and then input it into on-chain smart contracts or applications. As of now, over 18 million blocks have been written to Ethereum. However, smart contracts can only access the latest 256 blocks (or data from the last approximately 30 minutes), so "historical data" refers to information beyond the last 256 blocks.
Today, to access historical data, protocols typically query archive node providers, such as Infura, Alchemy, or other indexers. This means trusting and relying on them and their data.
Historical Data
However, with the use of storage proofs, data retrieval can be completed with a relatively lower level of trust.
Storage proofs are zero-knowledge proofs that can verify historical data stored on the blockchain. More specifically, "storage proofs" can be used to prove the existence of a specific state in a past block. The key feature is that it does not require trust in third parties or oracles, but embeds trust within the storage proof itself.
How do storage proofs help verify that certain data exists in earlier historical blocks? This involves a two-step verification:
- Step 1: Check if a specific block indeed exists in the chain's historical records, for example, if the block is a valid part of the source chain's history
- Step 2: Check if specific data is part of the block, i.e., if specific transactions or information are part of that block (this verification can be completed through Merkle inclusion proofs)
Upon completion of the proof by the recipient (such as a smart contract on the destination chain), trust in the validity of the data is established, enabling the execution of corresponding instructions. This concept can be further extended: verified data can be used to run additional off-chain computations, and then generate another zero-knowledge proof to prove the data and computation.
In summary, storage proofs allow for the retrieval of historical on-chain data in a trust-minimized manner. This is crucial because, as outlined in the first part, we believe that in the coming years, Web3 will become more multi-chain and multi-layer. The emergence of various Layer1 solutions, rollups, and application chains means that user activities on-chain may occur across multiple chains simultaneously. This further emphasizes the need for trust-minimized interoperability solutions that can maintain the composability of user assets, identities, and transaction histories across multiple domains. This is the problem that storage proofs can help solve.
Use Cases of Storage Proofs
Storage proofs enable smart contracts to check any historical transactions or data as a prerequisite, providing great flexibility for designing cross-chain applications.
First, storage proofs can prove any historical data on the source blockchain, such as:
- Account balances and token ownership
- User transaction activities
- Historical prices of assets traded within a specified time
- Real-time asset balances in liquidity pools on different chains
Second, storage proofs can be sent to the destination chain, unlocking various cross-chain use cases:
- Allowing users to vote on governance proposals on L2 at a lower cost
- Allowing NFT holders to mint NFTs and receive community benefits on a new chain
- Rewarding users based on their historical interactions with a specific dApp (e.g., airdrops)
- Providing interest rate loans based on a user's comprehensive transaction and credit history
- Recovering dormant accounts
- Calculating historical TWAP for future transactions
- Calculating more accurate AMM transaction prices based on liquidity pools on multiple chains
Essentially, storage proofs allow applications to query and port user on-chain activities and history across multiple chains to provide information for smart contracts or applications on another chain.

Storage Proofs - Use Cases
Below, we explain the mechanism of storage proofs through a more detailed example.
Detailed Explanation of Storage Proof Mechanism Use Case
Let's assume "X" is a DeFi protocol using tokens on Ethereum. X will propose a governance proposal, and the project team wants to publish it on a lower-cost chain to facilitate user voting. Users are only eligible to vote if they hold X tokens on Ethereum at a specific time (i.e., a snapshot, such as block #17,000,000).
How is it currently implemented?
The current method involves querying archive nodes to obtain a complete list of token holders meeting the requirements in block #17,000,000. Subsequently, the DAO administrator stores this list in a smart contract on the destination chain to determine the final eligible voting list. However, this method has some limitations:
- The list of voters may be very large, and it changes with each snapshot, making the on-chain storage and update costs for each voting proposal high
- Implicit trust in archive node providers and the data they provide
- Ensuring that the members managing the DAO do not tamper with the voting list
How does storage proof work?
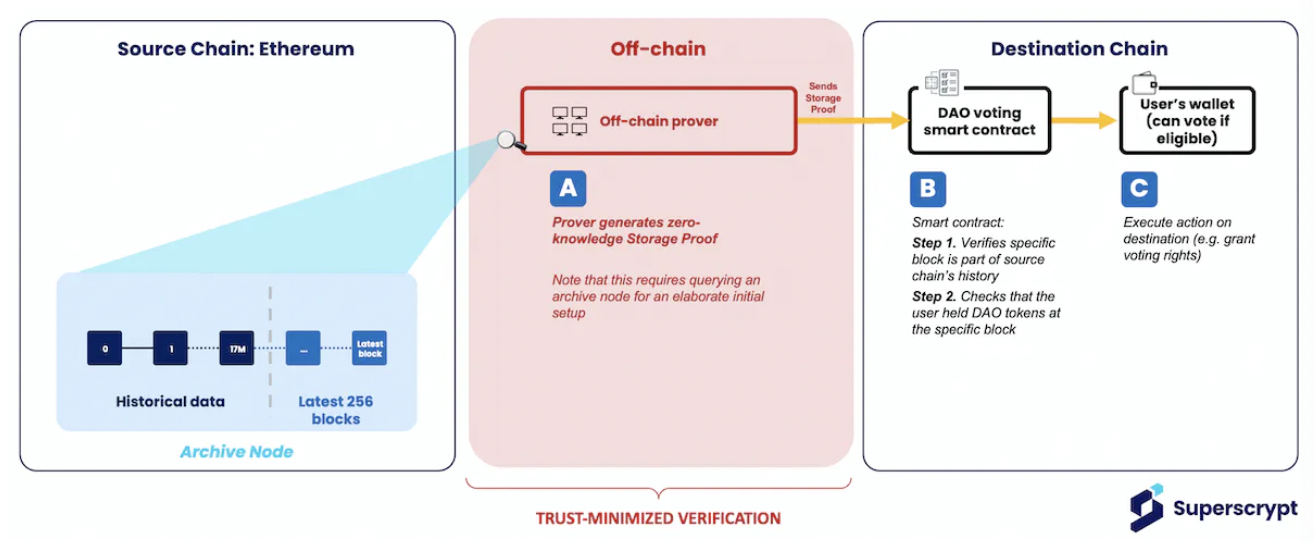
As explained in the second part, expensive computations can be handed over to an off-chain zero-knowledge proof generator.
The zk verifier will generate a succinct proof and send it to the destination chain for verification. Using the example of DAO voting eligibility:
- The prover generates a zero-knowledge proof that block #17,000,000 is part of Ethereum's history (as in Step 1 above).
- After proving the validity of the block, we can use Merkle inclusion proofs to prove that the user held DAO tokens at the finalization of that block (as in Step 2 above).
Historical data proof enabling cross-chain voting
Subsequently, the proof is sent to a smart contract on the destination chain for verification. If successful, the smart contract on L2 grants the user voting rights.
There are several advantages to using storage proofs, as their existence eliminates the need for:
- Trust in archive node providers
- Protocols to maintain expensive on-chain voter lists
- Users to move their assets to the destination chain
Setup Required for Storage Proofs
So far, we have abstracted some complexities of storage proofs. However, using storage proofs requires careful initial setup by service providers to ensure that storage proofs can be used without trusting the provider. As part of this process, two things will be generated and stored on-chain:
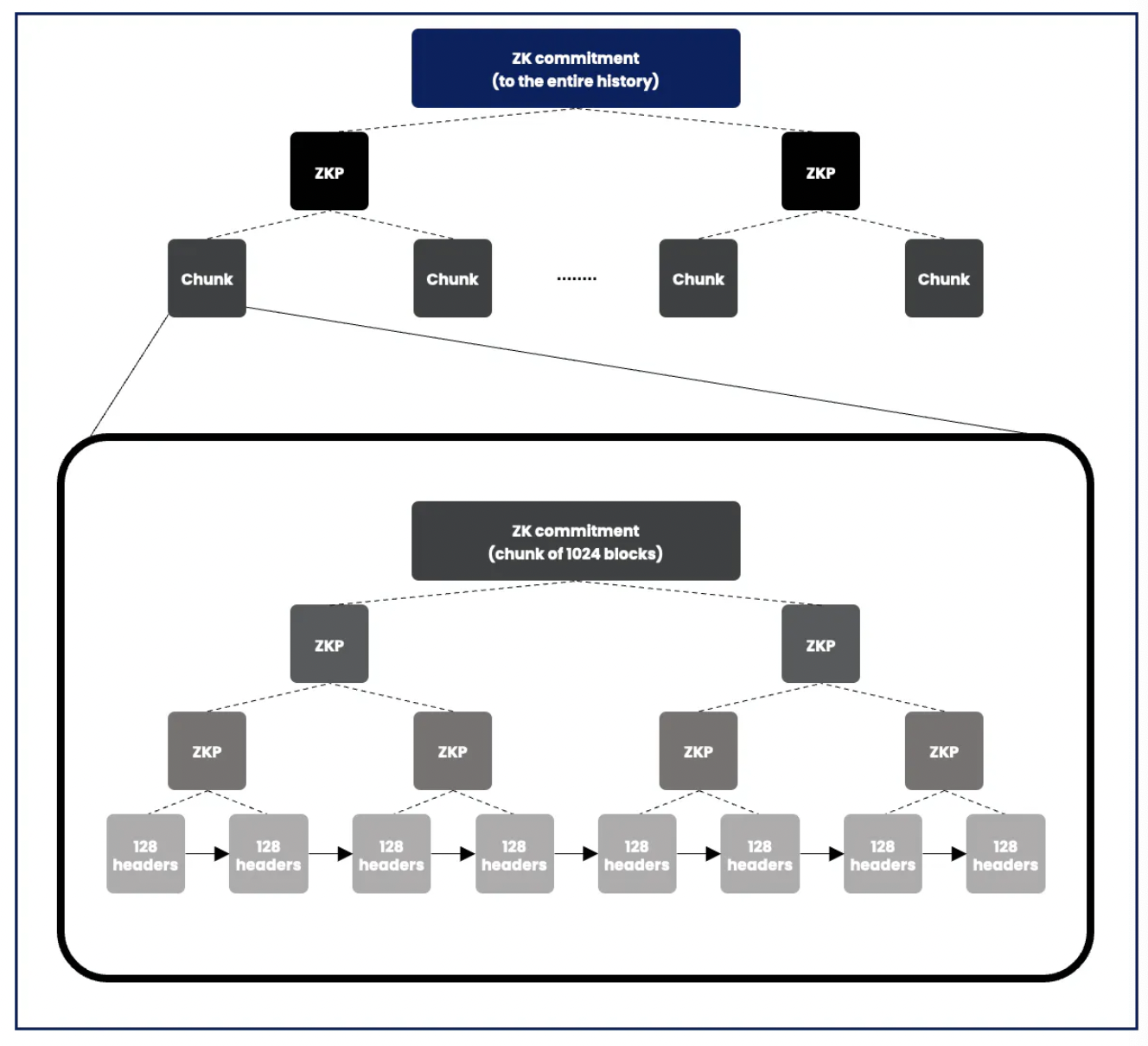
- Zero-knowledge proof for the entire chain ("zk commitment"): Service providers divide all historical blocks on the source chain into contiguous and fixed-size "chunks" using a Merkle Tree and generate a zero-knowledge proof for each chunk to verify grouping. These proofs are then recursively merged until the final zero-knowledge proof, which is the "zk commitment" for the entire chain. This proves that the provider has correctly indexed the entire history of the chain.
ZK commitment based on Ethereum historical information
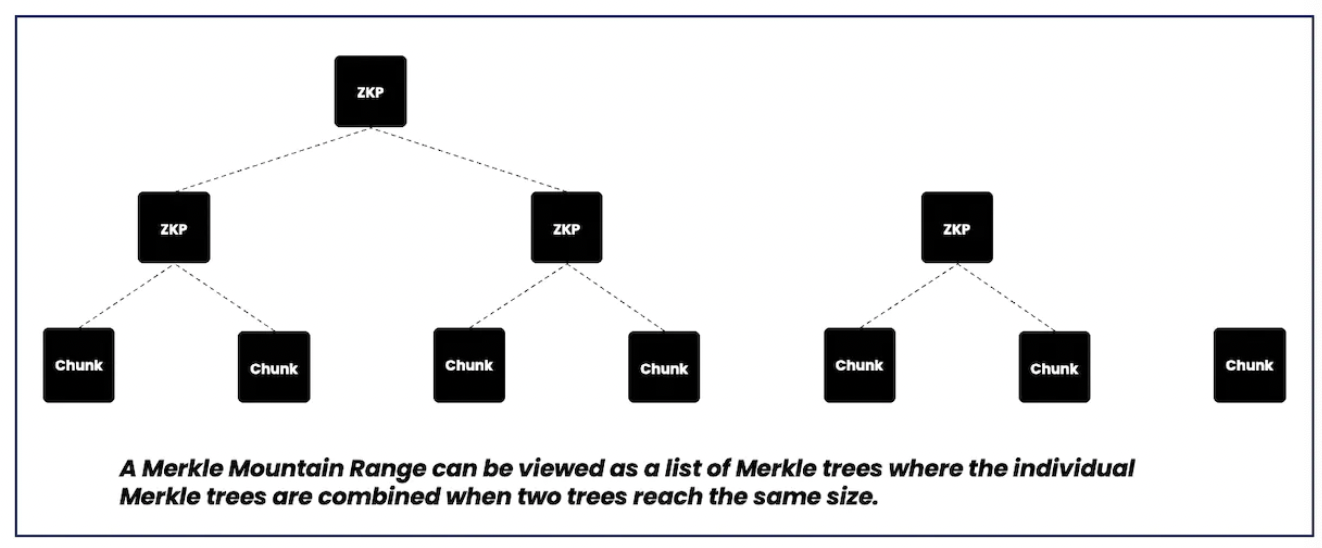
- Merkle Mountain Range data structure: The provider also stores the Keccak Merkle root of the hashed blocks (chunks) of the source chain in a chain data structure called Merkle Mountain Range (MMR). This data structure is used because it is easy to query and update, allowing the provider to efficiently prove the existence of a given block in the chain's history. MMR is created using Keccak256 hashes, Poseidon hashes, or a combination of both. Poseidon hashes are more friendly to zero-knowledge, allowing for computations on historical data and then proving the validity of the data and computation through zero-knowledge proofs.
Merkle Mountain Range (MMR)
As new blocks are added, service providers will regularly (e.g., hourly or daily) update the "zk commitment" and MMR and synchronize with the source chain. This is done to ensure that historical blocks are always associated with the 256 blocks currently accessible from the EVM. This ensures the correlation between historical data and the blocks available from Ethereum.
The detailed implementation of this setup is explained in the following diagram:
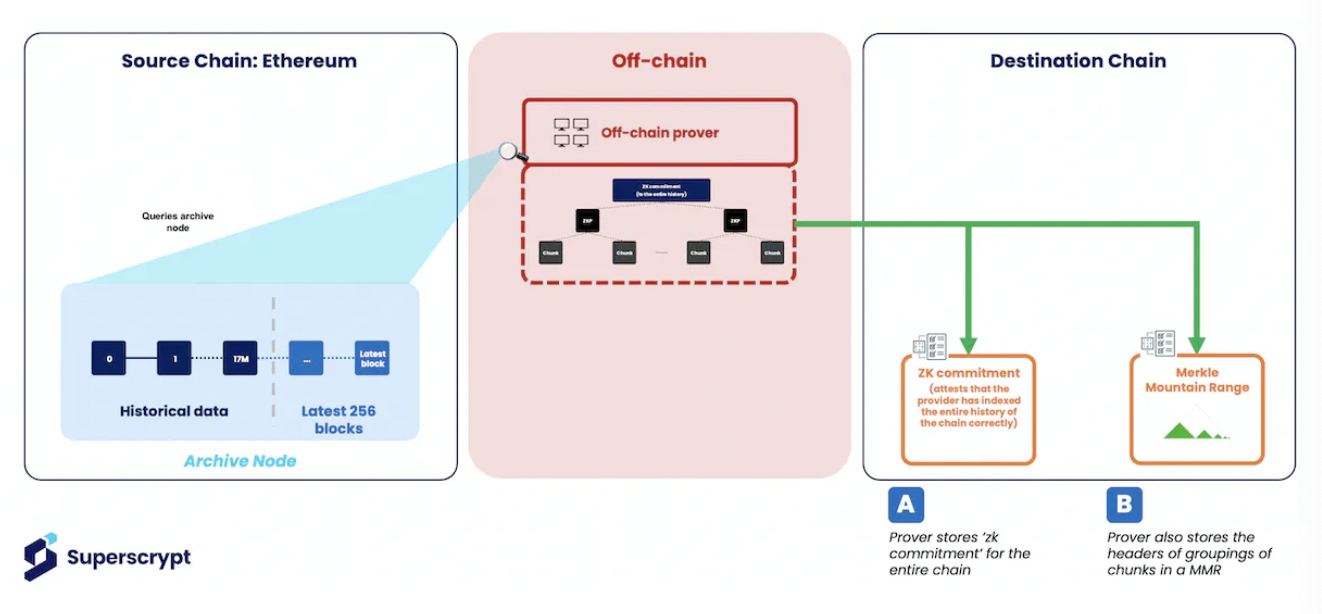
In conclusion, the following section outlines the specific method of storage proofs in the DAO voting example we introduced earlier after the setup is completed:
- The service provider creates and stores the "zk commitment" for the entire chain (i.e., Ethereum transaction history) and the MMR on the destination chain
- The service provider offers an application interface to query historical data on-chain or off-chain
- The voting dApp on the destination chain sends a query to the provider's smart contract to confirm if the user holds DAO tokens on Ethereum at block #17,000,000
- Additionally, for the provider, it needs to verify:
- The queried block is part of Ethereum's historical records (as in Step 1 above); then, generate a zero-knowledge proof for the block's inclusion through MMR
- The user holds DAO tokens at block #17,000,000 (as in Step 2 above); then, generate another zero-knowledge proof to prove the user's ownership of DAO tokens in that block
- The provider aggregates the generated proofs into a single zero-knowledge proof
- The aggregated zero-knowledge proof is then sent back to the voting dApp's smart contract on the destination chain for verification, and upon successful verification, allows the user to vote.
Projects Dedicated to the Field
Several companies are building smart contracts to access on-chain historical data in a trust-minimized manner.
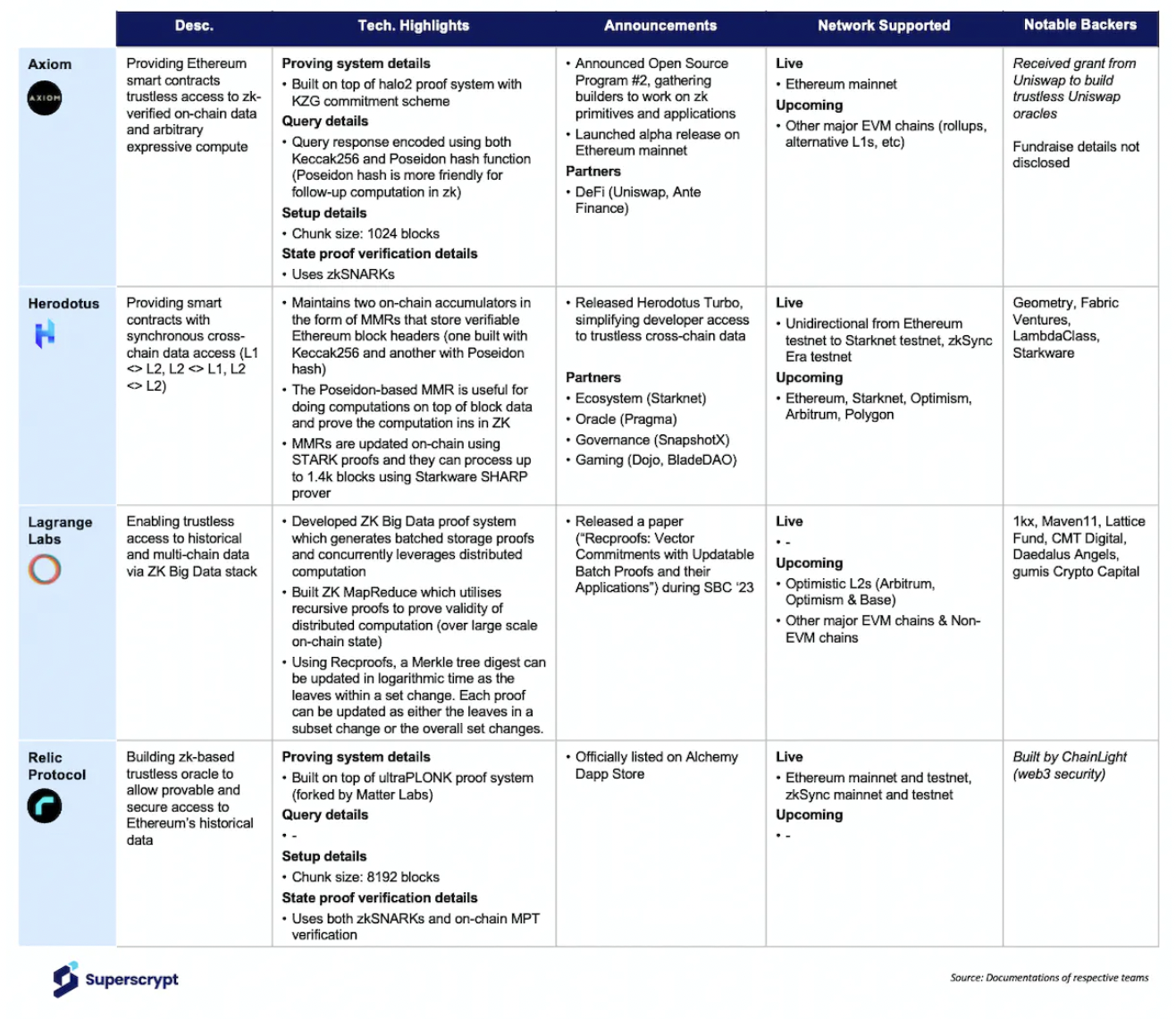
Axiom, currently live on Ethereum, aims to provide access to Ethereum's historical data for smart contracts through zk-based storage proofs. The team is also enhancing the ability to perform off-chain computations based on historical data and proving the correctness of these data and computations in zero-knowledge.
Relic Protocol adopts a similar technical approach to Axiom and is operational on Ethereum and zkSync Era. Relic uses Merkle inclusion proofs to prove data inclusion (different from Axiom's method of proving Merkle inclusion in zero-knowledge).
Herodotus is working on providing Ethereum historical data for L2. Currently, the testnet is live on Starknet and zkSync Era. With funding from the OP Foundation, the next goal for the Herodotus team is very clear.
Lagrange Labs introduces fully updatable proofs through the recent ZK MapReduce (ZKMR) innovation. It uses a new vector commitment called Recproofs, extending the concept of upgradability to data computation.
Conclusion
In this section, we have introduced how storage proofs can verify on-chain historical data without the need to trust third parties. This makes it an important tool for on-chain composability and cross-chain interoperability.
As the total value locked continues to migrate from Ethereum to the second-layer ecosystem, we expect more expressive applications leveraging on-chain historical data through storage proofs to emerge.
While the verification speed and cost of zero-knowledge proofs are improving, the ongoing cost of generating storage proofs to keep up with on-chain state remains a challenge. The profitability of such services will depend on the query volume generated by querying applications.
Despite the challenges, the importance of consensus proofs and storage proofs driven by zero-knowledge technology cannot be overstated. We are excited to see how these technologies will be used to build a more trust-minimized multi-chain future.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







