Original: SenseAI
"Since OpenAI launched GPT-4 in April this year, more and more models have been open-sourced, and the focus of AI believers is shifting from models to applications. The latest article from Lightspeed deduces the development trend of AI models and proposes that future large models will be divided into three categories, and structurally provides a model-level opportunity analysis. This issue brings to everyone the development trends and opportunities for the model infrastructure layer, including AI Ops middleware."
Sense Thinking
We attempt to propose more divergent deductions and deep thoughts based on the content of the article, and welcome discussions.
Based on the capabilities and costs of models, AI models will be divided into "brain models," "challenger models," and "long-tail models." Long-tail models are small and flexible, more suitable for training expert models for specific niche domains. With the periodicity of Moore's Law, future computational power constraints may not exist, and it will be difficult for brain models to dominate application scenarios. The market is likely to allocate suitable models based on the size of application scenarios and value chain rules.
Emerging system opportunities on the model side: 1) Model evaluation framework; 2) Running and maintaining models; 3) Enhanced systems. It is necessary to consider the differences in the markets of China and the United States, the diversity of original enterprise service ecosystems, and capital preferences.
Enterprise RAG (Retrieval Augmented Generation) platform opportunities: Opportunities brought by model complexity and diversity, 1) Operational tools: observability, security, compliance; 2) Data: the technology will bring opportunities for data monetization between differentiated business value and overall social value.
This article contains a total of 2426 words, and careful reading takes about 7 minutes.
Over the past decade, the well-established American fund Lightspeed has been collaborating with outstanding companies in the AI/ML field, the platforms they have built, and the clients they serve, to better understand how enterprises are thinking about Gen-AI. Specifically, Lightspeed has studied the foundational model ecosystem and raised questions such as "Will the best models have winner-takes-all dynamics?" and "Do enterprise use cases default to calling OpenAI's API, or will actual usage be more diverse?" These answers will determine the future growth direction of this ecosystem, as well as the flow of energy, talent, and capital.
01. Model Ecosystem Classification
Based on our learning, we believe that there will be a Cambrian explosion of models in AI. Developers and enterprises will choose the models most suitable for the "task to be completed," although the use in the exploration phase may appear more concentrated. The likely path for enterprise adoption is to use large models for exploration, and as their understanding of use cases increases, gradually transition to smaller specialized (adjusted + refined) models for production use. The figure below outlines how we view the evolution of the foundational model ecosystem.
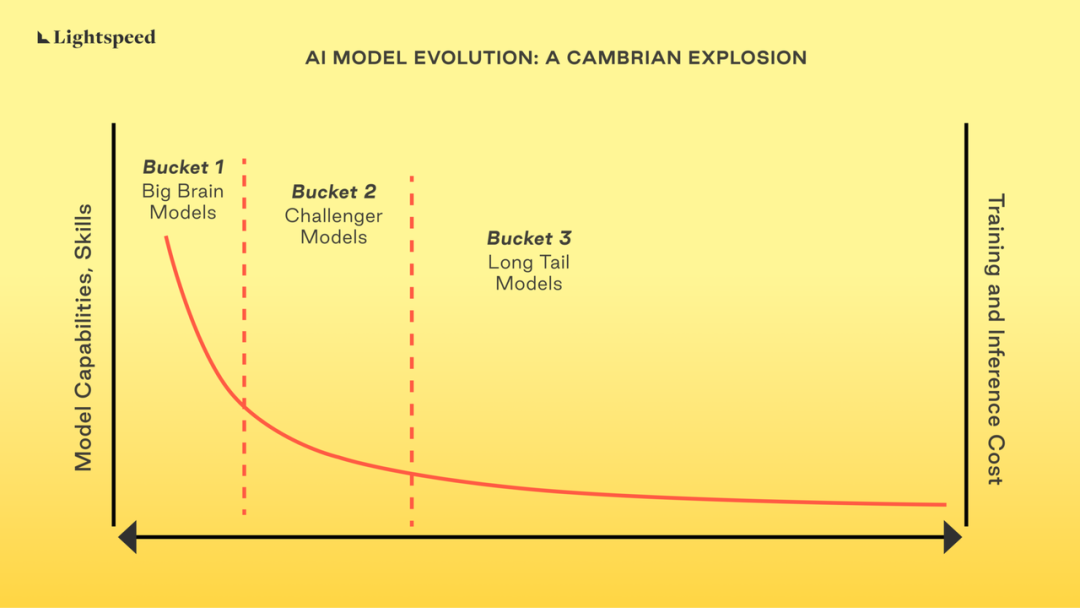
The AI model landscape can be divided into 3 main categories, which may overlap:
Category One: "Brain" Models
These are the best models, representing the cutting edge of models. They are the source of exciting and magical demonstrations. When developers are exploring what AI can do for their applications, they typically first consider these models. The training cost of these models is high, and maintenance and scaling are complex. However, the same model can take the LSAT, MCAT, write your high school essay, and interact with you as a chatbot. Developers are currently experimenting with these models and evaluating the use of AI in enterprise applications.
However, the use of general models is expensive, with high inference latency, and may be excessive for well-defined constrained use cases. The second issue is that these models are generalists and may not be very accurate in specialized tasks. (Refer to this Cornell paper for more information.) Finally, in almost all cases, they are also black boxes, which may pose privacy and security challenges for enterprises that are actively trying to leverage these models without relinquishing their data assets. OpenAI, Anthropic, and Cohere are some examples of companies.
Category Two: "Challenger" Models
These are also high-capability models, with skills and capabilities second only to the aforementioned general large models. Llama 2 and Falcon are the best representatives in this category. They are often as good as the Gen "N-1" or "N-2" models that come out of training general models on enterprise data. For example, according to certain benchmarks, Llama2 is as good as GPT-3.5-turbo. Fine-tuning these models on enterprise data can make them as good as the first category of general large models for specific tasks.
Many of these models are open source (or close to it), and their release immediately brings improvements and optimizations from the open source community.
Category Three: "Long-Tail" Models
These are "expert" models. They are built to serve a specific purpose, such as classifying documents, identifying specific attributes in images or videos, or identifying patterns in business data. These models are flexible, have low training and usage costs, and can run in data centers or at the edge.
A simple browse of Hugging Face is enough to understand the current and future vast scale of this ecosystem, as it serves a wide range of use cases.
02. Basic Adaptation and Practical Cases
Although still in the early stages, we have already seen some leading development teams and enterprises thinking about the ecosystem in this meticulous way. People want to match usage with the best possible models. They may even use multiple models to serve a more complex use case.
Factors to consider when evaluating which model/models to use often include:
Data privacy and compliance requirements: This affects whether the model needs to run in enterprise infrastructure or if data can be sent to externally hosted inference endpoints.
Whether the model allows fine-tuning.
The required inference "performance" level (latency, accuracy, cost, etc.).
However, the actual factors to consider are often much longer than those listed above, reflecting the enormous diversity of use cases that developers want to achieve with AI.
03. Where Are the Opportunities?
Model evaluation framework: Enterprises will need tools and expertise to help evaluate which model to use for which use case. Developers need to decide how to best evaluate whether a specific model is suitable for the "task to be completed." Evaluation needs to consider multiple factors, not only the model's performance, but also cost, implementable control levels, etc.
Running and maintaining models: Platforms to help enterprises train, fine-tune, and run models (especially the third category of long-tail models) will emerge. Traditionally, these platforms are widely referred to as ML Ops platforms, and we expect this definition to also expand to generative AI. Platforms such as Databricks, Weights and Biases, Tecton, etc., are rapidly moving in this direction.
Enhanced systems: Models, especially hosted LLMs, will need retrieval augmented generation to provide ideal results. This requires a series of auxiliary decisions, including:
Data and metadata extraction: How to connect to structured and unstructured enterprise data sources, then extract data and access policies, etc. metadata.
Data generation and storage embedding: Which model to use for data generation embedding. Then how to store them: using which vector database, especially based on the required performance, scale, and functionality?
Now is the time to build an enterprise RAG platform, thereby eliminating the complexity of choosing and piecing together these platforms:
Operational tools: Enterprise IT will need to establish guardrails, manage costs, etc. for engineering teams; all the software development tasks they are dealing with now need to be extended to the use of AI. Areas of interest for the IT department include:
Observability: How do the models perform in production? Does their performance improve/degrade over time? Are there usage patterns that may affect the selection of future versions of application models?
Security: How to ensure the security of AI native applications. Are these applications vulnerable to new attack vectors that require new platforms?
Compliance: We expect the use of AI native applications and LLM to comply with frameworks that relevant regulatory bodies have begun to develop. This is in addition to existing privacy, security, consumer protection, fairness, and other compliance regulations. Enterprises will need platforms to help them maintain compliance, conduct audits, generate compliance proofs, and related tasks.
Data: Platforms that help understand the data assets that enterprises possess and how to extract maximum value from these assets with new AI models will be rapidly adopted. One of the world's largest software companies once told us, "Our data is our moat, our core intellectual property, our competitive advantage. Leveraging AI to monetize these data and promote differentiation in a way that does not weaken defensibility will be crucial." Platforms such as Snorkel play a crucial role in this regard.
Now is an excellent time to build AI infrastructure platforms. The application of AI will continue to transform entire industries, but it needs accompanying infrastructure, middleware, security, observability, and operational platforms to enable every enterprise on the planet to adopt this powerful technology.
Reference Materials
https://lsvp.com/will-enterprise-ai-models-be-winner-take-all/
Authors: Vela, Yihao, Leo
Editing and Formatting: Zoey, Vela
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。








