Author: Friday, Deep Tide TechFlow
Anthropic has just delivered an impeccable report card on paper.
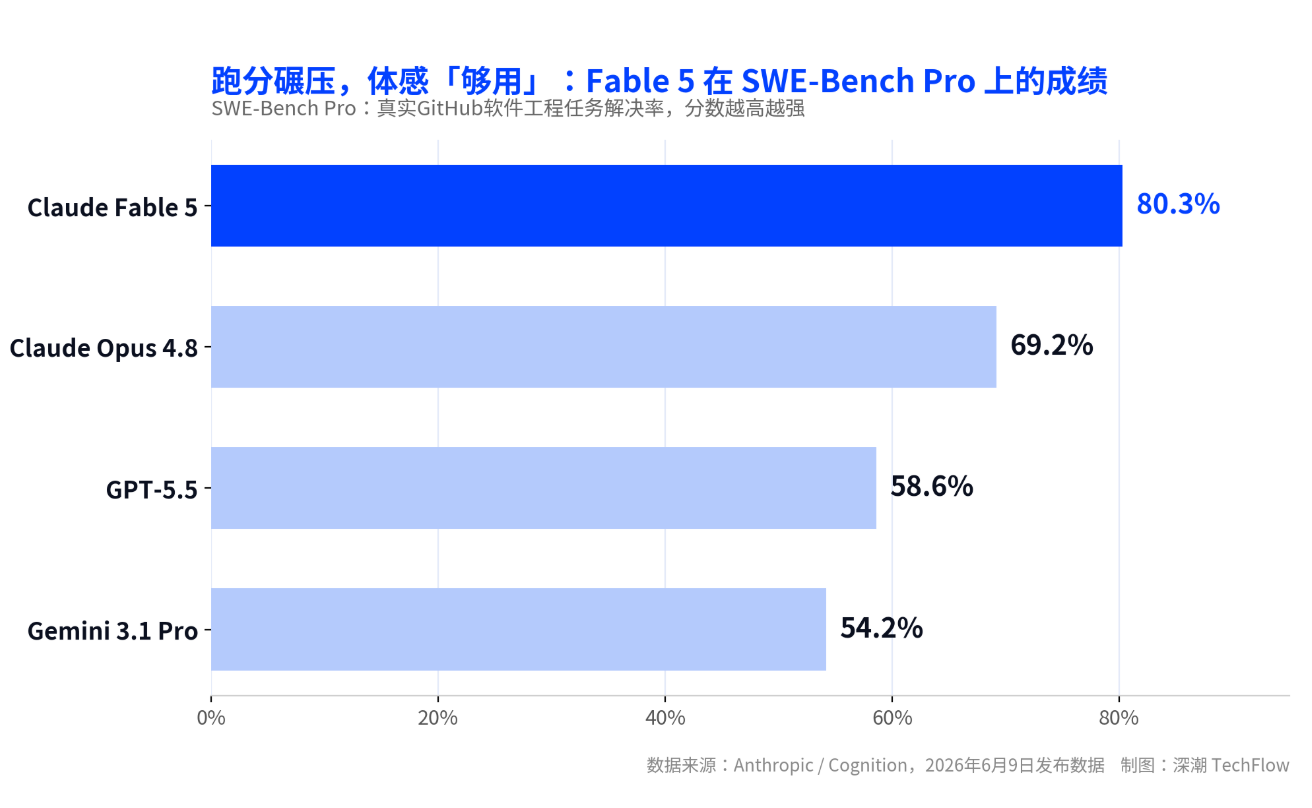
Released on June 9, Claude Fable 5 is the company's first publicly available Mythos-level model, achieving 80.3% on the SWE-Bench Pro benchmark for real software engineering tasks, leading its previous flagship Opus 4.8 by about 11 percentage points, and surpassing GPT-5.5 by more than 20 percentage points.
But user reactions poured cold water on it.
Three days after the release, a popular post in the r/artificial section (with 305,000 weekly visits) was titled: "Claude Fable made me realize I don't need a better model." The poster, Axi0m-22, stated that after using Fable for a while on safety research and daily work, he almost immediately switched back to Opus for coding and Haiku for handling miscellaneous tasks. He made an analogy: it's like looking at the iPhone 14 when the iPhone 17 is released; you know the new one is better, but you think: whatever, this one is just fine.
The highly praised area occupied by the "good enough faction": model aesthetic fatigue becomes a mainstream sentiment
The top comment received 42 likes: "Aside from the larger context window, I have not felt the need for a stronger model since Opus 4.5."
Another user, hyprlab, received 13 likes for their statement: "Switching to a more token-hungry model, I see no benefits to my workflow; Opus 4.8's high-intensity mode is already comfortable enough."
This kind of statement reflects a common cost accounting.
Fable 5's API pricing is set at $10 per million input tokens, nearly double that of Opus 4.8. User siromega37 bluntly said: "Higher token consumption, but no ROI. I feel we are seeing a plateau; the bubble will eventually burst."
User hobopwnzor offered a more systematic interpretation: "We have been at the top of the S-curve for a while. Recent advancements mainly come from tool calls and peripheral engineering, not from the model's inherent capabilities."
Security barriers become the biggest complaint: "90% of uses are directly rejected"
If "good enough" is still just a sentiment, then complaints about security barriers are a concrete product issue.
According to Anthropic's official statement, Fable 5 shares the same underlying model as Mythos 5, which is only available to a select few organizations, with the difference being that Fable is equipped with a security classifier: requests related to high-risk areas such as cybersecurity are intercepted and handled by Opus 4.8 instead. Officials state that this mechanism is tuned conservatively, triggering in less than 5% of conversations on average, but mistakenly rejecting harmless requests.
In this Reddit post, the perceived trigger rate is clearly much higher than 5%. User jradoff, who received 17 likes, mentioned that when he asked Fable to check the safety of his code, "it basically refused to process anything related to safety," and was then reverted to Opus. Another comment with 12 likes was even less polite: "90% of what you want to do with it will be rejected, it's useless."
Paid users are more frustrated. User kaitava, who subscribed at the $200 tier, wrote: "I'm paying double the usage fee, trying to get it to perform a security review, and I got downgraded to Opus. Now I dislike everything about it, just waiting for OpenAI to catch up."
For a flagship product focused on capability leaps, "the usability cost for security" is becoming the core variable for users deciding whether to pay.
Counter voices: Heavy task users feel it's "night and day"
There are indeed dissenters beneath the popular posts, and the opposing perspective is quite clear: the heavier the task, the higher the praise.
User Phylaras received 15 likes for their comment: "Fable made a substantial difference for me. For those complex tasks with huge context window requirements, it caught errors that had previously gone unnoticed." A user claiming to work on high-energy physics simulations mentioned that a single simulation model can easily exceed 8,000 to 10,000 lines of code, with hundreds of models interacting, "having a model that can work independently and understand environmental details is something I'm really looking forward to."
The strongest rebuttal came from user Navetz: "To be honest, those who have used this model will find such posts to be nonsense. For me, it's intelligent to the point of being like two different people, and I keep using it. I explain to my non-technical friends: it's like directly swapping a college player for an NBA starter."
Others have offered a middle-ground usage. User ready-eddy suggested treating Fable as a "planner and fixer," rather than a daily "builder," unless one doesn't care about burning money. Another comment summarized more like a user manual: using Fable for spreadsheet calculations is picking the wrong model, and running 16 agents in a complex task with Haiku is also the wrong model, "there are no inherently bad models, only models used inappropriately."
After decoupling scores from user experience, will public AI still be stronger?
One of the most interesting comments in this debate shifted the topic from products to industry structure.
User KedMcJenna proposed a "public AI freeze theory": the models that ordinary people can access may forever hover near the current level, while elite enterprises and governments will continue to gain access to stronger proprietary models, "we at least know about Mythos, and there are likely stronger models we will never hear about."
This comment points to a fact: Mythos 5 is not available to the public and is currently only provided to cybersecurity agencies and critical infrastructure companies through the Project Glasswing initiative.
When looking at scores and public sentiment together, the conclusion is not contradictory.
Benchmark tests measure capability limits, while Reddit's highly praised area reflects the ceiling of everyday needs. When most users' tasks had already been met during the Opus 4.6 era, stronger models can only prove themselves in extreme scenarios like physical simulations or ultra-long contexts. The model vendors no longer face the question of "can it be done," but rather "who needs it, how much are they willing to pay, and how much security friction can they tolerate."
Three days after its release, Fable 5 received two completely different report cards in the scoring rankings and the public discourse. Which one is closer to the truth will depend on how quickly Anthropic adjusts the security classifier and the wallets of heavy users.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。








