Web3 and AI: What kind of spark can be collided?
Author: YBB Capital Zeke

Preface
On February 16th, OpenAI announced the latest text-controlled video generation diffusion model "Sora", which demonstrated another milestone moment for generative AI by generating high-quality videos covering a wide range of visual data types. Different from AI video generation tools like Pika, which are still in the state of generating a few seconds of video from multiple images, Sora achieved scalable video generation by training in the compressed spatiotemporal space of videos and images, breaking them down into spatiotemporal position patches. In addition, the model also demonstrated the ability to simulate the physical and digital worlds, and the final 60-second demo could be described as a "universal simulator of the physical world".
In terms of construction, Sora continues the technical path of the previous GPT model "source data-Transformer-Diffusion-emergence", which means that its mature development also requires computational power as an engine. Furthermore, due to the much larger amount of data required for video training compared to text training, the demand for computational power will be further increased. However, we have already discussed the importance of computational power in the AI era in our early article "Prospects of Decentralized Computational Power Market", and with the continuous rise in the popularity of AI recently, a large number of computational power projects have emerged in the market, and other passive Depin projects (storage, computational power, etc.) have also experienced a wave of explosive growth. So, besides Depin, what kind of spark can be collided in the intertwining of Web3 and AI? What opportunities are contained in this track? The main purpose of this article is to update and supplement the previous articles, and to consider the possibilities of Web3 in the AI era.
Three Major Directions in the Development History of AI
Artificial Intelligence (AI) is an emerging science and technology aimed at simulating, extending, and enhancing human intelligence. Since its birth in the 1950s and 1960s, AI has become an important technology driving the transformation of social life and various industries after more than half a century of development. In this process, the interwoven development of the three major research directions of symbolism, connectionism, and behaviorism has become the cornerstone of the rapid development of AI today.
Symbolism
Also known as logicalism or ruleism, it believes that it is feasible to simulate human intelligence through processing symbols. This approach represents and operates objects, concepts, and their relationships in the problem domain through symbols, and uses logical reasoning to solve problems, especially achieving significant achievements in expert systems and knowledge representation. The core idea of symbolism is that intelligent behavior can be achieved through the manipulation of symbols and logical reasoning, where symbols represent highly abstract representations of the real world.
Connectionism
Also known as the neural network approach, it aims to achieve intelligence by mimicking the structure and function of the human brain. This method constructs a network composed of numerous simple processing units (similar to neurons) and achieves learning by adjusting the connection strength (similar to synapses) between these units. Connectionism particularly emphasizes the ability to learn and generalize from data, especially suitable for pattern recognition, classification, and continuous input-output mapping problems. As a development of connectionism, deep learning has made breakthroughs in fields such as image recognition, speech recognition, and natural language processing.
Behaviorism
Behaviorism is closely related to the research of bionic robotics and autonomous intelligent systems, emphasizing that intelligent agents can learn through interaction with the environment. Unlike the former two, behaviorism does not focus on simulating internal representations or thought processes, but achieves adaptive behavior through the cycle of perception and action. Behaviorism believes that intelligence is manifested through dynamic interaction and learning with the environment, which is particularly effective in mobile robots and adaptive control systems that need to operate in complex and unpredictable environments.
Although these three research directions have fundamental differences, they can also interact and integrate in practical AI research and applications, jointly promoting the development of the AI field.
Overview of AIGC Principles
The explosively developing generative AI (Artificial Intelligence Generated Content, referred to as AIGC) at the current stage is a kind of evolution and application of connectionism. AIGC can imitate human creativity to generate novel content. These models are trained using large datasets and deep learning algorithms to learn the underlying structures, relationships, and patterns in the data. Based on user input prompts, they generate novel and unique output results, including images, videos, code, music, design, translation, question answering, and text. Currently, AIGC is basically composed of three elements: deep learning (DL), big data, and large-scale computational power.
Deep Learning
Deep learning is a subfield of machine learning (ML), and deep learning algorithms model neural networks based on the human brain. For example, the human brain contains millions of interconnected neurons that work together to learn and process information. Similarly, deep learning neural networks (or artificial neural networks) are composed of multiple layers of artificial neurons that work together inside a computer. Artificial neurons are software modules called nodes that use mathematical calculations to process data. Artificial neural networks use these nodes to solve complex problems.
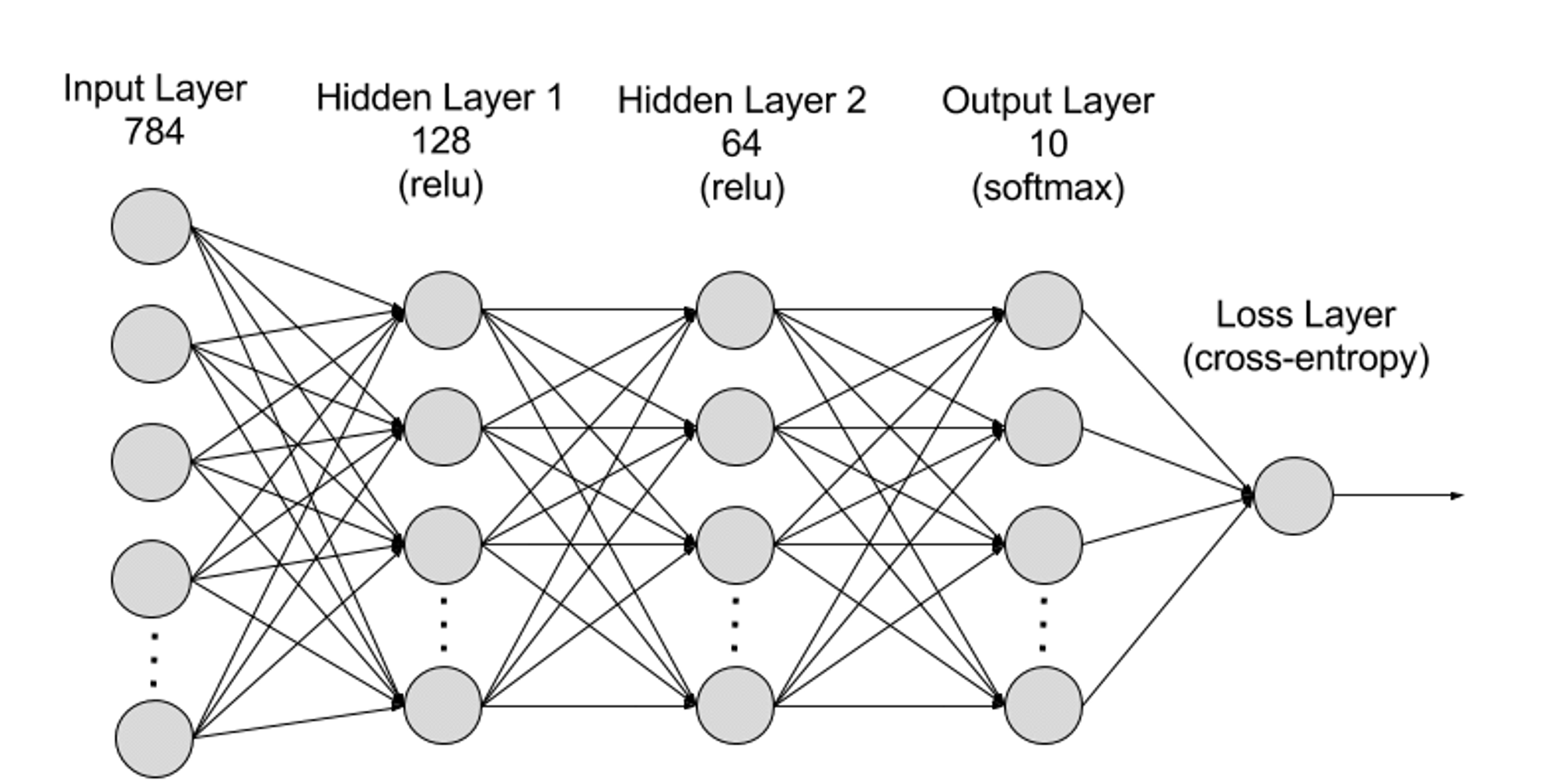
Neural networks can be divided into input layer, hidden layer, and output layer, and the connections between different layers are represented by parameters.
● Input Layer: The input layer is the first layer of the neural network, responsible for receiving external input data. Each neuron in the input layer corresponds to a feature of the input data. For example, when processing image data, each neuron may correspond to a pixel value of the image.
● Hidden Layer: The input layer processes the data and passes it to further layers in the neural network. These hidden layers process information at different levels and adjust their behavior when receiving new information. Deep learning networks have hundreds of hidden layers that can be used to analyze problems from multiple perspectives. For example, if you have an unknown animal image that needs to be classified, you can compare it with animals you already know. For instance, you can judge what kind of animal it is based on the shape of the ears, the number of legs, and the size of the pupils. The hidden layers in deep neural networks work in the same way. If a deep learning algorithm tries to classify animal images, each hidden layer will process different features of the animal and attempt to accurately classify it.
● Output Layer: The output layer is the last layer of the neural network, responsible for generating the network's output. Each neuron in the output layer represents a possible output category or value. For example, in a classification problem, each output layer neuron may correspond to a category, while in a regression problem, the output layer may have only one neuron, whose value represents the predicted result.
● Parameters: In neural networks, the connections between different layers are represented by weight and bias parameters, which are optimized during the training process to enable the network to accurately identify patterns in the data and make predictions. Increasing the number of parameters can increase the model capacity of the neural network, i.e., the ability of the model to learn and represent complex patterns in the data. However, the increase in parameters also increases the demand for computational power.
Big Data
To effectively train, neural networks typically require large, diverse, high-quality, and multi-source data. It is the foundation for training and validating machine learning models. By analyzing big data, machine learning models can learn patterns and relationships in the data, and make predictions or classifications.
Large-Scale Computational Power
The multi-layered complex structure of neural networks, large number of parameters, big data processing requirements, iterative training method (during the training phase, the model needs to iterate repeatedly, and the training process requires forward and backward propagation calculations for each layer, including activation function calculations, loss function calculations, gradient calculations, and weight updates), high-precision computing requirements, parallel computing capabilities, optimization and regularization techniques, as well as model evaluation and validation processes, collectively lead to the high demand for computational power.

Sora
As the latest video generation AI model released by OpenAI, Sora represents a significant advancement in the ability of artificial intelligence to process and understand diverse visual data. By using video compression networks and spatiotemporal patch technology, Sora can transform massive visual data captured from different devices around the world into a unified representation, thereby achieving efficient processing and understanding of complex visual content. Leveraging the text-conditioned Diffusion model, Sora can generate videos or images highly matched to the text prompts, demonstrating high creativity and adaptability.
However, despite the breakthroughs in video generation and simulating interactions with the real world, Sora still faces some limitations, including the accuracy of simulating the physical world, consistency in generating long videos, understanding complex text instructions, and training and generation efficiency. Moreover, fundamentally, Sora still relies on OpenAI's monopolistic computational power and first-mover advantage, continuing the "big data-Transformer-Diffusion-emergence" old technological path, achieving a kind of brute force aesthetics. Other AI companies still have the possibility of overtaking through technological shortcuts.
Although Sora is not directly related to blockchain, I personally believe that in the next year or two, due to the influence of Sora, it will force the emergence and rapid development of other high-quality AI generation tools, and will radiate into multiple tracks within Web3 such as GameFi, social, creative platforms, and Depin. Therefore, it is necessary to have a general understanding of Sora, and how AI will effectively integrate with Web3 in the future may be a key point for us to consider.
Four Paths of AI x Web3
As mentioned above, we can understand that the underlying foundation required for generative AI actually only consists of three points: algorithms, data, and computational power. On the other hand, from the perspective of generality and generative effects, AI is a tool that subverts the production process. The greatest role of blockchain has two points: reconstructing production relations and decentralization. Therefore, I personally believe that the collision of the two can produce the following four paths:
Decentralized Computational Power
Since I have written related articles in the past, the main purpose of this paragraph is to update the current situation in the computational power track. When it comes to AI, computational power is always an indispensable factor. The enormous demand for computational power by AI is already unimaginable after the birth of Sora. Recently, during the 2024 World Economic Forum in Davos, Switzerland, OpenAI CEO Sam Altman bluntly stated that computational power and energy are the biggest shackles at present, and their importance in the future may even be equivalent to that of currency. Then, on February 10th, Sam Altman made an astonishing plan on Twitter, proposing a $7 trillion financing (equivalent to 40% of China's national GDP in 2023) to reshape the global semiconductor industry and establish a chip empire. When writing about computational power, my imagination was still limited to national blockades and giant monopolies, but now a company wants to control the global semiconductor industry, which is really quite crazy.
Therefore, the importance of decentralized computational power is self-evident. The characteristics of blockchain can indeed solve the problem of extreme monopolization of computational power and the high cost of purchasing dedicated GPUs. From the perspective of AI requirements, the use of computational power can be divided into two directions: inference and training. Projects that focus on training are still few and far between, from the combination of decentralized networks with neural network design, to the extremely high hardware requirements, which are destined to be a highly challenging and difficult direction to implement. In contrast, inference is relatively much simpler. On the one hand, it is not complex in terms of decentralized network design, and on the other hand, it has lower hardware and bandwidth requirements, making it a more mainstream direction at present.
The imagination space of the centralized computational power market is huge, often linked to the key word "trillions", and it is also the most easily hyped topic in the AI era. However, from the numerous projects that have emerged recently, the vast majority belong to the category of rushing to capitalize on the trend. They often hold high the correct flag of decentralization, but remain silent about the inefficiency of decentralized networks. Furthermore, there is a high degree of homogenization in design, with many projects being very similar (one-click L2 with mining design), which may ultimately lead to chaos. It is indeed quite difficult for such situations to take a share from the traditional AI track.
Algorithm and Model Collaboration System
Machine learning algorithms refer to algorithms that can learn patterns and trends from data and make predictions or decisions based on them. Algorithms are technology-intensive because their design and optimization require deep expertise and technological innovation. Algorithms are the core of training AI models, defining how data is transformed into useful insights or decisions. Common generative AI algorithms such as Generative Adversarial Networks (GAN), Variational Autoencoders (VAE), and Transformers are each born for a specific domain (such as painting, language recognition, translation, video generation) or purpose, and then train specialized AI models through the algorithms.
With so many algorithms and models, each with its own strengths, can we integrate them into a model that is versatile and capable? Bittensor, which has recently gained popularity, is a leader in this direction, incentivizing different AI models and algorithms to collaborate and learn through mining, thereby creating more efficient and versatile AI models. Similarly, other projects in this direction include Commune AI (code collaboration), but for AI companies at present, algorithms and models are their own trump cards and will not be easily borrowed externally.
So, the narrative of AI collaboration ecosystems is quite novel and interesting. The collaborative ecosystem uses the advantages of blockchain to integrate the disadvantages of AI algorithm islands, but whether it can create corresponding value is currently unknown. After all, the closed-source algorithms and models of leading AI companies have very strong capabilities for updating, iterating, and integrating. For example, OpenAI has developed from early text generation models to multi-domain generation models in less than two years, and projects like Bittensor may need to take a different approach in the fields targeted by the models and algorithms.
Decentralized Big Data
From a simple perspective, using private data to feed AI and labeling data are very compatible with blockchain, and it can also benefit Depin projects such as FIL and AR in terms of data storage. From a more complex perspective, using blockchain data for machine learning (ML) to solve the accessibility of blockchain data is also an interesting direction (one of Giza's exploration directions).
In theory, blockchain data is accessible at any time and reflects the entire state of the blockchain. However, for people outside the blockchain ecosystem, accessing this massive amount of data is not easy. Storing a complete blockchain requires rich expertise and a large amount of specialized hardware resources. To overcome the challenge of accessing blockchain data, several solutions have emerged in the industry. For example, RPC providers enable access to nodes through APIs, while indexing services make data extraction possible through SQL and GraphQL, both of which play a crucial role in solving the problem. However, these methods have limitations. RPC services are not suitable for high-density usage scenarios that require a large amount of data queries and often fail to meet the demand. Meanwhile, although indexing services provide a more structured way of data retrieval, the complexity of Web3 protocols makes it extremely difficult to build efficient queries, sometimes requiring the writing of hundreds or even thousands of lines of complex code. This complexity is a huge obstacle for general data practitioners and those with limited knowledge of Web3 details. The cumulative effects of these limitations highlight the need for a method that is easier to access and utilize blockchain data, which can promote broader applications and innovations in this field.
Therefore, by combining ZKML (Zero-Knowledge Proof Machine Learning, reducing the burden of machine learning on the chain) with high-quality blockchain data, it may be possible to create datasets that solve the accessibility of blockchain data, and AI can significantly lower the barrier to accessing blockchain data. As time goes on, developers, researchers, and enthusiasts in the ML field will be able to access more high-quality and relevant datasets for building effective and innovative solutions.
AI Empowering Dapps
Since 23, the rise of ChatGPT3, AI empowering Dapps has become a very common direction. The widely applicable generative AI can be accessed through APIs, thereby simplifying and intelligentizing data analysis platforms, trading bots, blockchain encyclopedias, and other applications. On the other hand, it can also act as a chatbot (such as Myshell) or AI companion (Sleepless AI), and even create NPCs in chain games through generative AI. However, due to the low technical barriers, most of them are just fine-tuning after accessing an API, and the integration with the project itself is not perfect, so it is rarely mentioned.
But after the arrival of Sora, I personally believe that the direction of AI empowering GameFi (including the metaverse) and creative platforms will be the focus of attention next. Because of the bottom-up nature of the Web3 field, it is definitely difficult to produce products that can compete with traditional gaming or creative companies, and the emergence of Sora is likely to break this dilemma (perhaps in just two to three years). Based on Sora's demo, it already has the potential to compete with micro-drama companies, and the active community culture of Web3 can also generate a large number of interesting ideas. When the only limitation is imagination, the barriers between bottom-up industries and traditional top-down industries will be broken.
Conclusion
With the continuous advancement of generative AI tools, we will experience more epoch-making "iPhone moments" in the future. Although many people scoff at the combination of AI and Web3, in reality, I think that most of the current directions are not problematic. The pain points that need to be addressed are actually only three: necessity, efficiency, and fit. While the integration of the two is still in the exploration stage, it does not prevent this track from becoming mainstream in the next bull market.
It is essential for us to maintain a sufficient level of curiosity and acceptance towards new things. In history, the transition from horse-drawn carriages to automobiles became a foregone conclusion in an instant, just like the same with inscriptions and NFTs from the past. Holding too many prejudices will only lead to missed opportunities.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







