大语言模型范式能走到 AGI 吗?
撰文:晓静
编辑:徐青阳
「我语言的局限,即意味着我世界的局限。」( Die Grenzen meiner Sprache bedeuten die Grenzen meiner Welt. )
哲学家维特根斯坦在 1921 年写下这句话时,他谈论的是人类认知的边界。一百年后,这句话精确地描述了大语言模型面临的结构性困境,如果 AI 的「语言」就是离散 token 序列,那么它的「世界」永远被困在 token 能表达的范围内。
这也引出了一个老生常谈的问题:大语言模型范式能走到 AGI(通用人工智能)吗?
2024 年 12 月,OpenAI 前首席科学家 Ilya Sutskever 在 NeurIPS 发表主题演讲,他说「预训练即将终结」。2026 年 3 月,图灵奖得主 Yann LeCun 离开 Meta 创办 AMI Labs,直接宣判「大语言模型路线错了」。
两位深度学习殿堂级的大师,一位选择颠覆自己亲手开启的预训练时代,另一位选择继续践行自己坚守多年的世界模型路线,去赌「LLM 的下一个时代」。
当然绝对不是当前的模型不好用或没有商业价值,大模型的用户数量及渗透率都在持续增长,产业价值会越来越大。但是从技术路径来看,他们要表达的是:这条路有一个结构性的天花板,这个天花板恰好卡在通往 AGI(通用人工智能)的路上。
2026 年 5 月,MIT 何恺明团队和字节跳动 Seed 实验室几乎同时发布论文,给出了一个更明确的信号:语言生成的核心建模过程不必始终发生在离散 token 空间中,也可以转移到连续 embedding 或 latent 空间里完成,最后再映射回文本。
这是第一批来自工程实验的硬证据,逐 token 预测可能是通向 AGI 路上的一个局部最优解。但连续空间范式打开了另一条路,这条路的天花板也许更高。

图:美国国家人工智能科学院院士,麻省理工学院电气工程与计算机科学系副教授何恺明,图片由 AI 生成
01 天花板在哪?
维特根斯坦的话可以这样理解。
人类的离散语言不是思维的原生格式。大脑内部的认知活动是连续的、并行的、高维的。比如人类想到一个苹果时,激活的不是「苹果」两个字的 token,而是一大片感觉皮层的连续活动模式,包括颜色、质感、重量、咬下去的声音。人之所以把这团连续体验压缩成「苹果」这个离散符号,纯粹是因为人类大脑的带宽逼你序列化。
人类语言是进化设计的有损压缩协议,它是跨脑传输的工程妥协。
我们目前用到的主流的商业化大模型产品,底层都是自回归架构(预测下一个 token)。
自回归大模型做的事情是,在这个压缩协议的输出格式上建模。它无法理解「世界如何运作」,它了解的是「人类选择用什么符号序列来描述世界」。它们极其擅长模拟人类的语言行为,但模拟语言行为和理解世界之间,差着一个认识论的鸿沟。
比如身体感受,疼痛是怎样的;空间直觉,知道怎么接住球但无法描述如何接住的;因果干预的具身反馈,比如如果「我把这个椅子推倒会怎样」的直觉。这些隐藏在人类大脑中的「感觉」,从未被任何人类语言编码过。所以它们从未进入训练数据,在 token 序列上做任何建模,无论参数多大、数据多多,都触及不到这些维度。
这就是 token 范式的天花板。
02「逃逸」实验
从 token 空间逃逸的第一批实验正在发生。
何恺明团队的 ELF(Embedded Language Flows,嵌入式语言流)做了一件反直觉的事:把文字生成的全过程留在连续向量空间里完成,只在最后一步,真的只有最后一步,才把连续向量投影回人类可读的文字。它用 Flow Matching(一种 2022 年由 Yaron Lipman 等人提出的连续正则化流框架)从噪声出发,沿学习到的速度场平滑演化到目标嵌入。32 个采样步,生成质量超过离散模型用 1024 步的结果。训练数据约 450 亿 token,只有主流方法的十分之一。

图:ELF 仅用 32 步采样即超越 MDLM、Duo 等离散模型 1024 步的生成质量,且未使用蒸馏加速。模型参数 105M,训练数据约为同类方法的十分之一。
四天后发布的 Cola DLM(字节 Seed 团队):先用 Text VAE 把语言压缩成更深层的语义潜空间,再在这个纯语义空间里用 Flow Matching 建模全局先验,最后才解码回文字。论文明确说:扩散过程做的是「潜在先验运输」,不是「token 级别的观测恢复」。20 亿参数,8 个基准,与同体量自回归模型和已经 scale 到 1000 亿参数的 LLaDA2.0 严格对比,连续路线的 scaling 曲线是健康的。
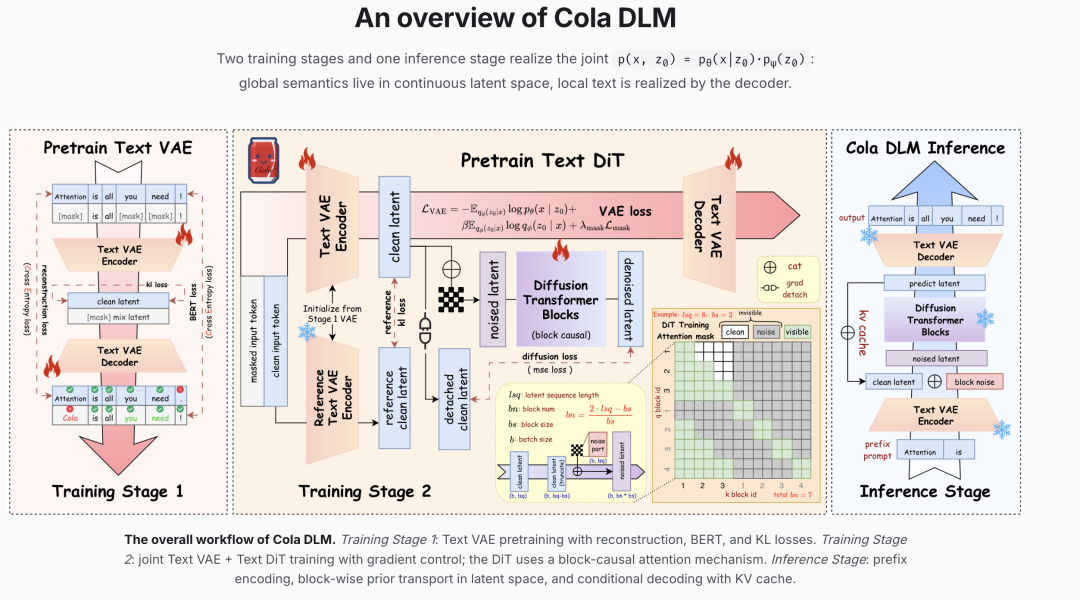
图:Cola DLM 整体架构图
两篇论文的核心都在表达,token 不是语言建模的必要条件。连续空间可以做得更好、更快、更省。
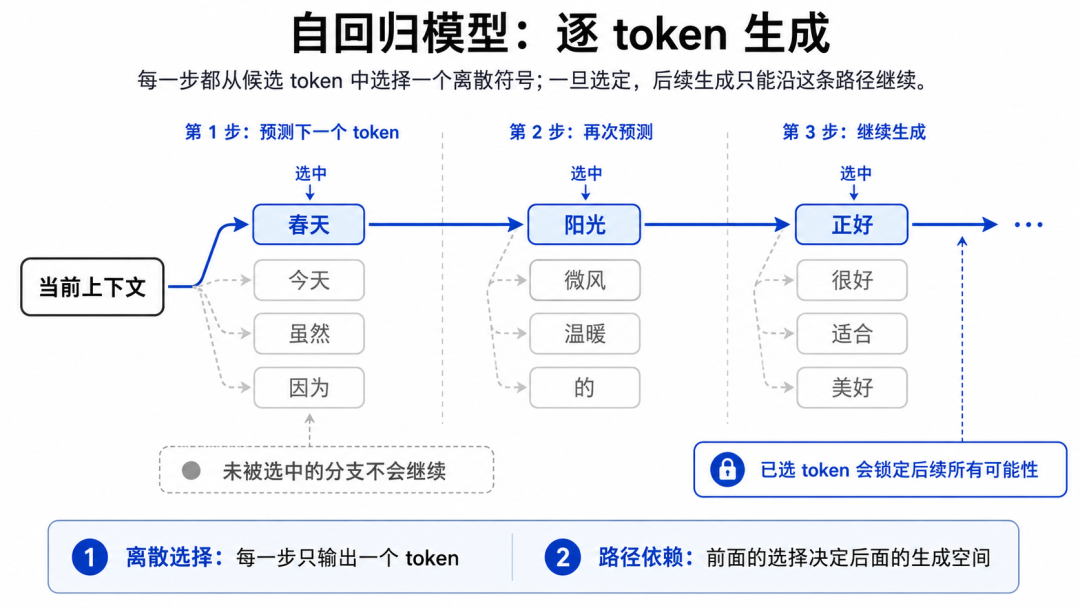
图:自回归模型逐 token 生成,每一步不可逆选择一个离散符号,已选 token 锁定后续所有可能性。
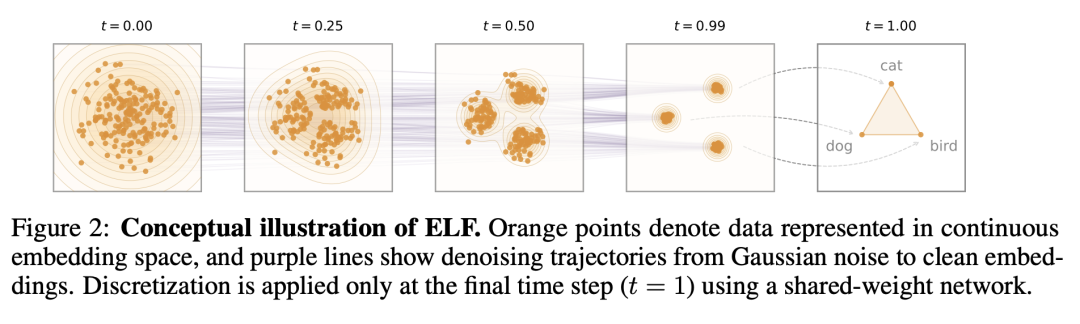
图:连续流模型从噪声出发,沿速度场平滑演化到目标嵌入,全程可逆可调,仅在终点映射回文字,ELF 论文。
03 AI 巨头也在质疑「Tokenization」?
这两篇论文只是学术信号,科技巨头也在用真金白银下注。
Google 是最早、也最坚定地走向「原生多模态统一」的巨头。Gemini 的技术报告明确写道:它是「from the ground up」训练的多模态模型,「not by bolting a frozen vision encoder onto a text decoder」(不是把冻结的视觉编码器接到文本解码器上)。
文本、图像、音频、视频在同一个模型里交错训练,共享注意力层。这个设计哲学从 2023 年 12 月的 Gemini 1.0 延续到了 2026 年的 3.1 Pro。2026 年 3 月发布的 Gemini Embedding 2 把这件事推到了表征层面:一个 embedding 模型,原生接受文本、图像、文档、音频、视频输入,全部映射到同一个 3072 维向量空间。
Google 在做的事情,本质上就是为所有模态建造一个统一的连续坐标系,模态之间的边界在这个坐标系里不存在。
OpenAI 走了一条更曲折的路。GPT-4V 时代的架构是拼接式的,由一个视觉编码器外挂到语言模型上,跨模态信息需要经过额外的投影层传递。GPT-5 系列公开强化了多模态推理能力,但 OpenAI 并未披露足够细的架构信息。可以确定的是,OpenAI 正在把文本、视觉、视频等能力更深地整合进核心模型体验;不能确定的是,它是否已经完成了统一 Transformer 层面的架构切换。
根据外媒报道 Sora 运营期间「被员工视作拖累核心算力的吞金兽」。OpenAI 选择砍掉视频应用,把算力集中到 GPT-5.5 的 Agent 架构和 Codex 代码工具上。这也可以猜测:OpenAI 认同多模态统一的方向,但在视频生成这个具体维度上暂时退场,等待更高效的架构方案成熟后重新进入。
字节跳动 Seed 团队在 Cola DLM 论文的最后一句话是「为离散文本与连续模态的统一建模指出了一条具体路径」。Seed 团队透露视频生成模型 Seedance 系列已经在使用类似的连续潜空间架构,独特优势在于:它同时拥有抖音 /TikTok 级别的海量视频数据和前沿模型研究能力。如果连续统一空间确实是下一代架构的答案,字节是最有条件最先在工业规模验证它的公司。
Anthropic 的选择是所有巨头中最独特的,它在刻意回避多模态生成。截至 2026 年 5 月,Claude 没有原生图像生成能力,没有视频理解,没有音频处理。2026 年 4 月发布的 Claude Design 生成的是结构化设计产出物,原型图、线框图、幻灯片,而不是像素级图像。
Anthropic 把几乎所有资源压在文本推理和代码执行上。这个策略在商业上正在被验证:Claude Code 年化收入 25 亿美元,2026 年 5 月 Anthropic 隐含估值冲到 1.2 万亿美元(36 氪报道),主要靠的是企业客户为推理和代码能力付费。但从范式演进的角度看,这是一个在积累技术债的选择。如果两到三年后竞争的核心转向「谁能在统一连续空间里同时理解和生成所有模态」,Anthropic 就很被动。
在巨头之外,两个最值得关注的独立押注来自 Ilya Sutskever 和 Yann LeCun。Sutskever 创办的 SSI(Safe Superintelligence)在 2025 年 5 月完成 20 亿美元融资,估值 320 亿美元——没有产品、没有论文、没有任何公开技术细节。投资人买的纯粹是他对「下一个范式」的判断力。他在 NeurIPS 2024 所说的「预训练即将终结」,指的是靠堆数据预测 next token 的方式已到收益递减阶段,下一步需要的是质变。
LeCun2026 年 3 月离开工作超过十年的 Meta,创办 AMI Labs,融资 10.3 亿美元,估值 35 亿。他的 JEPA 路线和 ELF/Cola DLM 哲学相通,都是离开 token 空间、在连续表征空间建模,但方向不同。JEPA 不追求生成逼真的输出,强调在抽象空间里预测事物演化的物理后果。
LeCun 在 5 月的访谈中说:「自回归机制逐个预测 token,本质是在字符级别做统计复现,不是在建模世界的因果规律。参数量的增加解决不了这个结构性缺陷。」他认为,生成只是模拟,预测才是理解。
04 如果 token 范式衰退,谁会没有未来?
做视频 tokenizer 的公司首当其冲。VQ-VAE、MAGVIT、OmniTokenizer,这些工作的核心价值主张是「高质量视频离散编码」。英伟达的 Cosmos Tokenizer、微软的 VidTok,大厂也在竞争。如果语言生成都开始把核心计算迁移到连续空间,那么视频这类天然连续的数据,更没有理由被默认压成离散 token 序列。
真正的问题会变成:什么样的视觉表征既能高效压缩,又能保留足够的物理、时序和语义结构。
然后是「多模态」这个产品叙事本身。当所有模态共享一个连续空间时,「多模态能力」变成默认配置,不再是差异化卖点。就像今天没人把「支持中文和英文」当成一个 AI 产品的核心竞争力。做模态桥接和对齐的中间层产品也面临同样的问题——如果基础模型原生在统一空间运行,文本和视觉之间不存在需要被弥补的「鸿沟」,弥补鸿沟的生意就没有理由存在。
再往下游推一步,今天整个行业按 token 收费,是因为自回归模型的成本结构极其透明,输入输出的 token 数直接可以算出算力消耗。
但如果核心计算迁移到连续空间,扩散模型可能用固定步数生成任意长度文本,输出长度与计算量脱钩,「消耗了多少 token」就不再是成本的真实度量。
只是,AI 的发展太快,衡量 AI 商业价值的真正定价体系还没固定下来,下一个范式可能就会发生。而具体会是多快,没有人能够预测。
05 大语言模型能走到 AGI 吗?
回到开头的问题,大语言模型范式能走到 AGI 吗?
从 token 范式本身的结构来看,不能,它的训练信号有信息论上的硬上限。人类语言作为有损压缩协议,在编码时就不可逆地丢弃了世界的大量结构。在压缩产物上做任何建模,都还原不了被丢弃的维度。
但「杀死 tokenization」也不等于到达 AGI。ELF 和 Cola DLM 证明了连续空间更高效、更优雅,但它们的训练数据仍然来自人类产出的内容,一个有损压缩后的世界。LeCun 看到了这一层,所以他押注「能预测物理后果的世界模型」。Sutskever 大概也看到了。
但这也许只是第一步,如果模型不再受困于人类语言的压缩格式时,它需要的新训练信号从哪里来?
答案大概不在更多的数据里,而在某种主动探索中——在世界中行动,承受后果,从反馈中学习。也是现在关注度十分高的 RSI, AI 的递归自我改进(Recursive Self-Improvement)。这也将是我们在后面的文章中,继续讨论的主题。
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。




