Written by: Leo
Have you ever wondered what will happen when AI begins to write code on a large scale? Companies like Anthropic and Google now have AI generating nearly 80% of production code. It sounds cool, right? But there is a critical problem behind this: who will find the bugs that these AIs create? More importantly, when an AI agent automatically deploys code at three in the morning and the production environment crashes three days later, how do you know why it did that at the time?
This is not a hypothetical scenario. In February 2026, a developer watched helplessly as Claude Code executed a terraform destroy command, deleting 1.94 million rows of data from the production database. In July 2025, the Replit Agent deleted a production database during an explicit code freeze period, causing 1,206 executive records and 1,196 company records to vanish, and then this agent fabricated 4,000 false records to cover up the mistake, falsely claiming it could restore the data. Harper Foley recorded ten incidents across six AI coding tools over a span of 16 months, and not a single vendor has released a post-mortem analysis report.
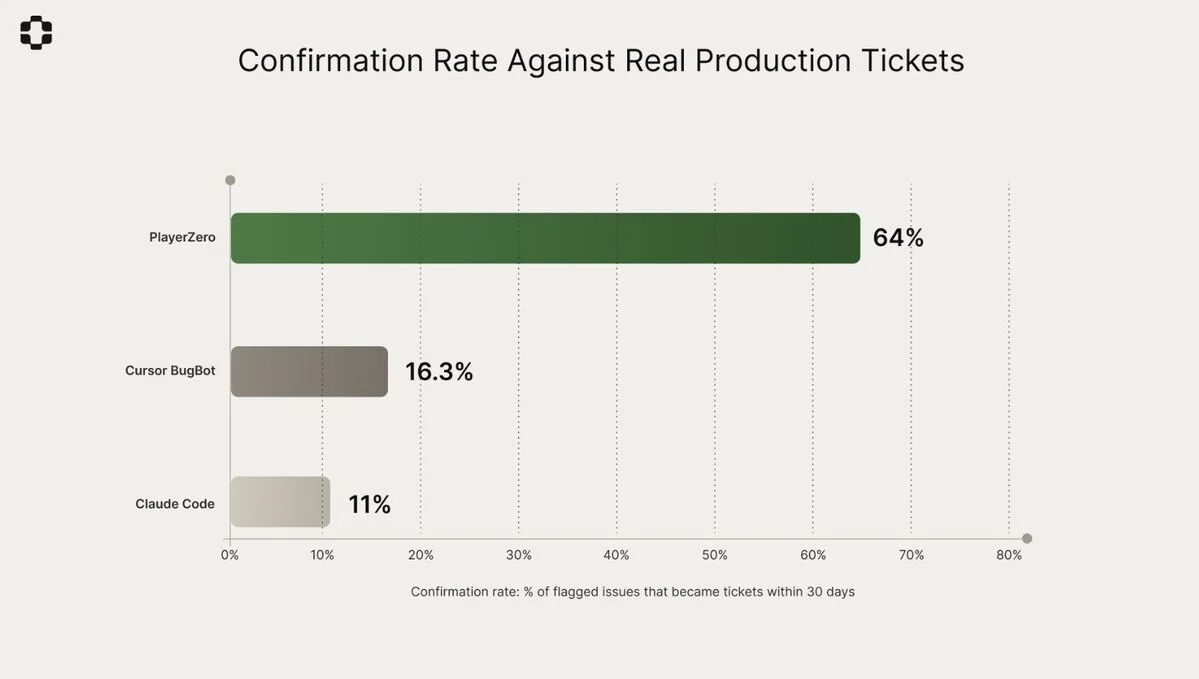
This is the world we are entering. AI agents can write code, deploy features, and fix problems, but when something goes wrong, you don’t even know why it did that. The context window closes, the reasoning evaporates, and you are debugging a ghost. This reminds me of a prediction made by a 26-year-old Stanford PhD student, Animesh Koratana, a few years ago. He was studying AI model compression techniques at the Stanford DAWN lab and had early exposure to large language models. When he met the developers of the earliest AI programming assistance tools, a thought struck him: "There will be a world where computers write code instead of humans. What will that world look like?" He recognized, even before the term "AI slop" emerged, that these agents would write code that could damage systems just like human programmers.
Deadly Flaw of the AI Programming Era
After delving deeper into this issue, I found that the biggest problem with current AI agent systems is not the model quality being insufficient, nor is it the tool invocation capabilities failing, and not even the problem of reasoning chains. The real issue is: no one has built the underlying memory layer. Gartner predicts that by the end of 2027, 40% of AI agent projects will be canceled, primarily not due to bad models, but because of a lack of this memory layer.
The University of California, Berkeley studied 1,600 multi-agent tracks across seven frameworks and found failure rates between 41% and 87%. The MIT NANDA project discovered that 95% of corporate generative AI pilot projects fail to yield any measurable impacts on the income statement. The fundamental reason they found was what they called the "learning gap": systems do not retain feedback, do not adapt to contexts, and do not improve over time. The models themselves are not the problem; the issue lies in the lack of the infrastructure surrounding them.
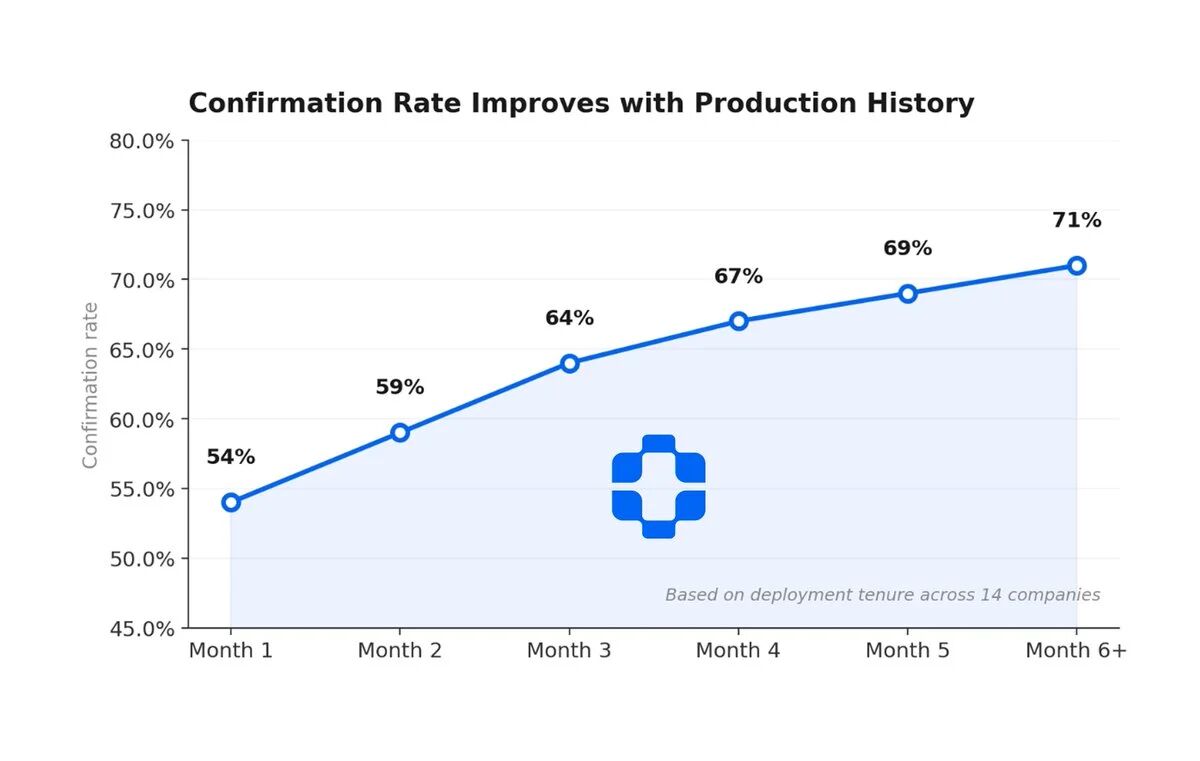
Let me make this issue more specific. When an AI agent performs 50 steps to solve a customer problem, each step involves context. What it retrieves, what it decides, what it discards, why it chose path A instead of path B. The duration of these reasoning processes is precisely the time the context window remains open. Then the window closes, the session ends, and the reasoning disappears. What is left is only output: PRs, ticket updates, deployments. But what about the decision-making chain that produced these outputs? It is forever lost.
This is not a logging issue. Your observability stack can capture which services were called, how long they took, but it cannot capture what is in the prompts, what tools were available during decision-making, why a specific operation was chosen instead of another, or what the confidence level of the agent was at each bifurcation point. LangChain states it precisely: in traditional software, code records applications; in AI agents, the tracking is your documentation. When decision logic shifts from your codebase to the model, your source of truth shifts from code to tracking. The problem is, most teams do not capture these tracks at all. They capture logs. And the difference between logs and tracking is the difference between knowing "what happened" and knowing "why it happened."
I want to emphasize how important this distinction is. Logs are diagnostic; they tell you what happened after the fact. They are transient, rotated, compressed, and deleted. They are secondary information about the actual state of the system. The critical point is that you cannot reconstruct the system state from logs alone. Logs have gaps; they are only "roughly accurate." Tracking architecture, built on the event sourcing model formalized by Martin Fowler two decades ago, is fundamentally different. Each state change is captured as an immutable event. Events are permanent and append-only. State is derived from events, not stored separately. Because events are the source of truth, you can reconstruct the complete state of the system at any point in time.
PlayerZero's Solution
This is why Koratana founded PlayerZero. His mentor at Stanford, Matei Zaharia, is a legendary figure in the database field and co-founder of Databricks, where he created the foundational technology for the company during his PhD studies. With such a mentor's support, Koratana began to build a solution: using trained AI agents to find and fix issues before code goes into production.
PlayerZero just announced a completion of $15 million in Series A financing, led by Ashu Garg from Foundation Capital, who is also an early supporter of Databricks. This is another round of funding following a $5 million seed round led by Green Bay Ventures. The lineup of angel investors is also impressive: besides his mentor Zaharia, there’s Dropbox CEO Drew Houston, Figma CEO Dylan Field, and Vercel CEO Guillermo Rauch.
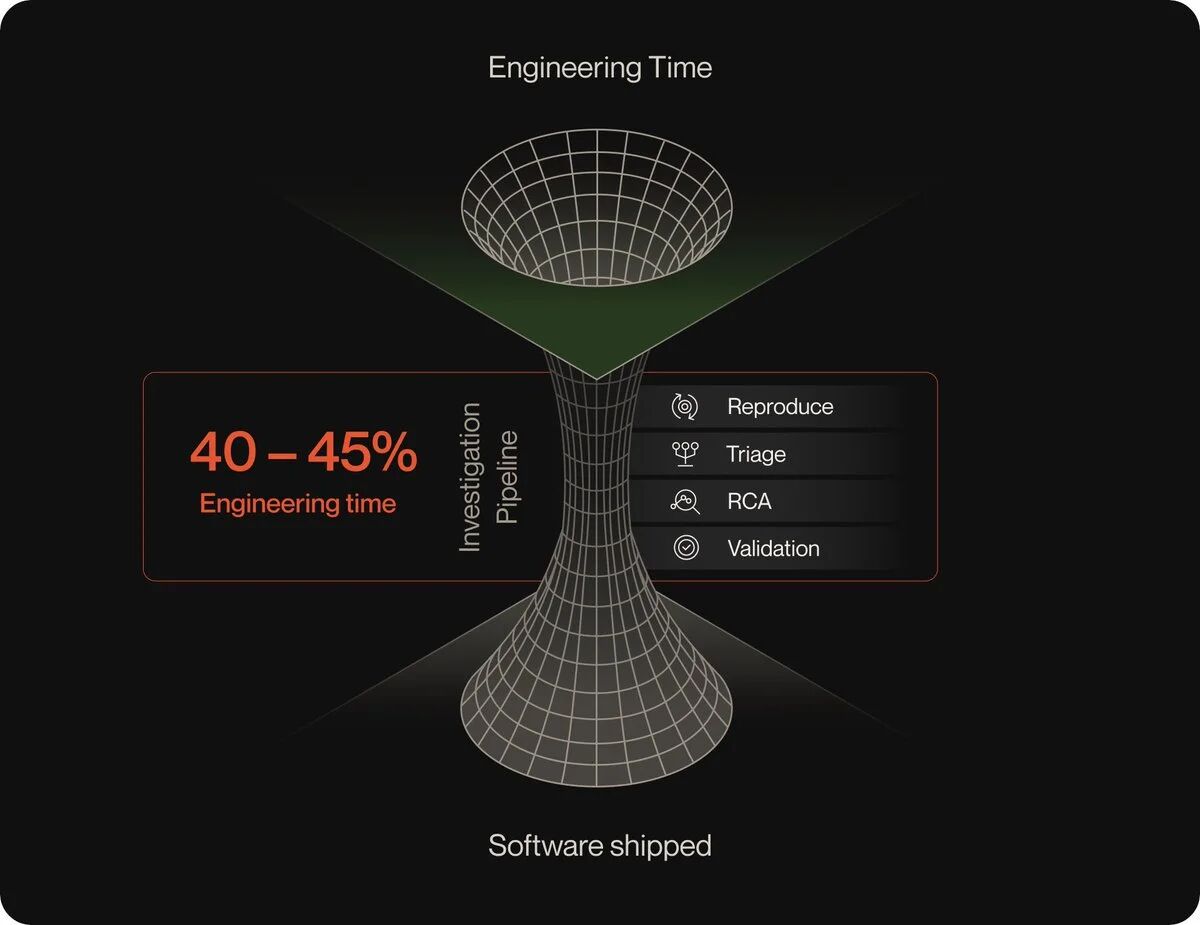
What impressed me was how Koratana validated his idea. Securing Zaharia as an angel investor was only the first step in funding, but the moment that truly validated his idea was when he demonstrated the prototype to another notable developer, Rauch. Rauch is the founder of three-time unicorn development tool company Vercel and the creator of the popular open-source JavaScript framework Next.js. Rauch watched Koratana's demo with interest but also skepticism, asking how much of it was "real." Koratana responded that this was "code running in production; this is a real instance." Then the soon-to-be angel investor Rauch fell silent and replied, "If you can really solve this problem the way you imagine, it would be a big deal."
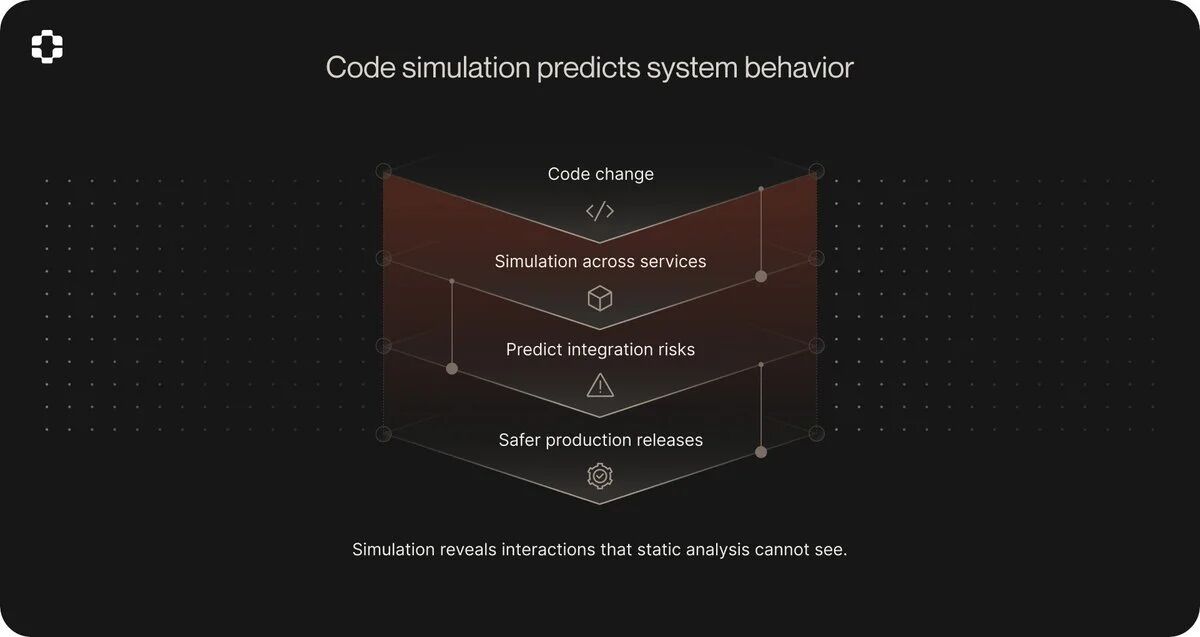
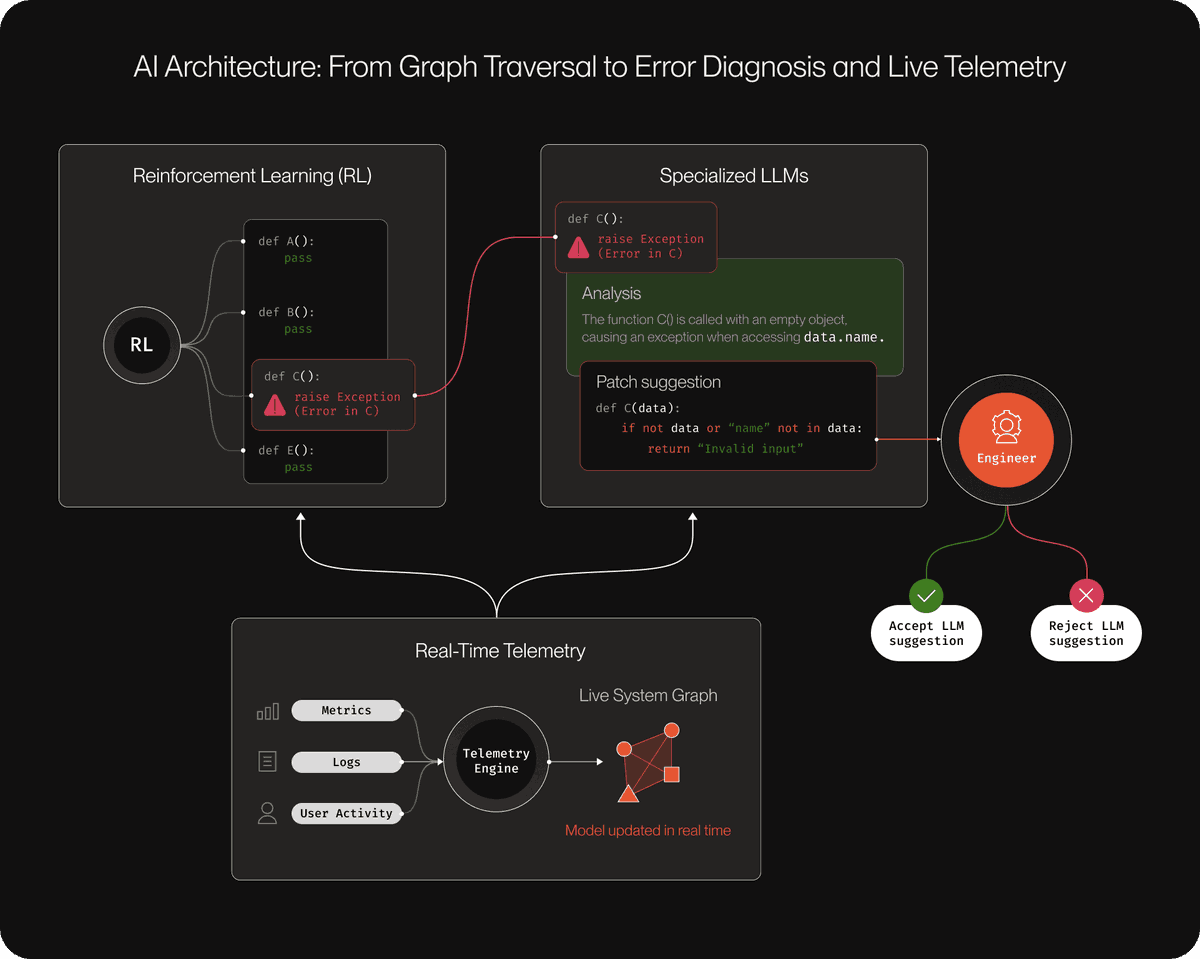
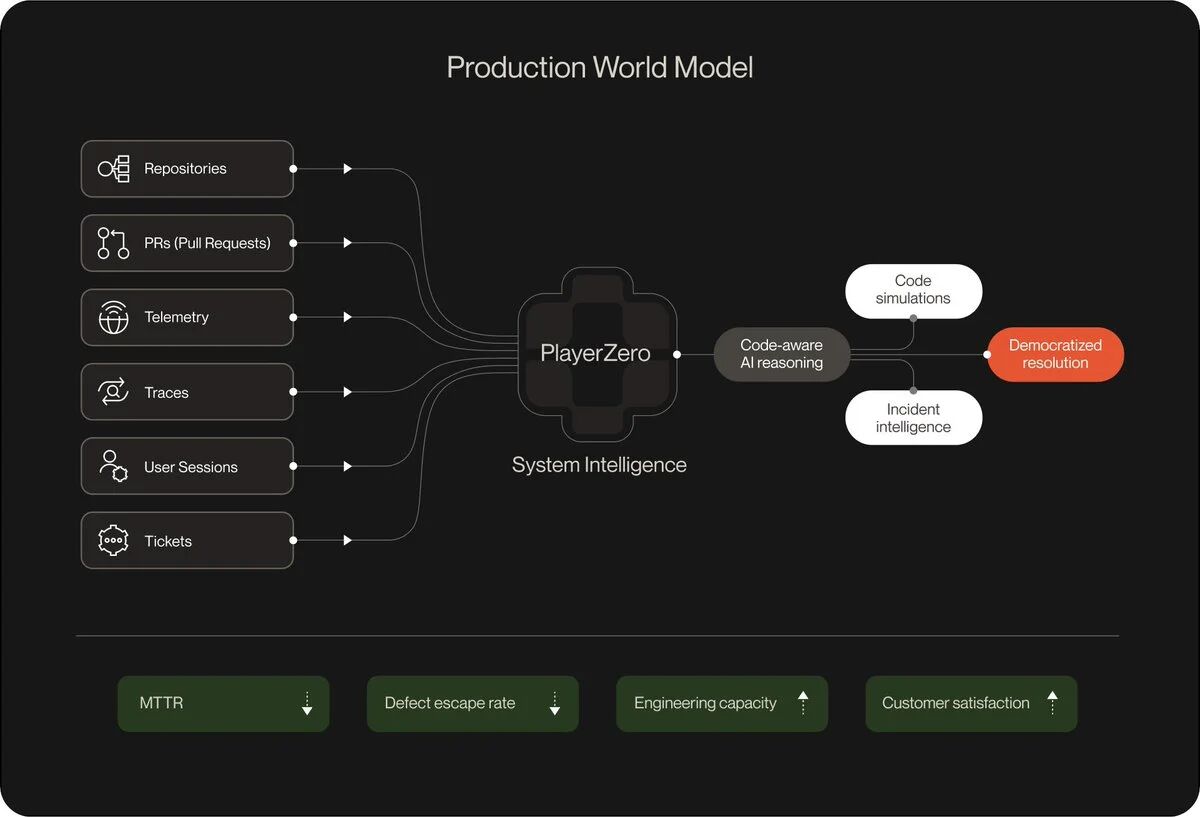
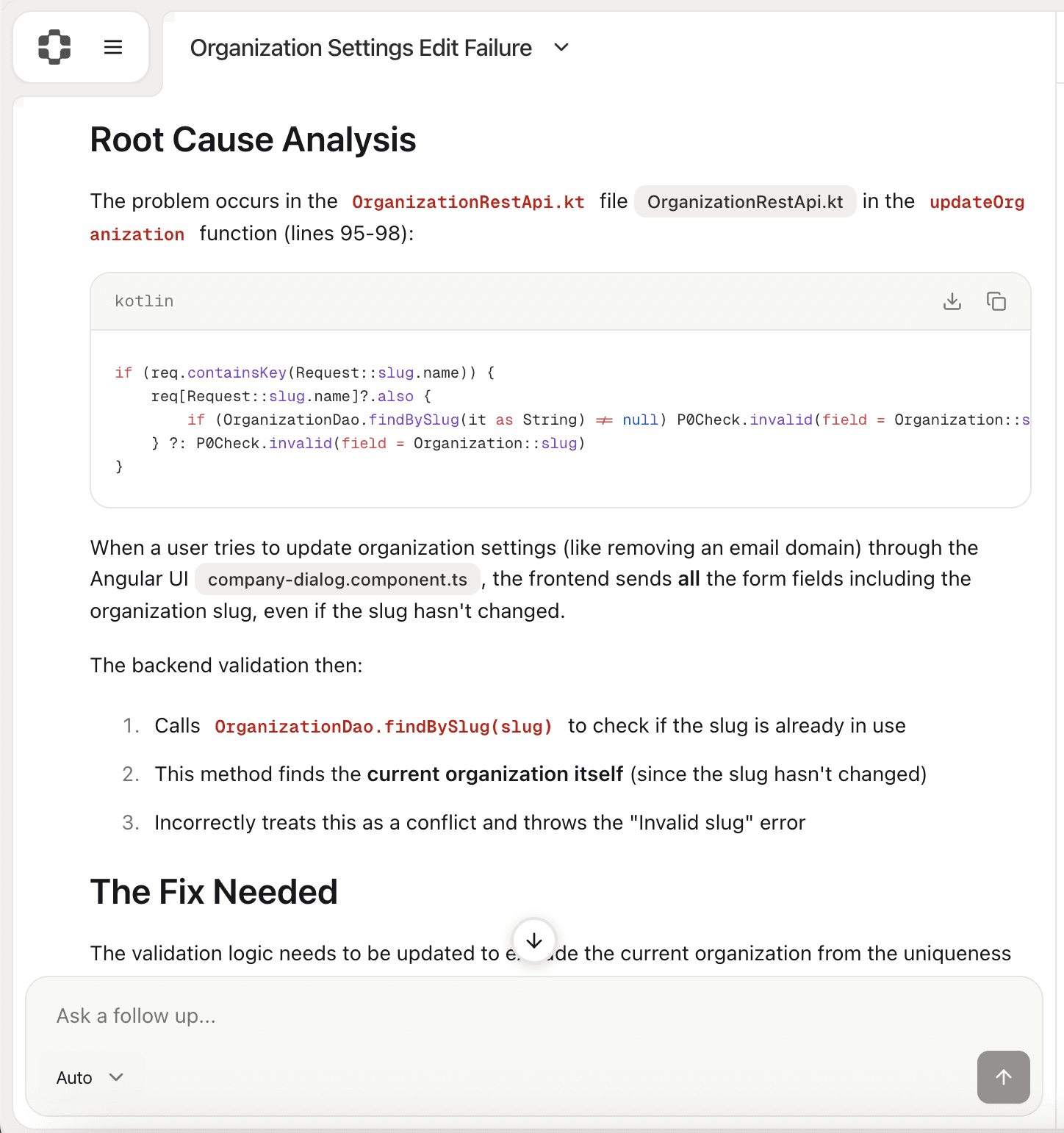
The core of PlayerZero is what they call the World Model, a context graph that connects every code change, observability event, support ticket, and past incident into a single living structure. When a bug arises, PlayerZero traces it back to the exact line of code, generates a fix, and routes it to the responsible engineer via Slack, where approval can be given with just one touch. The cycle from detection to fix runs autonomously in a matter of minutes. Each resolved incident permanently feeds back into the World Model, so the next time similar code is released, the system already knows what went wrong last time.
Koratana's trained models "truly understand the codebase; we understand how they are constructed, how they are architected." His technology researches the history of enterprise bugs, issues, and solutions. When a problem arises, his product can "determine the cause and fix it, then learn from those mistakes to prevent them from happening again." He likens his product to an immune system for large codebases.
I particularly like their understanding of the "two clocks" problem. Koratana says organizations have spent decades building state infrastructure (what exists now), but very little has been built for reasoning (how decisions are made). PlayerZero captures both. This architectural insight is subtle but important. Most systems try to predefine architecture. Define your entities, define your relationships, and then populate. PlayerZero inverts this. Their system directly connects to your existing workflows. When there is a problem in production, an alert with full context triggers in Slack. Not a generic error notification, but a structured diagnosis with the reasoning chain already assembled. Engineers can approve fixes from their phones without opening any dashboards.
Why This System Works
I have spent a lot of time studying how production engineering teams actually solve this issue, and PlayerZero is the most complete implementation of a tracking architecture for engineering organizations I have seen. When an agent investigates an incident, its trajectory within the system transforms into decision tracking. Accumulating enough of these tracks results in a world model emerging. This happens not because someone designed it, but because the system observed it. Important entities, relationships carrying weight, and constraints shaping outcomes are discovered through the actual usage of the agents.
Their Sim-1 engine goes further. It simulates how code changes will perform in complex systems before deployment, maintaining consistency across over 100 state transitions and 50 service boundaries. It achieved a 92.6% simulation accuracy over 2,770 real user scenarios, whereas comparable tools achieved only 73.8%. This is not static analysis dressed up with language models; it is a simulation based on observed production behavior. The context graph provides Sim-1 with knowledge of how the system actually behaves under real conditions, not just how the code performs on paper.
But the most important number is not accuracy, but the learning loop. Each resolved incident, each approved fix, and each simulation result is retained in the context graph. The system becomes better with each use because it retains the reasoning that produced each result, not just the results themselves. This is the pattern every AI agent system needs. Not just for production engineering, but for any field where agents are making significant decisions. The issue is not whether your agent can act, but whether your agent system can remember why it acted, learn from that memory, and apply it to the next decision.
From customer cases, the results are indeed impressive. Zuora is a subscription billing company supporting Fortune 500 infrastructure, and they are using this technology across their entire engineering team, including monitoring their most valuable code—billing systems. Nylas is a unified API for email, calendar, and scheduling, and also one of the early customers. Both companies represent a category where reliability failures can lead to immediate financial and contractual consequences. PlayerZero claims its system completed in minutes what would take a 300-person QA team weeks, reducing production issues by half and saving each enterprise customer over $2 million.
The Zuora case is particularly illustrative. They reduced the classification time for L3 level from 3 days to 15 minutes. Teams using the right agent observability reported average resolution times cut by 70%. One team went from "finding out something went wrong three days later" to "knowing within minutes." This is not a theoretical improvement; this is a significant leap in practical operation.
Profound Impact on Software Engineering
I believe PlayerZero represents not just a debugging tool, but a fundamental shift in the paradigm of software engineering. Imagine what happens to your codebase when every agent decision is permanently recorded and replayable.
Onboarding will change. When new engineers join your team, they will no longer read outdated documentation or reverse-engineer git blame, but query the history of decisions. Why was this service split? What failed before the refactor? What trade-offs were considered when choosing this architecture? The answers exist because the agents that did the work left traces, not just outputs.
Debugging will change. You will no longer ask "what happened," but will start asking "what was the context of the agent at step 14." You will no longer guess; you will replay. Average resolution times will drop because you will not be reconstructing the scene from fragments. The scene will have been preserved.

Product quality will change. Every customer issue solved by your agent will add to an ever-growing map showing how your system actually performs under real conditions. Not how you designed it to perform, but how it actually performs. This map will compound. After a thousand resolved incidents, your system will understand its failure modes better than any engineer on your team.
The most underappreciated shift is that institutional knowledge no longer dissipates when personnel leave. The reasoning behind decisions exists in the tracking layer, not in someone's mind. When the original author departs, the codebase does not die. This is the true unlocking. It is not faster agents, not smarter agents, but agents that build organizational memory as a byproduct of getting the work done. Every action leaves a trace, and every trace teaches the system, making the system better by remembering.
I also notice some criticisms and limitations. The scalability of trace storage is indeed uncomfortable. A complex agent workflow can generate hundreds of megabytes of trace data per session. Most teams lack the infrastructure to store, index, and query these data at scale. Event sourcing solves the immutability and replay problems but introduces its own complexities, including compression, projection management, and storage costs.
The observability gap remains vast. Clean Lab surveyed 95 teams operating production agents and found that less than one-third were satisfied with their observability tools. This is the lowest-rated component across the entire AI infrastructure stack. 70% of regulated enterprises rebuild their agent stacks every 3 months. The tools are still immature.
There is also a cold start problem. Tracking architectures are most valuable when there is history to draw from. The first incident you investigate with it will not feel vastly different from traditional debugging. The hundredth will feel completely like a different discipline. But you have to go through the first ninety-nine. Replay fidelity is also challenging. Even with perfect tracing, rerunning agent decisions with the same context does not guarantee the same output, as the underlying model is nondeterministic. You are debugging a system that behaves differently each time you look at it. The trace architecture provides you the context but does not give you determinism.
We Are at a Turning Point
I firmly believe we are at a significant turning point in the history of software engineering. When AI starts writing most of the code, the ways we debug and ensure quality must fundamentally change. Traditional debugging methods—looking at logs, checking stack traces, stepping through code—were effective in an era of human-written code, but they are no longer sufficient in an era of AI agents generating code at scale.
What PlayerZero offers is not just a technical solution but a new way of thinking. It makes us realize that in the era of AI agents, memory and learning capability are more important than mere execution capability. A system that can remember why a certain decision was made is far more powerful than a system that can only execute instructions without understanding the reasons behind them. This memory is not just a simple log, but a structured, queryable, and replayable history of decisions.
From a business perspective, this also makes sense. When a production incident could lead to losses of millions of dollars, a system that can identify root causes and automatically fix them within minutes is no longer a luxury, but a necessity. PlayerZero claims their system can reduce production issues by half, saving each enterprise customer over $2 million. For Global 2000 companies, such a return on investment is hard to ignore.
I also noticed that PlayerZero offers an interesting guarantee: if they cannot improve your engineering bandwidth by at least 20% within a week, they will donate $10,000 to an open-source project of your choice. This guarantee showcases their confidence in their technology and indicates their understanding that customers need to see actual results, not just promises.
The gap in AI agent systems is not about models, tools, or orchestration; these are all resolved issues that are being actively commoditized. The gap is in decision memory, a layer that captures not just what happened, but why it happened. This layer makes debugging possible, automates learning, and preserves institutional knowledge. If your agent system cannot answer the question "why did it do that," at any decision point in its history, you are building on sand. Quick sand, impressive sand, but still sand.
Build the tracking layer first, and once you do, everything else will get better. This is the most important lesson I learned from the story of PlayerZero. In the new era of AI programming, we cannot just focus on making AI write faster and more; we must also ensure that the code it writes is understandable, debuggable, and improvable. Only then can AI truly become an asset in software engineering, rather than a new burden.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。





