Written by: Founder Park
The leak of Claude Code's source code has attracted considerable attention on platforms like X.
However, what deserves even more attention this time is not the leak itself, but the very typical design of the production-grade AI agent harness of Claude Code, which completely showcases what a mature Autonomous Agent product should look like, from the underlying engineering implementation to the upper-level product decision logic, including various details.
Combining analysis of the source code from Substack and Hacker News, we have compiled some key points in Claude Code’s Agent architecture design that developers should pay attention to and learn from.
01 The real challenge lies in the Harness beyond the model
The core of Claude Code’s architecture is a local runtime shell for a “Harness,” relying more on the engineering and reliability of the Harness itself.
According to the public mirror repository nirholas/claude-code, the TypeScript source code of Claude Code spans about 1,900 files, totaling over 512,000 lines of strictly typed TypeScript, built on the Bun runtime, driven by React and Ink for terminal UI.
The architecture documentation describes the Claude Code system as quite extensive: a large QueryEngine, a centralized tool registry, dozens of slash commands, persistent memory, IDE bridging, MCP integration, remote sessions, plugins, skills, and a task layer that supports background and parallel work.
A more accurate metaphor is that Claude Code resembles an operating system for software work, stacking permission management, memory layers, background tasks, IDE bridging, MCP pipelines, and multi-agent orchestration around the model.
Vikash Rungta referred to this in his reverse engineering analysis as Harnes: a local runtime shell that wraps the LLM (Brain) inside tools, memory, and orchestration logic (Body), enabling the model to act in the real world.
To understand Claude Code, it is essential to grasp the three generational evolutions of Agent architecture:
The first generation is Chatbots, stateless Q&A;
The second generation is Workflows, embedding LLM into code-driven DAG flows using tools like n8n and LangChain, where code determines what the model does next;
The third generation is Autonomous Agents, where the model controls the loop, and the runtime merely acts as an executor.
Claude Code is a commercial product belonging to the third generation.
The source code of Claude Code also indicates that the real challenge lies in the Harness, providing filesystem access, shell, layered memory, and declarative extension capabilities for any supporting tool-calling LLM. All of this must operate within a bounded autonomous loop constrained by composable permissions.
02TAOR Loop Design: The more "foolish" the Orchestrator, the more stable the architecture
The execution engine of Claude Code is a loop called TAOR: Think-Act-Observe-Repeat. The design itself is not complicated, but the underlying design philosophy is worth paying attention to.
Its Orchestrator is designed to be extremely "simple," only responsible for driving the loop, executing tool calls, and perceiving results. All reasoning, decision-making, and when to stop are delegated to the model. The runtime does not know what the code is, does not know where the files are; it simply runs the loop and allows the model to decide the next step.
In summary:The simpler the runtime, the more stable the architecture. Intelligence is vested in the model, while certainty is granted to the framework.
This sharply contrasts with earlier attempts by LangChain to implement various "intelligent orchestration" at the framework level. LangChain tended to embed orchestration logic into the code, using complex orchestrators to control every step of the LLM. Claude Code's approach is to allocate all reasoning, decision-making, and stopping judgments to the large model itself. The core logic of the TAOR loop is only about 50 lines, yet it gives the model infinite operational space.
Similarly, in the tool layer, this "dumb" philosophy is followed. Claude Code does not equip the model with 100 specialized tools but instead provides just four fundamental capabilities: Read, Write, Execute, Connect. Among them, Bash is the universal adapter, allowing the model to use any tools a human developer might use—git, npm, docker—all accomplished through shell combinations. Do not build 100 tools; give the model a shell and let it assemble its own.
As the model grows stronger, the scaffolding should get thinner, not thicker. Hardcoded scaffolding should be proactively removed as the model's capabilities improve; the architecture should become thinner over time. If you find yourself adding more scaffolding to the framework with each model upgrade, it indicates you are working against the model rather than leveraging it.
03Context Window is a scarce resource,it is not better the larger it is
Context is not better just because it is larger; it is better when it is cleaner. This is a design principle that runs throughout the entire architecture of Claude Code.
Generally speaking, Context Collapse is the most common failure mode in Agent systems. As conversations progress, the context window gets filled, memories degrade, illusions occur, and the Agent begins to lose direction in the noise it has accumulated. However, Claude Code treats the Context Window as a scarce resource that needs to be actively managed and has built a system around Context with automated compression, sub-agent isolation, and detailed cache economics defenses.
The first level is Auto-Compaction. It is automatically triggered when the usage of Context reaches about 50%, replacing original dialogue turns with summaries generated by the LLM while freeing up space and retaining key decisions. This is not simply truncating history but compressing it with summaries to ensure that important information is not lost. The corresponding failure mode for this mechanism is called Context Collapse; the solution is: Auto-compaction at ~50% + sub-agents with isolated context windows.
The second level is Sub-Agent Isolation. It offloads heavy exploration and research tasks to independent sub-agents. Sub-agents run their own independent TAOR loops, have their own context budgets, and upon task completion, return only a summary to the main Agent. This way, regardless of how many tokens are consumed by the sub-task, the main Agent's Context remains uncontaminated.
From a code structure perspective, the design of this mechanism is very refined. The sub-agent runtime has its own maxTurns limit, its own compaction mechanism (independent compression, does not affect main dialogue), and its own MEMORY.md. Once the main Agent dispatches a sub-agent, it waits for just a summary to return, making the entire sub-task's token consumption completely transparent and isolated from the main Context.
The third layer is Prompt Cache Economics. In promptCacheBreakDetection.ts, 14 cache-break vectors are tracked, meaning 14 scenarios that can invalidate the prompt cache. There is also a function called DANGEROUS_uncachedSystemPromptSection() in the code; the name alone serves as a document: be careful when adding things here, as it will break the cache. The code also contains multiple sticky latches to prevent mode-switching from disrupting the locking mechanism of the prompt cache.
When you pay per token, cache invalidation is no longer a computer science joke, but a financial issue.
Additionally, there is a detail regarding: Session Continuity. In Claude Code, sessions are not one-time affairs. They operate like git branches, allowing for checkpointing, rollback, or even forking an exploration direction into a new path. This means that the management of Context is not only within a single session but spans across sessions.
04The core of the memory system is indexing,not storage
The design of Claude Code’s memory system is also very interesting.
Most people envision "Agent memory" as a bigger backpack, the more it holds, the better. But Claude Code’s memory system resembles an archival system with a strict librarian.
The core design principle is:Memory is indexing, not storage. Information that can be re-derived from the codebase should never be stored.
Architecturally, Claude Code’s memory system is divided into six layers, loaded by layer at the start of each session:
Managed Policy (organizational-level policy): Unified standards at the enterprise or team level
Project CLAUDE.md (project configuration): Specific instructions and context for the current project
User Preferences (user preferences): Personal habits and settings
Auto-Memory (automated learning mode): User patterns that the Agent learns from historical interactions
Session (session context): Temporary information for the current session
Sub-Agent Memory (sub-agent memory): Specialized memory independently maintained by sub-agents
Among these, the Auto-Memory loop even allows the Agent to learn the user's working patterns and write these patterns into MEMORY.md for future sessions. Users do not need to repeatedly explain the same things; the Agent learns and remembers important information from previous interactions.
At the same time, the memory mechanism of Claude Code’s sub-agents is also worth mentioning. In the configuration of custom sub-agents, you can set memory: user, and the Agent will write learned patterns to ~/.claude/agent-memory/name>/MEMORY.md, automatically loading the first 200 lines at the next call. This means that each sub-agent can have its own independent, continuously accumulating specialized memory.
More crucially, this system has the ability to self-edit actively. It not only records but also rewrites, deduplicates, and even eliminates contradictory information; expired and invalid memories are viewed as "liabilities" rather than assets.
The design of Claude Code’s memory system also reflects the fact that, at a product level, memory is not just a feature; it is a core retention mechanism that determines whether users continue to use it, as users genuinely expect an Agent that "learns."
05The design of the permission system is more like UX design,trust is composable
Permission and security issues are prerequisites for Agents to progress to enterprise applications.
The permission system of Claude Code is designed as a five-tier trust spectrum:
plan: read-only, cannot write at all, lowest trust level
default: requires confirmation before editing and shell operations, standard mode
acceptEdits: automatically approves file edits, still requires confirmation for shell operations, medium trust
dontAsk: automatically approves all operations within a whitelist, high trust
bypassPermissions: skips all checks, only for managed organizations, highest trust
Each tool call undergoes multi-layer whitelist validation in a static analysis layer. The bashSecurity.ts includes 23 numbered security checks, including:
18 blocked Zsh built-in commands
Defense against Zsh equals expansion: writing like =curl can bypass permission checks for curl
unicode zero-width character injection
IFS null-byte injection
A malicious token bypass discovered during HackerOne review
This composable trust spectrum enables Claude Code to adapt to completely different usage scenarios: from highly restricted enterprise environments where everything must be confirmed to personal development environments running at full speed. The design of permissions is more like UX design. For Agent products, this is also the "threshold" for moving from demo to enterprise production environments.
At the same time, Claude Code has a lower-level, clever mechanism in which API requests undergo authentication beneath the JS layer.
In the system.ts file, each API request contains a cch=00000 placeholder. Before the request truly leaves the process, Bun's native HTTP stack (written in Zig, running underneath the JavaScript runtime) replaces these five zeros with a calculated hash value. The server verifies this hash to confirm that the request originates from a genuine Claude Code binary, not a third-party forged client.
The reason for using a placeholder of equal length is to ensure that the replacement does not alter the Content-Length header and that no buffer reallocation is required; this is a detailed engineering consideration. The entire computation process occurs beneath the JS layer, completely invisible to any code running in JS. Essentially, this is an API call DRM implemented at the HTTP transport layer.
This also serves as the technical foundation behind Anthropic’s previous issuance of a lawyer's letter to OpenCode. Anthropic is not only requesting that third-party tools refrain from using their API; the binary itself proves its identity through encryption. After receiving the legal notice, the OpenCode community had to resort to session stitching techniques and authentication plugins for this very reason.
06Multi-Agent Orchestration,from Sub-Agents to Agent Teams
The multi-Agent orchestration of Claude Code adopts a horizontal scaling approach, divided into two layers.
The first layer: Sub-Agent
Sub-Agents run as independent processes, each with its own TAOR loop, context budget, maxTurns limit, and memory. After completing tasks, they return only summaries to the main Agent, and the main Agent's Context remains completely unaffected.
Claude Code includes three built-in preset sub-agents, each with specific functions:
Explore: Uses the Haiku model (fast and low cost), only has read-only tools (Read, Grep, Glob), specifically for file discovery and codebase exploration
Plan: Inherits the model of the main Agent, only has read-only tools, specifically for gathering information about codebase research and planning
General-purpose: Inherits the main Agent’s model and is equipped with a full set of tools for handling complex multi-step operations
Custom sub-Agents are defined through .md files with YAML frontmatter, allowing specification of model (sonnet/opus/haiku/inherit), permission modes, maxTurns, tool whitelist, tool blacklist, and even pre-loading specific skills. There are three storage locations: ~/.claude/agents/ (user-level), .claude/agents/ (project-level), or specified via --agents CLI parameter.
Sub-Agents also support both foreground and background execution modes. The foreground mode blocks the main dialogue, with permission inquiries and questions passed on to the user; background mode runs concurrently while the user continues to work, collecting permissions beforehand, and if it encounters permission requests that have not been pre-approved, the tool call fails outright while the Agent continues to function. Pressing Ctrl+B can switch the running foreground Agent to the background.
The second layer: Agent Teams
This is no longer a hierarchical relationship where the main Agent dispatches sub-Agents, but rather completely independent Claude Code instances coordinating tasks through a shared file system. The differences between the two are:
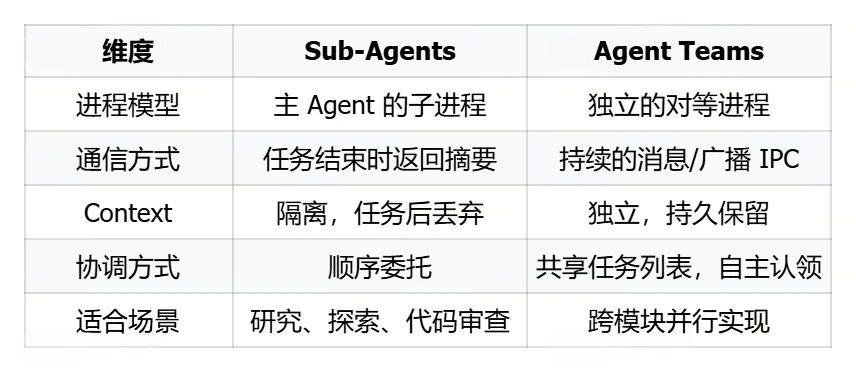
The coordination mechanism for Agent Teams includes: Shared Task List (task status visible to all Agents, autonomously claiming the next unassigned task after completing the current one), Unicast Message (sent to a specific Teammate), Broadcast (sent to all Teammates, noting that costs increase linearly with team size), and Automatic Idle Notification (automatically notifying Lead when a Teammate stops completing a task).
Additionally, there are two special quality gate Hooks aimed at teams: TeammateIdle (triggers when a Teammate is about to become idle; returning exit code 2 can send feedback to prompt continued work) and TaskCompleted (triggers just before a task is marked as complete; returning exit code 2 can prevent completion and request fixes).
However, Agent Teams are still an experimental feature and need to be enabled via the CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS=1 environment variable or settings.json.
07The yet-to-be-released KAIROS,an Always-On Agent
In this leak, there is a not-yet-released feature of Claude Code called KAIROS, which allows an Agent to run continuously in the background.
According to the code path in main.tsx, KAIROS is a feature-gated unreleased mode, containing the following characteristics:
/dream skill, for nightly memory distillation
Daily append-only logs
GitHub Webhook subscription
Background Daemon processes
Every 5 minutes Cron schedule refresh
Patching these features together forms a completely different product shape: a persistent background, continuously learning, proactively sensing changes in the codebase Autonomous Agent. It’s not about summoning it to help you; it exists continuously, actively working for you.
The existing Claude Code is a summon-style Agent: you open a terminal, it assists you, you close the terminal, it stops. But KAIROS envisions the next generation: an Agent continuously running in the background, perceiving changes in the codebase through GitHub Webhook, conducting nightly memory distillation, compressing the day's working patterns and project statuses into long-term memory, ready and "pre-heated" by the next morning.
While it’s unclear how far Anthropic has progressed internally in the development of KAIROS, the leak illustrates that Claude Code’s product ambitions have long surpassed "LLM + command line wrapping," trending toward becoming a "terminal operating system-level Agent."
08Some Easter eggs:Anti-Distillation Mechanism, Undercover Mode
Additionally, within the leaked source code, there are some very controversial engineering decisions that have been uncovered.
Anti-Distillation Mechanism
Lines 301-313 of claude.ts contain a flag called ANTI_DISTILLATION_CC. When it is enabled, Claude Code will carry the anti_distillation: ['fake_tools'] parameter in API requests, and the server will silently inject fake tool definitions into system prompts.
The logic is straightforward: if someone is recording Claude Code’s API traffic to train competing models, these fake tools will contaminate the training data. This mechanism is controlled by the GrowthBook feature flag tengu_anti_distill_fake_tool_injection, activated only for first-party CLI sessions.
A second layer mechanism is found in betas.ts, lines 279-298: server-side connector-text summaries. When enabled, the API buffers the Assistant's reasoning texts between tool calls, returning a summarized version with an encrypted signature. In subsequent rounds, the original text can be recovered from the signature. Those recording API traffic will only obtain summaries, not the complete reasoning chain.
Undercover Mode
The undercover.ts file has about 90 lines and implements a one-way gate: when Claude Code is used in non-Anthropic internal repositories, it instructs the model to never mention internal code names (like Capybara, Tengu), internal Slack channels, repository names, or even the name Claude Code itself.
Line 15 contains a comment that reads:
There is NO force-OFF. This guards against model codename leaks.
You can force enable it using CLAUDE_CODE_UNDERCOVER=1, but there is no way to force it off. In external builds, the entire function is eliminated as trivial returns by dead code. This is a one-way gate.
This means that Anthropic employees using commits and PRs generated by Claude Code in open-source projects will not have any markers indicating AI involvement. How to balance commercial defense needs with AI transparency ethics is also a matter worth contemplating.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







