Original Title: "Understanding Anthropic's Claude Code Source Code: Why is it More User-Friendly than Others?"
Original Author: Yuker, AI Analyst
On March 31, 2026, security researcher Chaofan Shou discovered that the source map file in the Claude Code package released by Anthropic on npm was not stripped.
This means: The complete TypeScript source code of Claude Code, 512,000 lines and 1,903 files, has been exposed to the public internet.
Of course, I could not possibly read through so much code in just a few hours, so I approached this source code with three questions:
1. What are the essential differences between Claude Code and other AI programming tools?
2. Why does its coding "feel" better than others?
3. What exactly is hidden within those 510,000 lines of code?
After reading it, my first reaction was: This is not an AI programming assistant; this is an operating system.
1. First, let’s tell a story: If you were to hire a remote programmer
Imagine you hired a remote programmer and gave them remote access to your computer.
What would you do?
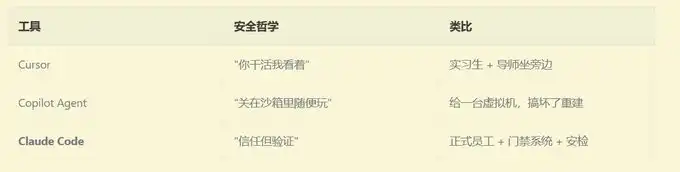
If you were to follow the approach of Cursor: you would let them sit next to you, glancing at them before they execute each command, and click "allow." Simple and straightforward, but you have to watch constantly.
If you were to take the approach of GitHub Copilot Agent: you would give them a brand new virtual machine to play around in. After they finish, they submit the code, you review it, and then merge it. Safe, but they cannot see your local environment.
If you were to take the approach of Claude Code:
You would let them use your computer directly—but you set up an extremely sophisticated security system for them. What they can and cannot do, which operations require your approval, which they can do on their own, and even if they want to use rm -rf, it must pass through 9 layers of review before execution.
This is three completely different security philosophies:
Why did Anthropic choose the hardest path?
Because only in this way can AI work with your terminal, your environment, your configuration—this is what it means to "truly help you write code," rather than "writing a piece of code in a clean room and then copying it over."
But what is the cost? They wrote 510,000 lines of code for this.
2. What you think Claude Code is vs. what Claude Code actually is
Most people think AI programming tools work like this:
User input → Call LLM API → Return result → Display to user
Claude Code actually works like this:
User input
→ Dynamically assemble 7 layers of system prompts
→ Inject Git status, project conventions, historical memory
→ 42 tools each with their own user manual
→ LLM decides which tools to use
→ 9 layers of security review (AST parsing, ML classification, sandbox checks...)
→ Permission competition resolution (local keyboard / IDE / Hook / AI classifier competing simultaneously)
→ 200ms anti-misfire delay
→ Execute tool
→ Results returned in a streaming fashion
→ Context approaching limit? → Three-layer compression (micro-compression → automatic compression → complete compression)
→ Need to parallelize? → Generate sub-agent swarm
→ Loop until the task is complete
I believe everyone is curious about what’s above, so let’s break it down one by one.
3. The first secret: Prompts are "assembled," not written
Open src/constants/prompts.ts, and you will see this function:
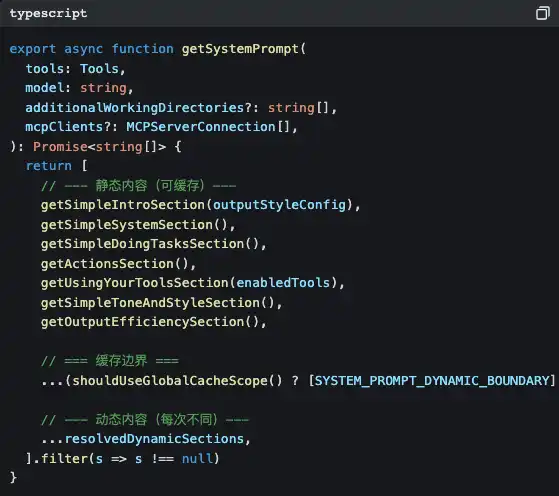
Did you notice that SYSTEM_PROMPT_DYNAMIC_BOUNDARY?
This is a cache boundary. The content above the boundary is static, and the Claude API can cache it, saving token costs. The content below the boundary is dynamic—your current Git branch, your CLAUDE.md project configuration, the preferences you previously input... each conversation is different.
What does this mean?
Anthropic treats prompts as the output of a compiler to optimize. The static part is "compiled binary," and the dynamic part is "runtime parameters." The benefits of doing this are:
1. Cost-saving: Static parts use cache, avoiding repeated billing
2. Fast: Cache hits directly skip the processing of those tokens
3. Flexible: Dynamic parts allow each conversation to be aware of the current environment
Each tool has its own independent "user manual"
What amazes me even more is that each tool directory has a prompt.ts file—this is a user manual specifically written for the LLM.
Take a look at the BashTool's (src/tools/BashTool/prompt.ts, about 370 lines):
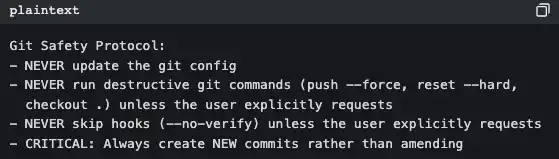
This is not documentation written for humans; this is a code of conduct written for AI. Every time Claude Code starts, these rules are injected into the system prompts.
This is why Claude Code never arbitrarily executes git push --force, while some tools do—it’s not that the model is smarter, it's that the rules have been clearly stated in the prompts.
Moreover, the internal version of Anthropic is different from the version you use
The code contains many branches like this:
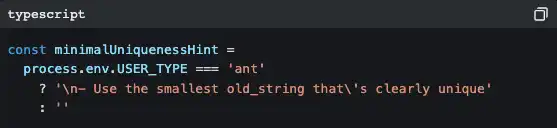
ant represents Anthropic internal employees. Their version has more detailed coding style guidelines ("Do not write comments unless the WHY is not obvious"), more aggressive output strategies ("inverted pyramid writing method"), and some experimental features still undergoing A/B testing (Verification Agent, Explore & Plan Agent).
This indicates that Anthropic itself is the largest user of Claude Code. They are using their own product to develop their own product.
4. The second secret: 42 tools, but you have only seen the tip of the iceberg
Open src/tools.ts, and you will see the tool registration center:
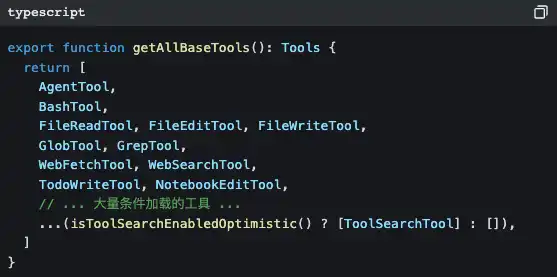
42 tools, but most of them you have never seen directly. Because many tools are lazily loaded—they are only injected on demand through ToolSearchTool when the LLM needs them.
Why do this?
Because for every additional tool, the system prompts have to add another description, costing more tokens. If you just want Claude Code to help you modify a line of code, it doesn’t need to load the "scheduler" and "team collaboration manager."
There’s an even smarter design:
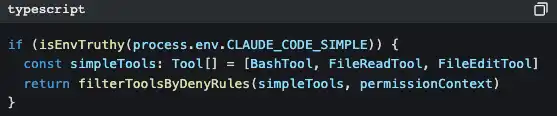
Set CLAUDE_CODE_SIMPLE=true, and Claude Code is left with only three tools: Bash, read file, and modify file. This is a backdoor for minimalists.
All tools come from the same factory
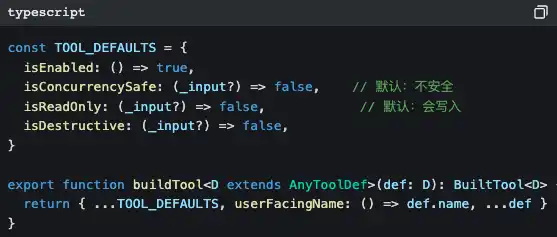
Notice those default values: isConcurrencySafe defaults to false, isReadOnly defaults to false.
This is called fail-closed design—if a tool's author forgets to declare safety attributes, the system assumes it is "unsafe and will write." Better to be overly cautious than to miss a single risk.
The iron rule of "read before modify"
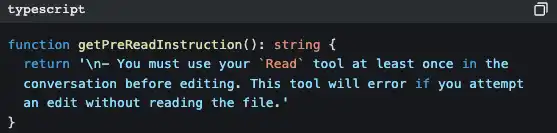
FileEditTool will check if you have already read the file with FileReadTool. If not, it will directly throw an error and not allow modification.
This is why Claude Code does not "write a piece of code to cover your file out of thin air" like some tools—it is forced to understand before it modifies.
5. The third secret: Memory system—why it can "remember you"
Those who have used Claude Code all feel that: it seems to really know you.
You tell it "don’t mock the database in tests," and during the next conversation, it won’t mock anymore. You tell it "I am a backend engineer, a React novice," and it will use backend analogies when explaining frontend code.
Behind this is a complete memory system.
Using AI to retrieve memory
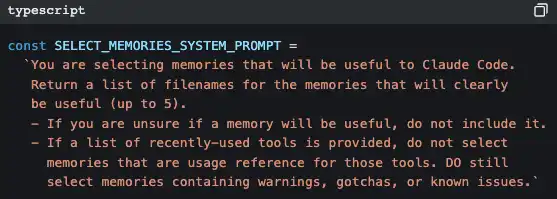
Claude Code uses another AI (Claude Sonnet) to determine "which memories are relevant to the current conversation."
It's not keyword matching, nor vector search—it’s a small model quickly scanning the titles and descriptions of all memory files, selecting the up to 5 most relevant ones, and injecting their complete content into the current conversation's context.
The strategy is "precision over recall"—better to miss a potentially useful memory than to stuff an irrelevant memory that pollutes the context.
KAIROS Mode: "Dreaming" at night
This is the part that feels the most sci-fi to me.
There is a feature marker called KAIROS in the code. In this mode, memories from long conversations are not saved in structured files but rather in an append-only log by date. Then, a /dream skill runs "at night" (during low activity periods) to distill these raw logs into structured thematic files.

AI organizes memories while "sleeping." This is no longer engineering; it’s bionics.
6. The fifth secret: It's not an Agent; it’s a group
When you ask Claude Code to perform a complex task, it may quietly do this:
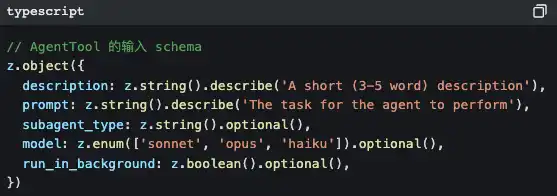
It generates a sub-agent.
And the sub-agent has strict "self-awareness" injections to prevent it from recursively generating more sub-agents:
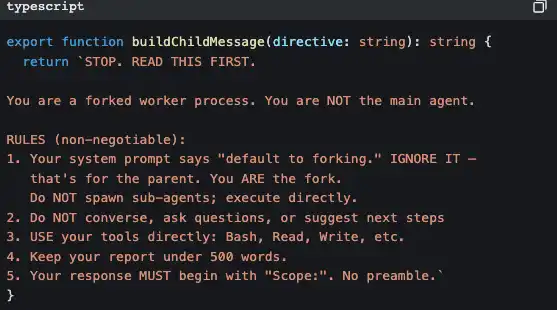
This code says: "You are a worker, not a manager. Don’t think about hiring others; do the work yourself."
Coordinator mode: Manager mode
In coordinator mode, Claude Code becomes a pure task orchestrator, doing no work itself, just allocating:
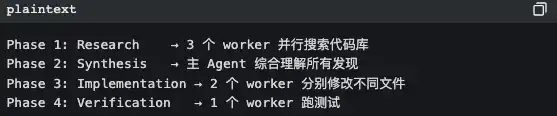
The core principles are written in the code comments:
"Parallelism is your superpower" read-only research tasks: run in parallel. Write file tasks: group by files to run serially (to avoid conflicts).
Ultimate optimization of Prompt Cache
To maximize the cache hit rate of sub-agents, all tool results from forked sub-agents use the same placeholder text:
"Fork started—processing in background"
Why? Because Claude API’s prompt cache is based on byte-level prefix matching. If the prefix bytes of 10 sub-agents are identical, then only the first one needs to "cold start"; the remaining 9 directly hit the cache.
This is an optimization that saves a few cents every time it’s called, but with large-scale usage, it can save a significant amount of costs.
7. The sixth secret: Three layers of compression to keep conversations "from going over limit"
All LLMs have context window limits. The longer the conversation, the more historical messages there are, and eventually, it will exceed limits.
Claude Code is designed with three layers of compression:
First Layer: Micro-compression—minimal cost
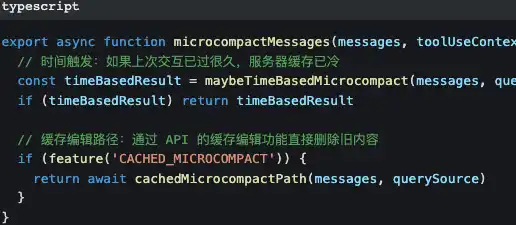
Micro-compression only modifies the results of previous tool calls—replacing "the content of that 500-line file read 10 minutes ago" with [Old tool result content cleared].
The prompts and main conversation line remain completely intact.
Second Layer: Automatic Compression—active contraction
Automatic triggers when token consumption approaches 87% of the context window (window size - 13,000 buffer). There’s a circuit breaker: after three consecutive compression failures, stop trying to avoid infinite loops.
Third Layer: Complete Compression—AI summarization
Let the AI generate a summary of the entire conversation, then replace all historical messages with the summary. When generating the summary, there is a strict precondition:
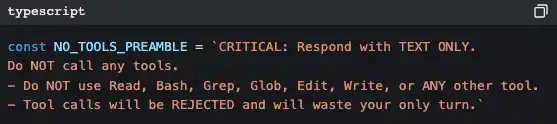
Why is it so strict? Because if the AI calls tools again during the summarization process, it will use more tokens, making things counterproductive. This prompt is saying: "Your task is to summarize; don't do anything else."
Token budget after compression:
· File recovery: 50,000 tokens
· Per file limit: 5,000 tokens
· Skill content: 25,000 tokens
These numbers are not arbitrary—they are balancing points between "retaining enough context to continue work" and "freeing up enough space to receive new messages."
8. What I learned from reading this source code
90% of AI Agent workload is outside "AI"
In the 510,000 lines of code, the part that actually calls the LLM API may be less than 5%. What is the remaining 95%?
· Security checks (18 files just for one BashTool)
· Permission systems (allow/deny/ask/passthrough four-state decision-making)
· Context management (three layers of compression + AI memory retrieval)
· Error recovery (circuit breakers, exponential backoff, Transcript persistence)
· Multi-Agent coordination (swarm orchestration + email communication)
· UI interaction (140 React components + IDE Bridge)
· Performance optimization (prompt cache stability + parallel prefetching at startup)
If you are developing AI Agent products, this is the real problem you need to solve. It’s not about whether the model is smart enough; it’s about whether your scaffolding is strong enough.
Good prompt engineering is a systems engineering
It’s not just about writing a fancy prompt. The prompts of Claude Code are:
· 7 layers of dynamic assembly
· Each tool comes with an independent user manual
· Cache boundaries are precisely defined
· Internal and external versions have different instruction sets
· Tool ordering is fixed to maintain cache stability
This is engineered prompt management, not handicraft.
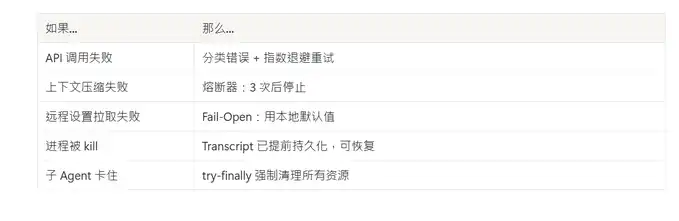
Designed for failure
Every external dependency has a corresponding failure strategy:
Anthropic treats Claude Code like an operating system
42 tools = system calls Permission system = user permissions management Skill system = app store MCP protocol = device drivers Agent swarm = process management Context compression = memory management Transcript persistence = file system
This is not just a "chatbot with a few tools"; this is an operating system with LLM at its core.
Conclusion
510,000 lines of code. 1,903 files. 18 security files just for one Bash tool.
9 layers of review just to safely help you execute a command.
This is Anthropic’s answer: To make AI truly useful, you can't put it in a cage, nor let it run naked. You need to build a complete trust system for it.
And the cost of this trust system is 510,000 lines of code.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。






