
Author: Phosphen
Compilation by; Gans Gan, Bagel Prediction Market Observer
This man has collected all professional tennis match data from the past 43 years and input it into a machine learning model, then asked just one question: Can you predict who will win?
The model answered with one word: Can.
It then correctly predicted 99 out of 116 matches at this year's Australian Open, achieving an accuracy of 85%!
This is a tournament that the model had never seen before during training, and it even predicted every match won by the final champion correctly.

All of this was done using a laptop, free data, and open-source code, created by @theGreenCoding.
Next, I will completely break down this miraculous project, from raw data to successful predictions. It will be the most impressive AI + successful prediction case you have ever seen.
Starting Point: 43 Years of Tennis Data in One Folder
The story begins with a dataset that can be called the "Holy Grail of Sports Data."
This dataset covers every professional match record in the ATP (Association of Tennis Professionals) from 1985 to 2024.
Break points, double faults, forehands, backhands, player height, age, rankings, historical head-to-head records, match venues… every point-by-point statistic tracked by the ATP throughout history is included.
Forty years of CSV files, all packed in one folder.
When he opened the complete dataset, the computer crashed immediately.
But he did not give up. For the 95,491 matches in the dataset, he calculated a large number of additional derived features:
Historical head-to-head records of the two players
Age difference, height difference
Winning percentages in the last 10, 25, 50, and 100 matches
Difference in first serve percentage
Difference in break point save percentage
A custom ELO rating system borrowed from chess (key points)
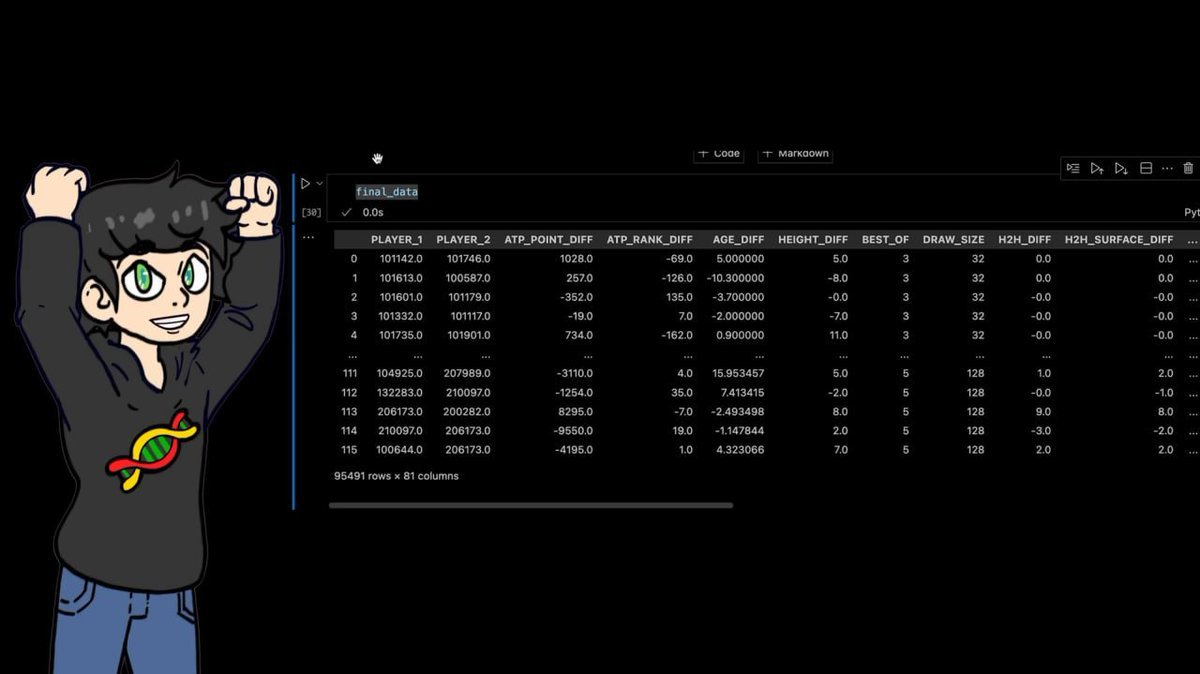
The final dataset: 95,491 rows × 81 columns.
Every professional tennis match from the past forty years, enhanced with dozens of manually calculated features.
Step Two: Algorithm Borrowed from the Titanic

Before feeding the data into the classifier, he decided to fully understand how the algorithm worked. To do this, he wrote a decision tree from scratch using numpy.
The decision tree works like a reasoning game—narrowing down the answer through a series of questions.
To illustrate this concept, he chose a completely different dataset: the Titanic.
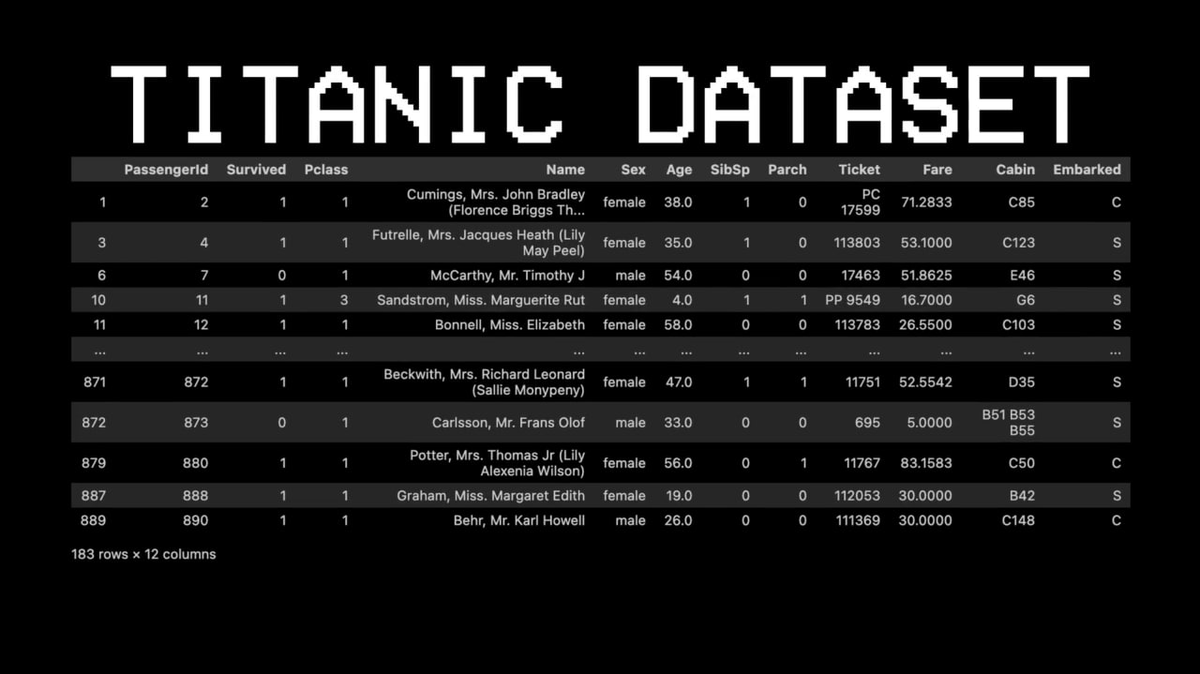
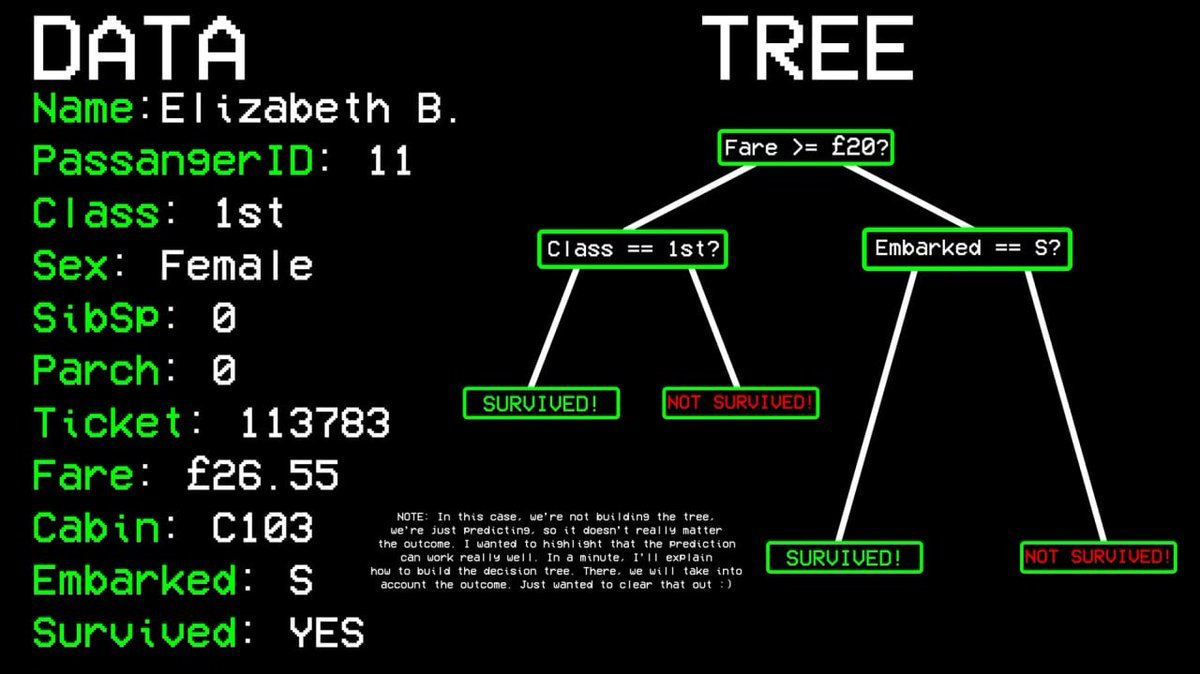
For example: Did passenger number 11 survive?
Question one: Are they in first class? → Yes.
Question two: Are they female? → Yes.
Prediction result: Survived.
How does the algorithm decide which questions to ask?
It starts from all the data and finds the single variable that best distinguishes between "survived" and "not survived." In the Titanic dataset, the answer is the cabin class. First-class passengers go one way, everyone else goes the other.
But there were also casualties in first class, indicating "impurity." The algorithm continues to search for the next best split point, which is gender. All first-class females survived, creating a "pure node," and the branch ends there.
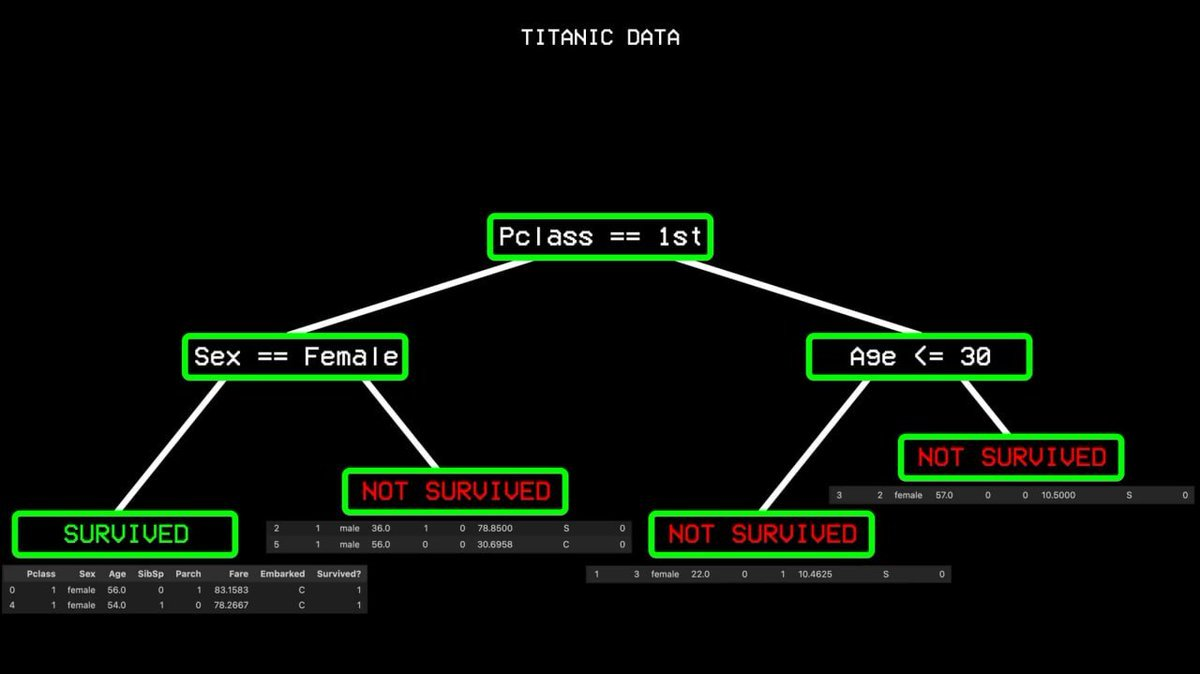
This process is repeated until a complete decision tree covering all cases is built.
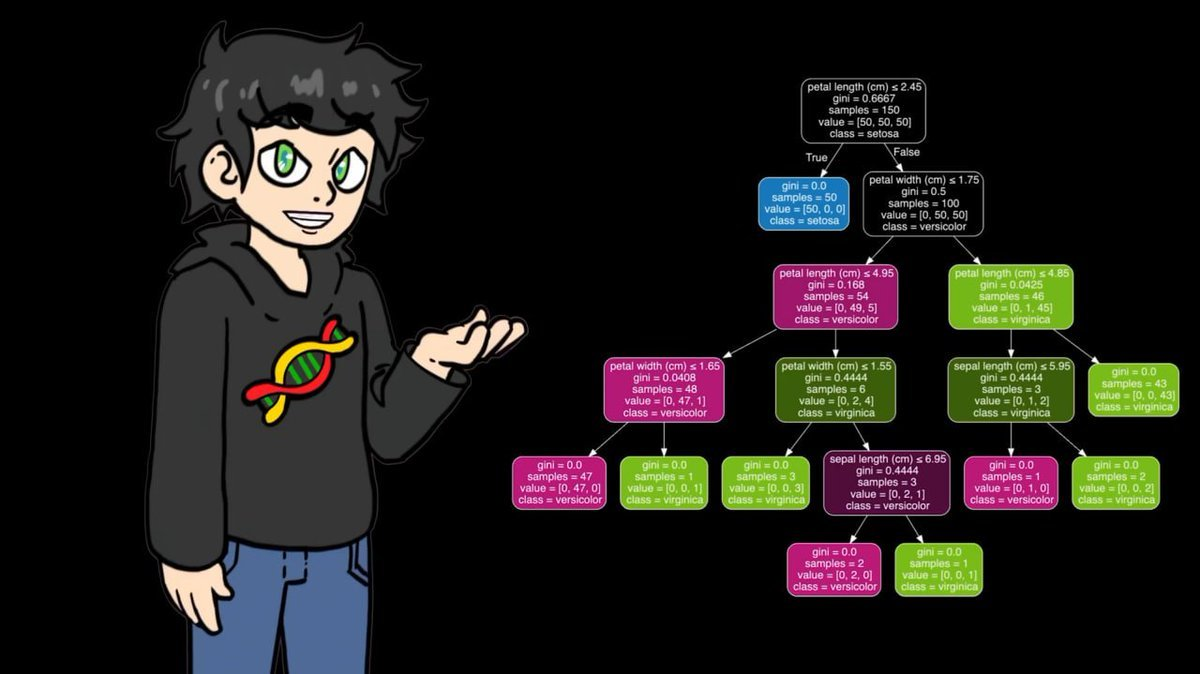
His numpy handwritten version performed well on small datasets, but it was painfully slow when applied to the 95,000 tennis match data. So in the formal training phase, he switched to the optimized version of sklearn, which operated on the same logic but much faster.
Step Three: Identify Key Variables that Determine Outcomes
Before training the model, he first plotted all the variables in pairs to create a giant scatter plot matrix (SNS pairplot) in search of patterns that could distinguish winners from losers.

Most features were noise. Player ID was obviously useless. The winning percentage difference showed some patterns but was not clear enough to support a reliable classifier.
Only one variable far surpassed the others: ELO difference (ELO_DIFF).
The scatter plot of ELO_DIFF and ELO_SURFACE_DIFF clearly demonstrated the separation degree between the two categories, with no other feature being comparable.
This finding prompted him to build the most crucial part of the entire project.
Step Four: Introducing the Chess Rating System to Tennis
ELO is a method for assessing player skill levels, originally applied to chess. The current world number one in chess, Magnus Carlsen, has a rating of 2833 points.

He decided to apply this system to tennis:
Starting rating for each player: 1500 points
Winning: rating increases; losing: rating decreases
Core mechanism: how much you gain or lose points depends on the rating difference with your opponent—defeating a higher-rated opponent earns more points, losing to a lower-rated opponent results in a heavier penalty.
He demonstrated this formula using the 2023 Wimbledon final: Carlos Alcaraz (rating 2063) versus Novak Djokovic (rating 2120), Alcaraz came back to win.

Plugging into the formula: Alcaraz +14 points, Djokovic -14 points.
Although the calculations were simple, their impact when applied to 43 years of historical data was astounding.
Step Five: Visualization of the Big Three’s Dominance
He plotted Roger Federer's entire career ELO score as a curve, recording every match from his debut to retirement.
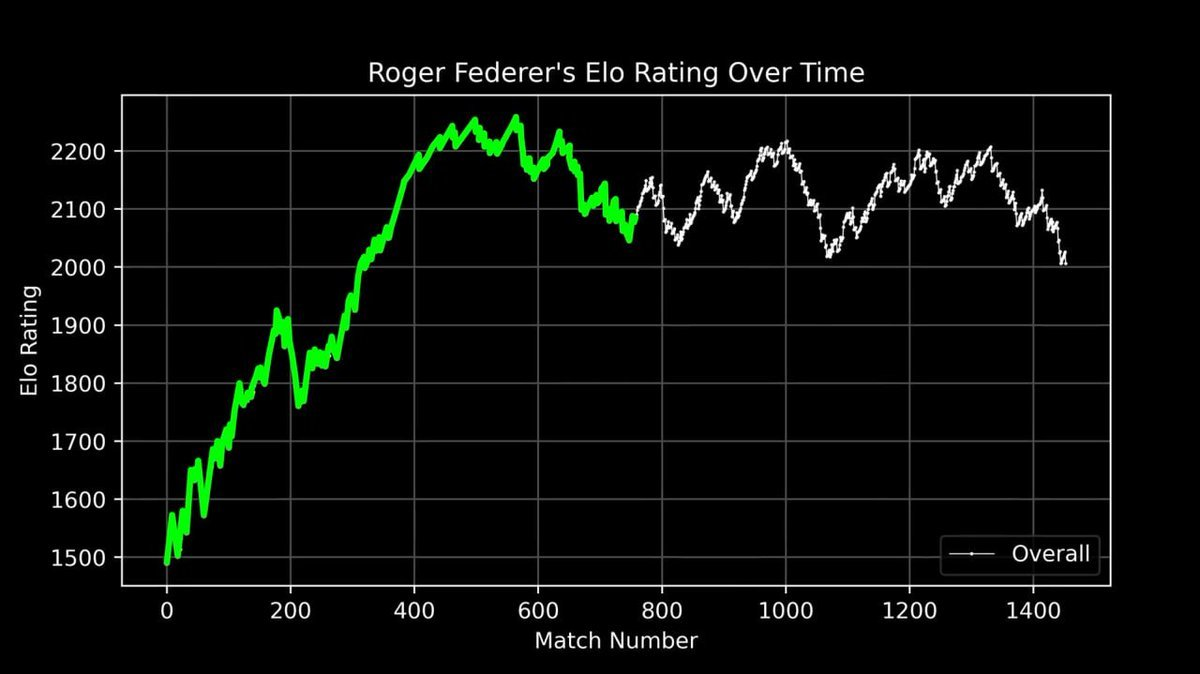
This curve fully depicts a legend: a rapid rise in the early years, absolute dominance during the peak period (around the 400th match), and fluctuations in the later stage of his career.
But what was truly shocking was placing Federer alongside all ATP players since 1985 on the same graph:
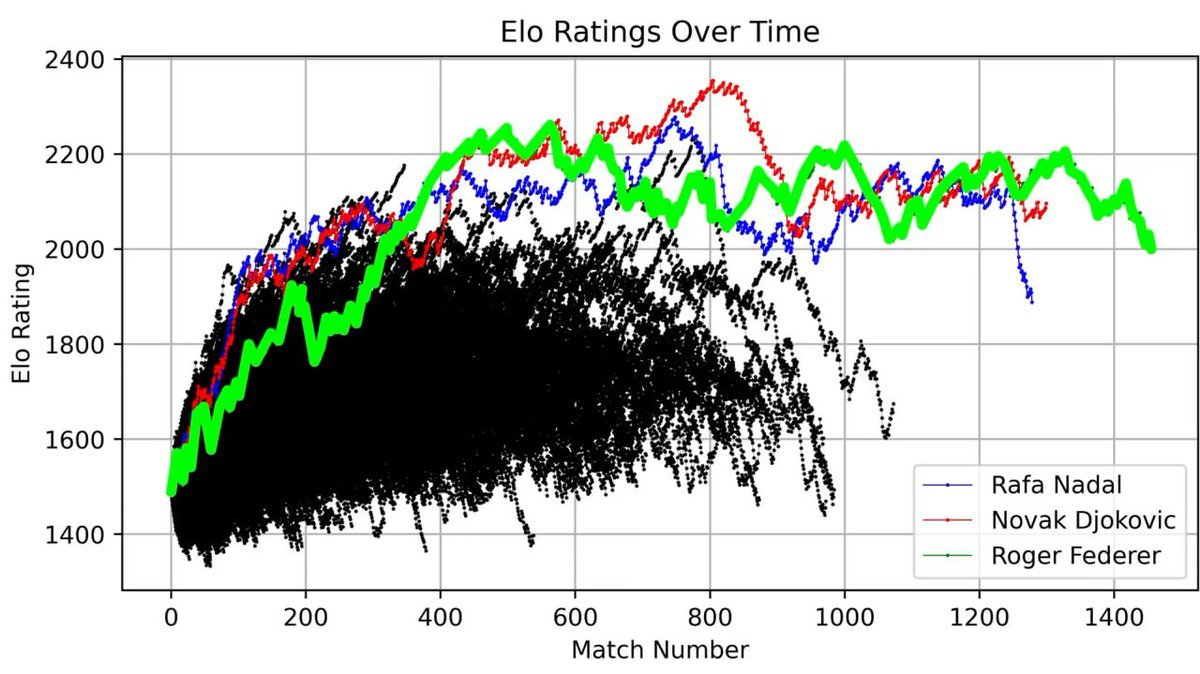
The three curves stand tall, far exceeding everyone else—Federer (green), Nadal (blue), Djokovic (red).
The "Grand Slam Big Three" is not just a title. When you visualize 40 years of match data, you will find that this dominance is mathematically evident.
According to his custom ELO system, the current world number one is Jannik Sinner (2176 points), followed by Djokovic (2096 points) and Alcaraz (2003 points).
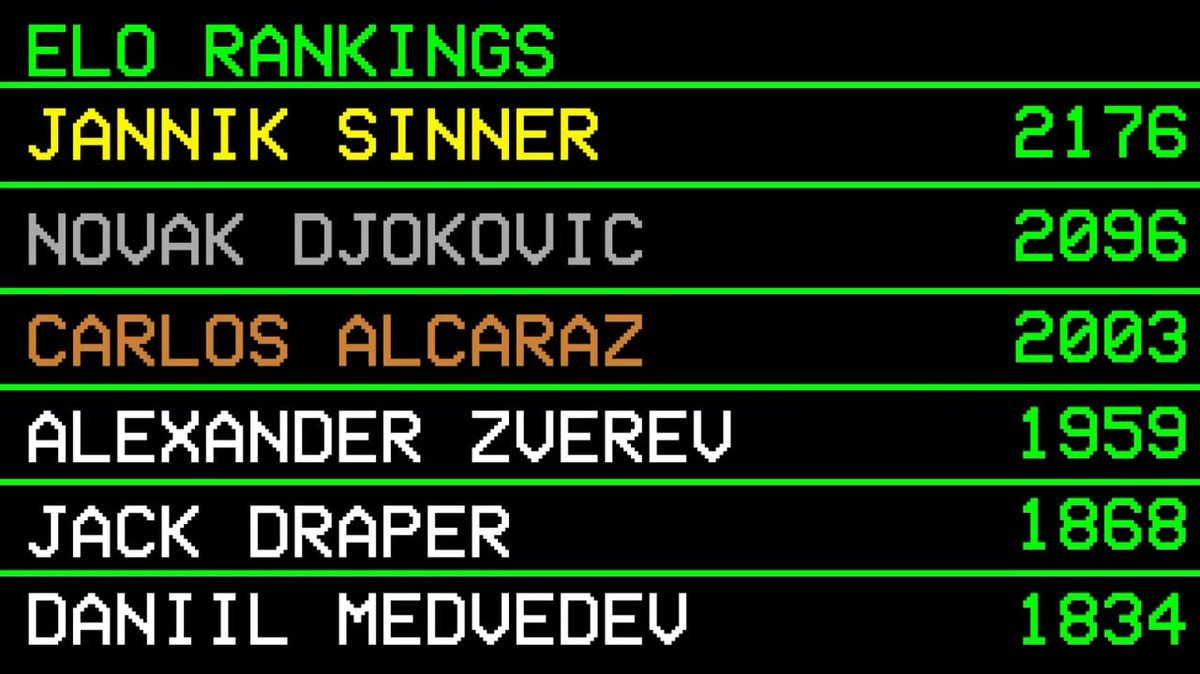
Remember Sinner ranking first—this is crucial later.
Step Six: The Variable that Changes Everything
The type of court in tennis completely alters the face of the sport:
Clay: slow, high bounce
Grass: fast, low bounce
Hard court: somewhere in between
A player who rules in one type of court might completely collapse in another court.
Thus, he established separate ELO scores for the three types of courts: clay, grass, hard court.
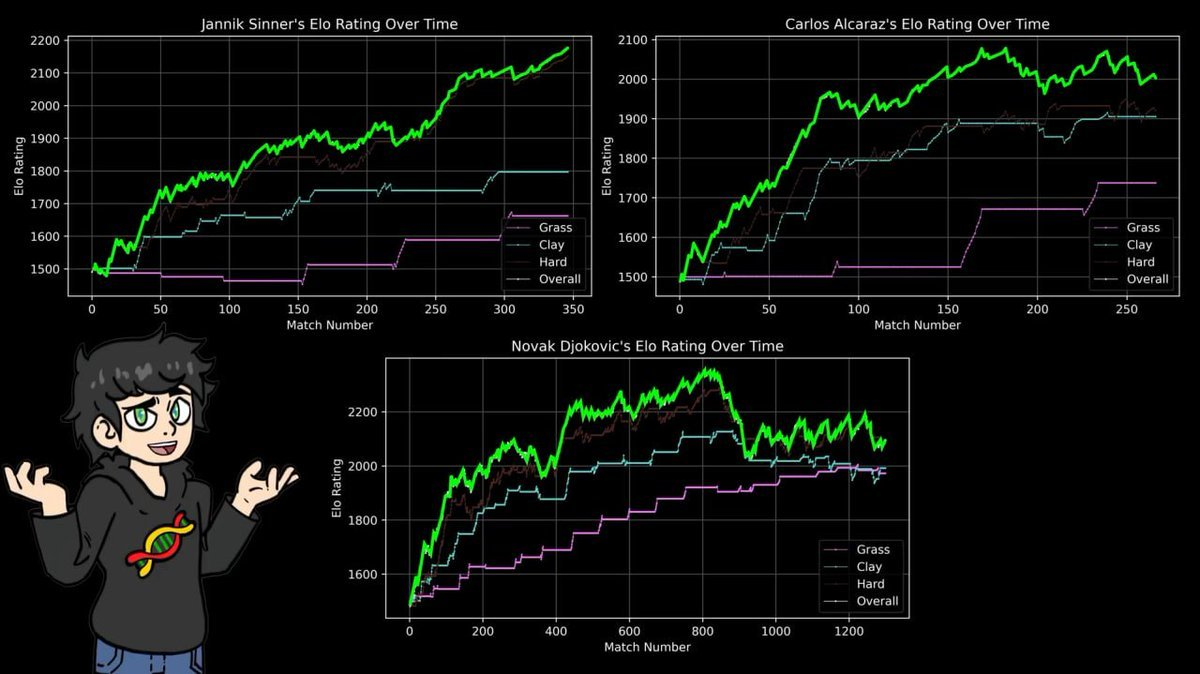
The results confirmed a fact every tennis fan knows, backed by 43 years of data:
Nadal's peak score on clay exceeds Federer's highest score on grass, exceeds Djokovic's highest score on hard court, and exceeds anyone's historical high on any court.
14 French Open titles, 112 wins and 4 losses at Roland Garros.
The ELO formula does not care about narratives or fame; it only deals with win-loss records. The conclusions it draws are completely consistent with forty years of sports journalism.
Step Seven: Hitting the Ceiling
With the data prepared and the ELO system constructed, he began training the classifier. This process perfectly illustrated the importance of algorithm selection.
Decision Tree: Accuracy 74%
A single decision tree achieved an accuracy of 74% on the complete dataset. It sounds good—until you realize that simply predicting the winner using ELO difference achieves 72% accuracy.
The decision tree brought almost no improvement based on the rating system he had already built manually.
Random Forest: Accuracy 76%
The problem with a single decision tree is "high variance"—it is overly sensitive to the subset of data selected during training. The standard solution is a random forest: building dozens or even hundreds of decision trees, each trained with different random subsets of data and features, and finally deciding the prediction result through majority voting.

94 unique decision trees collectively voting on each match.

The result is 76%. An improvement, but he hit the ceiling. No matter how he adjusted hyperparameters, redesigned features, or tampered with the data, the accuracy could not exceed 77%.
Step Eight: Breaking Through the Ceiling
Next, he tried XGBoost—he referred to it as "the steroid version of random forest."
The core difference is: random forests build trees in parallel and then take the average, while XGBoost builds trees serially—each new tree specifically corrects all errors of the previous trees. It introduces regularization to prevent overfitting and intentionally keeps each tree small in scale to avoid memorizing the training data.
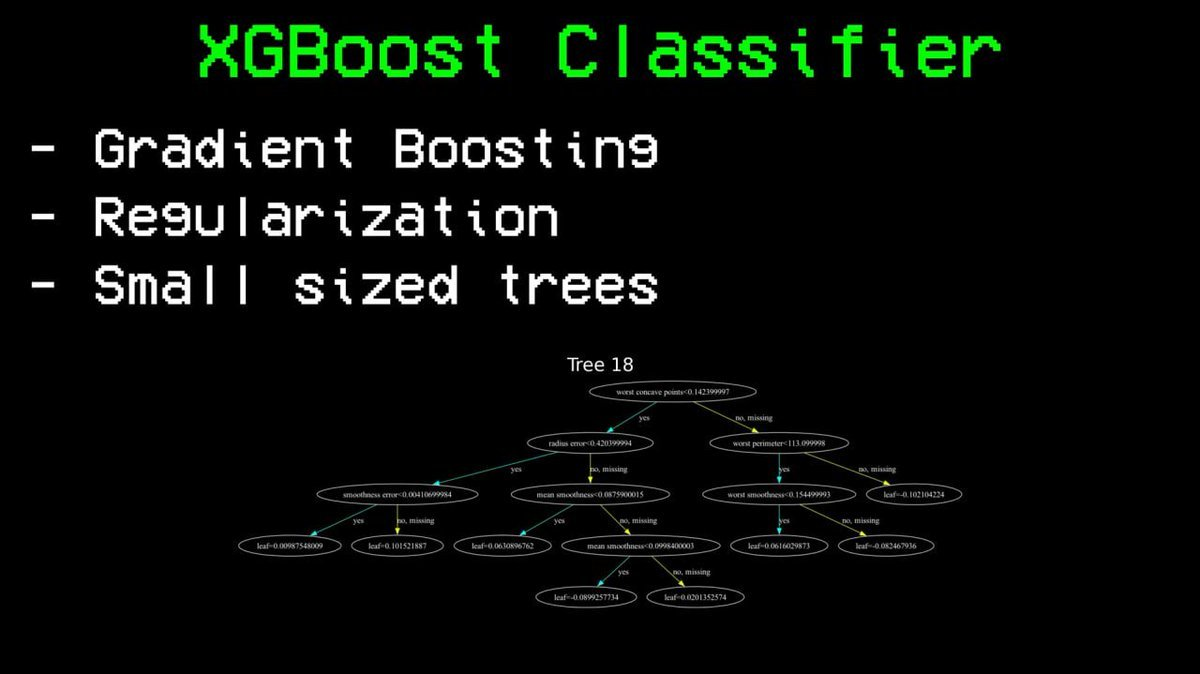
The result: accuracy 85%.
This is a massive breakthrough compared to the random forest ceiling of 76%. The same data, the same features, the only change is the algorithm.
XGBoost also identifies the three most important features as: ELO difference, surface-specific ELO difference, and overall ELO. This rating system borrowed from chess has been validated as the strongest predictive factor among the 81 columns of features.
For comparison, he trained a neural network using the same data, achieving an accuracy of 83%. Though good, it still fell short of XGBoost. In this dataset, tree-based methods came out on top.
Step Nine: The Moment of Truth—2025 Australian Open
All of the above was based on data trained before December 2024.
The Australian Open in January 2025 was completely outside the training set, making it a perfect test ground: did the model truly master the real patterns of tennis, or could it only memorize historical patterns?

He input the complete tournament draw into the model, allowing it to predict every match.
Result: correctly predicted 99 out of 116 matches, with only 17 mistakes. Accuracy 85.3%.
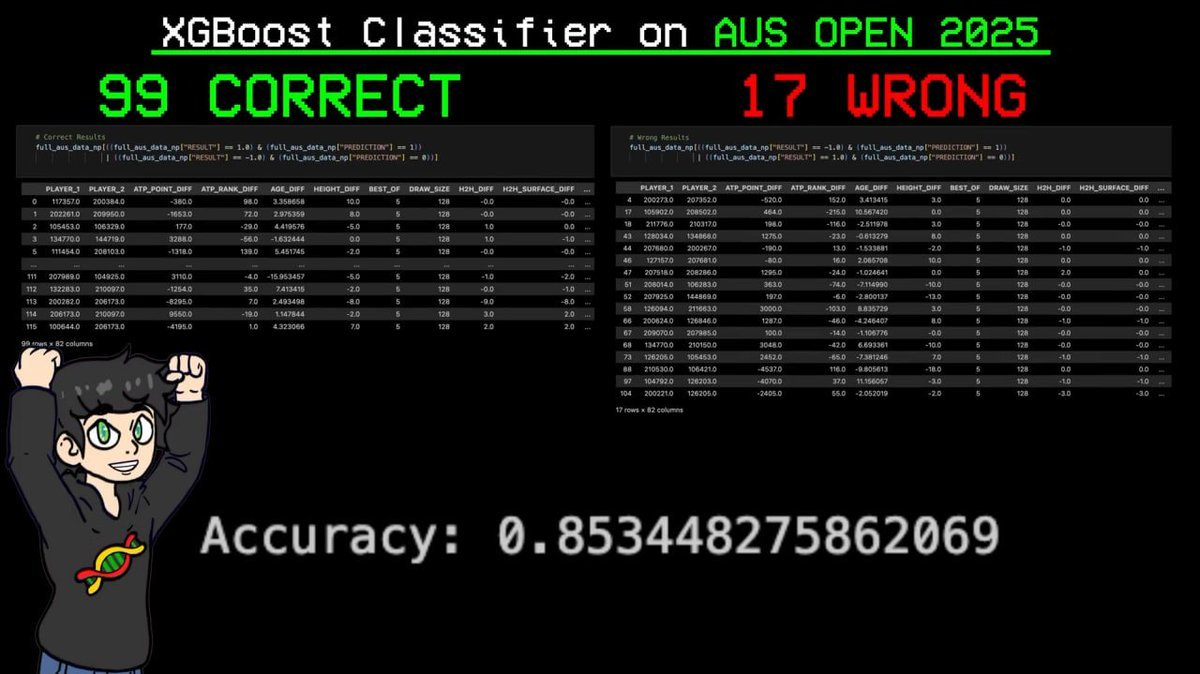
The most crucial prediction: the model accurately predicted Sinner (the player ranked number one by the ELO system) would win every single match in the entire tournament.
Before the first ball landed, the AI had predicted the Grand Slam champion.
Conclusion
A person, a laptop, no proprietary data, no expensive infrastructure, no research team—managed to build a professional tennis prediction model with an accuracy of 85% and predicted the Grand Slam champion before the tournament started.
Tennis data is available on GitHub, fully reproducible.
Creating miracles has never been so within reach as it is today.
The real difference is not in resources, but in whether you are willing to do it.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







