Today I fell into a big pit! How could I not have thought that the performance of the same model could vary so greatly!
After the official release of Deepseek 3.2 yesterday, its capabilities rivaled GPT-5. So, I assigned part of my daily tasks to it. It was responsible for over 30 analysis reports, and as a result, 8 of them had serious issues.
This outcome was truly unexpected, as it deviated significantly from expectations. So today, I accessed the official API interface and ran it again.
The result this time was very good. It indeed reached the level of GPT-5, completely different from the previous performance.
After thinking it over, the problem lay in the first use of the OpenRouter API. As we all know, there are now many large models available, and if each one requires registration, recharging, and configuring calling code, it becomes particularly cumbersome. OpenRouter integrates almost all large models, making it very convenient, especially when testing new models.
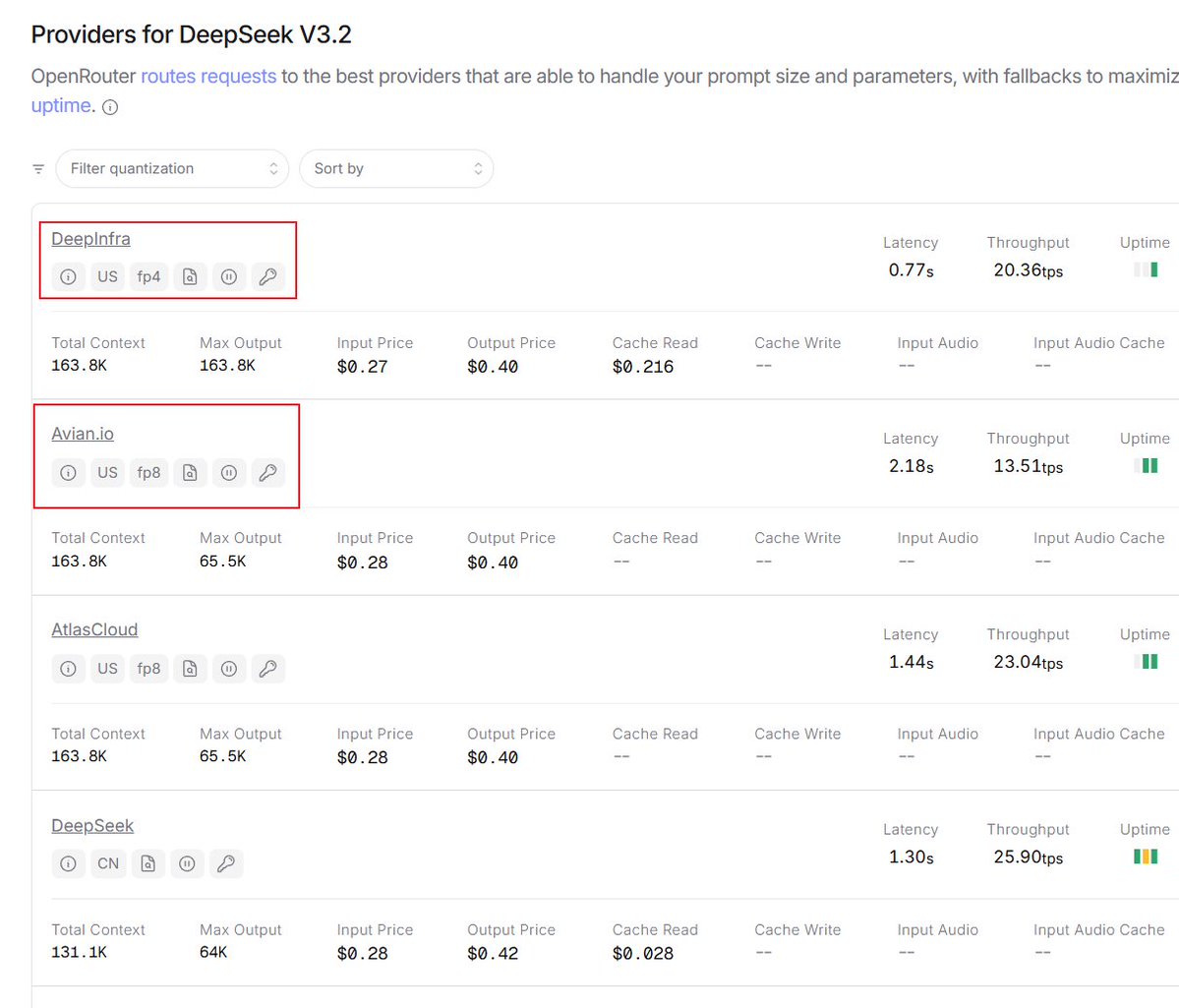
The model provider for Deepseek V3.2 offers FP4 and FP8. FP4 and FP8 refer to the data precision formats of floating-point numbers. In simple terms, they are techniques used to "compress" models (i.e., quantization), aiming to make models run faster and occupy less GPU memory while minimizing the loss of intelligence.
Although for most models, FP4 and FP8 generally do not result in a loss of intelligence, the DSA architecture used by Deepseek may be significantly affected by this.
Ah, the world of AI is still too complex.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。






