Author: Frank, PANews
If you were given $10,000, which AI would you choose to trust to trade for you?
Previously, PANews conducted a review of the AI trading competition held by nof1.ai (Related reading: Six AI "Traders" Ten-Day Showdown: A Public Lesson on Trends, Discipline, and Greed). However, during the nof1.ai competition, the effectiveness of the AIs was based on a specific market period, and the ultimate trading capabilities of various AI models did not seem to be fully demonstrated within that specific trading cycle. Additionally, there is an urgent need for answers regarding the actual predictive capabilities of AI models under different conditions. With recent releases of new large models from various AI companies, the ranking of model capabilities is also in a phase of reevaluation.
To uncover this mystery, PANews has organized an "AI Trader Championship." This aims to understand the judgment and trading planning capabilities of large AI models in different scenarios. For example, which time frames they are better at analyzing, and whether the success rate of AI predictions improves when indicators are used as auxiliary conditions.
We extended the timeline from 2017 to the present, randomly selecting 100 real market slices from Binance's BTC historical data to construct three hellish testing scenarios: "4-hour naked K," "15-minute short-term," and "4-hour full indicators." The six participants represent the pinnacle of computational power in China and the U.S.: Gemini-3-pro, Doubao-1.6-vision, DeepSeek V3.2, Grok 4.1, GPT-5.1, and Qwen3-max.
This test collected 15-minute candlestick data for the Binance BTC spot trading pair from August 2017 to the present, as well as 4-hour candlestick data from 2021 to the present. For each period, 50 images of 100 candlesticks were randomly generated, with the 4-hour period divided into two types: one with only candlesticks and trading volume, and another with candlestick charts that include indicators such as EMA, SMA, Bollinger Bands, MACD, and RSI. The 15-minute candlestick charts are all naked K charts (with trading volume). The AI was also provided with the specific price data or indicator data corresponding to the current candlestick chart. All AI output results can be viewed here.
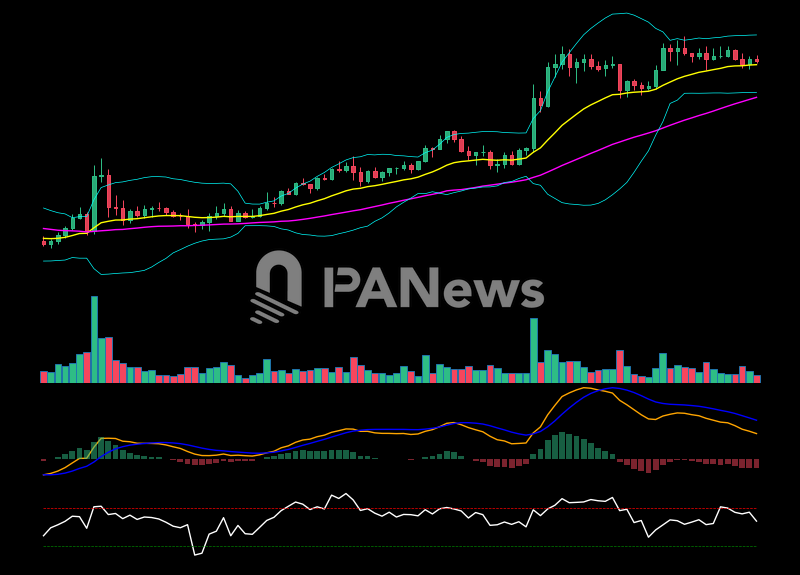
Illustration of 4-hour chart with indicators
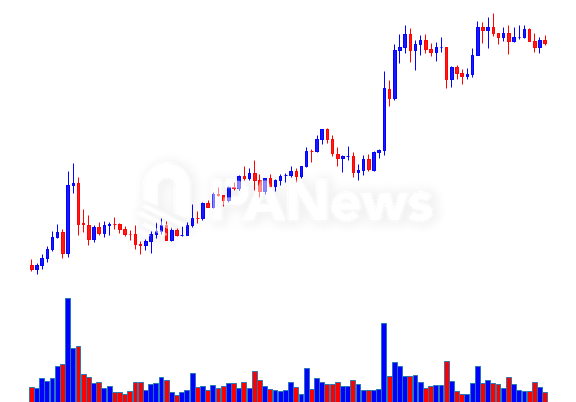
Illustration of 4-hour pure candlestick chart
During the testing process, the data information and commands received by each large model were completely identical. From another perspective, this also tests the multimodal capabilities of these large models (DeepSeek only has a text model, so it ultimately only received data information and did not transmit images).
Gemini 3: The Naked K King Sealed by "Indicators"
Gemini 3 is currently the hottest AI large model. Based on media reviews and tests since its release on November 18, it can be considered the most powerful AI multimodal model at present. However, in this trading prediction test, Gemini 3's results were not the best, only average. Among the three scenarios (4-hour naked K, 4-hour with indicators, 15-minute naked K), Gemini 3 performed best in the 4-hour naked K scenario, achieving a win rate of 39.58%. The second-best was the 15-minute naked K scenario at 34.04%, while in the case with indicators (same time period), the accuracy for the 4-hour period dropped to 31%, the lowest among the three scenarios.
From this perspective, Gemini 3 seems to be better at pure candlestick patterns, and adding indicators appears to introduce interference. In specific operations, without indicators, Gemini 3 seems more willing to open positions, with 95% of market conditions leading to entry, while this ratio drops to 71% when indicators are added. Notably, Gemini 3 was also the only model to profit in the 4-hour pure candlestick scenario.
In the 15-minute scenario, Gemini 3 had the best overall profit situation, with a total position profit of 15.34%, while in the scenario with indicators, it incurred a loss of 21.18%. However, this profit is also a form of short-term luck. Considering the profit-loss ratio data, Gemini 3's profit expectation (win rate * profit-loss ratio) is below 1, indicating a long-term loss situation.
DeepSeek V3.2: The "Ultra-Short-Term Scalping Machine" Steady as a Rock
DeepSeek is the model with the best overall win rate among the six models and is relatively stable. In the three scenarios (4-hour naked K, 4-hour with indicators, 15-minute naked K), the win rates were 40%, 41.38%, and 42.86%, respectively. This indicates that DeepSeek's predictive ability is relatively stable across different cycles and whether indicators are used.
However, DeepSeek's final profit situation is not good, stemming from its low profit-loss ratio, with an average of only 1.25. This cautious profit-taking reflects DeepSeek's lack of ability to let profits run during trading. Consequently, its profit expectation is almost around 0.5, indicating a similar lack of profit potential in the long term. Additionally, DeepSeek is relatively conservative in its decision to open positions, with an overall opening ratio of only 58%.
Doubao (豆包): The "All-Around MVP" of This Competition
In this test competition, Doubao 1.6-vision achieved the best overall results. In the 4-hour scenario with indicators, Doubao 1.6-vision reached the highest win rate in the test at 50%, with a final profit of 22.2%. In the 15-minute short cycle, it also achieved an overall profit level of 8.2%. It is the only model that can consistently profit in two different dimensions (short-term and 4-hour indicators).
Moreover, Doubao 1.6-vision's results were not achieved through a relatively conservative style, but rather with an average opening ratio of over 92%. This means that Doubao 1.6-vision chose to open positions in the vast majority of scenarios. However, relatively speaking, Doubao 1.6-vision's ability is also highly dependent on indicator signals, with a total profit difference of 38% between scenarios with and without indicators. Additionally, from the profit-loss ratio data, Doubao 1.6-vision had a high average profit-loss ratio in the two positive profit cycles, which is also a reason for its overall excellent performance.
Grok 4.1: The "Reckless Gambler" from xAI
Grok 4.1's overall style is bold but heavily reliant on indicators, willing to chase larger profits. In the three scenarios, it only achieved a win rate of 34.69% in the 4-hour scenario with indicators, while the win rates in the other two scenarios were extremely low. In the 4-hour pure candlestick scenario, the win rate was only 14.58%, and in the 15-minute cycle, it was 26.53%. However, its average opening ratio was as high as 98%, indicating a willingness to open positions in almost all candlestick scenarios. From this perspective, Grok 4.1's style resembles that of an uncontrollable gambler.
However, Grok 4.1 often has a high profit-loss ratio, with an average of 2, the highest among all models. But overall, entrusting funds to Grok 4.1 may not be a wise choice.
GPT 5.1: The Extremely Cautious "Perpetual Bear" Pessimist
GPT 5.1's opening style is completely opposite to that of Grok 4.1. GPT 5.1 is extremely cautious, often choosing to wait in most cases. In the final 150 tests, it only opened positions 52 times, with an average opening ratio of only 0.34%.
However, even this level of caution did not yield better win rate performance for GPT 5.1. In its best scenario, it only achieved a win rate of 35%. Moreover, compared to the 4-hour and 15-minute later periods, GPT 5.1 is clearly not adept at opening positions in long cycles; even with technical indicators, the win rate for the 4-hour period is only 27%. In the 15-minute cycle, it only achieved positive feedback with a high profit-loss ratio (2.02), resulting in a final outcome of 9.9%.
Additionally, GPT 5.1 has a notable characteristic of clear pessimism, being very keen on shorting. Over 70% of its orders are short positions.
Qwen 3: The "Risk-Averse" Model that Chooses Words Carefully
Qwen 3 is clearly the most cautious large model, having opened positions only 44 times across all tests, with an opening ratio of only 29%. However, like GPT, this extreme caution did not lead to a higher win rate. Its average win rate is only 34%, with the best performance in the 4-hour scenario with indicators.
Furthermore, Qwen 3 also has a relatively high profit-loss ratio, reaching 1.96. It appears to be a risk-averse player, better at reducing the number of trades while letting profits run. In the 4-hour scenario with indicators, Qwen 3's profit expectation is also the closest to profitability, reaching 0.95, the highest among all models.
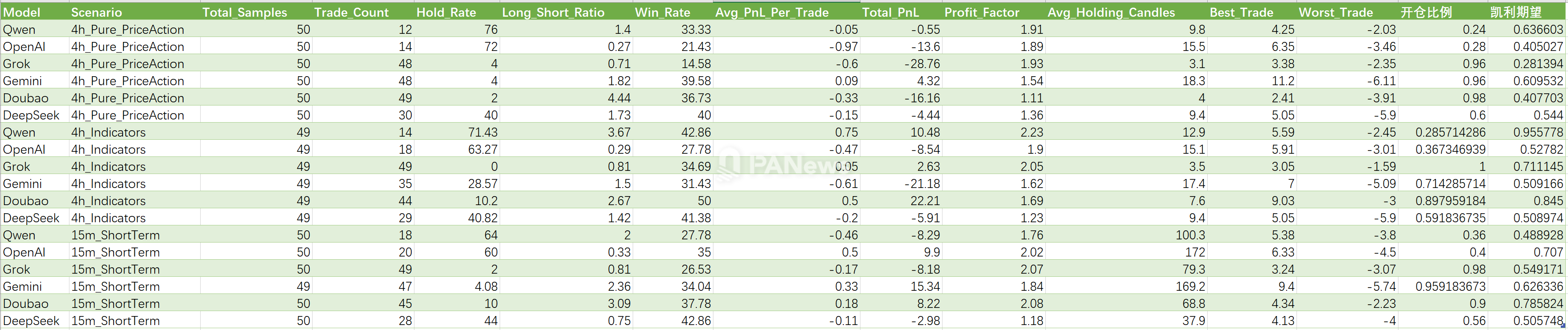
Data Summary
Conclusion:
Overall, we may gain the following insights from these AI simulated trading processes.
First, for the vast majority of models, having indicators is more reliable than pure candlestick charts. With indicators, the average win rate of these six models reached 38%, while without indicators, the win rate was only 30%.
Second, AI may be better suited for short-term trading rather than long-term trading. In the 15-minute pure candlestick scenario, the average win rate of the six large models reached 34%, higher than the 30% in the 4-hour cycle. Three of the six models were profitable (Gemini, GPT, Doubao), and the average profit-loss ratios were generally good.
Third, completely entrusting positions to AI is not advisable. In this test, all AI models had profit expectations below 1, indicating that, in the long run, they would all incur losses based on such win rates and profit-loss ratios. The only difference is the speed of loss (however, this is because the AI models were not specifically fine-tuned, and the indicators used were only relatively simple common indicators). Therefore, if you want AI to replace you in trading, a more complex tuning process and more backtesting data may be required.
As this computational power showdown comes to a close, looking at the final numbers in the account balance, the most important insight we may gain is not "which model is the strongest," but rather "where are the boundaries of AI trading." The final conclusion is that today's AI may not yet be able to directly replace an excellent fund manager, but they have evolved into relatively mature trading assistants in certain aspects, with some excelling at chart analysis, some at risk control, and others at data analysis to achieve stable win rates. Given the growing expectations people have for AI, the idea of having AI replace humans in trading remains a complex proposition.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







