From "Firewall" to "Bug Net," Cloudflare may rewrite the history of paid online content.

Elon Musk and Donald Trump, this duo from the White House, has recently entered the 2.0 phase of their "verbal warfare." Similar to this pair of frenemies is the love-hate relationship between foreign publishing groups and AI giants—on one hand, large publishers want to collaborate with AI companies, while on the other hand, some publishers vow to bankrupt the AI giants.
According to data, since the emergence of AI search and ChatGPT, global website traffic has been declining; on the other hand, AI giants' "AI crawlers" disregard crawling protocols and continuously erode data from all websites with tens of thousands of crawls.
At this moment, a foundational company has finally stepped up, taking the hand of content creators and saying, "We can say no to AI giants!"
Cloudflare, the internet infrastructure giant that controls about 20% of global web traffic and is hailed by netizens as the "Cyber Bodhisattva," launched an experimental product and trading market in July 2025: "Pay Per Crawl"—establishing new rules for AI crawlers:
Either obtain permission or pay.
In simple terms, the essence of this feature is to give website content creators an "on-off" option: they can choose to allow AI crawlers free access, charge per crawl, or directly block access.
According to Cloudflare's founder, "Content is the fuel that drives the AI engine, so it is fair for content creators to be compensated directly."
For AI companies, if they want to continue scraping content from the web to train their models, they can no longer "feast for free" as they did before. However, there are benefits as well, since paying a clear price can avoid copyright disputes.
Will Cloudflare's "bug prevention" measures alleviate the rampant attacks from AI crawlers? More importantly, can this company leverage its unique position to establish a brand new content distribution and monetization model for the AI era?
01
The "Free Lunch" of AI Giants
For the past few decades, most web pages have been publicly "crawlable" by default. Search engines like Google and Bing bring traffic to websites, and with traffic, websites can monetize through ads or subscription sales—this is the unspoken contract of the search era.
However, in the AI era, traditional search traffic has plummeted, making this equation increasingly unfavorable.
AI companies treat all web content as training fuel but hardly compensate most creators. When users ask questions directly in AI chatbots, the answers often come from summarized content rather than dozens of blue links, which does not bring more traffic to the websites.
Even search giants like Google are changing; they used to provide lists of website links, but now they have introduced "AI summaries" on their search pages. According to their reports, 75% of query users get answers without clicking any links.
Cloudflare's latest data from July 2025 shows that Google's crawlers bring back about 1 click for every 6 to 7 crawls, while OpenAI only gets 1 click for every 1500 crawls, and Anthropic's ratio is even more exaggerated, at 73,300 crawls for 1 click.
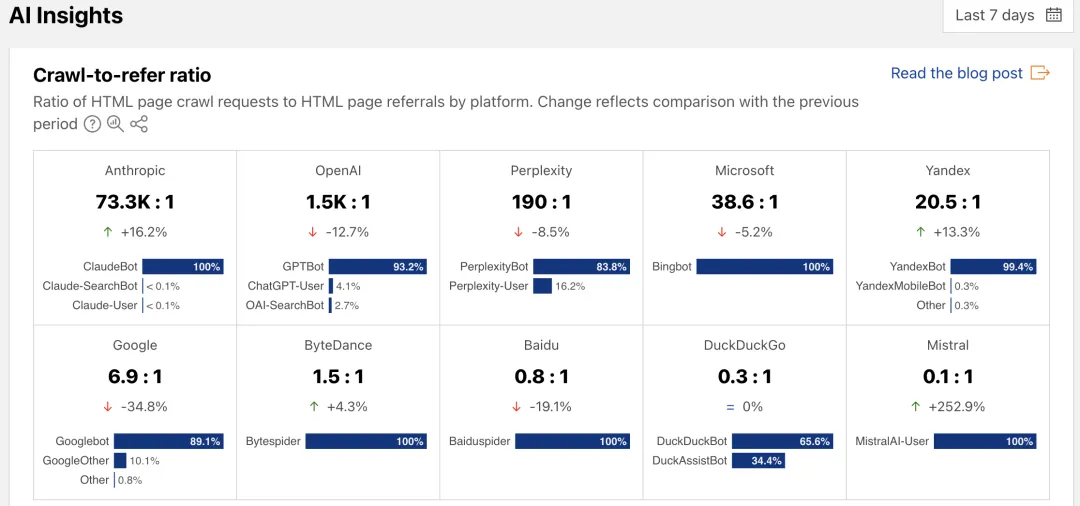
Click ratios brought to websites by major companies' AI crawlers|Image source: Cloudflare
This means that the traditional "content for traffic" model has failed. Compared to traditional search engines, AI giants consume vast amounts of website content without providing "traffic," creating an imbalance that makes it increasingly difficult for some content producers to survive.
"With OpenAI, the difficulty of acquiring website traffic is 750 times higher than in the Google era, and with Anthropic, the difficulty is as high as 30,000 times. The reason is simple: we are consuming derivative products rather than original content." Cloudflare CEO Matthew Prince stated in a blog post, "This is not a fair trade."
AI companies scraping data also come at a cost; in the past two years, AI giants have been accused of "stealing content" to train large models, leading to a wave of copyright lawsuits worldwide, especially with news organizations like The New York Times frequently suing OpenAI.
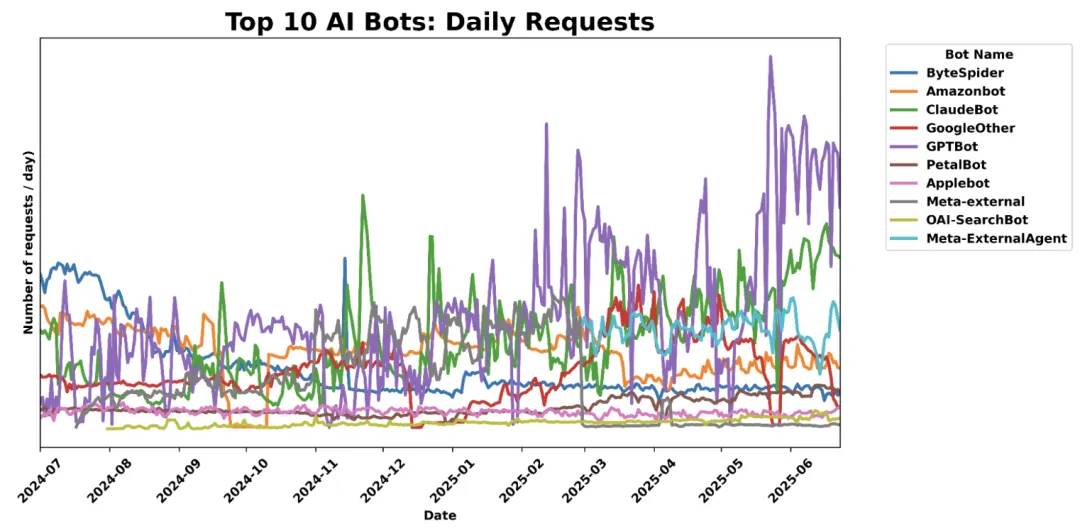
Active AI crawler bots from major companies|Image source: Cloudflare
Therefore, Cloudflare launched "Pay Per Crawl" to address this issue by establishing a market for "pay-per-crawl."
The company designed a permission and payment system where websites can choose to "allow, block, or charge" AI crawlers in the backend. If AI crawlers want to scrape content from a website, they must register, verify their identity, and complete payment for each visit.
If successful, this model could shift web content monetization from "advertising" to "content licensing," opening up new revenue streams. Whether for large media or niche blogs, all can have bargaining power in the AI era, being paid for their content usage by AI.
To emphasize its significance, Cloudflare's CEO referred to the launch day of "Pay Per Crawl" as:
"Content Independence Day."
02
How is the AI "Toll" Collected?
Of course, the vision is beautiful, but how does the technology land?
Cloudflare started by providing services like CDN, DDoS protection, DNS, and zero-trust security. It has deployed nodes in over 300 cities worldwide, handling about 20% of web traffic, making it convenient for it to act as an "intermediary."
"Pay Per Crawl" is built on its global CDN network's middle layer: it can identify and process AI crawlers before access requests reach the origin server. Website owners can set three modes in the Cloudflare backend: allow, charge, or block.
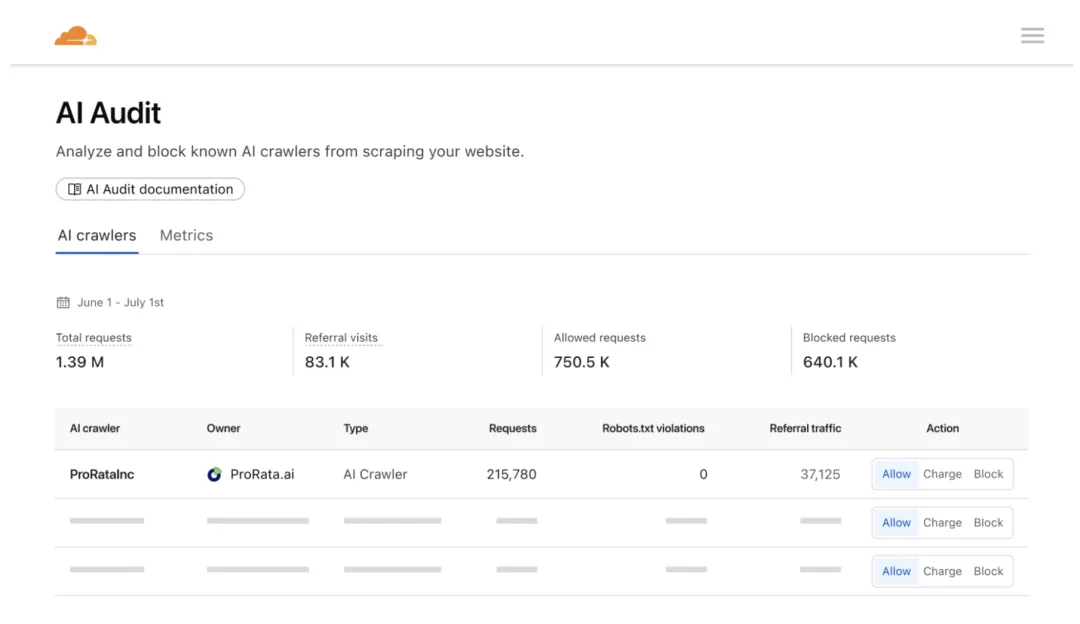
Website owners can set allow, charge, or block in the backend|Image source: Cloudflare
All new websites joining Cloudflare default to blocking AI crawlers unless the website owner actively allows it. Only AI companies that establish a partnership with Cloudflare can participate in the payment mechanism; otherwise, they will be blocked.
If an AI crawler requests a paid URL without having paid, Cloudflare will return an HTTP 402 Payment Required status code—a status code that was rarely used in the past, specifically reserved for "web payments." AI crawlers can include payment information in their requests to indicate agreement to pay the configured price; once the price matches, access is granted, and a 200 OK response is returned, automatically settling the payment.
Cloudflare itself acts as the "cash register" for this transaction, responsible for aggregating bills and distributing revenue.

Cloudflare will return HTTP 402 Payment Required status code|Image source: Cloudflare

Crawlers can include payment information in their requests|Image source: Cloudflare

HTTP 200 OK response confirms the charge|Image source: Cloudflare
More importantly, this cannot be bypassed by simple User-Agent deception. Cloudflare requires AI companies to register keys and use digital signatures to ensure identity. This is also to prevent "counterfeit crawlers" from impersonating compliant ones to evade payment.
In the past, robots.txt was a plain text file placed in the root directory of a website to inform search engine crawlers which pages could be scraped and which could not, but it was merely a "polite suggestion" from the website, and many AI crawlers ignored it. Cloudflare's solution changes this, turning the existing "soft constraint" of robots.txt into a "hard gate."
However, according to Cloudflare, currently, only about 37% of the top 10,000 domains have a robots.txt file.
Setting barriers for AI crawlers|Image source: Cloudflare
To participate in Cloudflare's pay-per-crawl market, both the scraping party and the scraped party must open Cloudflare accounts. As of now, "Pay Per Crawl" is still in the internal testing phase, with only a few large publishers participating, such as BuzzFeed, The Atlantic, and Fortune. Cloudflare is also continuously soliciting interested content creators and scrapers.
"We expect the pay-per-crawl model to see significant development," Cloudflare officials stated.
Although it is still in the early stages, the company has many ideas for the future. For example, publishers or other organizations could charge different fees for different types of content, or implement dynamic pricing based on the number of users of AI applications, or introduce more granular pricing strategies based on training, inference, search, and other fields.
They also believe that the true potential of pay-per-crawl may emerge in the world of intelligent agents.
"What if the payment wall for intelligent agents could operate entirely programmatically? Imagine being able to ask your deep research assistant to organize the latest cancer research, legal briefs, or help you find the best restaurants—then giving this intelligent agent a budget to acquire the most useful and relevant content."
"The first solution based on the HTTP 402 response code will open up a future where intelligent agents can programmatically negotiate access to digital resources," Cloudflare stated.
03
The Crossroads of the Internet
From an economic perspective, this could be the beginning of a "re-negotiation of revenue sharing" between AI and a wide range of content creators.
Currently, only top-tier media can negotiate licensing with AI companies (for example, The New York Times only reached a settlement with OpenAI after reporting it), while the vast majority of small and medium-sized websites, forums, and even individual authors are "silently scraped" with no ability to resist or even awareness. Cloudflare's solution can actually extend this bargaining power to a broader range of websites.
According to the Cloudflare team, they have had hundreds of conversations with news organizations, publishers, and large social media platforms, and they all "hope to allow AI crawlers to access their content but want to be compensated."
For supporters, the "Pay Per Crawl" model is conceptually "fair": creators receive income, AI companies avoid legal risks, and in the long run, it can promote the entire industry towards more compliant content licensing.
Image source: Cloudflare
Of course, AI companies may not be happy; internet data is no longer free, and to scrape new content, they will have to spend money, which means additional cost factors beyond computing power.
On the other hand, this may also curb excessive scraping and force AI model developers to be more selective about data—such as selectively purchasing high-value content instead of indiscriminately feeding various website content into their models.
Matthew Prince stated, "The AI engine is like a Swiss cheese; the truly new original content that can fill the holes in this cheese is more valuable than the repetitive, low-value content that currently occupies most of the web."
In his view, traffic has never accurately measured the value of content. "If we could start scoring and evaluating content, not based on how much traffic it generates, but based on how much it contributes to knowledge (measured by how many existing holes it fills in the AI engine's 'Swiss cheese')—we could not only help the AI engine progress faster but also potentially promote a new golden age of high-value content creation."
However, digital rights advocates may raise concerns: can small AI startups, researchers, and open-source communities afford such data costs? Will academic research and public archiving, these "benign crawlers," find it difficult to operate, only able to access limited, low-value data sources?
In a reality where advertising revenue is declining and traffic costs are rising, how many websites would be willing to open themselves up for free to AI crawlers? Could this mark the beginning of "closure," causing the internet to lose its spirit of freedom and sharing?
If the entire web defaults to blocking paid access, could this inadvertently exacerbate "big tech monopolies"? After all, big companies tend to have more money.
The "Pay Per Crawl" model attempts to address the issue of AI consuming content without reciprocation, but it may also unintentionally raise the barriers to AI innovation, returning to the old themes of copyright protection and knowledge openness.
Of course, Cloudflare is merely giving websites more autonomy. Website owners can choose to continue offering free access to public interest and non-profit projects. The power remains in the hands of the creators. Regardless, they deserve to receive "compensation."
According to the Cloudflare CEO, the goal of this transformation is to "build a better internet." "We do not yet know all the answers, but we are working with some of the top economists and computer scientists to find them."
Currently, other CDN and security providers (such as Akamai, Fastly, Amazon CloudFront) have not announced similar features.

Blocking AI crawler bots at the door|Image source: Cloudflare
Although Cloudflare's "Pay Per Crawl" appears to be just a new feature of a CDN product, in a sense:
It may signal that the internet has reached a crossroads.
In the search era, the value of content was converted into advertising revenue through user visits. But in the AI era, users may not even click into websites—every answer is summarized and generated within chatbots. Should we continue to let AI large models freely mine web content, or should we return to the principle of "reciprocity" in data acquisition, allowing creators to receive their due compensation? And how much compensation can there be?
This early experiment may pave the way for a new data economy in the AI era. Regardless of its success or failure, its stance is clear: AI cannot endlessly overdraw creators' patience and turn human labor into free fuel in the name of "openness."
"The internet is undergoing transformation, and its business model will change accordingly. In this process, we have the opportunity to learn from the good aspects of the past 30 years and make it better in the future."
As for whether things can really improve, as Cloudflare itself admits:
"This is just the beginning."
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







