Original Author: Weikeng Chen

In the Ethereum Virtual Machine (EVM), the Keccak hash function is widely used for the construction and verification of state trees (Merkle Patricia Trees), accounting for a significant portion of the computational overhead in zero-knowledge proofs. Efficiently proving Keccak has long been a technical challenge in the field of zero-knowledge proofs.
To address this challenge, the Polyhedra team has launched Binary GKR—a high-performance proof system specifically designed for Keccak and other binary operations.
Core Progress: 5.7 Times Speed Improvement for Keccak Proofs
Binary GKR has achieved the fastest Keccak zero-knowledge proof performance to date, speeding up approximately 5.7 times compared to the optimal solution of existing binary proof systems, FRI-Binius. This breakthrough is not only theoretically significant but also opens up new possibilities for practical applications.
Application Prospects: The "Universal Acceleration Sidecar" of zkEVM
We believe that Binary GKR can serve as a "universal acceleration sidecar" in various zkEVM architectures, efficiently handling a large number of Keccak operations in the Ethereum state tree, thereby significantly reducing proof costs and improving system throughput and response speed.
Polyhedra will continue to promote the productization and open-source process of Binary GKR, empowering zk architecture upgrades in Ethereum and the broader ecosystem.
Keccak: The "Holy Grail" of Zero-Knowledge Ethereum
Ethereum is gradually evolving into a Layer-1 that is natively zero-knowledge proof. The Ethproofs initiative, involving 21 teams and covering 22 types of ZK(E)VM implementations, is attempting to provide complete proofs for Ethereum's historical blocks, marking a key step forward.
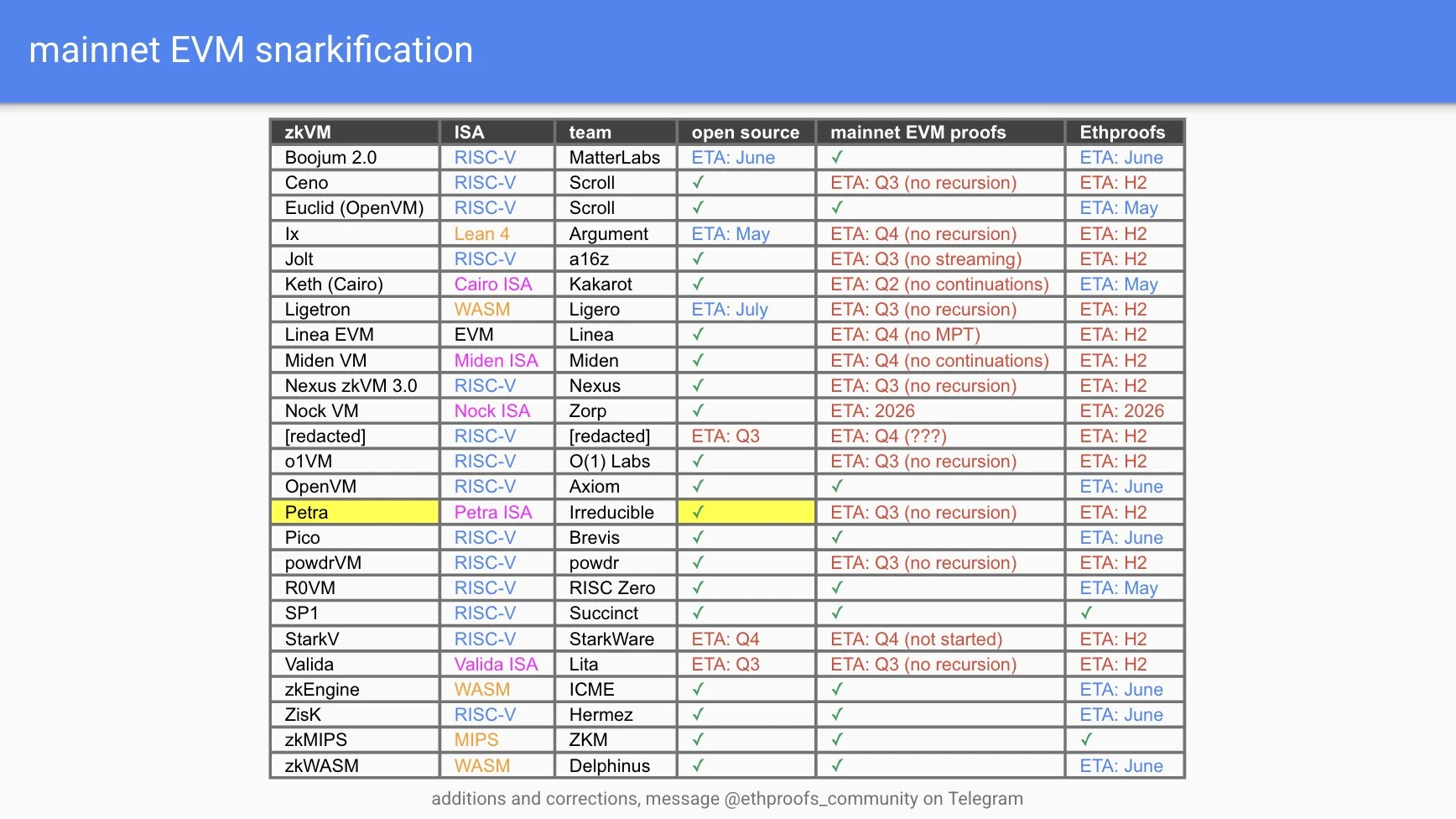
Real-time progress from multiple teams, including ZkCloud, Succinct, Snarkify, and ZKM, can be viewed on the Ethproofs official website, where they have begun continuously submitting ZK proofs for the latest blocks. The ultimate goal of this trend is to establish Ethereum as an execution layer driven by zero-knowledge proofs, while the consensus layer only needs to perform lightweight tasks such as proposing transaction lists.
The Biggest Challenge Facing zkEVM Architectures: The Bottleneck of Keccak Proof Efficiency
Several Ethereum-compatible zkRollup projects (such as Polygon, Taiko, Scroll) have attempted to implement zkEVM. However, some operations that are efficient on the CPU in traditional EVMs are costly in zero-knowledge proof systems. The main performance bottleneck is the Keccak hash function.
Keccak is widely used to construct Ethereum's Merkle Patricia Tree, recording the entire chain state in hash form. However, the underlying operations of Keccak are based on bit-level operations, which are incompatible with the prime field operation model used by most ZK systems, leading to significant performance degradation.
To help understand why the Keccak hash function is essentially a collection of "bit operations," we briefly outline five core operations: θ (theta), ρ (rho), π (pi), χ (chi), and ι (iota). These operations are applied to a 5×5 matrix structure, where each cell is a 64-bit integer, referred to as a "word." The entire matrix consists of 5 rows and 5 columns.
θ (Theta): First, calculate the parity value for each column, then XOR this parity value with the left adjacent column; simultaneously, perform a left rotation on the right adjacent column before XORing. This process involves basic binary operations such as "XOR" and "rotate-left."
ρ (Rho): Each word in the matrix is left-rotated by a different fixed distance. This step consists entirely of "rotate-left" operations.
π (Pi): Rearrange the words in the matrix according to a fixed pattern. Since this process is merely a positional permutation, it is typically considered a "zero-cost operation" in zero-knowledge proofs.
χ (Chi): Perform bitwise combination operations along each row, where each word is combined with its two adjacent words in that row. This operation includes "XOR," "negation," and "and."
ι (Iota): XOR the first word in the matrix with a fixed constant, involving only "XOR" operations.
The main challenge in implementing Keccak in zero-knowledge proofs is how to effectively represent these bit-level operations, especially since each operation affects 64-bit integers. This is why we refer to it as Keccak-1600—because the state space for each round is 5 × 5 × 64 = 1600 bits. Such operations need to be repeated for 24 rounds.
Next, we will briefly review some previous attempts to implement Keccak.
Attempt 1: Proof Systems Based on Groth16 or Other R1CS
The most popular and direct method currently is to use Groth16 or other R1CS (Rank-1 Constraint System) proof systems to implement Keccak. To express bit operations in Groth16, we represent each bit as 0 or 1 and simulate the following logical operations through arithmetic relations:
XOR: Using the expression a + b − 2ab
Negation: Using the expression 1 − a (which can usually be integrated into other constraints at no cost)
And: Using the expression a × b
Operations like "rotate-left" and other permutation operations are typically considered zero-cost operations in the ZK environment and do not require additional constraints.
According to calculations, the number of constraints in each round of Keccak is as follows:
The θ operation generates approximately 4480 constraints
The ρ and π operations are "zero-cost"
The χ operation generates approximately 3200 constraints
The ι operation generates 64 constraints
Thus, the complete Keccak-1600 (24 rounds in total) will produce 185,856 constraints in Groth16.
According to data from Ingonyama's ICICLE library, generating a ZK proof for Keccak on an Nvidia 4090 GPU takes about 30-40 milliseconds, while on a CPU it takes about 450 milliseconds. If 8192 Keccak operations need to be proven, the GPU would require at least 250 to 300 seconds, while the CPU might take close to an hour.
Attempt 2: Lookup-based Proof Systems
A more modern optimization approach is to process data in batches (for example, in groups of 4 or 8 bits) and use lookup tables to perform all bit operations. In other words, split each 64-bit integer into several smaller chunks (for example, 8 chunks of 8 bits) and use lookup tables to complete logical operations.
This includes the following types of lookup tables:
XOR Lookup Table: A lookup table of size 2⁸ × 2⁸, used to compute the XOR value of two 8-bit chunks. This allows for an 8-bit XOR to be completed with one constraint instead of the traditional 8 constraints.
AND Lookup Table: Similarly, a 2⁸ × 2⁸ lookup table for the bitwise AND operation of two 8-bit chunks, saving constraints similarly to XOR.
Rotate-left Lookup Table: To handle the frequently occurring rotate-left operations in Keccak, multiple lookup tables are introduced. Specifically, seven lookup tables of size 2⁸ correspond to rotation distances of 8k+1, 8k+2, etc. (where k is a non-negative integer). Compared to Attempt 1, which does not handle rotation operations at all, this approach incurs additional overhead—adding about 192 constraints per round. However, compared to other parts, this overhead remains relatively small.
To implement this system, we no longer use Groth16 but instead adopt smaller field proof systems like Stwo and Plonky3, which have better support for lookup tables. Under this scheme, each complete Keccak operation requires about 27,264 constraints, and the use of lookup tables can significantly reduce the overall number of constraints, optimizing it compared to Groth16.
However, this optimization is not absolutely superior in performance. The overhead of calling and managing the lookup tables can offset the advantages gained from the reduced number of constraints if not handled properly. Therefore, its actual operational efficiency may be inferior to implementations based on Groth16 in certain scenarios.
Attempt 3: Binius
Given that the acceleration brought by lookup tables or customized gates may not meet expectations in practice—due to the overhead of the lookup itself potentially offsetting the constraint optimization effects—we need to explore other paths to further enhance the proof efficiency of Keccak.
This is precisely why Keccak is hailed as the "holy grail of zero-knowledge." In comparison, earlier hash functions like SHA-256 and Blake2/3 also rely on bit operations such as XOR and AND, but their main performance bottleneck stems from integer addition. Integer addition is typically optimized in proof systems by breaking it down into multiple 4-bit blocks, significantly enhancing performance. However, Keccak does not involve any integer addition, rendering these optimization strategies ineffective.
The most cutting-edge solution currently is Binius. The core idea of this system is: since Keccak is entirely composed of bit operations, we can implement it using a proof system based on bits as the fundamental unit. This is where Binius makes its breakthrough.
In Binius, Keccak is represented as operations over the finite field 𝐹₂ (i.e., the binary field). Since XOR is essentially addition in 𝐹₂, its associated overhead is almost completely eliminated. The overall process is constructed as a series of polynomial operations, and bit rotation operations can also be easily implemented in a bitwise processing model. The proof cost mainly focuses on the AND gates that appear in the χ step.
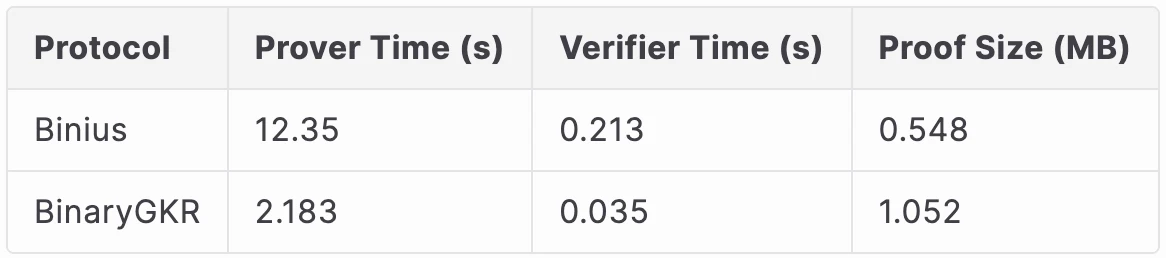
Benchmarking of Binius shows that it takes only about 12.35 seconds to prove 8192 Keccak operations, far outperforming Groth16 (Attempt 1) and the lookup table method (Attempt 2).
Is Binius the endpoint? Not at all. We have found that by removing certain redundant parts from the Keccak proof, it is possible to further enhance performance by about five times, surpassing the current Binius implementation.
Polyhedra Launches Binary GKR: A Binary Proof System Optimized for Keccak
The Polyhedra team is building a brand new proof system—Binary GKR (see: ePrint 2025/717), a framework specifically designed for efficient proof of binary operations, particularly suitable for functions like Keccak that are centered around bit operations. The core advantages of Binary GKR come from three key technological innovations:
1. GKR Protocol-Based Optimization of Redundant Computation
We chose to base the design of Binary GKR on the GKR protocol (Goldwasser–Kalai–Rothblum) because it effectively reduces the redundant overhead associated with handling repetitive computations.
In typical zkEVM scenarios, Keccak often appears as a "sidecar prover," used to batch process a large number of Keccak operations commissioned by zkEVM. Therefore, the circuit structure we are targeting naturally exhibits a lot of repetitive patterns, such as: 8192 Keccak calls being a common scale.
More importantly, the Keccak algorithm itself is highly repetitive:
It repeatedly performs similar Boolean operations on a 5×5 state matrix;
The entire process consists of 24 rounds of nearly identical steps;
The structure between rounds is the same, with only the input states differing.
These characteristics make Keccak a "natural fit" for the GKR protocol:
The verifier cost is low, suitable for high-frequency verification scenarios;
The prover can fully leverage structural repetitiveness, reusing computation paths and significantly simplifying proof overhead;
Compared to traditional general proof systems, it has significant performance advantages in batch Keccak scenarios.
2. Polynomial Commitment Based on Binary Fields
We adopted a polynomial commitment scheme based on linear codes that operates directly in the binary field. As we mentioned earlier, using native binary representation allows us to "freely" obtain operations such as XOR. Additionally, similar to Binius's approach, the polynomial commitment based on binary fields avoids the redundancy brought by using larger number fields, significantly enhancing the system's performance and efficiency.
3. Precomputation Tables for Binary Operations
A key innovation in the Binary GKR paper is that by fully utilizing the high sparsity of the circuit structure, the proof efficiency of the GKR protocol is significantly improved. This sparsity is preserved even when processing multiple bits simultaneously. Our approach is to "pack" multiple bits into the polynomials within the GKR protocol (note: these are intermediate polynomials that do not require commitment) and then directly perform the GKR protocol's operations on this packed data.
Since the sparsity remains high, we can utilize precomputation tables, allowing the prover to generate proofs with far lower computational overhead than traditional GKR protocols. This optimization significantly enhances the efficiency of GKR when handling binary relations.
This article will focus on the third technical optimization mentioned above: precomputation tables for binary operations.
Packing Bits into Polynomials
The core of our approach is a new method for sumcheck in the GKR protocol designed for data-parallel Boolean circuits. This method effectively reduces the computational burden on the prover by packing multiple bits into polynomials, significantly improving efficiency.

More Efficient Evaluation of Binary Relations
Compared to traditional GKR, Binary GKR brings a whole new optimization space.


The precomputation table is very small. By appropriately setting parameters, we can control the size of the table to about 15MB. This size can easily fit into the L3 cache of a CPU, making the lookup operation very efficient.
This technology is applicable to almost all binary operations and is the core of the performance improvement in the construction of Binary GKR.
Implementation and Evaluation
We implemented the SNARK system based on the Rust arkworks ecosystem and conducted comprehensive benchmarking on randomly generated Boolean circuits of various scales.
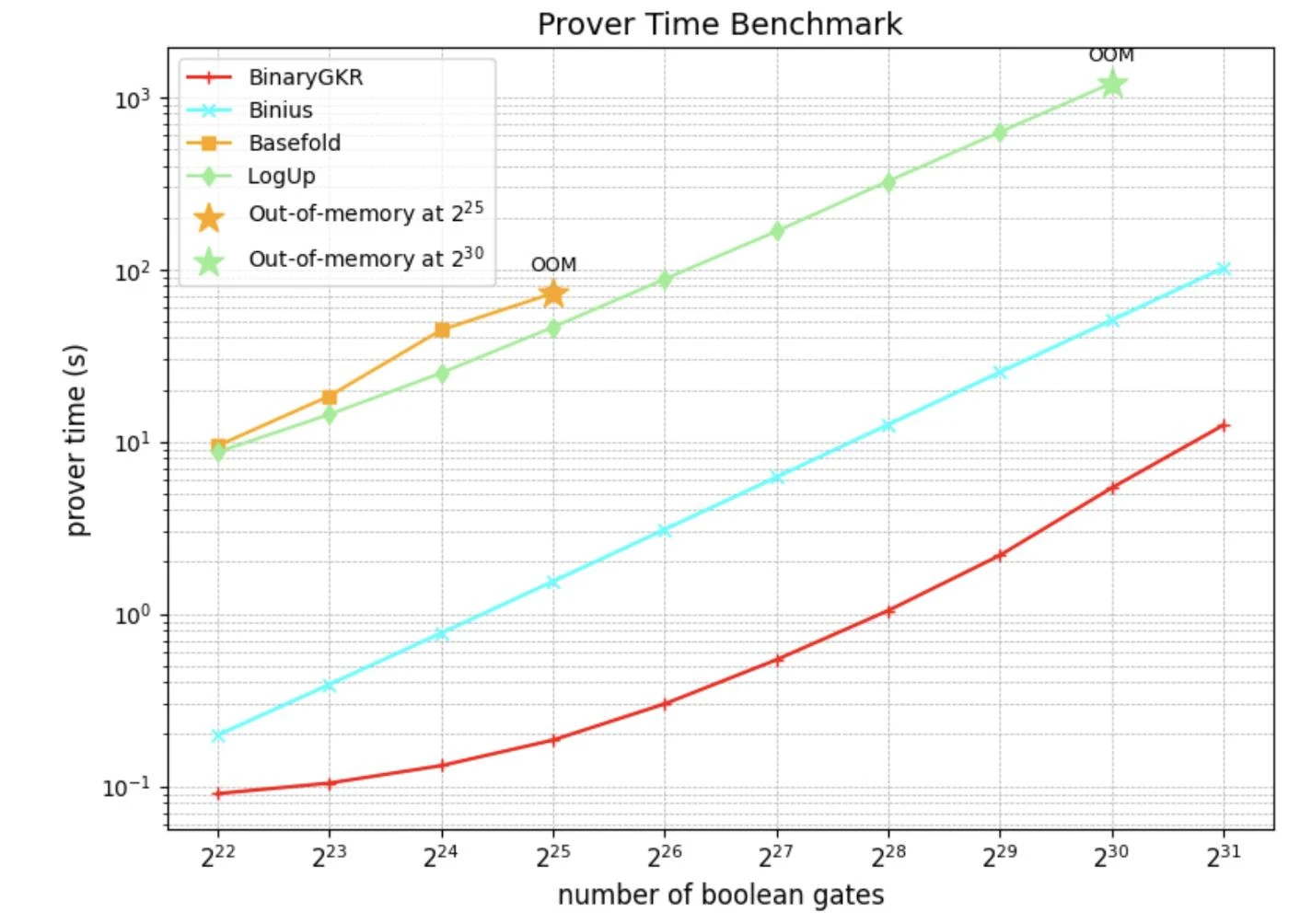
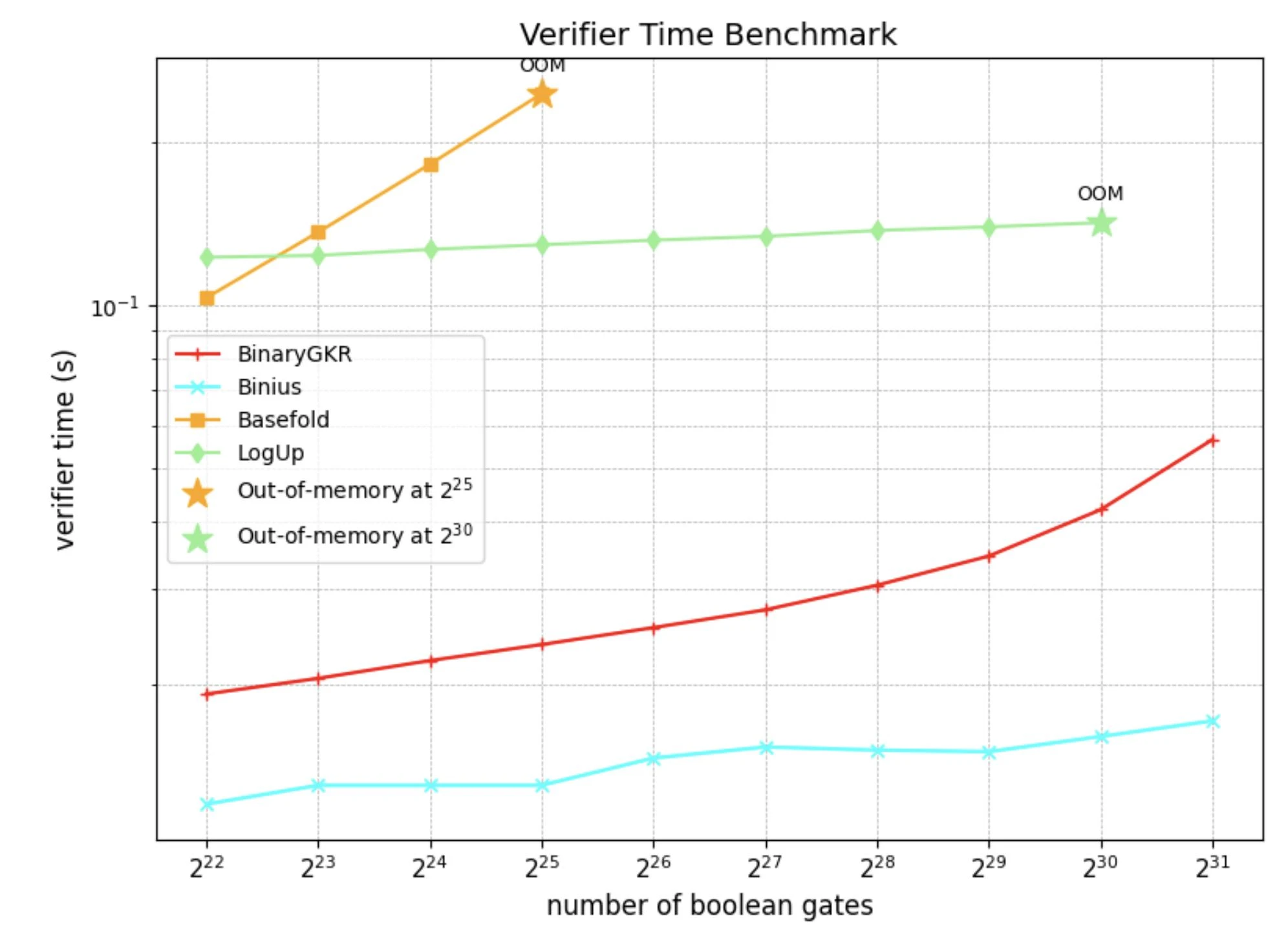
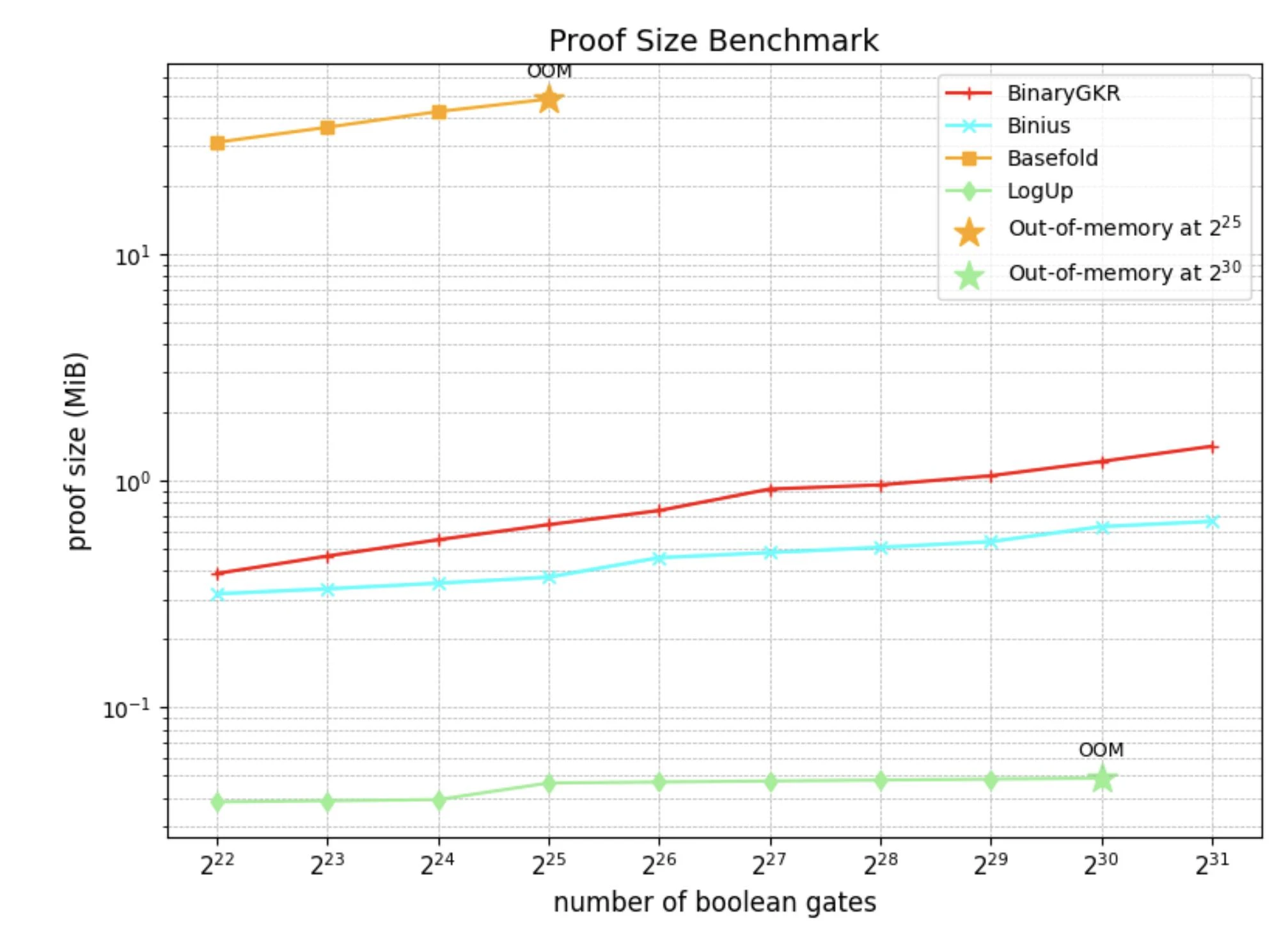
In addition to random Boolean circuits, we also focused on the "holy grail" of zero-knowledge proofs—Keccak. We compared the performance of our proposed method with Binius in Keccak proofs. Both are based on binary field operations.
When processing 8192 Keccak calls, Binius took 12.35 seconds to generate proofs, while our method only took 2.18 seconds. Additionally, thanks to the simple structure of Keccak, our verification time was also shorter, at just 0.035 seconds. In terms of communication overhead, our proof size was 1.052 MB.
Conclusion
This article presents the latest advancements by the Polyhedra team in the field of zero-knowledge proofs, focusing on optimizations for binary functions (such as Keccak). This achievement can serve as an efficient "auxiliary module" for various zkEVM constructions.
We plan to integrate Binary GKR into zkEVM systems such as RISC Zero and SP1 to further validate its role in alleviating the performance bottleneck of Keccak. The ultimate goal is to accelerate Ethereum's transition to a fully SNARK-based layer-1 without disrupting the existing EVM architecture.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







