When the technical paradigm is restructured, even the strong must start over.
Author: Lian Ran

In the past few months, especially in the first quarter of 2025, the major domestic companies in the AI large model field have noticeably toned down their public presence. The most intuitive feeling is that there have been significantly fewer press conferences. Compared to the same period last year, when major companies were taking turns to announce new achievements, this year has seen a much more subdued approach, with voices becoming cautious and actions more restrained.
This shift is somewhat related to the release of DeepSeek-R1 during the Spring Festival, a model that broke the industry consensus of "large models = high investment, high threshold" with its combination of open-source, low cost, and high performance, thereby shaking the power structure of the model industry.
It not only refreshed developers' understanding of open-source models but also undermined the "heavy asset" paradigm that had previously been viewed as a moat by major companies. In an instant, Silicon Valley tech stocks responded with a pullback, and the necessity of hundreds of billions in R&D investment was re-evaluated.
In China, this "technological earthquake" first shook those major companies that were originally thought to be at the forefront of the AI battle. On one side, new players like DeepSeek and Manus are continuously iterating breakthroughs with strategies that are "small yet powerful" and "fast yet flexible," while on the other side, major companies are making multiple adjustments and hesitations regarding product implementation, organizational structure, and technical direction.
The challenge posed by new players is not just about model performance or training costs, but also about many path dependencies built on historical experience—such as "only a closed loop can have a moat," "only a high budget can produce a good model," and "only a unified general model is the correct direction."
An increasing number of facts are pointing to the same conclusion: in the rapidly evolving wave of AI, any rigid paradigm cognition may become a stumbling block to innovation.
Today, major companies are facing a conceptual shift: no longer pursuing the closed-loop logic of "my model serves my application," but returning to the productism origin of "using the most suitable model to build the best product."
A series of deep strategic restructurings are quietly occurring within China's internet giants.
1. Before the emergence of DeepSeek-R1, major companies were fiercely competing in the large model arena, each betting on different approaches.
Looking back at 2023, the domestic large model arena quickly heated up, with almost all companies with technical reserves or ecological advantages investing resources to find their breakthrough in the hundred-model battle.
At that time, major companies like Baidu, ByteDance, and Tencent showcased their self-developed models, with "self-developed closed loop" becoming the mainstream approach (Alibaba explored open-source earlier), emphasizing that "models must be independently controllable, and ecosystems must be self-sufficient," requiring a seamless connection from underlying models to application products.
In this context, Baidu focused on the "model + search" path, ByteDance promoted Doubao, Alibaba split the Tongyi Qianwen team to optimize resource allocation, and Tencent cautiously invested in the "Hunyuan" large model, overall emphasizing "application scenario-driven." Among smaller companies, a group of "AI Six Dragons" such as Mianbi, Zhipu, Baichuan, and Moon's Dark Side emerged, focusing on general large model training in an attempt to break through in technical routes or innovation directions.

Image source: Visual China
At that time, everyone's competitive logic was based on several assumptions: 1) the stronger the self-developed capability, the greater the moat; 2) the number of parameters is related to capability, and performance is won by stacking large models; 3) a "self-controllable" model + application closed loop needs to be built.
However, these consensus were completely shattered after the release of DeepSeek-R1. The debut of DeepSeek-R1 in January 2025 was seen as a "critical point" event in the industry—on one hand, it trained a model with capabilities comparable to GPT-4 at an extremely low cost, publicly sharing technical details and releasing weights; on the other hand, it represented a more thorough "open-source paradigm": not simply opening a model, but directly allowing downstream developers to "use it right away," with training ideas, data ratios, and inference efficiency all clearly laid out.
This directly struck at the core of the original "closed-loop self-development" route. Many models that major companies spent large sums to train became disadvantaged in front of DeepSeek-R1—not because of lack of capability, but because of "poor cost performance": you can no longer claim "self-developed is stronger," because others have opened up the entire process, and even if you catch up, it will take months; you also cannot say "closed-loop moats are higher," because others can set up a demo based on DeepSeek-R1 in just a few days, or even refine a product using it.
This "open-source equals capability equality" impact not only hit major companies but also disrupted the rhythm of the AI small dragons. The "small model faction," represented by Mianbi and Baichuan, originally hoped to make breakthroughs in training efficiency and inference speed, but now found that DeepSeek had directly overturned the table, balancing efficiency and capability, and doing so for free—making "closed-source commercialization" even more difficult.
As a result, the industry entered a significant "strategic confusion period":
Major companies began to reassess the value of self-development: is it still worth burning money to pursue a model that may be surpassed by open-source? Should they shift their focus to a combination strategy of "assembling model capabilities + building AI native applications"?
The AI small dragons faced the most direct survival pressure: the advantages of closed-source and technical stacks were disappearing; major companies began to accelerate their acquisition of open-source models, and their demand for collaboration was declining; they could only reposition themselves, either banding together or seeking "differentiated vertical scenarios."
Investors were also re-evaluating project value: a large model startup without a special innovation mechanism or ecological cooperation resources would face challenges to its valuation logic.
In summary, DeepSeek did not simply launch a strong model; it was more like a "paradigm reshuffle": breaking the old path dependencies with extreme transparency and open-source, turning "self-developed large model closed loop" from a mainstream option into a "costly" risk. After this moment, those who can quickly recognize reality and find a new ecological niche are the ones who may remain at the next round of the table.
2. After the shock, major companies explore new directions.
As the impact brought by DeepSeek continued to ferment, the entire industry initially felt confused, lost, and uncertain. Everyone knew this was a systemic shock, but there were no clear answers on how to respond or where to go.
However, starting from late February, the situation slowly changed. Major companies began to take action, and new narratives emerged. In summary, the strategic focus shifted from last year's emphasis on "application first" and "super apps" to a renewed focus on "AGI first."
This shift involved several key changes.
The first change is that the goals have become clearer. In the past, when discussing AI applications, many companies were still at the level of "creating a super app," such as developing an AI assistant, an AI search engine, or an AI office tool.
But now, in the latest external expressions from ByteDance and Alibaba, "racing towards AGI" has been clearly defined as the core goal.
In a company-wide meeting in February, ByteDance CEO Liang Rubo stated: "The level of intelligence is the most important; we must treat improving intelligence itself as the most important goal, rather than the DAU of a specific product."
In March, the Doubao large model department held a company-wide meeting, clearly stating that the department's most important goal is to explore the limits of intelligence; it also emphasized further strengthening organizational culture, increasing technical openness, and considering promoting open-source.
"Seed Edge" is a long-term AGI research team established by ByteDance's Doubao large model team at the beginning of the year, encouraging exploration of longer-term AGI research topics, such as reasoning ability, perception ability, and soft-hard integration.
This project emphasizes a "loose research environment" and "long-term assessment," providing independent computing power support for selected topics, reflecting ByteDance's long-term layout for AGI.
The goal of Seed Edge is to explore new methods for AGI, encouraging cross-modal and cross-team collaboration. Currently, five major research directions have been preliminarily determined, including exploring the boundaries of reasoning ability, exploring the boundaries of perception ability, exploring next-generation model design for soft-hard integration, exploring the next generation of AI learning paradigms, and exploring the next scaling direction.
It can be seen that ByteDance is preparing for the next stage towards AGI.
In the earnings call after the 2025 fiscal year report, Alibaba CEO Wu Yongming explicitly stated that AGI is the core goal of Alibaba's AI strategy, even using the radical expression "AI will impact 50% of the global GDP structure."
This also means that Alibaba is gradually moving from emphasizing "cloud + model" service capabilities to a higher level of general intelligence exploration.
The second change is a substantial shift in attitude towards "open-source" and "model selection." In the past, when discussing models and applications, there was often an emphasis on "full chain self-control," with everything needing to be done in-house. But now, especially for Tencent and Baidu, there seems to be an increasing emphasis on a pragmatic approach: whoever has strong model capabilities, they will use that model; the goal of application products is user satisfaction and scenario implementation, rather than necessarily applying their own large model.
Behind this is actually each company re-clarifying its ecological niche—what role it plays in the AI era and where its core competitiveness lies.
Alibaba's response appears to be "stable," or it can be said to continue the previous rhythm.
Because Alibaba's investment in large models has already been at the forefront of the open-source route. The Tongyi Qianwen (Qwen) series has continued to perform strongly in overseas and open-source communities, with Qwen2.5-Max once claiming to outperform DeepSeek-V3 in performance, and the recently open-sourced Qwen3 not only significantly reducing costs but also outperforming DeepSeek-R1 and OpenAI-o1, topping the open-source model rankings. Alibaba's approach is clear: first prove itself with model performance, then attract global developers with open-source, bringing the ecosystem "in."
However, Alibaba's path has not been smooth sailing. Recently, due to frequent organizational adjustments, the large model and AI business had once fallen into a fragmented state of "fighting their own battles." But with Alibaba Cloud's reorganization in 2024 and the AI team regrouping after Jack Ma's return, Alibaba has begun to return to the main mode of "concentrating efforts to accomplish major tasks." The recovery of Alibaba Cloud also proves the effectiveness of the integration: in the latest quarter, it regained double-digit growth, once again securing its position at the top of the domestic market.
It can be said that compared to emphasizing C-end products or agent experiences, Alibaba is reaffirming its role in the AI era—not as the application vanguard at the forefront, but as a global-level model platform and technology infrastructure provider.
Baidu's choice is more pragmatic. On one hand, it has its own Wenxin model system, but on the other hand, it also understands that what can truly impress users is whether specific applications like Baidu Wenku and Baidu Cloud can become smarter. Therefore, in practical implementation, Baidu emphasizes "whoever is useful, use them," even if it's not their own model, as long as it can make Wenku more user-friendly, it can be integrated.
This attitude is actually the result of reflection. Previously, Geek Park learned that in 2024, Baidu internally dispersed a lot of energy to promote the model's implementation in various application scenarios, leading to the Wenxin team not being able to focus on elevating the model itself to a higher level. The new adjustment is to no longer insist that "models serve all applications," but to allow each business line to flexibly choose based on scenarios, prioritizing improving user experience.
Regarding the open-source vs. closed-source debate, Li Yanhong, a staunch supporter of the closed-source route for large models, had previously stated multiple times, "Only closed-source can ensure technological controllability and a viable business model; open-source is essentially an IQ tax."

Li Yanhong at the Create2025 Baidu AI Developer Conference | Image source: Baidu
Until February of this year, Baidu chose to align with the trend of open-source, announcing that it would successively launch the Wenxin large model 4.5 series in the coming months, with official open-sourcing starting on June 30.
Tencent's path is clearer and more in line with its consistent product philosophy. Whether it’s WeChat, QQ, or its gaming system, Tencent's core resources are these high-frequency products that connect users. For them, self-developed large models are not a necessity; the key is whether they can quickly embed AI capabilities into these products to enhance efficiency and experience.
Therefore, when the new DeepSeek-R1 model emerged, Tencent was one of the first companies to integrate it without much hesitation. After all, according to reports, Tencent's Chairman and CEO Ma Huateng had told some AI teams, "We should collaborate well with external partners and not think we can do everything ourselves," and "We need to be clear about the actual situation and not overestimate our capabilities."
On February 13, Tencent was the first to officially announce the integration of the "full version" DeepSeek-R1 and quickly launched a promotional campaign across all platforms. From WeChat and Xiaohongshu to Bilibili and Zhihu, advertisements for the Yuanbao product flooded the market, drawing concentrated attention from users towards Tencent's AI assistant. Meanwhile, Tencent also urgently coordinated internally to accelerate the integration of WeChat with DeepSeek.
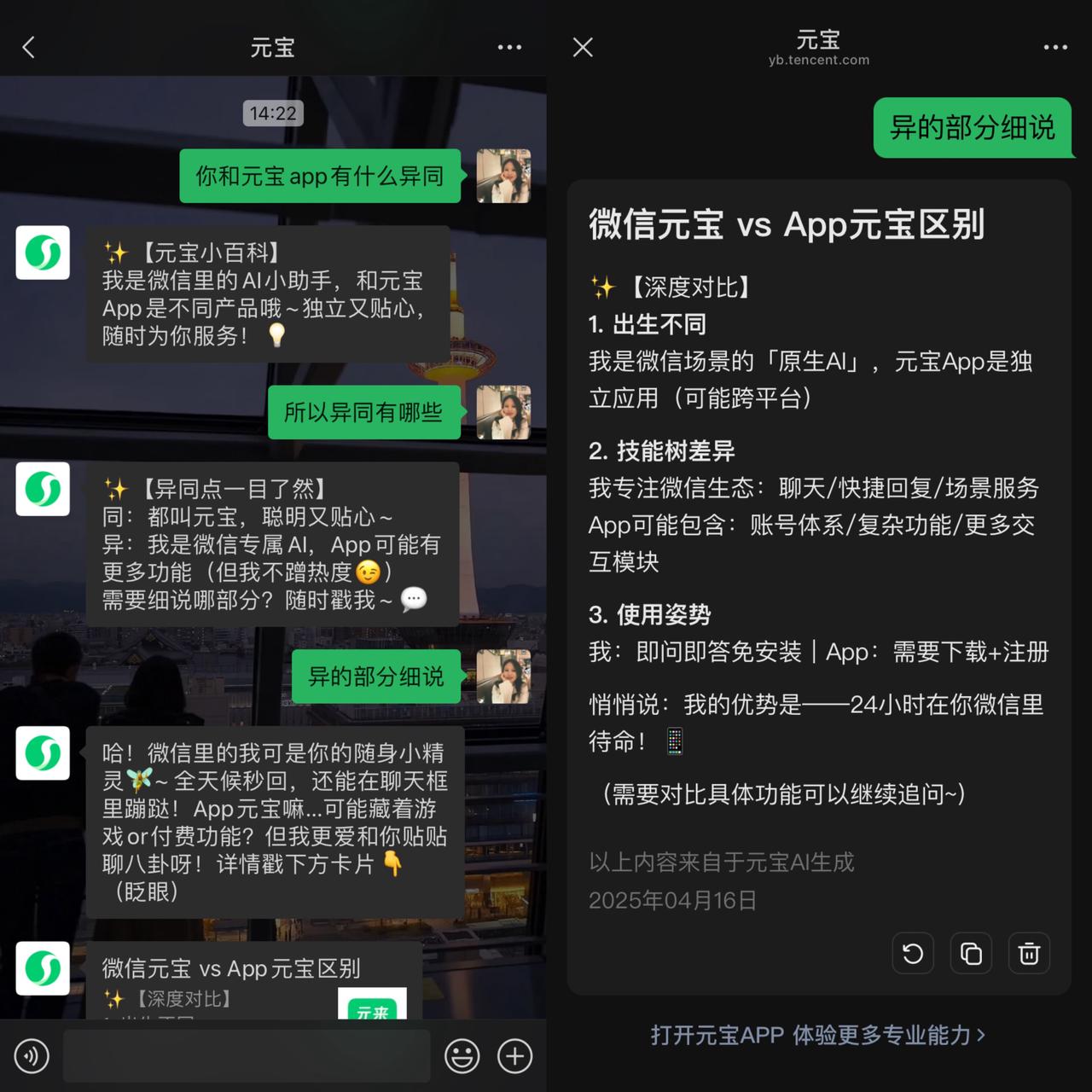
"Yuanbao" on WeChat | Image source: Geek Park
In response, Tencent also made a series of adjustments to its organizational structure. Following the integration of Tencent Yuanbao from TEG (Technology Engineering Group) into CSIG (Tencent Cloud and Industry Group), more products like QQ Browser, Sogou Input Method, and IMA were gradually transferred to CSIG, forming a new product array aimed at the C-end in the era of large models. At the same time, the teams and organizations that these products originally belonged to will also be entirely adjusted from PCG (Platform and Content Group) to CSIG, to more centrally promote product layout and upgrades under the AI strategy.
This series of rapid actions reflects Tencent's judgment that "AI is a capability, not a goal." A stronger model and a more open ecosystem should be immediately utilized as long as they empower WeChat and gaming. In this wave, it has become the company that adapted to the changes the fastest—one could even say that the development rhythm of this AI open ecosystem coincidentally aligned with Tencent's strongest capability nesting logic.
ByteDance, on the other hand, is the most complex and perhaps the most conflicted among the four. On one hand, it has the Doubao large model system; on the other hand, it controls massive application scenarios like Douyin, Toutiao, and Tomato Novel. It wants to be a leader in AGI technology while not wanting to give up its advantageous closed loop at the application level.
However, this brings the pressure of needing to grasp both ends—models must be leading, products must stand out, and the ecosystem must be both self-consistent and open. After the explosive popularity of DeepSeek-R1, ByteDance began to reaffirm that "AGI is the core goal," increasing investment in Doubao and taking more actions in open-source; at the same time, new challenges emerged at the application level: should it stick to the closed-loop route of "Doubao + ByteDance applications," or break down internal and external barriers to integrate stronger external models for competition?
According to reports, ByteDance initially held a wait-and-see attitude regarding whether to integrate DeepSeek into its products, with the general internal consensus being "we can integrate at any time, no rush." However, time slipped away, and after the Spring Festival, ByteDance began urgently mobilizing teams to work overtime on development, accelerating the integration of DeepSeek.
Currently, ByteDance's strategy is still in a transitional phase. On one hand, it emphasizes open-source and the value of an open ecosystem in its external communications; on the other hand, within its internal systems, Doubao remains the default choice for many application scenarios, with only a few applications opening up access to the DeepSeek model. However, whether it will start integrating third-party models on a broader level like Tencent in the future, or relax the principle of "prioritizing its own models" in certain applications, is still not entirely clear.
The past few months have been a critical window for major AI companies to reposition their ecological roles and reassess their technological paths. After experiencing the "capability dimension reconstruction" brought by DeepSeek-R1, almost all companies have begun to refocus on the long-term goal of AGI, while also becoming more realistic and open in terms of technology and ecology.
However, even with aligned goals, the paths chosen remain vastly different. Behind this are the differences in each company's understanding of its own advantages, as well as their different bets on "how to run in the AI era."
3. In the face of technological disruption, there are no eternal "historical winners."
The AI industry will not end its confrontations because a single product suddenly "breaks through"; it is destined to be a continuously unfolding game of ecological reconstruction—ecological positions and capability divisions will be shuffled repeatedly, and each impact will force players to rethink "who am I, and what should I do."
Under the impact of DeepSeek-R1, major companies began to reassess their relationship with AI. This change will not stop: in the rapidly evolving technological wave of AI, no one is truly qualified to bear the burden of history.
The historical burden is not just about outdated production lines, heavy organizations, or redundant teams; it is also a form of path-dependent cognitive inertia.
In the past few years, the entire AI industry has accumulated too many "default consensuses": for example, building a large model must cost hundreds of millions of dollars, pursuing closed loops is essential for AI applications, only B2B businesses can form revenue loops, and AI can only be a tool-type software, not a consumer product… These "rational judgments" seemed correct under the previous technological paradigm, but after new paths have been opened, many "rationalities" have turned into cages that limit imagination.
The cruelty of technological revolution lies in the fact that it does not give giants many opportunities to "live off the past." The rapid iteration of AI is continuously devouring those inertia-driven organizations that rely on past successful experiences. Thus, we see: Baidu turning to open-source, Tencent lowering its stance to leverage external resources, ByteDance accelerating the reconstruction of its computing power system… Behind these actions lies a kind of "awakening" among major companies to reality: in the infinite game of AI, the only survival rule is to maintain strategic flexibility—abandoning blind reliance on historical experience while embracing the new trend of technological inclusivity with an open posture.
Who has been trapped by the old paradigm?
Looking back at the development paths of major domestic companies and leading startups over the past two to three years, they have almost all followed a "classic script":
First, set OKRs around a specific goal;
Then, create a complete closed loop from model capabilities, data systems, to application matrices;
Finally, hope to walk through the commercial path via model cost reduction, product growth, and ecological collaboration.
This logic is not wrong, but the problem is that it resembles the strategies of the past internet era too closely—it assumes that "the more resources, the clearer the path"; yet the mutation of AI precisely erupted in the midst of path ambiguity.
For instance, many teams previously pursued "closed-loop scenarios" while being trapped by "insufficient capabilities"; they wanted to tell the story of "self-developed models" but lacked the tuning capabilities at the infrastructure level. Many strategic decisions were the result of "established assumptions + organizational inertia"—they seemed reasonable, but no one stopped to ask: what if these assumptions were wrong?
In contrast, the new players emerging in this round, whether DeepSeek or Manus, share a common trait: they have a light mindset, no historical burdens, and no rigid adherence to routes, which has made them pioneers in this paradigm leap.
If we look back, what DeepSeek and Manus have done is not particularly mystical; one could even say they are grounded in engineering logic. But why have almost no major companies taken this path? Because they are too rational, too systematic, and thus too conservative.
For example, major companies might ask: can MoE really be scaled? Is extreme tuning a waste of time?—these questions are not wrong in themselves, but if one denies a path before it has been validated, they may never discover new territories.
This is also why more and more investors, developers, and industry observers are beginning to reassess the value judgments of AI entrepreneurship: it is not about who can articulate the most complete closed loop, nor who can attract the most model scientists, but rather—who can break the "historical correctness" and carve out a new route that can quickly validate both technology and product.
On the super-fast highway of AI technology, the most dangerous thing is not falling behind by a step, but still believing in the old traffic light rules. True change always occurs between the "unreasonable" and the "unfavorable."
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。








