Compilation: Strange thinking, BlockBeats
Translator's Note: In March of this year, 0G Labs completed a $35 million Pre-Seed round of financing led by Hack VC. 0G Labs aims to build the first modular AI chain to help developers launch AI dApps on a high-performance, programmable data availability layer. Through innovative system design, 0G Labs strives to achieve gigabyte-level on-chain data transfer per second, supporting high-performance applications such as AI model training.
In the fourth episode of the DealFlow podcast, BSCN Editor-in-Chief Jonny Huang, MH Ventures General Partner Kamran Iqbal, and Animoca Brands Investment and Strategic Cooperation Director Mehdi Farooq jointly interviewed 0G Labs co-founder and CEO Michael Heinrich. Michael shared his personal background, from being a software engineer at Microsoft and SAP Labs to founding the Web2 company Garten, which was valued at over $1 billion, and now fully dedicating himself to 0G, aiming to build a modular AI technology stack on the blockchain. The discussion covered the current status and vision of DA, the advantages of modularity, team management, and the mutual dependency between Web3 and AI. Looking ahead, he emphasized that AI will become mainstream, bringing about significant social change, and Web3 needs to keep up with this trend.

The following is the transcript of the interview:
Web2 Unicorn Leader Ventures into Entrepreneurship Again
Jonny: Today, we want to delve into an important topic—data availability (DA), especially in the field of encrypted AI. Michael, your company has a significant say in this area. Before we delve into the details, could you briefly introduce your professional background and how you entered this niche field?
Michael: I initially worked as a software engineer and technical product manager at Microsoft and SAP Labs, focusing on cutting-edge technology in the Visual Studio team. Later, I transitioned to the business side, working at Bain & Company for a few years, and then moved to Connecticut to work for Bridgewater Associates, responsible for portfolio construction. I had to review about $60 billion in transactions daily and gained a deep understanding of various risk indicators. For example, we examined CDS rates to assess counterparty risk, among other things. This experience gave me a deep understanding of traditional finance.
Afterward, I returned to Stanford for postgraduate studies and founded my first Web2 company, Garten. At its peak, the company expanded to 650 employees, with annual revenue reaching $100 million and total financing of approximately $130 million. It became a unicorn company valued at over $1 billion and a star project incubated by Y Combinator.
At the end of 2022, my Stanford classmate Thomas contacted me. He mentioned that he had invested in Conflux five years ago and believed that Ming Wu and Fan Long were the most outstanding engineers he had supported. He suggested that the four of us should get together and see if we could spark something. After six months of interaction, I reached the same conclusion. I thought to myself, "Wow, Ming and Fan are the most outstanding engineers and computer scientists I have worked with. We must start a business together." I transitioned to the Chairman of Garten and fully dedicated myself to 0G.

The four co-founders of 0G Labs, from left to right: Fan Long, Thomas Yao, Michael Heinrich, Ming Wu
Current Status, Challenges, and Ultimate Goal of DA
Jonny: That's one of the best founder introductions I've heard. I guess your VC financing process must have been very smooth. Before delving into the topic of data availability, I'd like to discuss the current status of DA. Although some players are well known, how do you assess the landscape of DA at present?
Michael: DA currently has various sources, depending on the blockchain. For example, before the Ethereum Danksharding upgrade, Ethereum's DA was about 0.08 MB per second. Later, Celestia, EigenDA, and Avail entered the market, with their throughput typically ranging from 1.2 to 10 MB per second. The issue is that this throughput is far from sufficient for AI applications or any on-chain gaming applications. What we need to discuss is gigabyte-level per second, not megabyte-level DA. For example, if you want to train an AI model on-chain, you actually need a data transfer rate of 50 to 100 GB per second to achieve it. This is an order of magnitude difference. We saw this opportunity and thought about how to create this breakthrough, enabling large-scale Web2 applications to be built on-chain with the same performance and cost. This is a huge gap we see in this field. Additionally, there are some issues that have not been fully considered. For example, we believe that data availability is a combination of data publication and data storage. Our core insight is to split the data into these two channels to avoid broadcast bottlenecks in the system, thereby achieving breakthrough performance improvements.
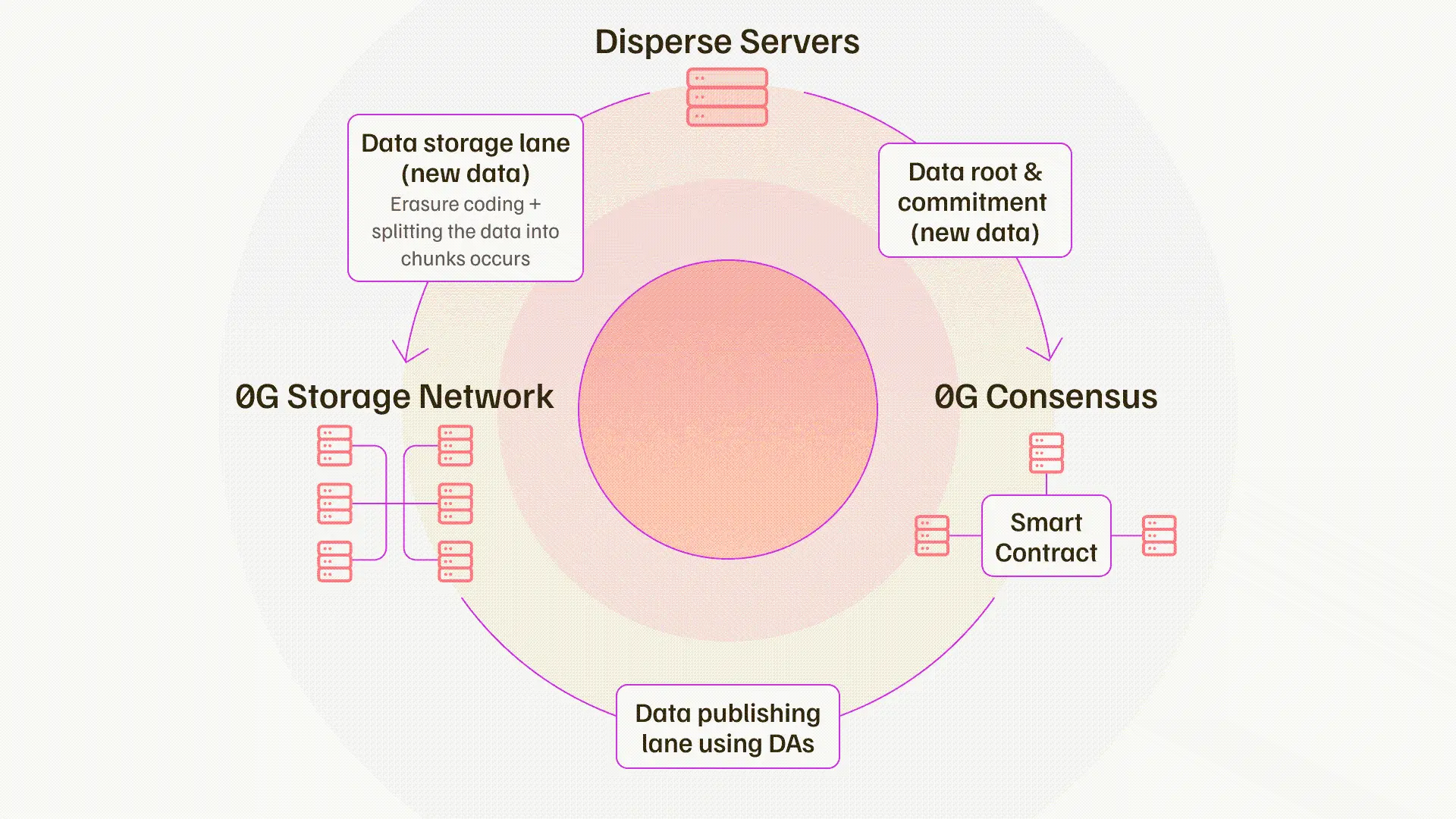
An additional storage network can enable you to do many things, such as model storage, training data storage for specific use cases, and even programmability. You can perform complete state management, decide where to store data, how long to store it, and how much security is needed. Therefore, various real-world use cases that are truly needed are now possible.
The current status of DA is that we have made significant progress, increasing from 0.08 MB per second to 1.4 MB per second, significantly reducing transaction costs, and even reducing them by 99% in some cases. But for the real needs of the future world, this is still not enough. High-performance AI applications, on-chain games, high-frequency DeFi—all these applications require higher throughput.
Mehdi: I have two fundamental questions. First is about storage. You mentioned L2 transaction history and even the history of AI models. Regarding storage, how long do we need to store the data? That's my first question. The second question is, there are already decentralized storage networks like Arweave and Filecoin. Do you think they can help increase throughput? I'm not referring to data publication, but storage.
Michael: The storage duration of data depends on its purpose. If we consider disaster recovery, data should be stored permanently to reconstruct the state when needed. For optimistic rollups with fraud proof windows, at least 7 days of storage is needed to reconstruct the state when necessary. For other types of rollups, the storage time may be shorter. The specifics vary, but that's the general idea.
As for other storage platforms, we chose to build an internal storage system because Arweave and Filecoin are more designed for log-type storage, which is long-term cold storage. Therefore, they are not designed for very fast data writing and reading, which is crucial for AI applications and structured data applications that require key-value storage or transactional data types. This is essential for achieving fast processing and even building decentralized Google Docs applications.
Jonny: You've explained very clearly why DA is needed and why existing decentralized storage solutions are not suitable for this specific scenario. Could you discuss the ultimate goal of data availability?
Michael: The ultimate goal is easy to define. What we aim to achieve is performance and cost equivalent to Web2, making it possible to build anything on-chain, especially AI applications. It's straightforward, just like how AWS has computing and storage, with S3 being a key component. Although data availability has different characteristics, it is also a key component. Our ultimate goal is to build a modular AI technology stack, where the data availability component includes not only data publication but also storage components integrated by the consensus network. We let the consensus network handle data availability sampling, and once consensus is reached, we can provide proof on the underlying Layer 1 (such as Ethereum). Our ultimate goal is to build an on-chain system that can run any high-performance application, even supporting on-chain AI model training.
Kamran: Can you provide more details about your target market? Besides AI and those building AI applications on the blockchain, what other projects do you hope will use 0G?
Michael: You've mentioned one application area. We are striving to build the largest decentralized AI community and hope to have a large number of projects building on top of us. Whether it's Pond building large graph models, or Fraction AI or PublicAI doing decentralized data labeling or cleaning, or even execution layer projects like Allora, Talus Network, or Ritual, we are working to establish the largest community for AI builders. This is a fundamental requirement for us.
But in reality, any high-performance application can be built on top of us. For example, in the case of on-chain games, with 5000 users in a non-compressed scenario, 16MB of data availability per second is needed to achieve a complete on-chain game state. Currently, there is no DA layer that can do this, perhaps Solana can, but it is different from the Ethereum ecosystem and has limited support. So, such applications are also very interesting to us, especially if they combine on-chain AI agents (such as NPCs). There is a lot of potential for cross-application in this area.
High-frequency DeFi is another example. Future fully homomorphic encryption (FHE), data markets, high-frequency deep-end applications—all of these require very high data throughput and need a DA layer that can truly support high performance. Therefore, any high-performance dApp or Layer2 can be built on top of us.
Modular Advantages: Flexible Choices
Mehdi: You are working to improve scalability, throughput, and address the state bloat issue caused by storage components. Why not just launch a complete Layer1? If you have the ability to make a technological breakthrough, why adopt a modular approach instead of creating a Layer1 with its own virtual machine? What is the logic behind the modular stack?
Michael: Fundamentally, we are a Layer1, but we believe that modularity is the future of application development. And we are modular, not ruling out the possibility of providing an execution environment specifically optimized for AI applications in the future. We haven't fully determined the roadmap in this regard, but it is possible.
The core of modularity lies in choice. You can choose the settlement layer, execution environment, and DA layer. Developers can choose the best solution based on different use cases. Just like in Web2, the reason why TCP/IP was successful is because it is fundamentally modular, and developers can freely choose to use its different aspects. Therefore, we hope to give developers more choices to build the most suitable environment for their application types.
Mehdi: If you were to choose a virtual machine now, which virtual machine on the market would be most suitable for the applications you are considering or striving to achieve?
Michael: I have a very practical view on this. If we want to attract more Web2 developers into Web3, it should be some kind of WASM virtual machine that can be used to build applications with the most common programming languages such as JavaScript or Python. These languages may not necessarily be the best choice for on-chain development.
The Move VM is excellently designed in terms of objects and throughput. If high performance is the goal, this is a choice worth considering. If we consider battle-tested virtual machines, that would be the EVM, because there are a large number of Solidity developers. So the choice depends on the specific use case.
Priority Sorting and Community Building
Jonny: I'd like to hear about the biggest obstacles you are facing, or is everything going smoothly? I can't imagine that your business is so vast that everything has been smooth sailing all the time.
Michael: Yes, I think any startup company will face challenges, there will always be some obstacles. From my perspective, the biggest challenge is ensuring that we can keep up with the pace, as we have to execute multiple tasks exceptionally well and have to make some trade-offs to enter the market quickly.
For example, we originally wanted to launch with a custom consensus mechanism, but that would have extended the launch time by four to five months. So we decided to use an existing consensus mechanism in the first phase, do a strong proof of concept, and achieve part of the end goal, such as 50 GB per second for each consensus layer. Then in the second phase, introduce horizontally scalable consensus layers to achieve unlimited DA throughput. Just like turning on another AWS server, we can add additional consensus layers to increase the overall DA throughput.
Another challenge is ensuring that we can attract top talent to join the company. Our team is strong, including winners of the Informatics Olympiad and top computer science PhDs, so we need the marketing team and new developers who join to match that.
Jonny: It sounds like the biggest obstacle you are currently facing is priority sorting, right? Accepting that it's not possible to do everything in a short time and having to make some trade-offs. What about competition? How do you view it? I guess Celestia or EigenDA wouldn't pose a serious threat to your specific use case.
Michael: In Web3, competition largely depends on the community. We have built a strong community around high performance and AI building, while Celestia and EigenDA may have more general-purpose communities. EigenDA may be more concerned with bringing economic security and building AVS on the EigenLayer, while Celestia is more concerned with which Layer2 wants to reduce their transaction costs and doesn't have many high-throughput applications. For example, building high-frequency DeFi on Celestia is very challenging because you need multi-megabyte throughput per second, which would completely clog the Celestia network.
From this perspective, we don't really feel threatened. We are building a very strong community, and even if others appear, we already have network effects in terms of developers and market share, and are expected to gain more funding as a result. So, the best defense is our network effect.
Mutual Dependency between Web3 and AI
Jonny: You have chosen artificial intelligence as the main focus, but why does Web3 need to host artificial intelligence within its ecosystem? Conversely, why does artificial intelligence need Web3? This is a two-way question, and the answers to both questions may not necessarily be affirmative.
Michael: Of course, Web3 without AI is possible. But I believe that in the next 5 to 10 years, every company will become an AI company, because AI will bring about huge changes like the internet did. Do we really want to miss this opportunity in Web3? I don't think so. According to McKinsey, AI will unlock trillions of dollars in economic value, and 70% of jobs can be automated by AI. So why not leverage it? Web3 without AI is possible, but with AI, the future will be even better. We believe that in the next 5 to 10 years, most participants on the blockchain will be AI agents, performing tasks and transactions for you. This will be a very exciting world, and we will have a large number of AI-driven, customized automated services for users.
On the contrary, I believe AI absolutely needs Web3. Our mission is to make AI a public good. Fundamentally, this is an issue of incentives. How do you ensure that AI models don't cheat, and how do you ensure that they make decisions that are most beneficial to humanity? Alignment can be broken down into incentive, verification, and security components, each of which is very suitable to be implemented in a blockchain environment. Blockchain can help achieve tokenization and incentives, creating an environment where AI is economically disincentivized to cheat. All transaction history is also on the blockchain. Here's a bold statement: fundamentally, I believe everything, from training data to data cleaning components, to data ingestion and collection components, should be on-chain, allowing for a complete traceability of who provided the data and what decisions the AI model made.
Looking ahead 5 to 10 years, if AI systems are managing logistics, administrative, and manufacturing systems, I would want to know the version of the model, its decisions, and supervise models that surpass human intelligence to ensure alignment with human interests. I'm not sure if we can trust a few companies to consistently ensure the security and integrity of such a system, especially considering the superpowers AI models may have in the next 5 to 10 years, by putting AI into a black box that may cheat and make decisions not in the best interest of humans.
Kamran: We all know that the crypto space is full of various narratives, and with your strong focus on the AI field, do you think this will be an obstacle for you in the long run? As you mentioned, your tech stack will far surpass what we currently see. Do you think the narratives and naming around AI itself will hinder your development in the future?
Michael: We don't think so. We firmly believe that in the future, every company will become an AI company. There will hardly be any company that does not use AI in some form in its applications or platforms. From this perspective, every time GPT releases a new version, such as one with trillions of parameters, unlocking new capabilities previously unavailable and achieving higher performance levels, I think the excitement will continue because this is a whole new paradigm. This is the first time we can tell computers in human language what to do. In some cases, you can achieve capabilities beyond ordinary humans, automating processes that were previously impossible. For example, some companies have almost completely automated their sales development and customer support. With the release of GPT-5, GPT-6, and so on, AI models will become even smarter. We need to ensure that we keep up with this trend in Web3 and build our own open-source version.
It is crucial that AI agents running parts of society in the future are governed by blockchain in the appropriate manner. In 10 to 20 years, AI will definitely be mainstream, bringing about huge societal changes. Just look at Tesla's fully autonomous driving mode to see that the future is becoming a reality day by day. Robots will also enter our lives, providing us with a lot of support. We are basically living in a science fiction movie.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







