Original Source: Quantum Bit

Image Source: Generated by Wujie AI
Pika teams up with Peking University and Stanford to open source the latest text-image generation/editing framework!
It allows diffusion models to have a stronger understanding of prompt words without the need for additional training.
When faced with extremely long and complex prompt words, it achieves higher accuracy, stronger control over details, and more natural image generation.
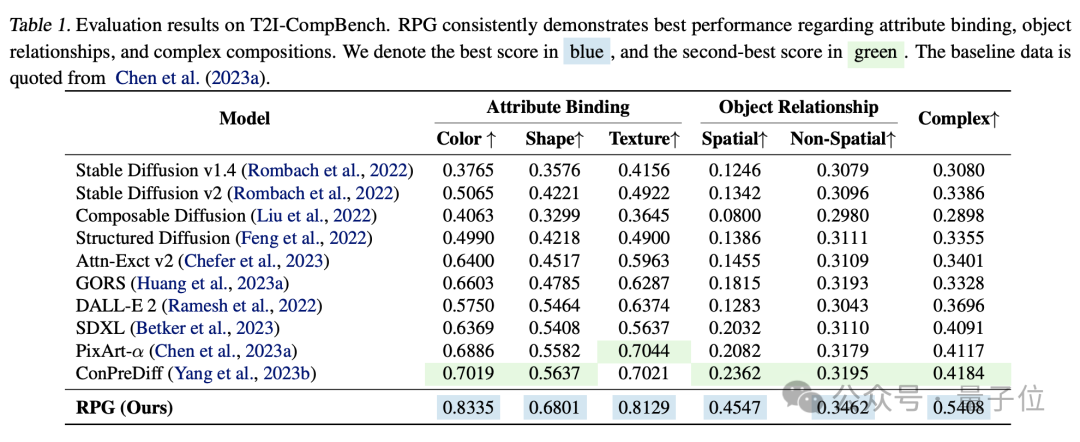
Its performance surpasses the strongest image generation models Dall·E 3 and SDXL.
For example, if asked to depict a scene of "ice and fire" with an iceberg on the left and a volcano on the right.
SDXL completely fails to meet the requirements of the prompt words, and Dall·E 3 fails to generate the detail of a volcano.

It also allows for secondary editing of generated images using prompt words.

This is the text-image generation/editing framework RPG (Recaption, Plan and Generate), which has sparked discussions online.

It was jointly developed by Peking University, Stanford, and Pika. The authors include Professor Cui Bin from Peking University's School of Computer Science and Pika's co-founder and CTO Chenlin Meng.
The framework's code has been open sourced and is compatible with various multimodal large models (such as MiniGPT-4) and diffusion model backbones (such as ControlNet).
Enhancing with Multimodal Large Models
Historically, diffusion models have been relatively weak in understanding complex prompt words.
Some existing improvement methods either fail to achieve good final results or require additional training.
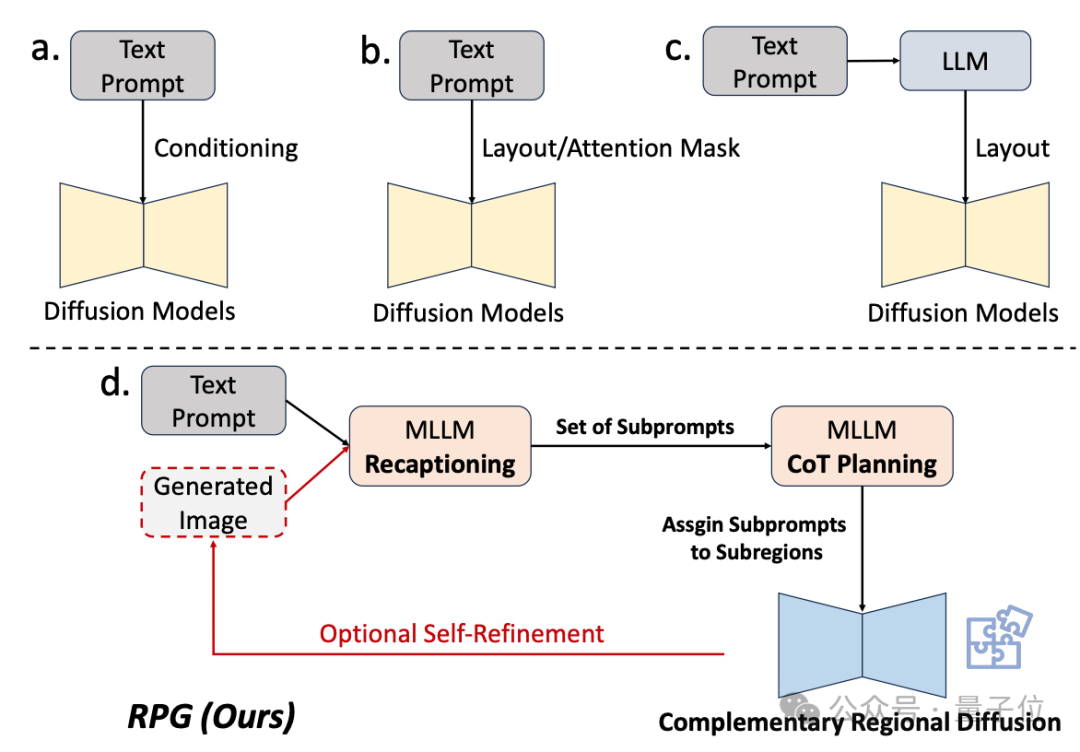
Therefore, the research team utilized the understanding capabilities of multimodal large models to enhance the combinational and controllable abilities of diffusion models.
From the name of the framework, it is clear that it allows the model to "recapture, plan, and generate."
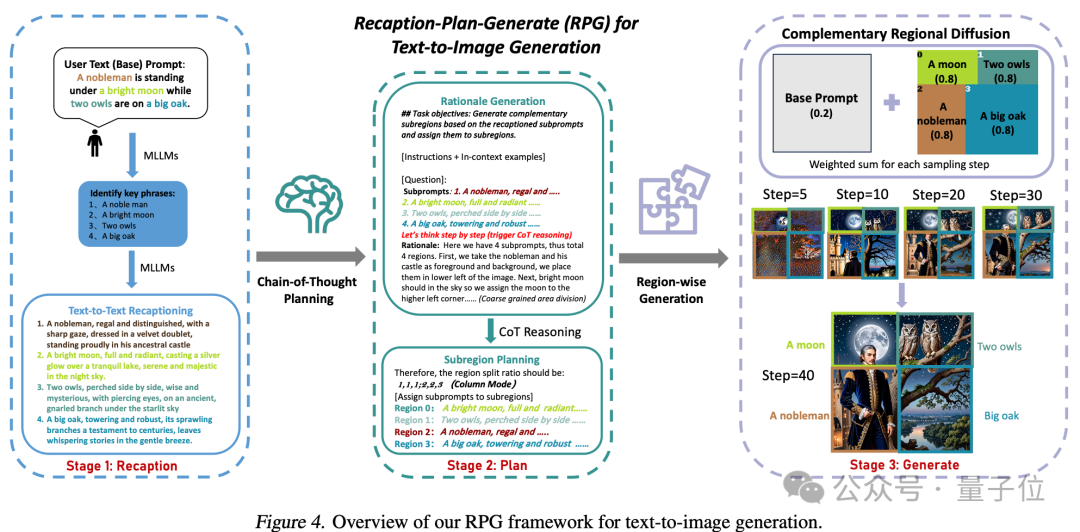
The core strategy of this method includes three aspects:
1. Multimodal Recaptioning: Utilizing large models to break down complex textual prompts into multiple sub-prompts and provide more detailed recaptions for each sub-prompt, thereby enhancing the diffusion model's understanding of the prompts.
2. Chain-of-Thought Planning: Utilizing the chain-of-thought reasoning ability of multimodal large models to divide the image space into complementary sub-regions and match different sub-prompts to each sub-region, breaking down complex generation tasks into simpler ones.

3. Complementary Regional Diffusion: After dividing the space, non-overlapping regions generate images based on their respective sub-prompts, which are then combined.
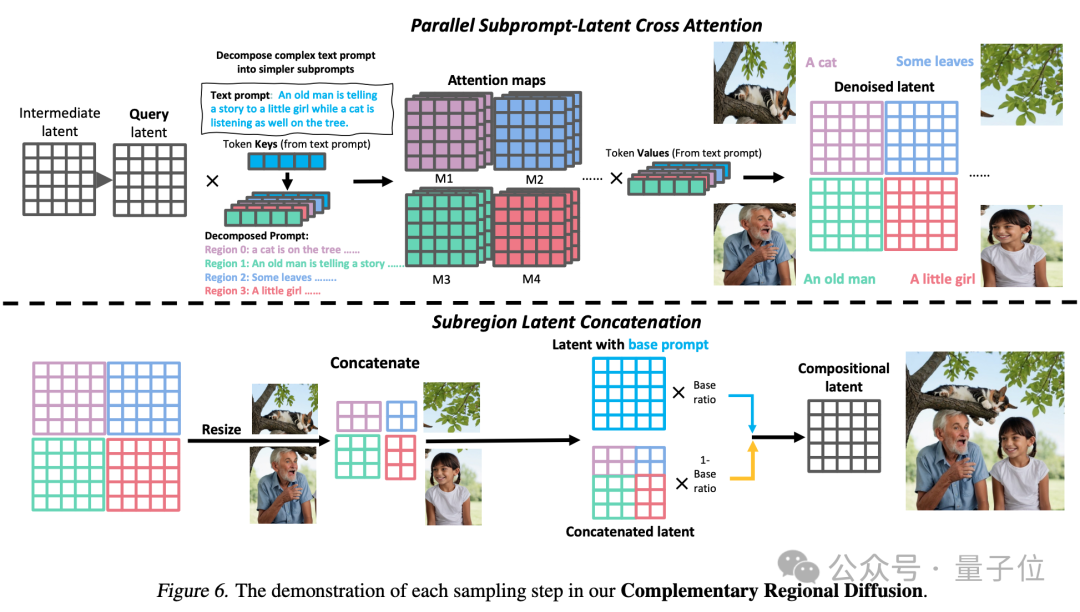
This ultimately results in the generation of an image that better meets the requirements of the prompt words.

The RPG framework can also utilize information such as posture and depth for image generation.
Compared to ControlNet, RPG can further break down input prompt words.
User Input: In a bright room, there is a beautiful black-haired girl wearing a champagne-colored long-sleeved formal dress, with her eyes closed. On the left side of the room, there is an exquisite blue vase with a pink rose in it, and on the right, there are some vibrant white roses.
Basic Prompt: A beautiful girl standing in her bright room.
Region 0: An exquisite blue vase with a pink rose.
Region 1: A beautiful black-haired girl wearing a champagne-colored long-sleeved formal dress with her eyes closed.
Region 2: Some vibrant white roses.

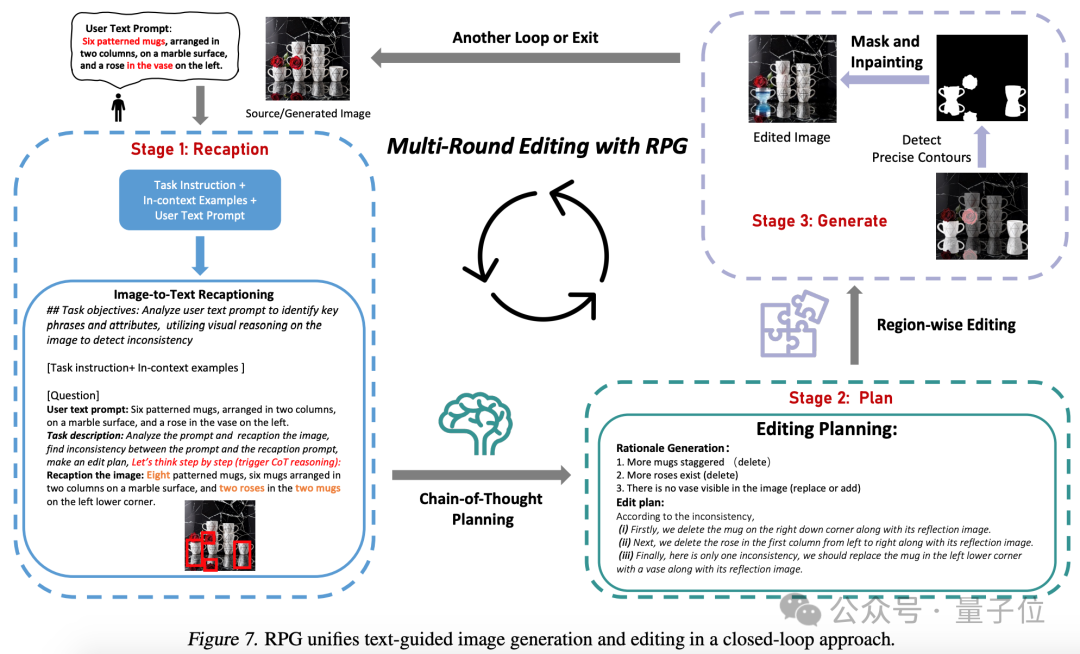
It can also achieve a closed loop of image generation and editing.
Experimental comparisons show that RPG surpasses other image generation models in dimensions such as color, shape, space, and text accuracy.
Research Team
This research was co-authored by Ling Yang and Zhaochen Yu, both from Peking University.
Other participating authors include Chenlin Meng, co-founder and CTO of the AI startup Pika.
She holds a Ph.D. in Computer Science from Stanford University and has rich academic experience in computer vision and 3D vision. She has been involved in the research paper "Denoising Diffusion Implicit Models (DDIM)," which has already been cited over 1700 times. She has also published multiple generative AI-related research papers at top conferences such as ICLR, NeurIPS, CVPR, and ICML, with several selected for oral presentations.
**

**
Professor Cui Bin, the Vice Dean of the School of Computer Science at Peking University, also participated in the research. He is also the director of the Institute of Data Science and Engineering.

In addition, Dr. Minkai Xu from the Stanford AI Lab and Assistant Professor Stefano Ermon from Stanford also participated in this research.
Paper link: https://arxiv.org/abs/2401.11708
Code link: https://github.com/YangLing0818/RPG-DiffusionMaster
Reference link:
https://twitter.com/pika_research/status/1749956060868387101
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。






