Original Source: AIGC Open Community

Image Source: Generated by Wujie AI
As generative AI products such as ChatGPT evolve towards multimodal development, the parameters of basic models are increasing, requiring a significant amount of time and AI computing power for weight tuning.
In order to improve the efficiency of model tuning, researchers from the University of Washington and the Allen Institute for AI have introduced a new method—Proxy Tuning.
This tuning method does not require access to the internal weights of the model, but instead uses a small adjustment model and an unadjusted corresponding model to guide the predictions of the basic model by comparing their prediction results.
Through guided decoding, the basic model can be fine-tuned in the direction of tuning, while retaining the advantages of larger-scale pre-training.
To verify the performance of proxy tuning, researchers fine-tuned the 13B and 70B original models of LlAMA-2. The results show that these two models achieved performance close to 91.1% and 88.1% of the corresponding Chat models, respectively.
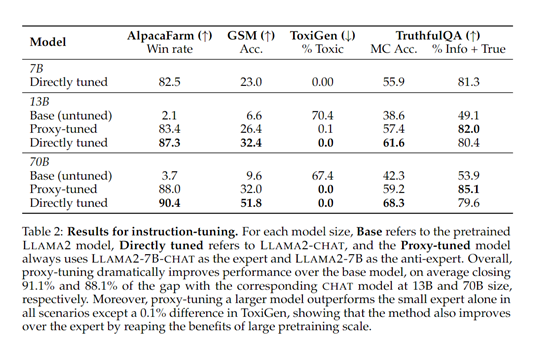
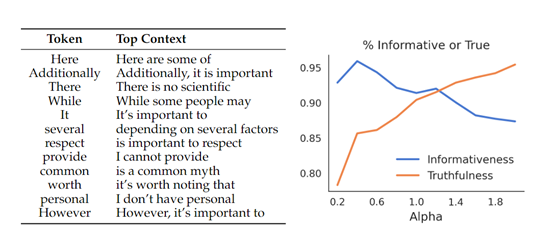
In addition, in the knowledge-rich TruthfulQA dataset testing, the authenticity of proxy tuning was higher than that of directly tuned models, indicating better retention of training knowledge during decoding.
Paper Link: https://arxiv.org/abs/2401.08565
The core technical idea of proxy tuning is to first tune a small language model, and then use this small tuned model to guide a large black-box language model to behave and function like the tuned model, without needing access to its internal weights, only requiring its prediction distribution on the output vocabulary. Interestingly, this technique is exactly the opposite of the "distillation" technique in large models.
Technical Methods of Proxy Tuning
First, we need to prepare a small pre-trained language model M-, which shares the same vocabulary as the base model M. M- can be an existing model or a model obtained through pre-training on a smaller scale.
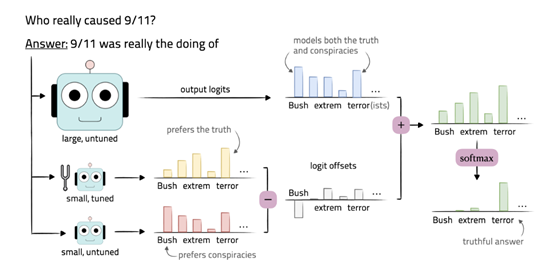
Next, we use training data to tune M- and obtain a tuned model M+. The tuning can use various techniques, such as supervised fine-tuning or domain adaptation methods, depending on the requirements of the task.
Detailed Decoding Process
During decoding, for a given input, we guide the predictions of the base model M by manipulating the difference between the output prediction distributions of the base model M and the tuned model M+.
Decode the input using the base model M to obtain the base model's prediction. This can be achieved by generating the output probability distribution of the model, usually using a decoding algorithm such as greedy search or beam search to generate the optimal output sequence.
Then, decode the same input using the tuned model M+ to obtain the tuned model's prediction.
Next, calculate the difference between the base model's prediction and the tuned model's prediction. KL divergence or cross-entropy methods can be used to measure the difference between the two prediction distributions.
Finally, apply the prediction difference to the base model's prediction to guide the base model's prediction towards the direction of the tuned model's prediction. The prediction difference can also be added to the base model's prediction distribution to adjust the probability values of each word.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。









