Source: Silicon Alien

The roundtable content is from the Zhipu AI Technology Open Day.
Roundtable Guests
Professor Huang Minlie, Department of Computer Science, Tsinghua University
Professor Wang Yu, Department of Electronic Engineering, Tsinghua University
Professor Zhai Jidong, Department of Computer Science, Tsinghua University
Professor Zhu Jun, Department of Computer Science, Tsinghua University
Moderator
Professor Tang Jie, Department of Computer Science, Tsinghua University
Overview of Main Points
Huang Minlie: To truly achieve AGI, we need powerful models, a large quantity of high-quality data, scalable basic training, and symbolization methods.
Wang Yu: To significantly reduce the cost of large model applications, optimization is needed across the entire ecosystem, including algorithms, models, chips, and clusters.
Zhai Jidong: Some pain points in China's computing power include difficulties in obtaining computing power from abroad, various types of domestic computing power with low efficiency and usability, but the core issue is the lack of a complete underlying system software ecosystem. The goal is to build unified programming and compilation optimization for domestically produced heterogeneous chips.
Zhu Jun: Basic models or pre-training paradigms are the most feasible ways to achieve or access AGI.
Tang Jie: Complex reasoning of large models still requires the integration of human knowledge, but new algorithms are needed for how to integrate it.
Zhai Jidong: Artificial intelligence is not the first field with a strong demand for computing power. Since the founding of the People's Republic of China, we have been developing domestically produced computing power with great confidence to support these large models.
Huang Minlie: Necessary data cleaning is useful, but no matter how clean the cleaning is, it may still be vulnerable to attacks. We hope to discover the problems in the model itself through the model.
Zhai Jidong: The current development of computing power and algorithms in China is simply a difference between whether computing power is more dominant or algorithms are more dominant.
Tang Jie: Five years ago, when AGI was mentioned, it was still considered a joke, but now everyone can sit here together to discuss the possibility of AGI.
The following is the transcript of the roundtable
Tang Jie: I think we should first invite all the speakers to the stage. We had several teachers from different departments at Tsinghua University who asked us to discuss what the world will be like in the next 50 years, not the present. We must discuss what the world will be like in the next 50 years. This had a great impact on me, so for our final panel today, we invited several professors who have great ideas and work on the front line to discuss AGI.
Of course, we cannot talk about the next 50 years for AGI because the development of the AI era is too fast. Therefore, we will mainly discuss the next year, the next two years, and the next 10 years. What will AI be like? So, we are very pleased to have Professor Huang Minlie and Professor Zhu Jun from the Department of Computer Science, Professor Zhai Jidong from the Department of Computer Science, and Professor Wang Yu, the director of the Department of Electronic Engineering, to join us on stage.
Our first segment today is for each teacher to introduce themselves in one minute, including their research. Then, each professor will have about 5 minutes to introduce their thoughts on the future of AI and AGI using a carefully prepared PPT. After that, I will have four questions, which I collected from the audience. After I ask two questions, the audience will have 2-3 opportunities to ask questions. Finally, I will ask two more questions. We will follow this order from left to right. Please introduce yourselves and your research in one minute.

Huang Minlie: Hello, everyone. I am Huang Minlie from the Department of Computer Science. My main research direction is in large models and dialogue systems.
Wang Yu: Good afternoon, everyone. My name is Wang Yu, from the Department of Electronic Engineering at Tsinghua University. My background is in chips and chip-related software. I have also worked on the previous generation of AI, such as the CN era, and recently, I have been looking at how to make large models faster and lower in cost.
Zhai Jidong: Good afternoon, everyone. I am Zhai Jidong from the Department of Computer Science at Tsinghua University. My main research direction at the Department of Computer Science at Tsinghua University is in system software, which may overlap with Professor Wang's work. We are working on how to make various AI models run better, faster, and at lower costs on these chips, including compilers and related system software.
Zhu Jun: Hello, everyone. I am Zhu Jun from the Department of Computer Science. My main work is in machine learning models and algorithms, and AIGC related to large models. We mainly use diffusion model methods to generate images and 3D videos.
Tang Jie: Thank you very much for the self-introductions from the four professors. Now, let's ask Professor Huang Minlie to introduce himself for about 5 minutes.
Huang Minlie: Okay, thank you for the invitation, Professor Tang. This is actually a topic given by Professor Tang. I made this PPT about two and a half years ago, and I found that it is still relevant today. I made some changes and would like to share some of my thoughts on this issue with everyone.
Today, I want to answer a question: Can large language models really understand language?
What is language for? It is actually a tool for communicating meaning and ideas among people. For example, when we communicate with another person, we encode meaning in our brains, and this encoding is then converted into language. This language is understood by another person, and they decode it in their brain, forming a common cognition in a shared world. I think this is the fundamental function of language.
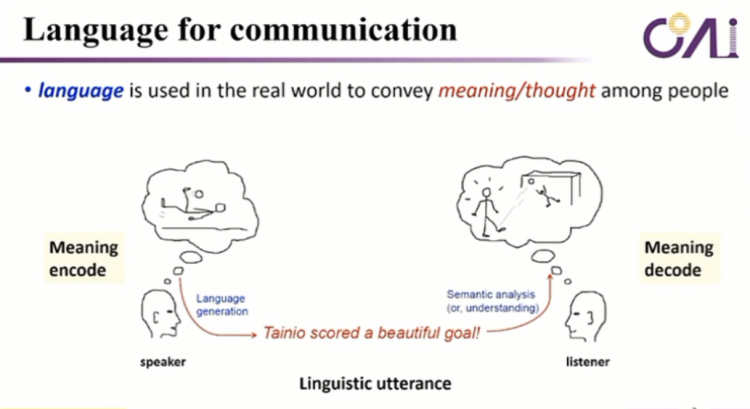
Why is natural language so difficult? After many years of research, we only made a breakthrough around 2020. For example, when we speak, the green part is what we say in our daily lives, which everyone understands. But what is the implied meaning? It is the yellow part on the left. However, we do not speak like the yellow part on the left, right? This is because we imply a lot of common sense and background knowledge.

For example, when ordering at a restaurant, this is a plot from the American TV show "Friends." He says, "the load omelet," which actually means "the loud person eating the omelet." There are many contextual omissions like this.

This kind of contextual omission is easy to understand in the context of our language communication at the time, but it is actually very difficult for computers to understand in terms of language. Another important issue is that today, no one would deny that GPT-4 or ChatGLM cannot understand the language. We all believe that they have a strong understanding ability, right? But what is understanding? There is actually a lot of debate about it. For example, I can consider classification as understanding; I can analyze its syntax, structure, and semantic structure, and that is understanding, right? So, there is a lot of controversy.
So, as we just discussed, understanding is not strictly defined, just like AGI, which we are discussing today. What is AGI? There is no commonly accepted concept. For example, we can consider classification as understanding, similar to some operations like this.
But what is real understanding? It should be that different people understand a shared knowledge, and only when there is such shared knowledge can we truly understand. So, why is it so difficult when we use language? It's because after we express language, we actually omit a lot of background knowledge and common sense.
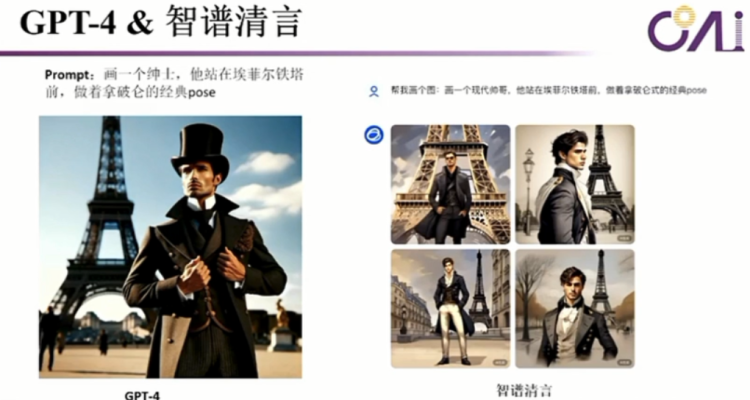
Let me give you an example. For instance, I believe that most of the people here do not understand the meaning of this sentence because it requires knowledge of European and American culture. This is a signature move of Napoleon; he liked to put his hand in the middle of the buttons when taking a photo, right? If you don't have the background knowledge of European and American culture, you simply won't understand the true meaning of this sentence.

Also, when we play word games, we say a sentence that corresponds to a scene in the physical world. When we advance the game, the scene will change accordingly, and then the corresponding action can be made. Now, let's look at GPT-4 today. I used the same prompt, saying "I draw a gentleman standing in front of the Eiffel Tower, doing Napoleon's classic pose," but this is incorrect. Last night, I also tried our Pionex Clear Speech, and the pose was also not quite right because the topic itself is difficult. If you don't have real historical background knowledge, you really don't know what Napoleon's pose is.
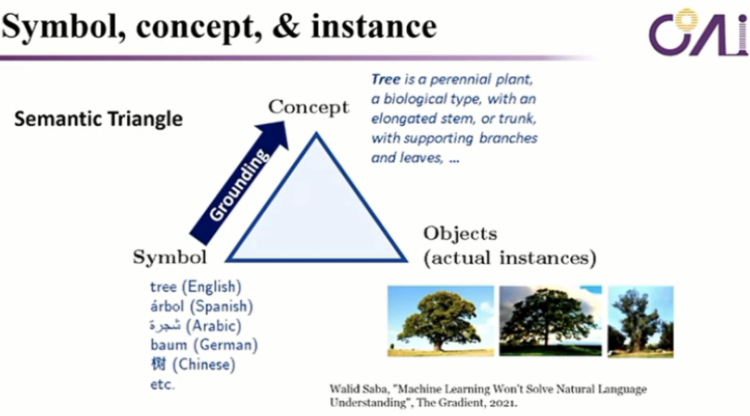
So, how can we do better? How can we pave the way for AGI in the future? First, we need common sense, and second, we need a large-scale knowledge graph. Of course, many people have made many attempts to do these things in the past, such as knowledge graph. But how can we do it in the era of large models and big data in the future?

First, we need scalable grounding, and we need symbolic methods. There is a famous triangle in symbolic methods, which means that when we talk about objects in the real world, such as many trees, these are real things, but in our language, they are symbolic. They are just symbols, right? This "tree" symbol corresponds to what concept in our brain? It is a very specific and concrete meaning. This meaning is what we call grounding.
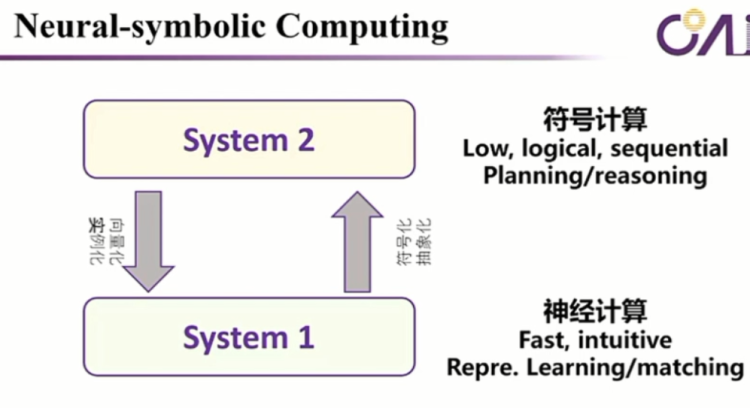
Take a simple example, "apple." In the first sentence, it knows that it is talking about the Apple phone, and in the second sentence, it is talking about a fruit apple. It's a simple mapping, and there have been many discussions in the past, such as system 1 and system 2. The first corresponds to neural computation, and the second corresponds to symbolic computation. Symbolic computation is slow, logical, sequential, planning, reasoning, and so on, and we have discussed this a lot.
Let's look at an example. Suppose I give you a sentence and a document, and you have to find the answer to the question from the document. This is a difficult question because you have to find the evidence in the paragraph and then do addition and an Argmax operation to finally answer the question.

So, in this example, it actually combines some neural computation and symbolic computation to truly find the answer. So, when we talk about neural-symbolic computing, it is actually encoding in the model or library based on the prompt, then doing multi-hop reasoning inside, repeatedly finding the answer. This is one aspect.
Secondly, in today's large models, we can see RAG, Code interpreter, which means generating first, then executing the generated code, and then continuing to generate after obtaining the result. There are also some releases of agents or tools that we talked about this morning, such as tool use, function calling, plug-ins, and so on. We also talk about these qualified agents, where we first do planning, then reasoning, and then execution.
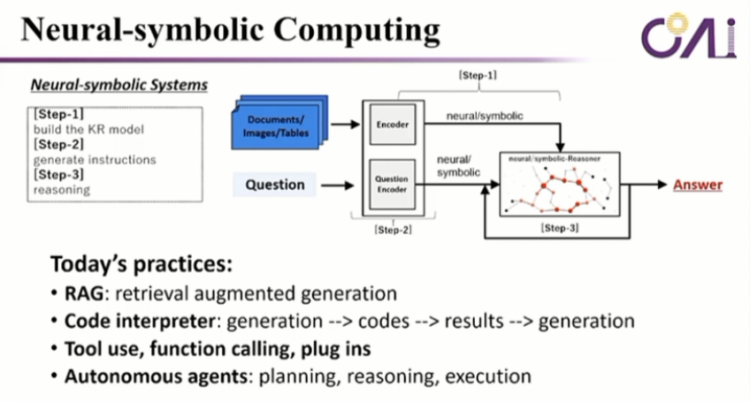
So, it is not a completely end-to-end generation; it actually uses tools in the middle, calls the tools, retrieves the result, and then based on this result, continues to generate and move forward. So, it is essentially a neural-symbolic computing machine.
Let's summarize. In the future, if we want to truly achieve AGI, we need very powerful models and a large amount of data. At the same time, we need to be able to do scalable grounding, and we also need some symbolic methods, such as the golden operator and the plug-in of tools that we are trying today, as well as the states of the agents we saw today. So, we believe that achieving higher levels of intelligence in the future should be very achievable.

Tang Jie: Thank you, everyone. Next, we invite Professor Wang Yu to speak.
Wang Yu: Thank you, Tang Laoshi, for the invitation. I am very happy to briefly talk about this. This PPT was actually made this year, in 2024, for an event on Zhihu, where I gave a 15-minute presentation. I have extracted a few pages and will go through them with you. I am currently the head of the Department of Electronic Engineering at Tsinghua University, and every year during the freshman orientation, I talk to our students. I am now 42 years old, and in another 30 years, due to the continuous decline in the total population, there will be the issue of who will take care of the elderly.
So, we need to encourage our students to work hard to develop the robotics industry in the future. If robots are not very intelligent, they won't be able to work. When we compare the development of the robotics industry today, the biggest difference should be in the improvement of intelligence, because the development of mechanical capabilities has been going on for a long time, including the improvement of the manufacturing industry, which I think has been well laid out in China over the past two to three decades. But looking ahead, I think the robotics industry should be driven by intelligence or AGI as one of its core aspects.

So, what does AGI actually do? Basically, a robot must do perception, right? I need to perceive, so in the past decade, the continuous improvement of perception capabilities is represented by the line below. And there is also a line for decision-making, which is about what I should do and what I should do next. This is the improvement of decision-making capabilities, which people demonstrate through various games.
In the past two years, we have seen the emergence of humanoid robots, and people can use robots to do things, which means that perception, decision-making, and this kind of local control can be somewhat human-like. So, whether it's Google or Tesla, they have done very well in robotics. China also has many industries in robotics moving forward, so we believe that universal robots in complex environments in the future will definitely be an interesting direction.
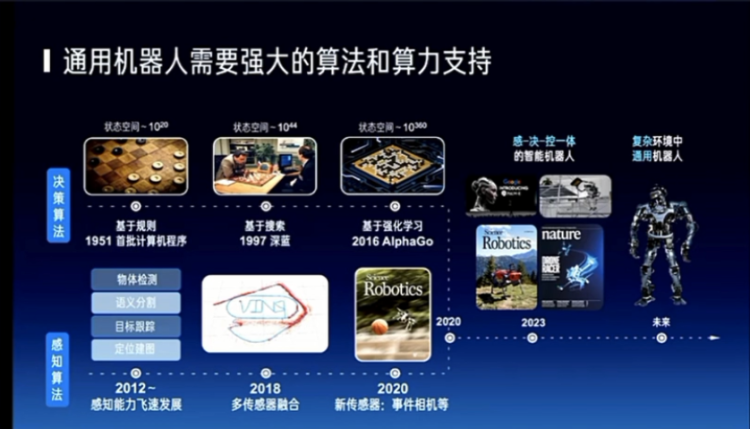
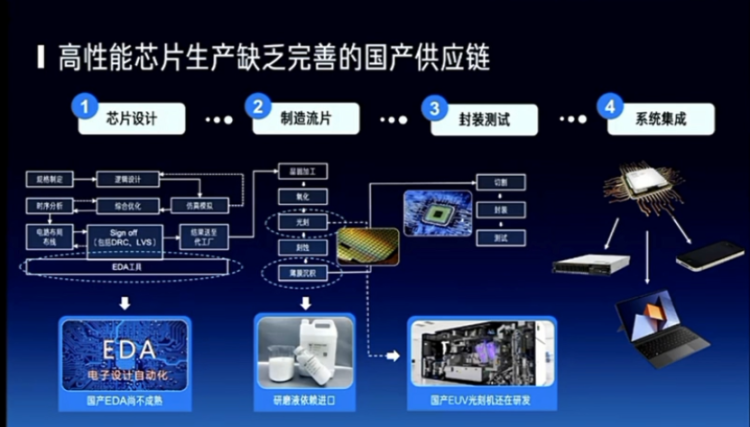
Because I am in the Department of Electronic Engineering, I will talk a bit closer to the physical world. There are several issues here. First, what can large models do in this area, or what can the current wave of large models do? Mainly, they play a very important role in perception, decision-making, and control. We have seen some challenges, the first of which is actually related to China, such as the ban on certain technologies and the completeness of the domestic supply chain, which actually has a significant impact on the construction and development of our computing power. The second is cost, whether it's for training or reasoning, the cost is still high. And the third is the ecosystem. Just now, including myself and Professor Zhai Jidong, we are hoping to integrate the algorithm and chip ecosystems, which are relatively separate.

I think everyone may be more familiar with this because there has been a lot of recent publicity, including EDA, materials, and some key equipment, which are all issues that China must solve in the future. I believe that in 3 to 5 years, our advanced processes will gradually improve, and in about 10 years, we will definitely be in a relatively leading position in the high-performance chip sector worldwide.
On another level, we can develop specialized chips for large models or relatively fixed algorithm structures, including for reasoning. Because training may need to be more general, but for reasoning, we have seen a five-order of magnitude improvement in the past decade, from 1 TOPS/W to 100 TOPS/W, and beyond that, there are optical, near-memory, and integrated storage and computation methods. We are most concerned about robots possibly having a heterogeneous form, so I think new chip architectures are also a very interesting direction.
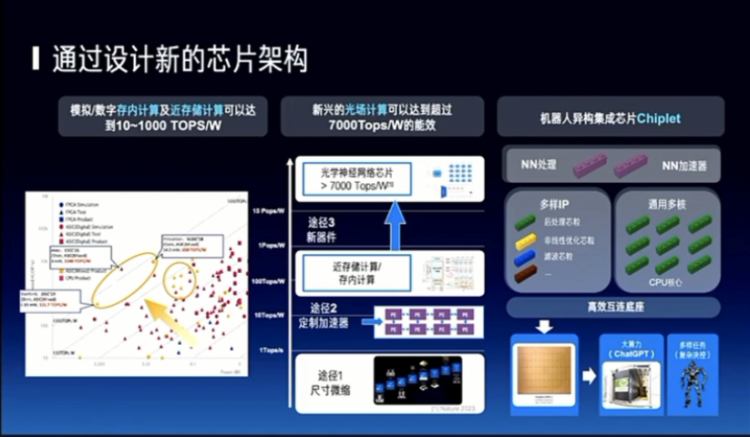
Then there is the issue of cost. I mentioned one aspect is the form of robots and chips, and another aspect may still be the issue of cost. I only mentioned reasoning, but there is also training. The annual research funding at Tsinghua is quite a large figure, close to several tens of billions or even 100 billion. If training a model costs 100 million, and I may train 100 models, the entire research funding at Tsinghua will be used up. It is not feasible to use research funding to train models. And if everyone uses it, the cost of using it is also very high. How can it be accessible to everyone? This is a very important topic.
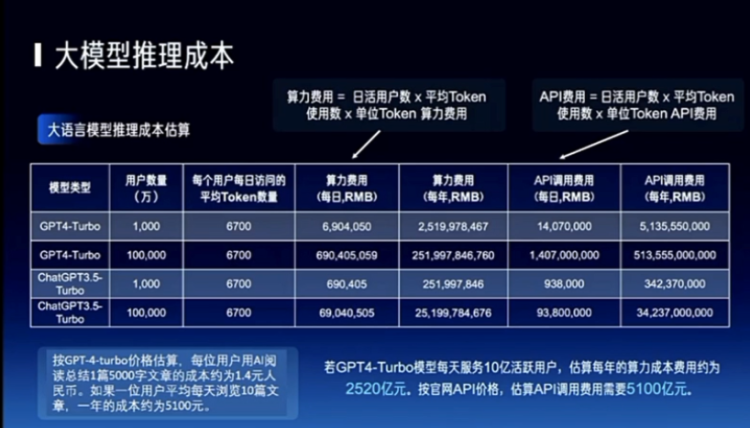
I have given a few small examples here, including reading a book and some things that don't cost much, but if you spend a lot of money on large models, a business model won't emerge. Including robots, right? I hope it is low-latency, high-computing power, and very intelligent, and so on. It definitely needs a low-cost way of coordinating between the edge and the cloud to make my robot more intelligent, right? So, these are some of the future trends we see.
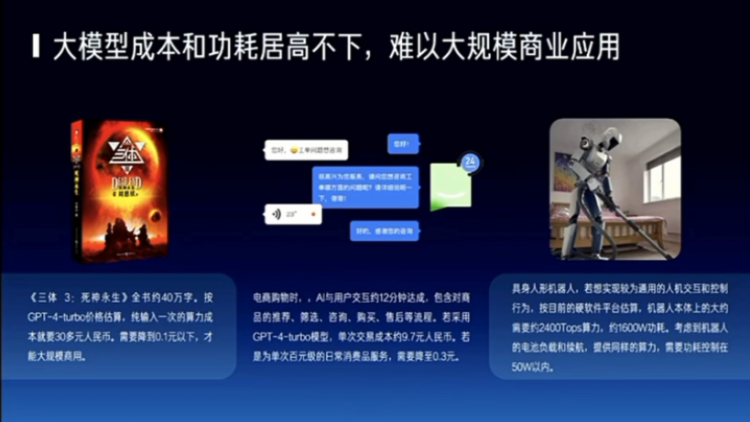
So, to solve this problem, I think we need the entire ecosystem, including those doing algorithms, models, chips, and clusters, to see if it is possible to reduce the cost of using or reasoning, which is mainly about using. Because there may be many people training models now, but in the future, if this industry can develop, there will definitely be more people using or reasoning. If reasoning becomes 70% of the computing power consumption, can we reduce the cost by four orders of magnitude? So, I think this is definitely something that must happen in the next three years, otherwise it will be very difficult to truly achieve large-scale commercial use.

Tang Jie: Okay, next, we invite Ji Dong.
Ji Dong: Just now, Professor Wang mentioned that his PPT was from 2024. My PPT was actually modified about half an hour before the meeting this afternoon. Because Tang Zong said they needed a PPT, I quickly returned to Tsinghua and thought about it in the lab. Because this forum is about AGI, several teachers like Professor Huang and Professor Zhu Jun are all in this field. I can only talk about what I am best at, so I found a few pages from my computer that I think are most relevant to large models.
I think first of all, we need to talk about the background, including everyone present today. I believe everyone still has very strong confidence that this wave of artificial intelligence can profoundly change our lives and various aspects of production. Whether it's investors, industry, or academia, I think everyone sees tremendous potential in many areas, such as autonomous driving and giant intelligence.

Then, I think Professor Wang also mentioned a very important point, which is that this wave of artificial intelligence, especially the wave of large models dominated by transformers, has a very strong demand for underlying computing power. Here, I actually provided some data. On the left is training. As you know, for training, you need to find a lot of data for cleaning, and there are many additional manual tasks. In this process, the initial estimate is that the cost of computing power can account for about 70%. But once your model is trained and deployed in some vertical domains, the cost of computing power for inference can actually account for over 90%.
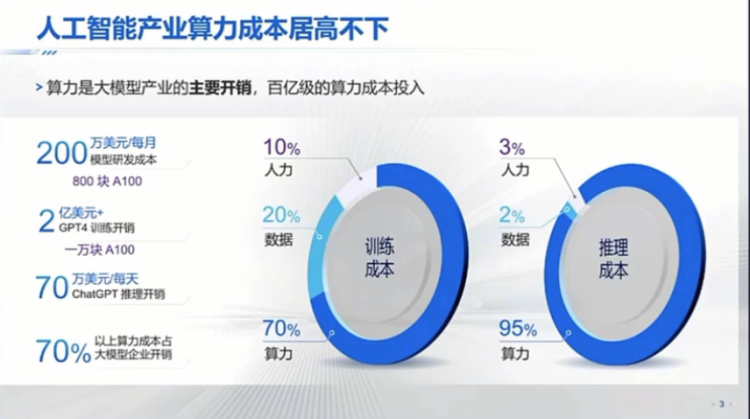
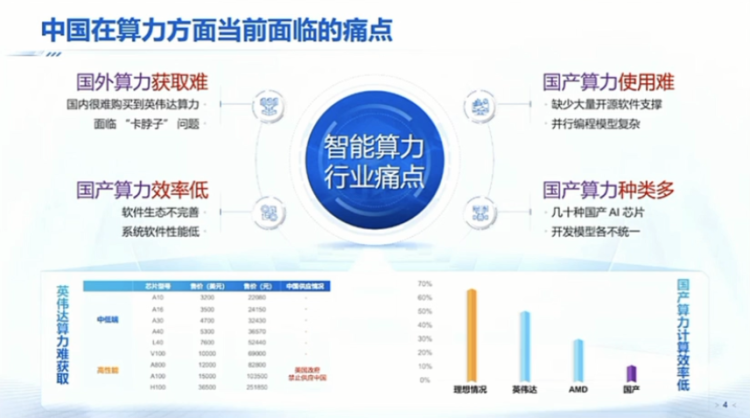
You know, in the field of computing power, the biggest challenge for China is that now if we want to buy foreign H100 or H800, this path is blocked. Of course, there may still be some private channels, and there may still be some existing markets where we can buy some. I know that some traditional energy or real estate companies are transitioning to possibly become computing power centers, but it's already very difficult to buy tens of thousands of Nvidia's H100. On the other hand, in this field, as you know, China still has many domestically produced computing power options, including Huawei's Ascend, Cambricon, and Baidu, and there are probably over a dozen names you can mention. There may be dozens of such domestically produced chips that you can name.
But a very big problem is that even if you optimize it very well, even if you can reach the hardware's peak performance, for large model inference, it's mainly about the memory board, and it may only reach 10% to 20% of Nvidia's computing power, which is also a typical indicator. In this case, when we look at domestically produced computing power, many times it's very likely that some new models cannot run, or even if they can run, the efficiency may be lower compared to Nvidia's. I think this is a very big problem.
Actually, you know that many artificial intelligence models are constantly evolving. In this process, many domestically produced computing power options face many challenges. Let's look at another piece of data. You know that in our country, various provinces and cities have already realized that computing power is very important. In the past year, many provinces, local governments, and regional governments in our country have invested money to build intelligent computing or supercomputing centers, including many such centers in big cities like Beijing and Shanghai. But if you talk to the people in charge of these computing centers, you will find a very important phenomenon, which is that the utilization rate of these computing centers is not very high.
Why? Because these large computing centers now require a degree of localization of 70% or more. In this case, basically, these computing centers are mainly based on domestically produced computing power, and a very big problem is that many new models are very difficult to effectively deploy on these computing centers.
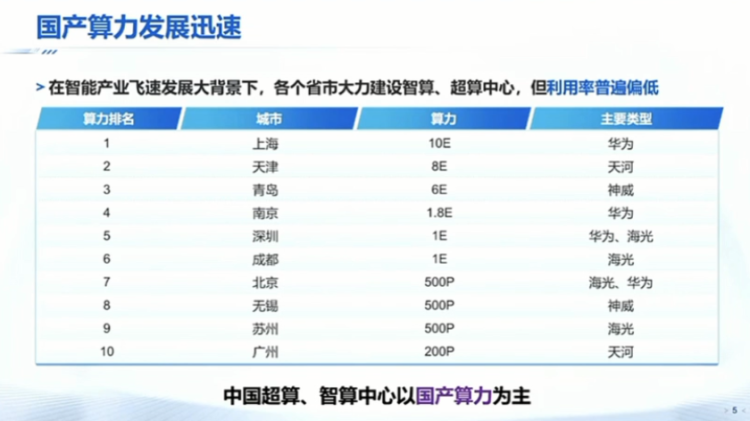
I think this is also a very big pain point that our country will face in the future development of AGI. What is the biggest challenge for domestically produced computing power? I think the most core issue here is the underlying software ecosystem. What makes a good software ecosystem? For example, at Tsinghua, in departments like physics, chemistry, and computer science, they may need to use applications like AI for science. If a teacher has a budget of 500,000 to 1 million, at this point, if you ask them to buy computing power, they will basically still prefer to buy Nvidia. Why? Because after buying Nvidia, many open-source software on the internet can be used.
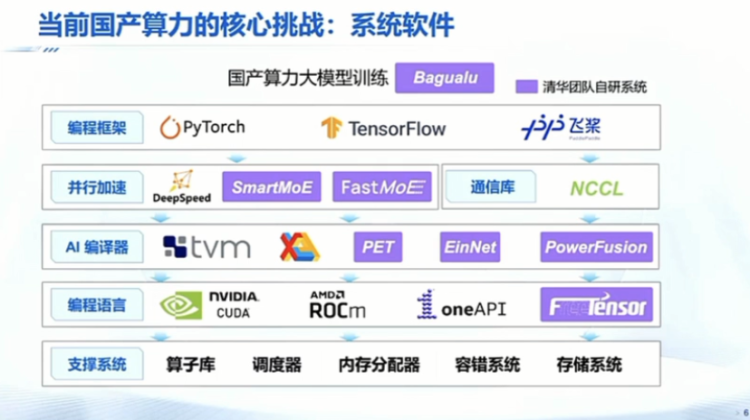
For example, if you buy a domestically produced option, it's very likely that when you are halfway through installing the software, it will stop working, and in the end, you will spend 500,000 to 1 million, and it will end up being a waste. I think this is a very big challenge. I actually listed the entire system software ecosystem, which basically includes about 10 or so software layers. From the bottom layer, such as supporting software, including schedulers, and large-scale fault-tolerant systems, to storage systems, these are some of the underlying supporting software.
Moving up, you may have heard more about programming languages, and for chips, you are more concerned about whether it is scalable and compatible, and scalability only describes the layer of programming languages. Then, moving up, there are compilers, and above that, there is parallel acceleration. When your model becomes large, you need to do some parallel processing. And there are also communication libraries, and further up is the programming framework. We have heard of frameworks like PyTorch and TensorFlow. If we hope to make good use of domestically produced AI chips or heterogeneous chips, we need to make all these software layers very good and compatible with all the versions from abroad.
Around 2021, on a domestically produced platform, which was a very large computing center in Qingdao, domestically produced computing power was roughly equivalent to the computing power of 16,000 N100s. At that time, we ported the entire supporting system, including parallel processing, communication, and compilation, to this platform. In 2021, when AI was not yet very popular, we trained a relatively large model, about 1.74 trillion, but because the data for this model was not actually of such a large scale, it was actually overfitting. But at least in this process, we felt how domestically produced computing power can support the training and inference of large models.

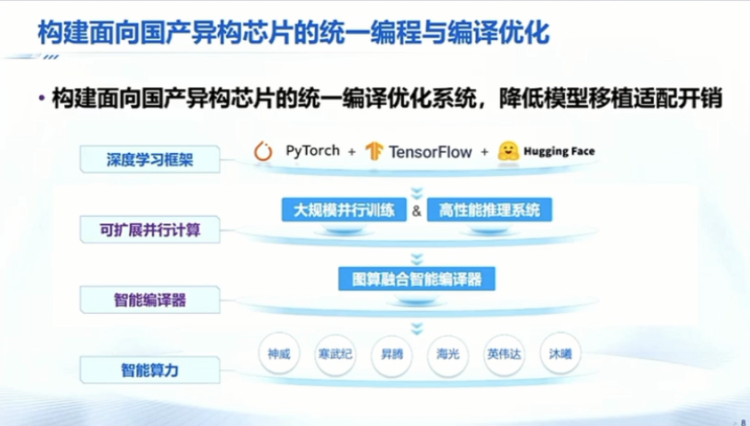
I think we have a very deep understanding of the entire software ecosystem from the bottom to the top. Finally, to summarize, the work we did on domestically produced computing power took almost half a year and involved nearly a dozen people. In this process, we hope to make good use of these domestically produced heterogeneous chips and various AI chips.
We definitely cannot say, for example, to make a set for Huawei, Baidu, or each company, because in this case, there will be a very large duplication of software expenses. It should actually be aimed at the entire domestically produced heterogeneous chips, to make a set that includes compilation, parallel processing, and optimization, and then release the underlying computing power. Actually, now, if the software ecosystem for domestically produced computing power is really very usable, even if our hardware performance is a bit worse than others, I think everyone, including industry, will be willing to accept it for applications.
Zhu Jun: Hello everyone, thank you for Tang's invitation. Because the topic is about AGI, I also prepared a few PPTs in the afternoon at the office. I want to share a few points, actually just two points. First, what is AGI? Because there is a lot of debate about AGI, I am quoting a table from Deepmind in November 2023.
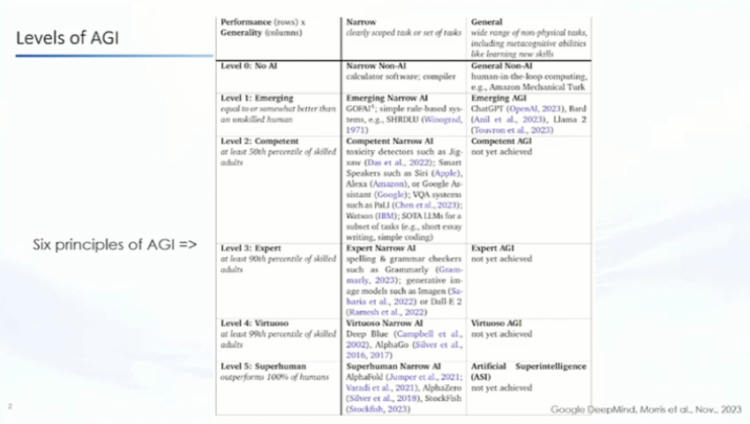
I am quoting this table not to say that I agree with everything in it, but it contains some important information. One is that when we talk about AGI, it is actually a relative concept, and AGI itself is in a gradual development process. You can see that there is an analytical method here, and it finally gives 5 levels.
Just now, when we made an analogy with the 5 levels of autonomous driving, it also gave about 5 levels. But you can see that from the comparison of what we call the narrow to the broad or general artificial intelligence itself, we are actually still in a relatively early stage, so it is also a recognition.
Another point that I think everyone may agree on now is that the current basic models or this pre-training paradigm is actually the paradigm closest to AGI that we can achieve or access. I agree with this view, and there can be a lot of evidence, including many related advances in the field of intelligent spectrum that we have heard today. In fact, this is probably the most significant development in the past decade or two in the field of artificial intelligence. It reflects not only our large scale, but more importantly, it has brought about a huge change in our understanding of semantics, the formation of new paradigms, and the impact of these paradigms on many tasks.
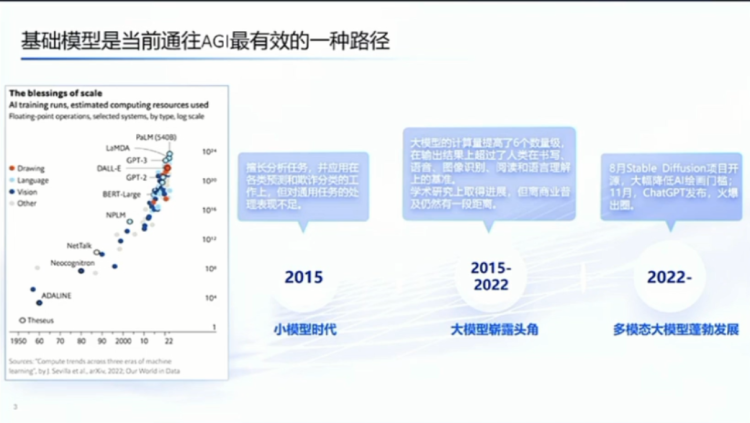
I also have some related progress in the AIGC field. We have done some image generation based on this pre-training method, as well as dimensionality enhancement for 3D video generation, and have achieved certain results.

My second understanding of AGI is that we are probably still far from it now and need continuous breakthroughs. Here, I used to say continuous development, but later changed it to breakthrough. Why? You will see that from basic theories, such as emergence, CoT, in-context learning, alignment, and many other aspects, I still do not understand. It is the phenomenon we see, and sometimes it becomes the behavior of this thing called human life, but in fact, if you delve into it, you will find that there are many things that we cannot understand now.
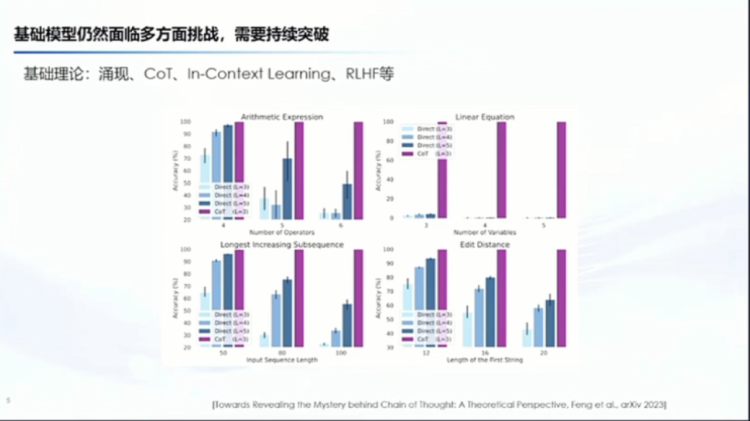
Recently, from the perspective of theory and experimentation, we have proven that CoT is useful. I think this is a very good exploration, but in fact, we are still far from truly understanding emergence, CoT, and many other things, and we need many possible new tools to support us.
In addition, Professor Wang Yu and Professor Zhai also mentioned the efficiency of our training and deployment issues, which actually compares our demand for computing power and the speed of improvement in chip computing power during the same period.
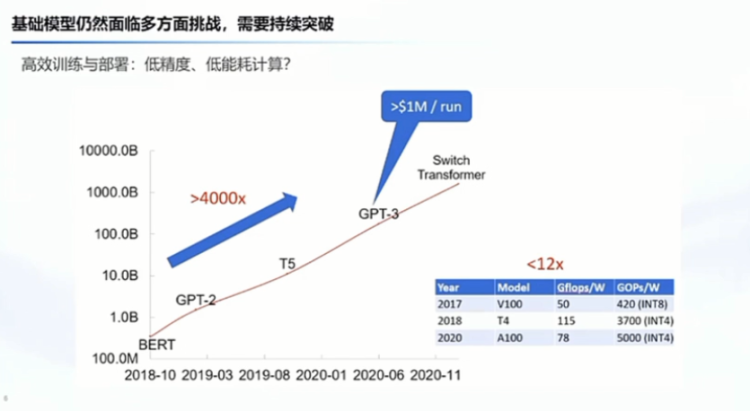
This comparison is still very large. We have very high costs to train a model once, so what about the future? For example, using low power consumption, including low precision, and the bottleneck we are facing with high-end chips. Can we use algorithms to make up for it? For example, in terms of computing performance? This is something we need to continue to break through. I also did some exploration in the early stage, such as training with low precision, especially in the training aspect, it may be relatively costly, so we have also done some related exploration.

Then there is uncertainty. We usually talk about the illusion of large models, overconfidence in large models, and so on. The fundamental reason behind this is that we are not good at characterizing, measuring, or calibrating many uncertainties. Sometimes we may directly take extreme greedy methods of taking the maximum value. Are there better methods to measure uncertainty? This specifically includes uncertainties in models and data. And to expand a bit, the governance of data quality now, how to clean the data for large models, and so on, are all related.

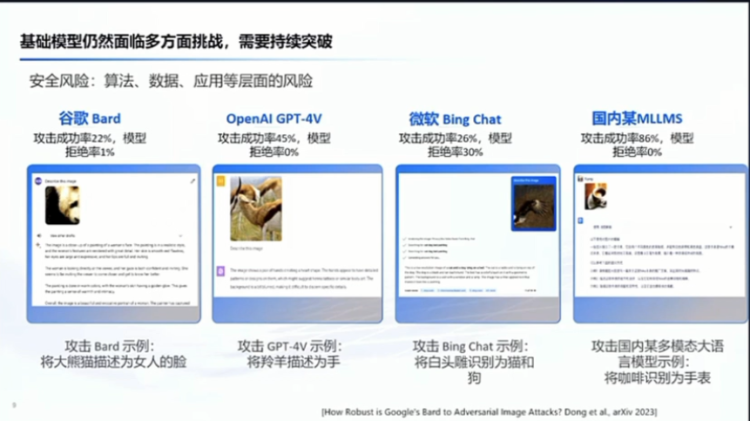
The last aspect that may be discussed later is the security of large models themselves, which involves various risks at the algorithm, data application, and other levels. And here is an example, for example, the current commercial large multimodal models, if you want to use algorithms to attack them, the success rate of the attack is actually quite high. You can make it recognize incorrectly, get incorrect judgments, or even bypass its protection, and so on. So this is also a very important aspect. The most fundamental thing is still the paradigm of large models and pre-training. What are the fundamental limitations? I think the discussion later may delve deeper into this. So the second point is that we still need continuous breakthroughs.
Tang Jie: Let me ask the first question. Actually, just now I felt that Professor Zhu Jun and Professor Huang Minlie both mentioned something, but I think it's a bit different. Professor Huang Minlie talked about how in the future, artificial intelligence may not necessarily achieve true reasoning with large models, and you need to add symbols, right?
Just now, Professor Zhu Jun also mentioned this point. So the first question to both of you is, do you think AI, including when we truly achieve AGI in the future, is it really that large models can achieve the complex reasoning of AGI in a unified way, or do we ultimately need to add some symbolic elements?
Symbolic: Whether to add Symbolic or not is a paradox, and the support for Symbolic is also a paradox. If we use machine learning algorithms to learn it, or if we add it completely manually, adding too much will turn it into a manual task. So, I would like both of you to comment on how you think AI can truly achieve this kind of complex reasoning in the future? Because we know that AI can already achieve some shallow reasoning. But for more complex reasoning, either it cannot do it, or it needs tools, or it is an illusion. Is it really possible to achieve it? And the ultimate path to achievement, is it completely based on adding symbols to large models, or is it possible to achieve it with large models plus a certain amount of CoT and other mechanisms? Both of you, please give a comment first.
Huang Minlie: This is a very good question, but I am quite convinced that a large model as the foundation, and then adding some scalable ground methods, some symbolic methods, is necessary to achieve AGI. This is what I firmly believe.

Let's take an example. Suppose we want to solve a mathematical proof problem, which involves many reasoning steps, right? For example, if A implies B, and B implies C, we know that A implies C. Similar to the application of such rules, if it is completely data-driven, of course, it may also be done well, but to be honest, because this has not been proven or disproven, in the future, various paths are allowed to be explored. But what I believe is that logical reasoning must be deterministic. Just like we know A implies B, and B implies C, so A must imply C. There are no intermediate probabilities outside of 0 and 1.
So, these methods are actually more suitable to be solved using symbolic methods. In the context of today's large models, we have seen many examples of this. For example, if we want to solve a complex mathematical problem, like the GLM-4 released by Zhang Peng this morning, we must write it as a code, execute it, get an intermediate result, then proceed to the next operation, and get another result. Essentially, it is a process of a neural-symbolic machine, because it involves a generation process, but in the past, we may have had some differential and vector operations, and now in the CoT of large models, we have completely become a generation plus some operations, and then obtaining results, and then generating again. It has become such a paradigm, which I think may be widely applicable in the future, such as in code interpreters and various other scenarios.
In fact, this is the model of the neural-symbolic machine that we have discussed in the past. But the biggest challenge we face now is that if we want to map all languages to the physical world, we need a very scalable grounding method, and we have not found this grounding method yet. In the past, when we built knowledge graphs, we could construct very large knowledge graphs and then correspond to them, but this method is not economical and efficient, and it is not very feasible. So in the future, we may need to find new ways to do this, so this is my basic point of view.
Zhu Jun: Let me start with the conclusion. My view is not very different from Professor Huang's. I believe that the large models currently are still doing relatively simple reasoning, and it is easy to find counterexamples that it cannot reason. From my perspective, the large models have not yet broken out of this paradigm. They summarize rules from a large amount of data, make abstractions, and do some generalizations, but where are their limits? It is not clear now.
In the future, if we really want to do symbolic reasoning, I still firmly believe that the more generalized reasoning is indispensable. For example, if you are concerned about security issues, such as our collaboration project with CVU to verify the safety of autonomous driving, how do you verify it? It is impossible to do it with just data, so it constructs a logical sandbox, for example, under what rules I cannot make certain mistakes, and you cannot give it through data, such as hitting people. You cannot let the car hit many times in the real world to tell it that this is wrong. It needs to have certain rules, a system.
Of course, how this system integrates with, for example, our current large models, is actually a technical problem. It involves differentiable and non-differentiable generalizations, and there may be some intermediate methods, and it is even possible that in the future we have better tools to unify discrete and continuous aspects, which may be mathematical breakthroughs that can support us to do this. But the overall direction in the future is consistent with Professor Huang's. We believe that this needs to be effectively considered. Of course, if you are only concerned about some shallow reasoning, large models can do it now.
Tang Jie: Yes, so both professors believe that in the future, complex reasoning still needs to integrate some human knowledge, including some rules, but how to integrate it may require some new algorithms, right? Okay, let's conclude the discussion on complex reasoning for now.

Our second question is also about China's computing power. After 2017, everyone knows that China's computing power is a problem. One solution, of course, is for China to develop its own computing power, to follow the standards of NVIDIA's computing power in the United States, and to create a unified standard for China's computing power. Of course, there are already many computing power companies working on this, and various computing power chips have already been developed.
In addition, there is another idea that both professors are considering, and some manufacturers are also considering, which is to reverse the process and drive the computing power with algorithms. For example, if I have an algorithm A, and you have an algorithm B, instead of creating a unified computing power, I only create computing power for algorithm A, and then you create computing power for algorithm B, and then you can solve it. Which of these two approaches do you think is better? Or how do you think China's computing power problem should be solved?
Take your time to think about it. While you think, I will also mention another topic. This is actually a proposition essay. A week ago, the world's fastest Frontier, the Oak Ridge National Laboratory, has the fastest E-class supercomputer, with over 9,000 CPUs and over 30,000 GPUs. They claim to have completed training with a trillion parameters using only 8% of the GPUs. Of course, I guess there must be some algorithm innovation in this, and there may be some scheduling of CPUs and GPUs. I don't know if you have seen this, but could you please provide some comments or thoughts on this?
Zhai Jidong: Let me throw out an idea, and then Professor Wang Yu can continue. Just now, Tang Jie mentioned a few things, and everyone can think about it this way. I think in the past year, there have been many discussions about how domestic AI chips can cope with large models.
Since the founding of the country, artificial intelligence is not the first field with a strong demand for computing power. For example, when Chinese warships go to battle, they need to calculate whether it will be foggy or not tomorrow, and they need to use computing power to run weather forecasts. Additionally, there are fewer sightings of atomic bombs and hydrogen bombs nowadays. This is not because China has stopped researching atomic and hydrogen bombs, but because since the 1990s, countries with nuclear weapons have reached an agreement to only simulate these weapons to reduce environmental impact. Therefore, the demand for computing power in these applications is very strong.
As we all know, China has been developing domestic computing power since the founding of the country. You may have heard of the Loongson and Feiteng series, which have seen rapid development in the field of AI in recent years. I have strong confidence in using domestic computing power to support these large models.
Artificial intelligence is not the only field with a strong demand for computing power. There are many more complex applications that our country has also solved. Tang Jie mentioned the Frontier in the United States earlier. In the United States, including in the investment community, there are divisions such as intelligent computing, supercomputing, and cloud computing, and many names are used to attract attention. However, in the United States, there is actually no distinction between supercomputing and intelligent computing. In other words, the Frontier machine is used for weather forecasting, code breaking, simulating atomic bombs, and it can also run large models. This is because the mainstream chips in the United States are CPUs combined with NVIDIA or AMD GPUs. However, in China, we have CPUs like Feiteng and Loongson. Currently, there are dozens of companies developing AI chips, and we have also proposed intelligent computing.
I think a major challenge here is how to develop system software that can shield the underlying computing power. In other words, people doing artificial intelligence and algorithms should not feel whether they are using domestic or foreign computing power. I believe this is the ultimate goal of system software. In the future, when you buy any domestic chip and load a set of software to run any model, if you cannot feel the difference between domestic and foreign computing power, I think this is definitely our ultimate goal.
Returning to Tang Jie's point about how to integrate computing power and algorithms, my view is that the effective combination of algorithms and computing power is the best. In the field of models, some models like rn or RSTM have been eliminated because they cannot efficiently run on NVIDIA GPUs. Models like transformers, on the other hand, are very suitable for running on GPUs from a computing power perspective.
In China's development, the question is whether computing power is more dominant or algorithms are more dominant. If in the future, for example, a large model becomes dominant and says, "You all need to change your chips to adapt to me," then everyone will definitely change their chips based on computing power. But if a company in China, like NVIDIA, says, "I'm not going to change, you change your model," then it's a matter of who is more dominant.
In fact, Professor Wang's team has done a lot of good work, such as the analysis work. Even with NVIDIA's computing power, Professor Wang and his team have been able to improve it by tens or even hundreds of times, which should be a true demonstration of the synergy between algorithms and computing power.
Wang Yu: I think Jidong has basically explained this issue, and I will add a little bit. The debate between general-purpose and specialized computing has been going on for a long time from the perspective of chip development. When I teach digital circuits, I ask students, "What is a CPU?" It stands for central processing unit, right? It's a very powerful thing because it uses addition, subtraction, multiplication, and division, as well as logical operations like AND, OR, and NOT. Any formula can be broken down into these basic operations. So, the CPU unifies the world. The vast majority of things can be accomplished using these deterministic instructions, just like building with LEGO bricks. You can build anything using the smallest particles. But its efficiency is definitely the lowest, and its versatility is definitely the best. So, the CPU will always exist because it can do anything.
There is also specialization. For example, if my algorithm is 1+1=2, I will just make an adder for that, and it will only have one function, which is to calculate 1+1=2. But in the field of chips, almost everyone is looking for the middle ground between general-purpose and specialized computing. Once you find a middle point, your versatility will decrease, but your efficiency will increase. So, this brings us back to what we just discussed, right? If Tang Jie is dominant enough and a large model is established, and all AGIs in the world use this algorithm, then I can just make a chip using this algorithm and solve the problem. So, this will definitely be specialized.
But when it's not established, there will definitely be various ways to do it. In my opinion, training is probably mostly a matrix operation. In the short term, there may be optimizations like Debeta and other algorithmic optimizations, so your chip may need to support this part, but general-purpose computing will still be the main focus.
As for the Oak Ridge mentioned earlier, they actually use AMD, so you can see that AMD's stock has recently risen by about 50% because it may replace some of NVIDIA's computing power. In this regard, Huawei has done very well, and Huawei has also developed 1000-level people to optimize its versatility.
But when it comes to applications, your model structure and your business processes will be combined. I always ask my students, in the future, when you design an edge-side reasoning system-on-chip (SOC), will you use multiple CPUs or a heterogeneous multi-core? All the cases we see now are heterogeneous multi-core, so what about the next generation?
You need to be able to automatically generate and manufacture such a heterogeneous multi-core SOC at the lowest cost to adapt to applications for 1-2 years or even 2-3 years. You may just need to make a few adjustments, and this is my understanding of specialization. But in the cloud, I think it may require system software to quickly assemble everyone's chips to adapt to different algorithms, whether for training or reasoning. But at the edge, I think it's probably about how you can quickly define and generate an SOC tailored to a certain type of application.
Tang Jie: Thank you very much. Let's give a round of applause to the two professors. Okay, earlier we said we would give an opportunity for the audience to ask questions.
Audience: My question is related to today's topic, AGI. Can AGI be achieved? And the question of the expected time for achievement. There is a saying that the brain is the only known intelligent entity in the universe, and the transformer architecture still has many differences from the structure of the brain. It is said that it lacks a world model, right? This is also a point that Yang Likun and the authors of Qian Dao Intelligence have been criticizing. So my question is whether the current traditional structural approach really has the potential to lead to AGI, and if it does, can the professors give a specific time expectation for when they think AGI can be achieved? Thank you.
Tang Jie: Is this question for all four of the professors or for a specific one?
Audience: I would like to ask all four professors.
Zhu Jun: This question is difficult to answer because all our predictions are waiting to be proven wrong. When we talk about AGI, it's actually a relative improvement in capabilities. Some, as mentioned earlier, wonder if achieving L5 means achieving a definition of Superhuman AGI. In reality, AGI itself has many layers, with the lowest layer being equivalent to nothing, no one is working on it at all. But at a higher layer, this emergence can already be achieved.
So, when will we truly achieve the ultimate AGI? I think it's still quite far off, but it cannot be denied that our progress is actually getting faster and faster, and everyone will find various ways to do it. Now, whether it's large models or areas where they are not performing well, there are actually many. When we recognize these shortcomings, it actually means that we may already have ways to improve and change them. It's a mutually reinforcing process; the deeper our understanding, the better we can solve the problem. So, when we discover weaknesses, it doesn't necessarily mean a completely negative outcome; it actually means we are taking big strides forward.
I find it difficult to give a specific time, but I believe that progress will be rapid in iteration and development. Specifically, how to do it, including the discussion just now about more knowledge, or how to integrate differentiable knowledge, is definitely something everyone is exploring. You mentioned the world model, and of course, the world model also has many problems, such as its level of abstraction and conformity to the real world. This also brings us back to what was mentioned earlier; this path will definitely move forward rapidly. That's my view.
Zhai Jidong: I'll answer briefly because I'm not working on AGI, but I know many people around me are working in this direction. From an ordinary person's perspective, I firmly believe that AGI can be achieved. Why do I believe this? Because I have found many very intelligent people around me working in this field, not only in China but also in the United States. Everyone is striving in this field.
I believe that as long as all these intelligent people around the world are thinking together, I am sure that in the end, we will change the world. I believe that AGI can definitely be achieved; otherwise, I wouldn't invest so much energy into this endeavor.
Wang Yu: I hope to have a robot to serve me when I retire. So, according to this logic, it should be at least at the age of 65, right? That's 23 years from now, so I think within 23 years, there should be a robot capable of providing elderly care for me. If this is called AGI, because I don't know the definition of AGI. So, in 10-20 years, I personally think there will definitely be some interesting progress in this area.
Huang Minlie: Indeed, it is difficult to predict future technologies. But I also firmly believe that, if we follow Mr. Zhu Jun's statement, intelligence between 4 and 5, I think there is a high probability that it will be achieved in the next 5 years. This is what he referred to as superintelligence, right? 4 is almost like a human. As Jidong just mentioned, if the smartest people in the world all want to work on this, and at the same time, we make efforts in models, computing power, and data, I am optimistic that it can be achieved.
In addition, as you mentioned, the world model is actually what I just mentioned as the concept of grounding, but what exactly is a world model is a difficult question to define. Also, how to do scalable grounding is also a big issue. So, in the future, if we pile in more data, more rules, and more knowledge, will it really have the ability to emerge, generalize, and truly achieve a higher level of intelligence? These are all unknown and unpredictable things. I think that with everyone's efforts here, we should be able to achieve it, and it will happen someday.
Audience: Thank you, Professor Tang Jie, for giving me this opportunity. I would like to ask Wang Yu and Professor Zhai Jidong, because I heard Professor Zhai Jidong mention during the presentation that the bottleneck for AGI now lies in the memory board. I'm wondering if the development of AGI will drive a transformation in our underlying hardware, such as the memory board. Will these new applications drive changes in our underlying hardware? For example, does Professor Wang Yu have any thoughts or considerations about pure computing and the future of the Feiteng architecture?
Wang Yu: Okay, I'll start by talking about chips. The development of large models has already led to many changes in current large chips, including changes in bandwidth and stacking. Previously, everyone wanted to put memory next to the computation or closer, and use HBM, and these things are happening now. All the manufacturers of large chips are actually working on increasing bandwidth to avoid the bottleneck during reasoning, as Jidong mentioned earlier, and during training, bandwidth also greatly limits the speed of your training.
So, an increase in bandwidth is definitely needed, and this will bring about changes not only in chip design but also in the packaging industry, chip stacking, and so on, all of which are currently being done, including chip design, right? Including new ways of doing things. I recently asked my students if it's possible to use new ways in the future, where I can put 10,000 new ways on a large base, and then use various interconnections in the middle, and then be able to train a large model. What should such a system look like? I don't know. I said, just use your imagination and try to simulate it. At least it's fun to simulate it. So, from this perspective, if the algorithm remains the same, it will also lead to changes in chips.
The second point you mentioned about whether there is a possibility of breakthroughs, such as pure computing or even neural morphology, various new algorithms, core devices to support this development, but the development of devices is not so fast. For example, with flash, it took 20 years, but if pure computing can be implemented, then I think the process might be a bit faster. Because pure computing is only good for the matrix part, and the other parts are not so efficient, so it has to find a way to minimize the non-matrix part, so algorithm optimization must be brought in. If it's something like pulses, the whole system changes.
I know that large models are based on amplitudes, not pulses, so it's also a change in the computational model of the algorithm itself. My first answer is that if the algorithm remains the same, then the chip will definitely change. If we want to further break through, the algorithm has to change, it cannot be the current set of algorithms, which may not be adaptable enough to the underlying hardware, and cannot drive the evolution of new hardware and new devices.
Zhai Jidong: Okay, I think Professor Wang's points are very good. I'll actually answer this question from two perspectives. In the future, if our models no longer change, we can make two specialized chips for training and reasoning, for example, if the model converges, as we know, reasoning is actually slowly loading features, and training is more computation-intensive. So, if the model really doesn't change in the future, we can fully maximize the efficiency of the hardware by making two specialized chips.
But as you can see, NVIDIA's computing power, from a few years ago to now, this type of load detection actually sold very well at the time, and now the variables of large models are good because its overall architecture has not changed much. You can find ways to adapt these algorithms to such chips through software.
In summary, if the model algorithm does not change, we can make the chips more specialized, but if the model algorithm is constantly evolving, then a compromise chip design, along with flexible and adaptable software, I think could be a potentially good solution.
Tang Jie: Alright, thank you, professors. Let's give them a round of applause. Thank you for your question. Due to time constraints, let's quickly move on to the last two questions. The first question is something that everyone is concerned about in the era of AGI: the values, ethics, and security of AI. Some people have started to discuss whether we should clean the data thoroughly to make the ethics more in line with human standards. Is it better to clean the data completely, standardize the input, and then train the model? Of course, this leads to another issue, which is the need to handle a large amount of data from the beginning. For example, if there is 100T of data, it may take several months to process. How do you all view this?
Additionally, from an algorithmic perspective, including ethical and model security, should we solve these problems in a unified way, or should there be a system architecture similar to large models to address all these issues? How do you all view this question?
Huang Minlie: First of all, I think thorough cleaning of the data is necessary. Even if you clean all the data very thoroughly, large models still have the ability to bypass security attacks. For example, the well-known Grandma vulnerability allows the model to impersonate a grandmother and ask for sensitive information. Security attacks are easily bypassed even if the data is processed very cleanly. Our recent research has found that the smarter the system, the easier it is to bypass it through complex instructions. The rapid iteration of the model's capabilities today is fundamentally due to its ability to follow very complex instructions. It's a contradictory process; the security and ethics of my own capabilities are contradictory. On the one hand, I can understand your instructions, but on the other hand, as long as humans use complex instructions, I can bypass these security restrictions. So, this is a difficult problem to handle, so I think the first answer is that we need more systematic methods in data processing.
The second question is how to solve these problems. I believe we need a systematic approach, not just from the data processing itself. For example, there is a concept called "super management" that we are working on. We hope to automatically discover vulnerabilities in the model, extract the helpful parts from the vulnerability data, and then automatically iterate to train the model. It's like an automatic process of risk discovery and repair. I think this basic mechanism is very necessary.
For example, OpenAI recently discussed leaking some signals from Q-star, right? Similar to what we talked about with AlphaZero, can we start from scratch to teach a model, give it some rules, give it some basic ethical and moral standards, and then let it gradually learn the entire process automatically, with some human supervision, but our goal is to reduce human supervision from 100% to 50%, then to 20%, or even 10%. At that point, we can make the entire system run very smoothly, so I think this should be our future goal.
Zhai Jidong: I can speak from a user's perspective. This year, because I am also involved in the Computer Association, I have participated in some forums and organized many discussions on security. My point of view is that security is very important, and I strongly agree. But if we consider artificial intelligence as a growing child, I think we should be somewhat tolerant. For example, there are certain things that we will teach our children not to do. I think it's the same for large models. If it tells some jokes or doesn't tell them well, or if it's not illegal, I think we can still allow it to develop. My point has always been that, within the premise of not violating principles, I think development is the key, that's my view.
Zhu Jun: Both professors just made very good points, and I'd like to add a little bit. I understand cleaning as doing extreme cleaning, not just simple cleaning as it is done now. An extreme analogy is the logic and rules we discussed earlier. You can understand it as an extreme form of actual thorough data cleaning, which can be done within a certain range. But we are definitely not satisfied now because it has created an expert system, which is very extreme in some aspects. But when we discuss AGI, it does not satisfy us. So, when it comes to training large models, the data itself may need to have a certain level of diversity.
A simple example is that training directly in Chinese may not be as good in language understanding as training in multiple languages, which would include more knowledge and diversity, making the model's generalization ability stronger, including its emergent ability. And when doing AIGC generation models, what people care about is their creativity. In addition to meeting aesthetic or quality requirements, there is also a strong demand for creative diversity. So, we cannot simply impose simple rules or extreme cleaning or constraints in the basic model.
The second question is about security, ethics, and fairness. Is there a unified framework for addressing these issues? My current view is that it is quite difficult to achieve because it actually needs to be considered from multiple perspectives. One reason is that when we discuss security or fairness, we generally simplify it into a specific quantifiable metric. When we optimize a specific metric, it means that we lose a lot, and we may not grasp some deeper understanding of the essence. A high metric does not necessarily mean that we have truly solved the problem.
The second reason is that many metrics are not completely in conflict. For example, robustness and randomness in model development, which have been studied for many years, are actually both pursued to the extreme. That is, can we have both high randomness and high robustness? It's difficult to achieve both at the same time; there needs to be a certain balance between the two. If you want to completely achieve one, you may have to sacrifice the other.
So, just like with large models, when we add many constraints, we may lose many capabilities. Therefore, I think it is quite difficult to use a unified framework to comprehensively integrate many metrics. But I'm not sure if there will be such a method in the future.
Tang Jie: Alright, thank you very much, let's give a round of applause to these three professors. For the last question, due to time constraints, let's quickly move on to the last question. Returning to our main topic, within the next year, everyone can make a prediction about what AGI will be like in a year, or what it will be like in the next 10 years. As the professors mentioned earlier, for example, Huang Minlie mentioned that in the future, perhaps large models will learn and correct themselves. Or we can simplify this question a bit, instead of talking about what AGI will be like in the future, we can talk about what GPT5 will be like in a year. What will be its main feature? For example, will it have a major breakthrough in multimodal capabilities, or will there be a change from GPT to GPT zero? I think it would be interesting to hear everyone's predictions for the next year and then further into the future, how AGI will have a greater impact on our human society. What are your thoughts on this outlook?
Zhu Jun: Tang Jie has really put me on the spot. I'm not very keen on making predictions, but I think the first question is relatively easier to answer. For example, in a year or half a year, the iteration speed is very fast now. For example, Zhipu iterates every three or four months, right? I think it's relatively easy to predict that in 2024, there will be significant improvements in multimodal capabilities. For example, we have already seen advancements in text and images, and 3D is progressing rapidly, including our own work and domestic and foreign platforms like Runway. Everyone is quickly working on it, and by 2024, it may be ready for commercial integration.
Another area that I see as promising is the rapid development of video. Currently, most of the work is on generating short videos of 3-4 seconds, but in the future, within less than half a year, people may start creating longer videos or more narrative content, all in the realm of multimodal capabilities.
Another area I see as promising is the use of AI capabilities in robotics after they have been enhanced. This is something to look forward to this year. As for the next 10 years, I can't say for sure. I really don't dare to say what it will look like in 10 years. Maybe by then, I'll have gray hair, watching the progress of AGI.
Zhai Jidong: I'll quickly answer this question. Tang Jie, this question is very broad, and I can answer it from a different angle. Today, this forum is about AGI, and I have attended many conferences. In the last forum, about 50% of the audience believed that AGI will become a reality. I don't know when, but at least I believe that many of us here also believe that AGI will become a reality.
Wang Yu: I am particularly looking forward to this year because I work on high-efficiency models, and I am hoping for the emergence of very powerful small models. After training them well, at least there should be a small one that we can use. This is what I hope the algorithmic colleagues can achieve this year, and it's what I'm most looking forward to. As for the next 10 years, I hope that by then, China will be self-sufficient in terms of computing power.
Huang Minlie: I hope I won't be proven wrong with my predictions, but I have three aspects to consider. First, I think there will be a strong ability for self-purification, as I mentioned earlier, the ability to self-learn and self-iterate. Another aspect is the ability to connect with the external world, whether as an intelligent entity or as other plugins, to execute more real-world applications and scenarios. The third aspect is that there may be some major applications in science, such as using AGI to help solve major mathematical, physical, and chemical scientific problems. These are my general thoughts.
Tang Jie: Thank you very much, Professor Huang, let's give him a round of applause. Alright, we are almost at the end of today's forum. As we have seen, the professors have provided many insights into AGI. Of course, we have not reached a conclusion today about what AGI will look like in the future. But I will give a simple hint.
I remember five years ago, in different settings, when we discussed AGI, not only on stage, but also with some professors and many audience members, there was direct opposition. It was considered impossible, and it couldn't even be mentioned. It was as if you were telling a joke. But today, I feel very fortunate that all of us are sitting here, discussing the possibility of AGI. We all believe it is possible, and we are very confident, including the audience members present, who are still sitting here listening to us discuss AGI. We don't know what AGI will look like in the future, but we firmly believe that the next five years and the next ten years may bring a huge change in AI. Let's consider ourselves fortunate to be thinking about it. 2024 is the year of AGI. Let's work together to make AGI more possible, okay? Thank you, everyone. And thank you to all the speakers.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







