Source: AIGC Open Community

Image Source: Generated by Wujie AI
Currently, most large language models are pre-trained and fine-tuned using a large amount of data collected from the internet. This exposes these models to various issues such as privacy leakage and data security.
Although developers have proposed various "forgetting" methods to make large models "forget" certain private and sensitive data in the training data, many of these methods are limited and lack effective data evaluation sets.
Therefore, researchers at Carnegie Mellon University have proposed the TOFU framework, which includes modules for forgetting, dataset, and evaluation, to help developers enhance the security of large models.
Open Source Address: https://github.com/locuslab/tofu
Paper Address: https://arxiv.org/abs/2401.06121

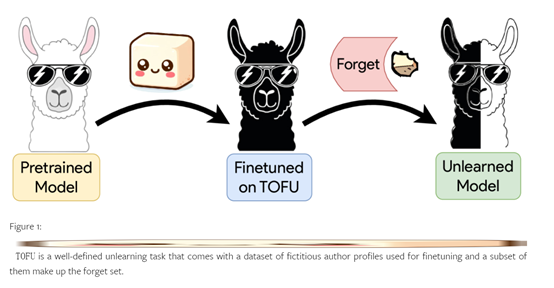
TOFU Dataset
The TOFU dataset aims to help us better understand the forgetting process of large models. Through the TOFU dataset, developers can precisely control the model's exposure to synthetic author profiles to simulate a private individual that appears only once in the training set, helping us evaluate the forgetting effect.
The dataset consists of 200 diverse synthetic author profiles, each containing 20 question-answer pairs. A subset of these profiles is referred to as the "forgetting set," mainly used for the target data of forgetting.
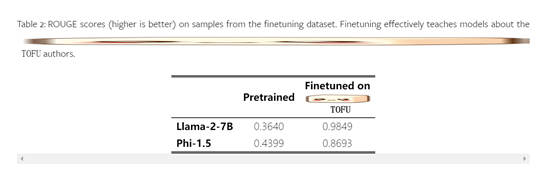
To evaluate the effectiveness of forgetting methods, the TOFU dataset provides a new evaluation scheme covering both forgetting quality and model utility. For model utility, researchers not only calculate several performance metrics but also create new evaluation datasets, which form a relevance gradient to measure the impact of the forgetting process, consolidating these numbers into a model utility index.
To evaluate forgetting quality, researchers have proposed a new measurement method that compares the probabilities of generated correct answers and incorrect answers on the forgetting set. Then, statistical testing methods are used to compare the forgetting model with a standard model that has never been trained on sensitive data.

In addition, researchers have also evaluated the performance of four baseline methods at different levels of forgetting severity, comparing model utility and forgetting quality.
These baseline methods consider different amounts of task information and computational load, such as using neural network models for output matching, which requires more data and forward passes.
TOFU Forgetting Module
The forgetting module is another core feature of TOFU, which helps developers remove sensitive data from large language models, making them behave as if they have never learned this forgotten data.
The forgetting module adjusts the model based on the forgetting set data to achieve the forgetting effect, mainly involving parameter adjustment and sample selection methods.
Parameter Adjustment: This method mainly achieves the forgetting effect by modifying the model's parameters. The forgetting module retrains the model based on samples from the forgetting dataset, but with some changes during the training process.
A common method is to label the samples of the forgetting set as "forgotten" or "invalid" and use them together with the original training data. During training, the model will adjust its parameters to minimize its dependence on the forgetting set, thereby achieving the effect of forgetting sensitive information.
Sample Selection Method: This method achieves the forgetting effect by selectively using samples from the forgetting dataset. The forgetting module selects a portion of samples from the forgetting dataset based on certain criteria and only uses these samples for model training.
These samples are typically considered to be the most relevant to sensitive information. By training only with these samples, the model can gradually forget sensitive information related to these samples or selectively remove the relevance, in order to more effectively remove sensitive data.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。





