Source: Synced

Image Source: Generated by Wujie AI
Still struggling to find open-source large-scale robot models? Try RoboFlamingo!
In recent years, research on large-scale models has been accelerating, gradually demonstrating multimodal understanding and spatiotemporal reasoning capabilities in various tasks. Various physical operation tasks of robots naturally require high capabilities in language command understanding, scene perception, and spatiotemporal planning, which naturally raises a question: Can the capabilities of large-scale models be fully utilized and transferred to the field of robots to directly plan lower-level action sequences?
In response to this, ByteDance Research has developed an open-source and easy-to-use RoboFlamingo robot operation model based on the open-source multimodal language visual model OpenFlamingo, which can be trained using only a single machine. With simple usage and minimal fine-tuning, the VLM can be transformed into a Robotics VLM, making it suitable for language interactive robot operation tasks.
OpenFlamingo has been validated on the robot operation dataset CALVIN, and the experimental results show that RoboFlamingo achieved state-of-the-art performance in a series of robot operation tasks using only 1% of the language-labeled data. With the opening of the RT-X dataset, pre-training RoboFlamingo with open-source data and fine-tuning it to different robot platforms may become a simple and effective robot large-scale model pipeline. The paper also tested the performance of various policy heads, different training paradigms, and different Flamingo structures of VLM in fine-tuning on Robotics tasks, obtaining some interesting conclusions.

- Project homepage: https://roboflamingo.github.io
- Code repository: https://github.com/RoboFlamingo/RoboFlamingo
- Paper link: https://arxiv.org/abs/2311.01378
Research Background
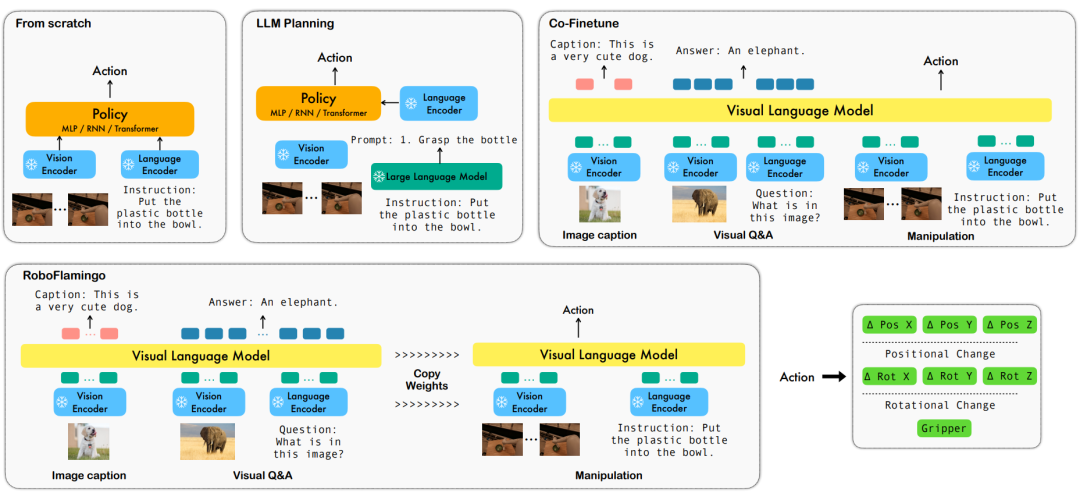
Language-based robot operation is an important application in the field of embodied intelligence, involving the understanding and processing of multimodal data, including vision, language, and control. In recent years, Visual Language Models (VLMs) have made significant progress in various fields, including image description, visual question answering, and image generation. However, applying these models to robot operation still faces some challenges, such as how to integrate visual and language information and how to handle the temporality of robot operation.
To address these issues, ByteDance Research's robot research team utilized the existing open-source VLM, OpenFlamingo, to design a new visual language operation framework, RoboFlamingo. The VLM can perform single-step visual language understanding, while additional policy head modules are used to handle historical information. Simple fine-tuning methods can adapt RoboFlamingo to language-based robot operation tasks.
RoboFlamingo has been validated on the language-based robot operation dataset CALVIN, and the experimental results show that RoboFlamingo achieved state-of-the-art performance in a series of robot operation tasks using only 1% of the language-labeled data (the success rate of multi-task learning task sequences is 66%, with an average task completion of 4.09, compared to the baseline method of 38% and an average task completion of 3.06; the zero-shot task success rate is 24%, with an average task completion of 2.48, compared to the baseline method of 1% and an average task completion of 0.67), and can achieve real-time response through open-loop control, and can be flexibly deployed on lower-performance platforms. These results indicate that RoboFlamingo is an effective robot operation method and can provide useful references for future robot applications.
Method
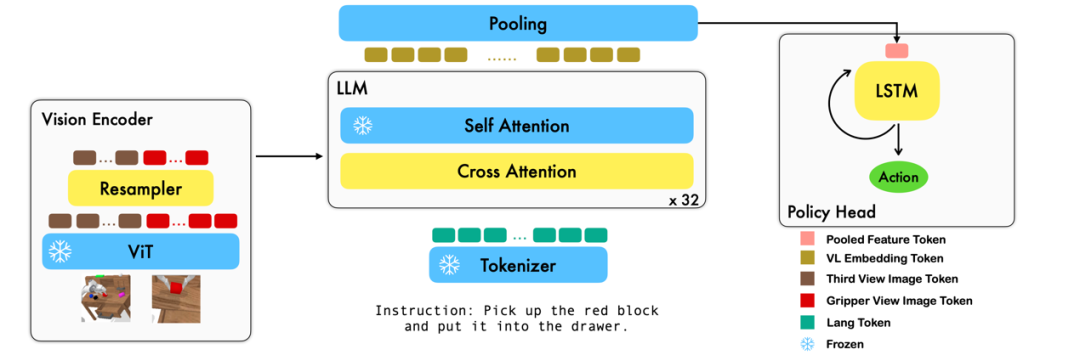
This work uses existing image-text-based visual language basic models to generate relative actions of robots in an end-to-end training manner. The main modules of the model include the vision encoder, feature fusion decoder, and policy head. The vision encoder module first inputs the current visual observation into ViT and downsamples the tokens output by ViT through a resampler. The feature fusion decoder takes the text token as input and, in each layer, first uses the output of the vision encoder as a query for cross-attention, then performs self-attention to complete the fusion of visual and language features. Finally, the feature fusion decoder is subjected to max pooling and then input into the policy head, which directly outputs the current 7 DoF relative action based on the current and historical token sequences, including the 6-dimensional end effector pose of the robotic arm and the 1-dimensional gripper open/close.
During the training process, RoboFlamingo utilizes pre-trained ViT, LLM, and Cross Attention parameters, and only fine-tunes the parameters of the resampler, cross attention, and policy head.
Experimental Results
Dataset:
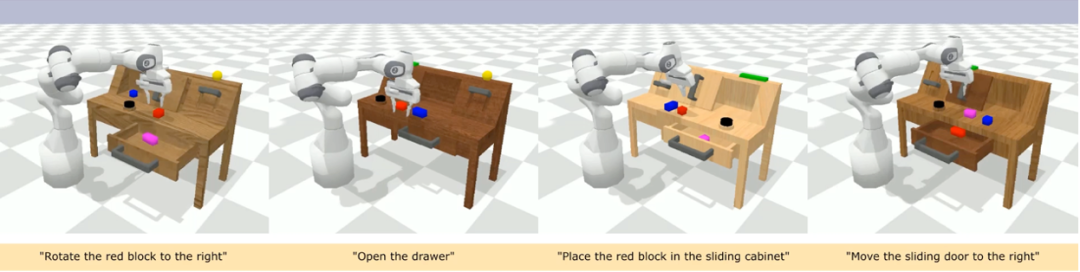
CALVIN (Composing Actions from Language and Vision) is an open-source simulated benchmark used for learning language-based long-horizon operation tasks. Compared to existing visual-language task datasets, CALVIN's tasks are more complex in terms of sequence length, action space, and language, and support flexible specification of sensor inputs. CALVIN is divided into four splits: ABCD, each corresponding to different contexts and layouts.
Quantitative analysis:
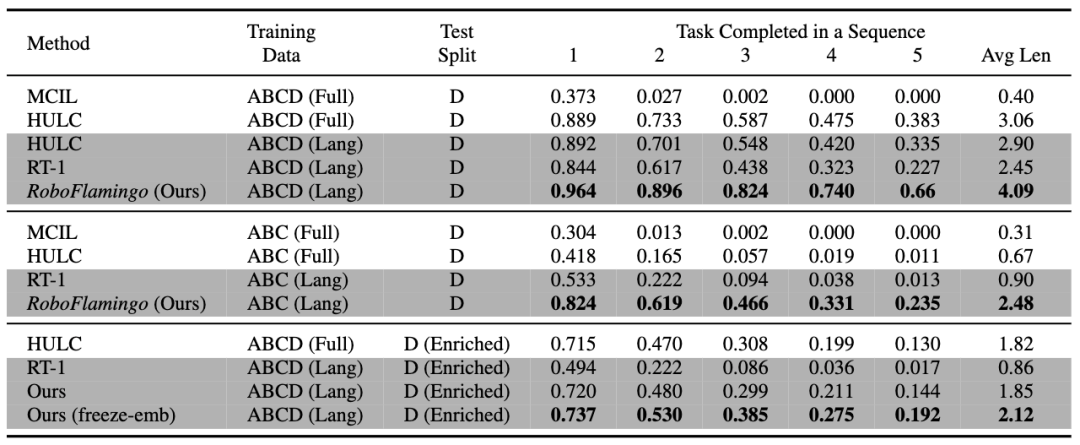
RoboFlamingo performs best in various settings and metrics, demonstrating strong imitation, visual generalization, and language generalization capabilities. "Full" and "Lang" indicate whether the model was trained using unpaired visual data (i.e., visual data without language pairs); "Freeze-emb" refers to freezing the embedding layer of the fusion decoder; "Enriched" indicates the use of GPT-4 enhanced instructions.
Ablation experiments:
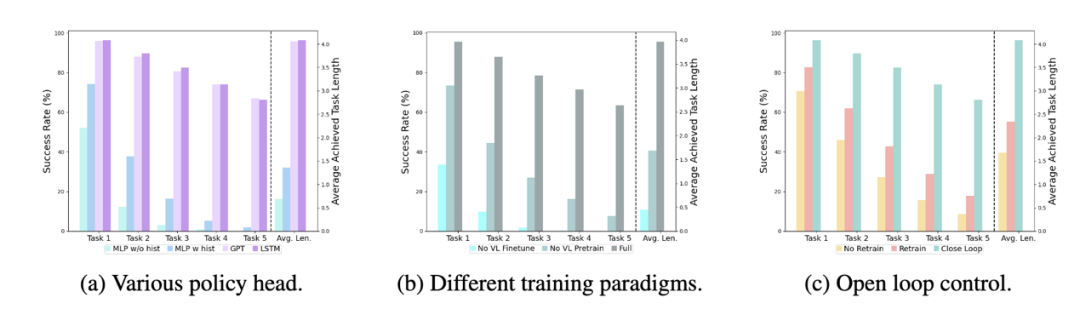
Different policy heads:
The experiment examined four different policy heads: MLP w/o hist, MLP w hist, GPT, and LSTM. Among them, MLP w/o hist directly predicts history based on the current observation, with the worst performance. MLP w hist fuses historical observations at the vision encoder end before predicting action, resulting in improved performance. GPT and LSTM explicitly and implicitly maintain historical information at the policy head, with the best performance, demonstrating the effectiveness of historical information fusion through the policy head.
Impact of visual-language pre-training:
Pre-training plays a crucial role in improving RoboFlamingo's performance. The experiment shows that pre-training on a large-scale visual-language dataset leads to better performance in robot tasks.
Model size and performance:
Although larger models generally lead to better performance, the experimental results show that even smaller models can compete with large models in certain tasks.
Impact of instruction fine-tuning:
Instruction fine-tuning is a powerful technique, and the experimental results show that it can further improve the model's performance.


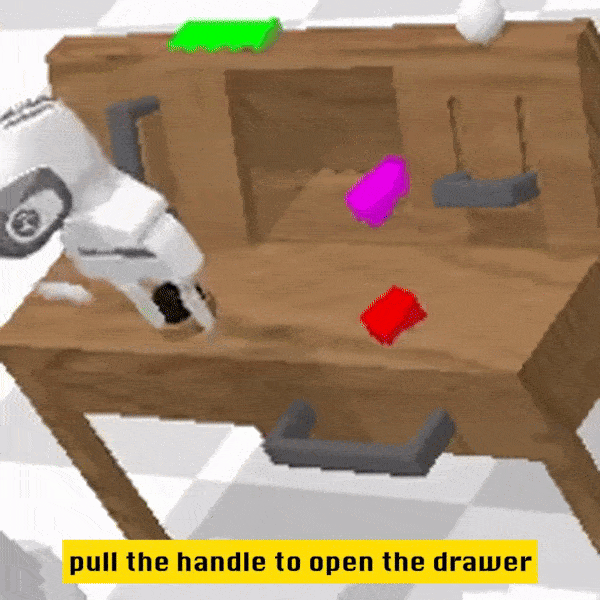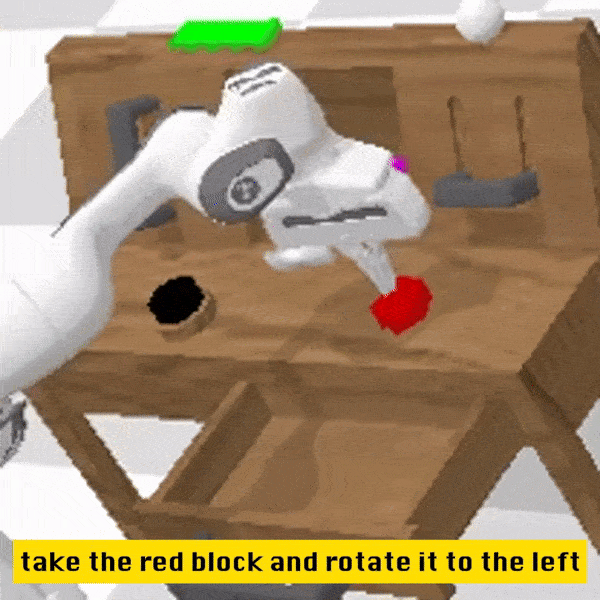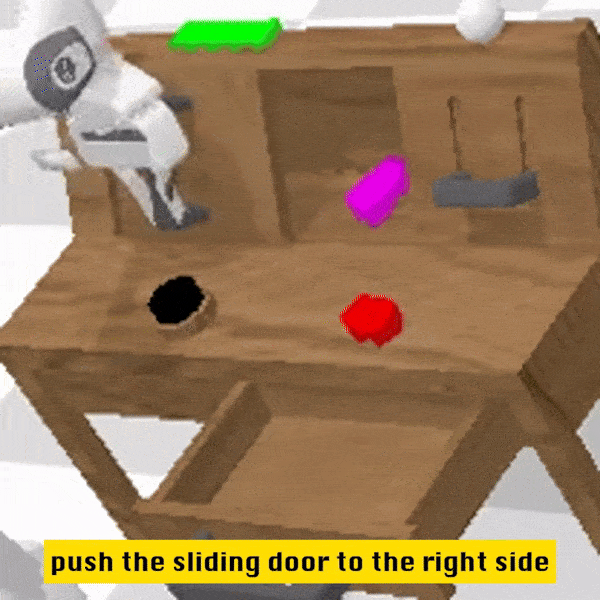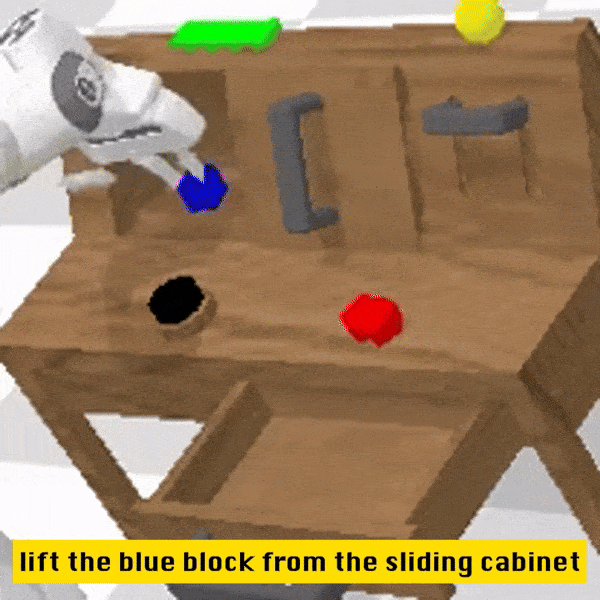



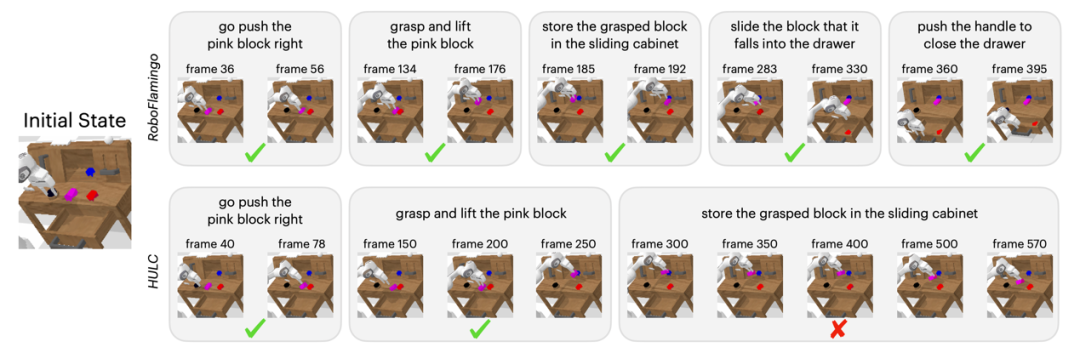
Qualitative Results
Compared to the baseline method, RoboFlamingo not only completed 5 consecutive sub-tasks but also used significantly fewer steps for the first two sub-tasks that the baseline method successfully completed.
Conclusion
This work provides a novel framework for language-interaction robot operation strategies based on existing open-source VLMs, achieving excellent results with simple fine-tuning. RoboFlamingo provides a powerful open-source framework for robot technology researchers to more easily unleash the potential of open-source VLMs. The rich experimental results in this work may provide valuable experience and data for the practical application of robot technology, contributing to future research and technological development.
References:
- Brohan, Anthony, et al. "Rt-1: Robotics transformer for real-world control at scale." arXiv preprint arXiv:2212.06817 (2022).
- Brohan, Anthony, et al. "Rt-2: Vision-language-action models transfer web knowledge to robotic control." arXiv preprint arXiv:2307.15818 (2023).
- Mees, Oier, Lukas Hermann, and Wolfram Burgard. "What matters in language conditioned robotic imitation learning over unstructured data." IEEE Robotics and Automation Letters 7.4 (2022): 11205-11212.
- Alayrac, Jean-Baptiste, et al. "Flamingo: a visual language model for few-shot learning." Advances in Neural Information Processing Systems 35 (2022): 23716-23736.
- Mees, Oier, et al. "Calvin: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks." IEEE Robotics and Automation Letters 7.3 (2022): 7327-7334.
- Padalkar, Abhishek, et al. "Open x-embodiment: Robotic learning datasets and rt-x models." arXiv preprint arXiv:2310.08864 (2023).
- Brown, Tom, et al. "Language models are few-shot learners." Advances in neural information processing systems 33 (2020): 1877-1901.
8. Awadalla, Anas, et al. "Openflamingo: An open-source framework for training large autoregressive vision-language models." arXiv preprint arXiv:2308.01390 (2023).
9. Driess, Danny, et al. "Palm-e: An embodied multimodal language model." arXiv preprint arXiv:2303.03378 (2023).
10. Jiang, Yunfan, et al. "VIMA: General Robot Manipulation with Multimodal Prompts." NeurIPS 2022 Foundation Models for Decision Making Workshop. 2022.
11. Mees, Oier, Jessica Borja-Diaz, and Wolfram Burgard. "Grounding language with visual affordances over unstructured data." 2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023.
12. Tan, Mingxing, and Quoc Le. "Efficientnet: Rethinking model scaling for convolutional neural networks." International conference on machine learning. PMLR, 2019.
13. Zhang, Tianhao, et al. "Deep imitation learning for complex manipulation tasks from virtual reality teleoperation." 2018 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2018.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。





