Article Source: Synced
Recently, the CMU Catalyst team released a comprehensive review of efficient LLM reasoning, covering more than 300 related papers, and introducing algorithm innovation and system optimization from the perspective of MLSys research.

Image Source: Generated by Wujie AI
In the context of the rapid development of artificial intelligence (AI), Large Language Models (LLMs) have become an important driving force in the field of AI due to their outstanding performance in language-related tasks. However, as these models become more widely used in various applications, their complexity and scale have also brought unprecedented challenges to their deployment and service. LLM deployment and service face intensive computational intensity and huge memory consumption, especially in scenarios requiring low latency and high throughput. How to improve the efficiency of LLM services and reduce their deployment costs has become an urgent problem in the current AI and system fields.
In their latest review paper, the Catalyst team from Carnegie Mellon University (CMU) analyzes in detail the revolutionary changes from cutting-edge LLM reasoning algorithms to systems from the research perspective of machine learning systems (MLSys) to address these challenges. The review aims to provide a comprehensive understanding of the current state and future direction of efficient LLM services, providing valuable insights for researchers and practitioners to overcome obstacles in deploying effective LLM and reshape the future of AI.

Paper Link: https://arxiv.org/abs/2312.15234
The first author of the paper is Dr. Xupeng Miao, a postdoctoral researcher at Carnegie Mellon University, and the co-authors include Assistant Professors Tianqi Chen and Zhihao Jia. In addition, other student authors are also from the CMU Catalyst Group laboratory, which is jointly led by Zhihao Jia and Tianqi Chen at CMU, dedicated to integrating optimization technologies from various aspects such as machine learning algorithms, systems, and hardware to construct automated machine learning systems. Previously, the laboratory has also launched open-source projects such as SpecInfer, MLC-LLM, SpotServe [ASPLOS‘24], promoting research and application of LLM large model-related systems. Laboratory homepage: https://catalyst.cs.cmu.edu.
Overview of the Review
The review systematically examines existing LLM reasoning technologies, covering more than 300 related papers, and introduces them from the perspectives of algorithm innovation and system optimization. Based on this, the paper designs a clear and comprehensive classification system for existing work, highlighting the advantages and limitations of various methods, collecting and introducing relevant papers for each category. In addition, the paper also conducts in-depth comparisons and analyses of the current mainstream LLM reasoning frameworks in terms of system design and implementation. Finally, the authors look forward to how to continue to improve LLM reasoning efficiency and propose six potential development directions at the technical level.
Classification System
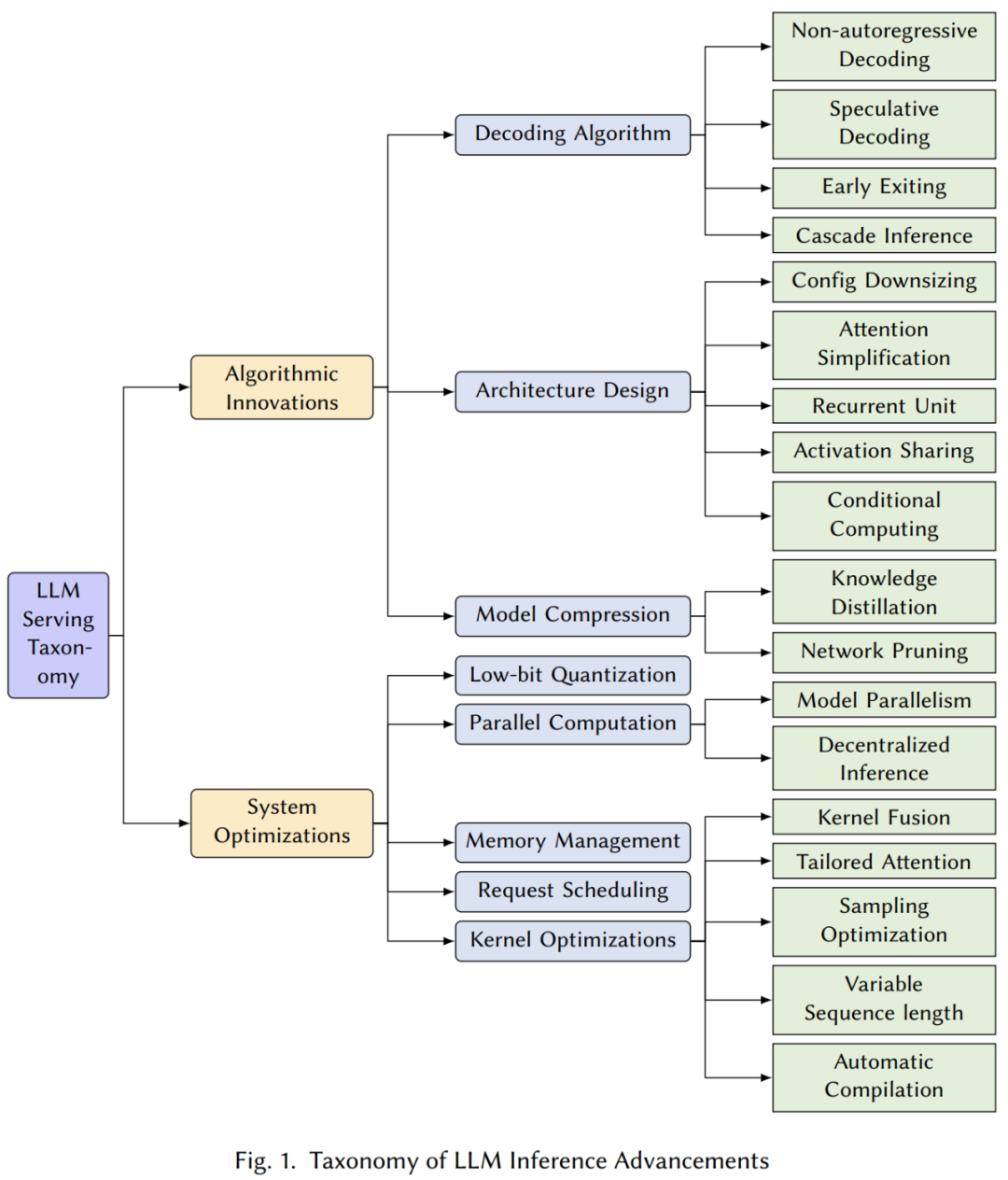
Algorithm Innovation
This section provides a comprehensive analysis of various proposed algorithms and technologies aimed at improving the native performance deficiencies of large-scale Transformer model reasoning, including decoding algorithms, architecture design, and model compression, among others.
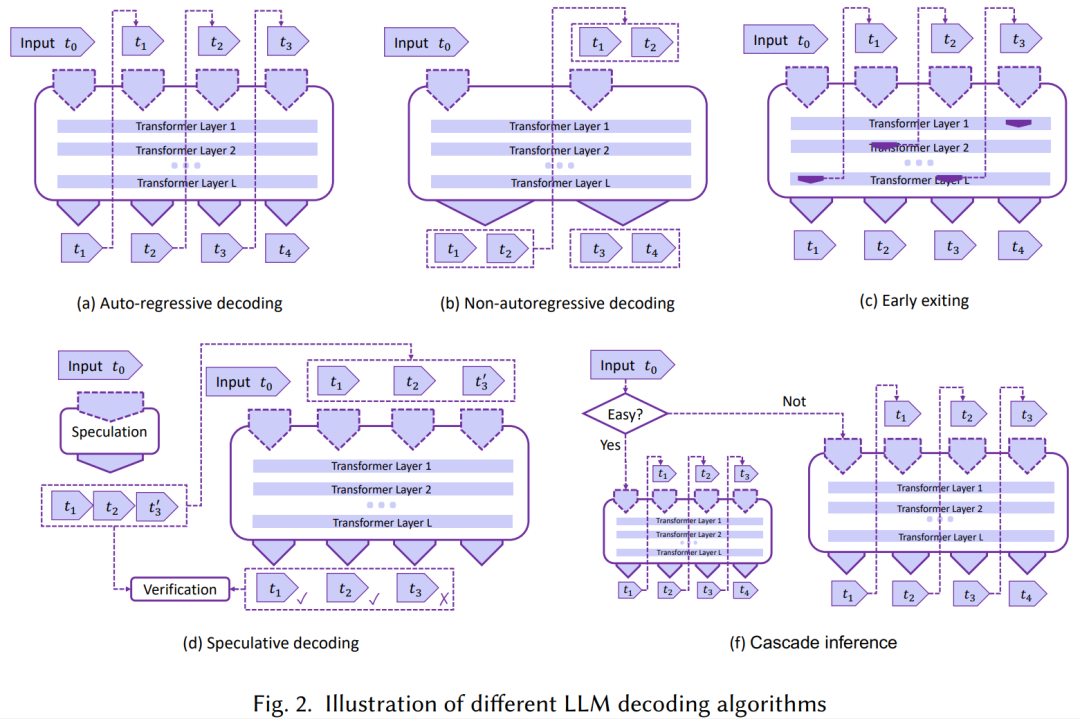
Decoding algorithms: In this section, we review several novel decoding algorithms for LLMs reasoning optimization shown in Figure 2. These algorithms aim to reduce computational complexity and improve the overall efficiency of language model reasoning in generation tasks, including:
- Non-autoregressive decoding: A major limitation of existing LLMs is the default autoregressive decoding mechanism, which generates output tokens sequentially. To address this issue, a representative direction of work is non-autoregressive decoding [97, 104, 108, 271], which abandons the autoregressive generation paradigm, breaks word dependencies, assumes a certain degree of conditional independence, and decodes output tokens in parallel. However, although such methods have improved decoding speed, the output quality of most non-autoregressive methods is still not as reliable as autoregressive methods.
- Speculative reasoning: Another type of work is to achieve parallel decoding through speculative execution [47]. Each decoding step in autoregressive LLM reasoning can be viewed as a program execution statement with conditional branches, i.e., deciding which token to generate next. Speculative reasoning [51, 155] first uses a smaller draft model to predict multiple decoding steps, and then allows the LLM to verify these predictions simultaneously to achieve acceleration. However, there are still some practical challenges when applying speculative decoding to LLMs, such as how to make decoding predictions lightweight and accurate, and how to achieve efficient parallel verification with LLMs. SpecInfer [177] first introduced tree-based speculative decoding and tree attention, proposing a low-latency LLM service system implementation, which has been directly adopted by multiple subsequent works [48, 118, 168, 185, 229, 236, 274, 310].
- Early exit: These methods mainly utilize the deep multi-layer structure of LLMs to exit reasoning early in the intermediate layers, and the output of the intermediate layers can be transformed into output tokens through a classifier, thereby reducing reasoning overhead [117, 147, 163, 167, 234, 272, 282, 291, 308], also known as adaptive computation [68, 219].
- Cascade reasoning: These methods cascade multiple LLM models of different scales to handle reasoning requests of different complexities, with representative works including CascadeBERT [157] and FrugalGPT [53].
Architecture design:
- Configuration reduction: Directly reducing model configuration.
- Attention simplification: Many recent research works have mainly applied efficient attention mechanisms for long sequences [240] to LLMs, shortening the context, reducing KV cache, and attention complexity, while slightly reducing decoding quality (such as sliding window [129, 299], hash [198], dilated [74], dynamic selection, etc.). Table 1 summarizes the correspondence between some recent popular methods and previous works.

- Shared Activation: This type of method mainly aims to reduce reasoning memory overhead by sharing intermediate activations of attention calculations. Representative works include MQA [220] and GQA [32].
- Conditional Computation: This type of method mainly refers to Sparse Mixture of Experts (Sparse MoE) models, such as the recently popular Mistrial 7Bx8 model.
- Recurrent Units: Although Transformers have replaced RNN models, considering the secondary complexity of attention mechanisms, people have always been trying to reintroduce recurrent unit mechanisms into LLMs, such as RWKV [200], RetNet [235], and state space models [91, 102, 103, 176], among others.
Model Compression:
- Knowledge Distillation: These methods train a small student model supervised by a large teacher model. Most previous methods have been exploring white-box distillation [106, 133, 214, 233, 255], which requires access to the parameters of the entire teacher model. With the emergence of API-based LLM services (such as ChatGPT), some black-box distillation models have attracted a lot of attention [238, 59, 273, 201, 313], which usually have fewer model parameters and show considerable performance on various downstream tasks compared to the original LLMs (such as GPT-4 [195]).
- Network Pruning: In the past few years, network pruning methods [180, 215, 215] have been widely studied, but not all methods can be directly applied to LLMs. Consideration needs to be given to the potential high computational cost of retraining and evaluating whether pruning can achieve efficiency improvements in the underlying system. It can generally be divided into structured pruning [80, 149, 174, 216, 172] and semi-structured sparsification [40, 87, 232, 251, 276], among others.
System Optimization
This section studies LLM reasoning system optimization techniques to accelerate LLM reasoning without changing LLM semantic computation. The goal of this work is to improve system efficiency by enhancing the underlying systems and frameworks used for large language model reasoning, including low-bit quantization, parallel computation, memory management, request scheduling, and kernel optimization, among others. For detailed content, please refer to the original paper.
Software Framework
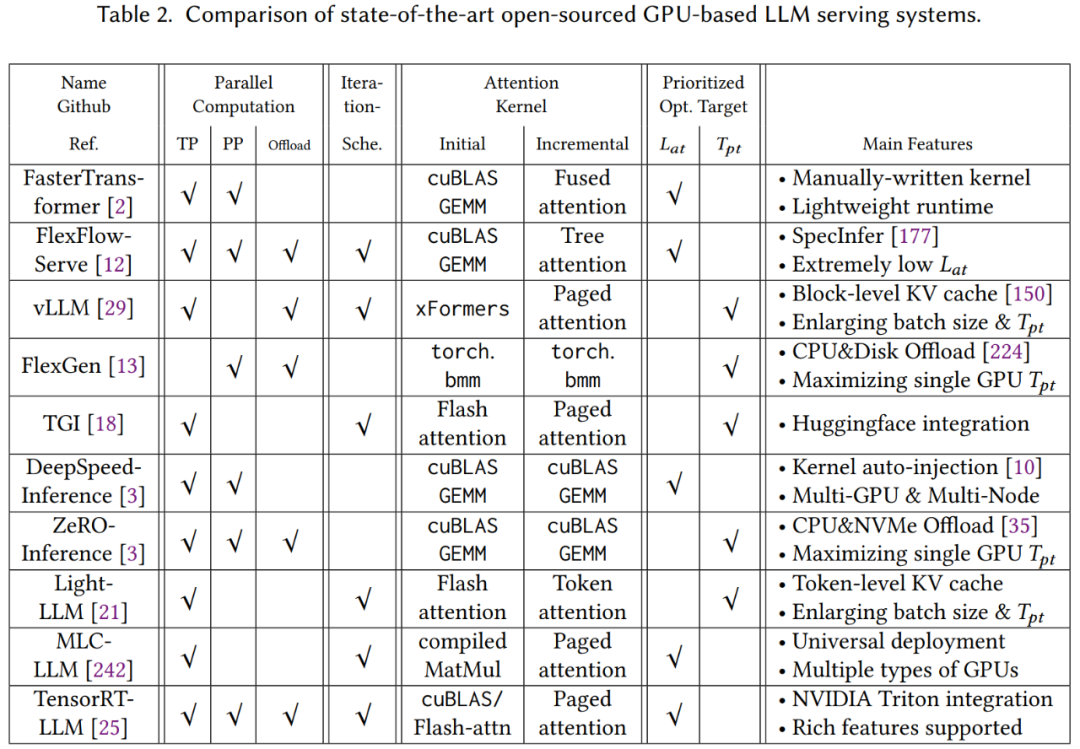
The paper also provides in-depth analysis of some of the most advanced GPU-based open-source LLM reasoning systems and summarizes their differences in design and implementation from multiple aspects.
Future Directions
- Development of Specialized Hardware Accelerators: Significant improvements in the efficiency of generative LLM services may largely depend on the development and enhancement of specialized hardware accelerators, especially through software-hardware co-design methods. For example, making memory units closer to processing units, or optimizing chip architecture for LLM algorithm data flow, can greatly facilitate and provide opportunities for LLM reasoning at the software level.
- Efficient Decoding Algorithms: Developing more efficient decoding algorithms can significantly improve service efficiency. Driven by the need for faster generation speed for real-time applications, a promising direction is generalized speculative inference, which not only brings significant acceleration but also maintains the same generation quality. As pointed out in SpecInfer, in generalized speculative inference, the small model used to generate draft tokens can be replaced with any fast token generation method, such as custom functions, recall methods, or even early stopping mechanisms and non-autoregressive decoding, among others.
- Optimization for Long Context/Sequence Scenarios: As application scenarios become more complex, the demand for handling longer contexts or sequences continues to grow. LLMs serving long sequence loads need to address challenges in both algorithms and systems. In terms of algorithms, they still face issues of length generalization failure and even "loss in the middle." Current solutions mainly focus on shortening sequence length and preserving relevant information through recall enhancement, sequence compression, and caching as much as possible.
- Exploration of Alternative Architectures: Although Transformer models and self-attention mechanisms currently dominate the LLM field, exploring alternative architectures is a promising direction for future research. For example, some recent studies have explored attention-free methods, using pure MLP (multi-layer perceptron) architectures to replace attention mechanisms, which may change the landscape of current LLM reasoning optimization.
- Exploration of Deployment in Complex Environments: As LLM applications expand, exploring and optimizing their deployment in various complex environments becomes a key future direction. This exploration is not limited to traditional cloud-based deployment but also includes edge computing, hybrid computing (cloud+edge), decentralized computing, and inexpensive preemptible resources, among others.
- Automatic Adaptation to Specific Requirements: The diversity of application-specific requirements creates a range of innovative opportunities for optimizing LLM services, such as parameter-efficient fine-tuning, vector database retrieval, multimodal loads, and more. These unique challenges also require the seamless and automatic integration of LLM service technology into existing IT infrastructure, expanding optimization opportunities throughout the entire LLM lifecycle.
Conclusion
In summary, this review not only provides a comprehensive overview of current research on LLM service optimization but also points the way for future exploration and development in this field. By gaining in-depth understanding of these advanced solutions, researchers and practitioners can better understand and address the challenges of deploying large language models in practical applications.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







