Source: New Wisdom Element

Image Source: Generated by Wujie AI
Instruction tuning may be the most potential method to improve the performance of large models.
Using high-quality datasets for instruction tuning can quickly improve the performance of large models.

In response, the Microsoft research team trained a CodeOcean dataset, which includes 20,000 instruction instances, and 4 general code-related tasks.
At the same time, the researchers fine-tuned a large code model, WaveCoder.

Paper link: https://arxiv.org/abs/2312.14187
Experimental results show that WaveCoder outperforms other open-source models and performs well in previous code generation tasks.
Instruction Tuning Unleashes the Potential of "Large Code Models"
In the past year, large models such as GPT-4, Gemini, and Llama have achieved unprecedented performance in a series of complex NLP tasks.
These LLMs, through the process of self-supervised pre-training and subsequent fine-tuning, have demonstrated powerful zero/few-shot capabilities, effectively following human instructions to complete various tasks.
However, the cost of training and fine-tuning such a large model is enormous.
Therefore, some relatively smaller LLMs, especially code large language models (Code LLM), have attracted the attention of many researchers due to their outstanding performance in a wide range of code-related tasks.
Given that LLMs can gain rich domain knowledge through efficient pre-training on code corpora, it is crucial for large code models.
Several studies, including Codex, CodeGen, StarCoder, and CodeLLaMa, have successfully demonstrated that the pre-training process can significantly enhance the ability of large models to handle code-related problems.
In addition, multiple studies on instruction tuning (FLAN, ExT5) have shown that models tuned with instructions perform as expected in various tasks.
These studies incorporate thousands of tasks into the training pipeline to improve the pre-trained model's generalization ability for downstream tasks.
For example, InstructGPT effectively adjusts user input by integrating high-quality instruction data written by human annotators, advancing further exploration of instruction tuning.
Alpaca at Stanford uses the Self-Instruct method through ChatGPT to generate instruction data for instruction tuning.
WizardLM and WizardCoder apply the evol-instruct method to further enhance the effectiveness of pre-trained models.
These recent studies all demonstrate the powerful potential of instruction tuning in improving the performance of large models.
Based on these works, researchers' intuition is that instruction tuning can activate the potential of large models and then fine-tune the pre-trained model to an excellent intelligent level.
In this regard, they summarized the main functions of instruction tuning:
- Generalization
Instruction tuning was initially proposed to enhance the cross-task generalization ability of large models. When fine-tuned with instructions from different NLP tasks, instruction tuning can improve the model's performance in a large number of unseen tasks.
- Alignment
Pre-trained models have already learned to understand text inputs from a large number of token and sentence-level self-supervised tasks. Instruction tuning provides instruction-level tasks for these pre-trained models, allowing them to extract more information from instructions beyond the original text semantics. This additional information is the user's intent, which enhances their interaction with human users, thereby aiding alignment.
To improve the performance of large code models through instruction tuning, there are already many well-designed methods for generating instruction data, mainly focused on two aspects.
For example, self-instruct and vol-instruct utilize the zero/few-shot capabilities of teacher LLM to generate instruction data, providing a magical method for generating teaching data.
However, these generation methods rely too much on the performance of teacher LLM and sometimes produce a large amount of duplicate data, which can reduce the efficiency of fine-tuning.
CodeOcean: Instruction Data for Four Code-Related Tasks
To address these issues, as shown in Figure 2, researchers have proposed a method that can fully utilize source code and explicitly control the quality of generated data.
Since instruction tuning aims to keep the pre-trained model consistent with the instruction-following training set, researchers have proposed a Large Model Generator-Discriminator framework for instruction data generation.
By using the generator and discriminator, the latest method can make the data generation process more customizable and controllable.
This method takes the original code as input, selects core datasets, and by adjusting the distribution of the original code, can stably generate more realistic instruction data and control the diversity of the data.
To address the above challenges, researchers classified instruction instances into 4 general code-related tasks: code summarization, code generation, code translation, and code repair.
At the same time, using data generation strategies, they generated a dataset of 20,000 instruction instances for the 4 code-related tasks, called CodeOcean.
To validate the latest method, researchers used StarCoder, CodeLLaMa, and DeepseekCoder as base models and fine-tuned a brand-new WaveCoder model based on the latest data generation strategy.
At the same time, researchers evaluated the model on HumanEval, MBPP, and HumanEvalPack, and the results show that WaveCoder has excellent performance on small-scale instruction tuning benchmarks.
Code Data Generation
As mentioned above, researchers selected 4 representative coding tasks and collected original code from open-source datasets.
The training data generation process is specifically described below.
In this section, we will introduce the details of the methods we explored. We first selected 4 representative coding tasks and collected original code from open-source datasets.
For each task, the authors used GPT-3.5-turbo to generate instruction data for fine-tuning. The generation prompts are shown in Table 2.

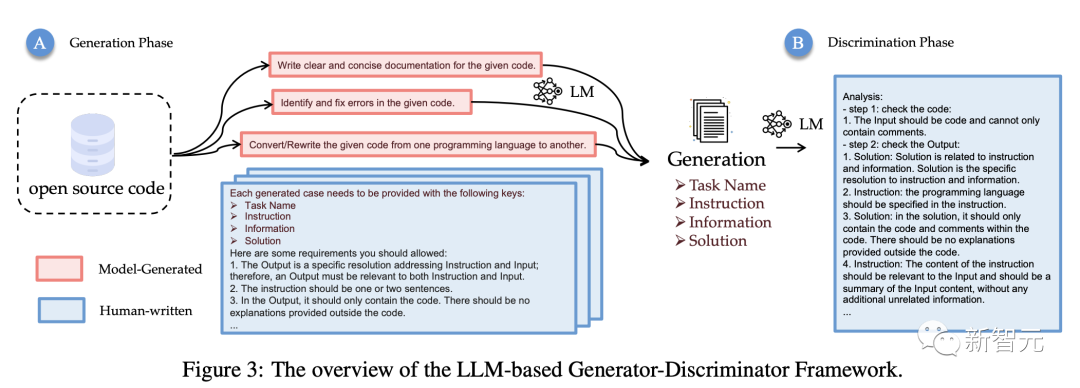
Below is the overall architecture of LLM Generator-Discriminator, which is also the complete process of data generation.
Codesearchnet is a dataset containing 2 million pairs of (comments, code) from open-source repositories hosted on GitHub. It includes code and documentation for 6 programming languages. We chose CodeSearchNet as our base dataset and applied the coreset-based selection method KCenterGreedy to maximize the diversity of the original code.
Specifically, the generator generates instruction data based on input (a). Subsequently, the discriminator accepts the output and generates analysis results, output (b) includes four keys, which the researchers use as input and output for instruction tuning.
The analysis (c) includes detailed reasons for each rule and the overall answer to check if the sample meets all requirements.

Experimental Evaluation Results
Code Generation Task Evaluation
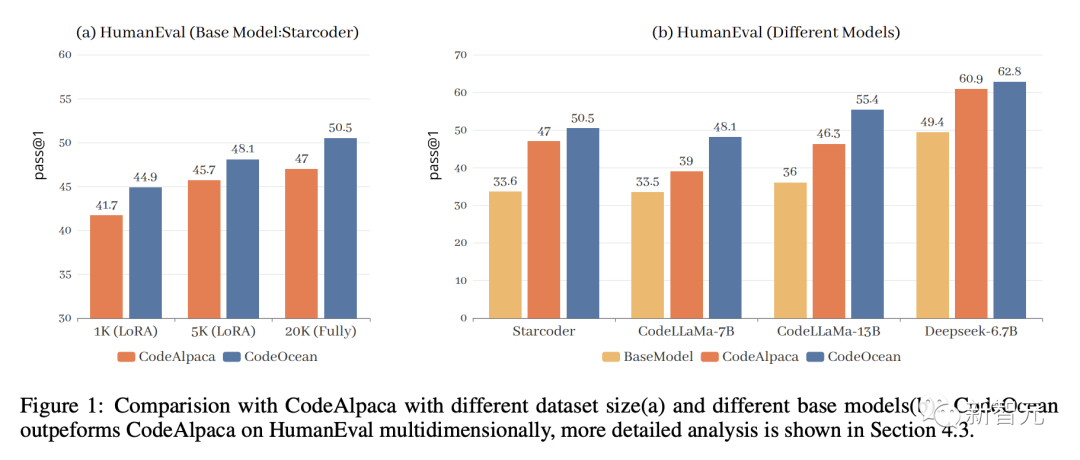
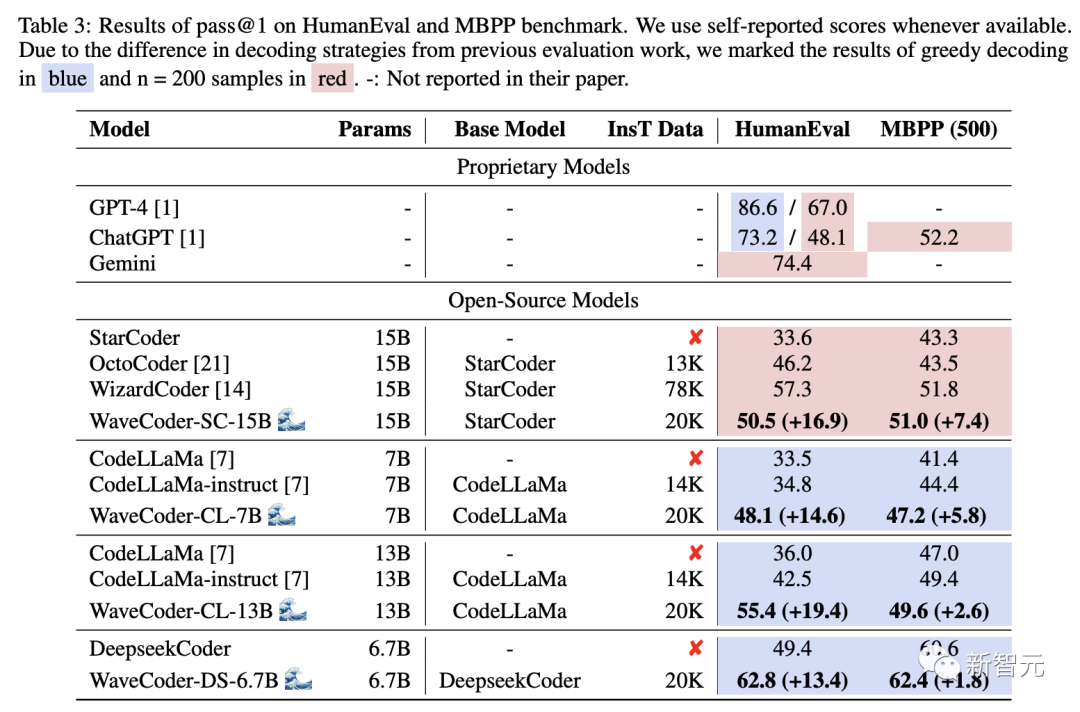
Table 3 shows the pass@1 scores of different large models on two benchmarks. From the results, we have the following observations:
WaveCoder significantly outperforms instruction models trained with less than 20k instruction tuning data (InsT Data).
After the fine-tuning process, the performance of the latest model shows substantial improvement compared to the base model and open-source models, but it still lags behind the guided model trained with over 70k training data.
The researchers also scored WaveCoder with the state-of-the-art Code LLM on HumanEvalPack, as shown in Table 4.
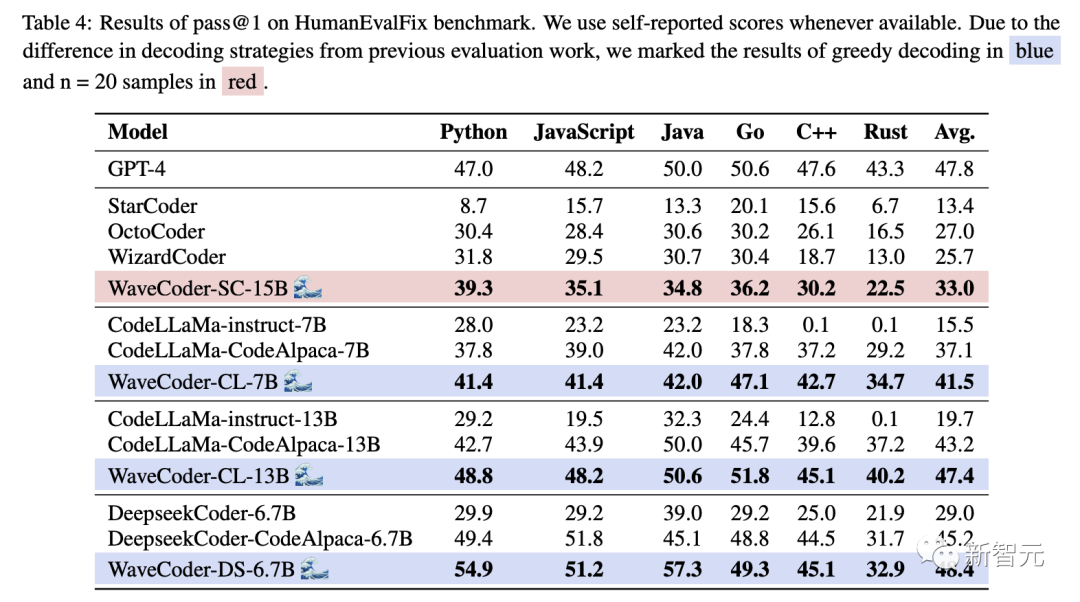
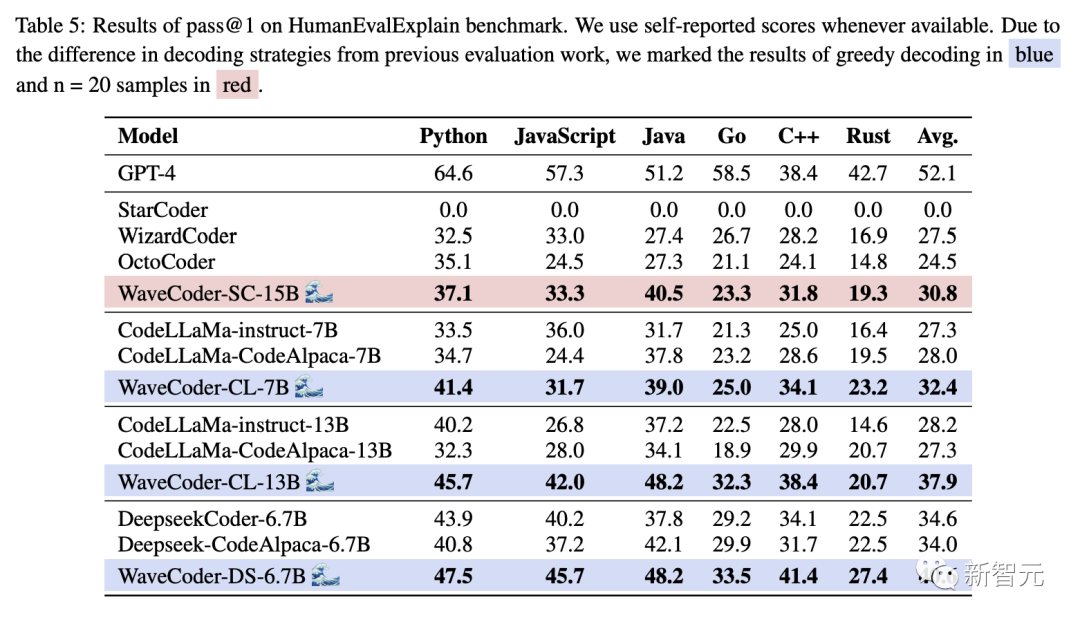
Table 5 lists the results of WaveCoder in the code summarization task, highlighting the following significant observations:
Reference:
https://arxiv.org/abs/2312.14187
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







