Article Source: Synced

Image Source: Generated by Wujie AI
Text-guided video-to-video (V2V) synthesis has a wide range of applications in various fields, such as short video creation and the broader film industry. While diffusion models have changed the way image-to-image (I2I) synthesis is done, they face challenges in maintaining temporal consistency between video frames in video-to-video (V2V) synthesis. Applying I2I models to videos often results in pixel flickering between frames.
To address this issue, researchers from the University of Texas at Austin and Meta GenAI have proposed a new V2V synthesis framework called FlowVid, which leverages both spatial conditions and temporal optical flow clues from the source video. Given an input video and a text prompt, FlowVid can synthesize temporally consistent videos.

- Paper Link: https://huggingface.co/papers/2312.17681
- Project Link: https://jeff-liangf.github.io/projects/flowvid/
In general, FlowVid demonstrates remarkable flexibility and can seamlessly collaborate with existing I2I models to accomplish various modifications, including stylization, object swapping, and local editing. In terms of synthesis efficiency, it only takes 1.5 minutes to generate a 4-second video at 30 FPS and 512×512 resolution, which is 3.1 times faster than CoDeF, 7.2 times faster than Rerender, and 10.5 times faster than TokenFlow, while ensuring high-quality synthesized videos.
Let's first take a look at the synthesis effects, for example, transforming the characters in a video into the form of "Greek sculptures":

Transforming a giant panda eating bamboo into the form of "Chinese painting," and then replacing the giant panda with a koala:

The scene of jumping rope can be smoothly transitioned, and the character can also be changed to Batman:

Method Overview
Some studies use flows to derive pixel correspondences, which are then used to obtain occlusion masks or construct canonical images between two frames. However, if the flow estimation is inaccurate, this hard constraint may lead to issues.
FlowVid first uses common I2I models to edit the first frame and then propagates these edits to subsequent frames, enabling the model to accomplish video synthesis tasks.
Specifically, FlowVid performs flow warping from the first frame to the subsequent frames. These warped frames will follow the structure of the original frame but contain some occluded areas (marked in gray), as shown in Figure 2 (b).

If flows are used as hard constraints, such as for fixing occluded areas, inaccuracies in estimation will persist. Therefore, the study attempts to introduce additional spatial conditions, such as the depth map in Figure 2 (c), and temporal flow conditions. The joint spatiotemporal conditions will correct imperfect flows, resulting in consistent results as shown in Figure 2 (d).
The researchers built a video diffusion model based on an inflated spatial control I2I model. They trained the model using spatial conditions (such as depth maps) and temporal conditions (flow-warped videos) to predict input videos.
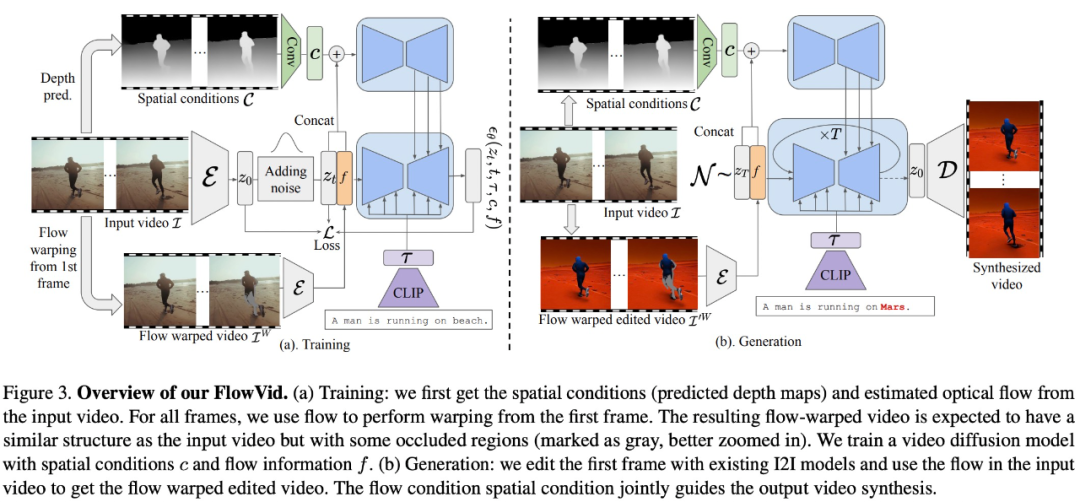
During the generation process, the researchers adopted an edit-propagate procedure: (1) edit the first frame with a popular I2I model. (2) Use the model in this paper to propagate the edited content throughout the entire video. The decoupled design allows them to adopt an autoregressive mechanism: the last frame of the current batch can be the first frame of the next batch, enabling the generation of lengthy videos.
Experiments and Results
Experimental Settings
The researchers used 100k videos from Shutterstock to train the model. For each training video, the researchers sampled 16 frames at intervals of {2,4,8}, representing videos with durations of {1,2,4} seconds (video FPS is 30). The resolution of all images was set to 512×512 through center cropping. The model was trained with a batch size of 1 on each GPU, using a total of 8 GPUs and a total batch size of 8. The experiments used the AdamW optimizer with a learning rate of 1e-5 and 100k iterations.
During the generation process, the researchers first used the trained model to generate keyframes and then used a ready-made frame interpolation model (such as RIFE) to generate non-keyframes. By default, 16 keyframes were generated at intervals of 4, equivalent to a 2-second segment at 8 FPS. Then, the researchers used RIFE to interpolate the results to 32 FPS. They adopted a classifier-guided scaling factor of 7.5 and used 20 inference sampling steps. Additionally, the researchers used a zero signal-to-noise ratio (Zero SNR) noise scheduler. They also fused self-attention features obtained from DDIM inversion on the corresponding keyframes in the input video, based on FateZero.
The researchers selected 25 object-centered videos from the publicly available DAVIS dataset, covering humans, animals, etc. For these videos, the researchers manually designed 115 prompts, ranging from stylization to object replacement. Additionally, they collected 50 Shutterstock videos and designed 200 prompts for these videos. The researchers conducted qualitative and quantitative comparisons on the above videos.
Qualitative Results
In Figure 5, the researchers qualitatively compared this paper's method with several representative methods. When there is a large amount of motion in the input video, the output results produced by CoDeF exhibit noticeable blurriness, as observed in areas such as the man's hand and the tiger's face. Rerender generally fails to capture large movements, such as the propeller blade movement in the left example. TokenFlow occasionally struggles to follow the prompts, for example, turning the man into a pirate in the left example. In comparison, this paper's method demonstrates advantages in editing capability and video quality.

Quantitative Results
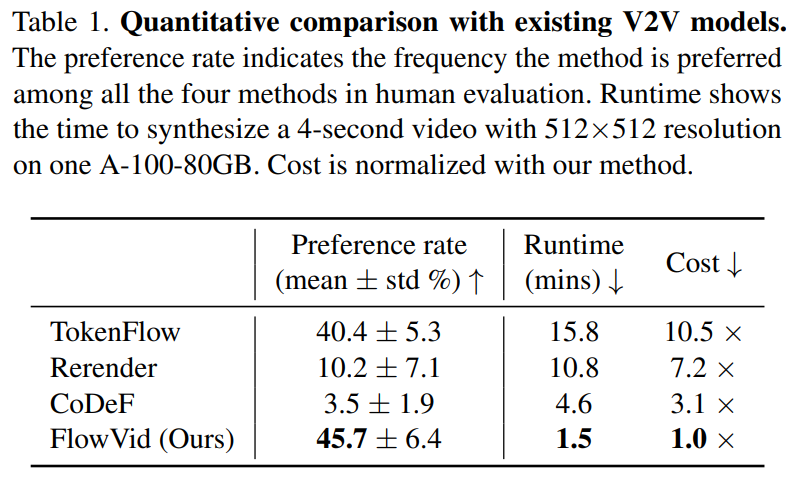
Researchers conducted a human evaluation to compare this paper's method with CoDeF, Rerender, and TokenFlow. Participants were shown four video clips and asked to identify which one had the best quality considering temporal consistency and text alignment. The detailed results are shown in the table. This paper's method achieved a preference of 45.7%, outperforming the other three methods. Table 1 also displays the pipeline runtime for each method, comparing their efficiency. This paper's method (1.5 minutes) is faster than CoDeF (4.6 minutes), Rerender (10.8 minutes), and TokenFlow (15.8 minutes), being 3.1 times, 7.2 times, and 10.5 times faster, respectively.
Ablation Experiments
Researchers combined four conditions for study as shown in Figure 6 (a): (I) Spatial control, such as depth map; (II) Flow-warped video, frames warped using optical flow from the first frame; (III) Flow occlusion mask indicating which parts are occluded (marked in white); (IV) First frame.

Figure 6 (b) evaluates the combinations of these conditions by assessing their effectiveness compared to the full model containing all four conditions. Due to the lack of temporal information, the win rate of pure spatial conditions is only 9%. After adding flow-warped videos, the win rate significantly increased to 38%, highlighting the importance of temporal guidance. The researchers used gray pixels to represent occluded areas, which may be confused with the original gray in the image. To avoid potential confusion, they further added binary flow occlusion masks to better help the model identify which parts are occluded. The win rate further increased to 42%. Finally, the researchers added the first frame condition to provide better texture guidance, which is particularly useful when there is a large occlusion mask and few original pixels remaining.
The researchers studied two types of spatial conditions in FlowVid: canny edges and depth maps. In the input frames shown in Figure 7 (a), it can be seen from the panda's eyes and mouth that canny edges preserve more details than depth maps. The strength of spatial control in turn affects video editing. During the evaluation process, the researchers found that canny edges work better when it is desired to preserve the structure of the input video as much as possible (e.g., stylization). If there is significant scene change, such as object swapping, and greater editing flexibility is needed, the effect of depth maps is better.
As shown in Figure 8, although ϵ-prediction is commonly used for parameterizing diffusion models, the researchers found that it may result in unnatural cross-frame global color shifts. Despite both methods using the same flow-warped videos, ϵ-prediction brings about unnatural dark colors. This phenomenon is also observed in image-to-video.

Limitations
While FlowVid has achieved significant performance, it also has some limitations. Firstly, FlowVid heavily relies on the generation of the first frame, which should structurally align with the input frame. As shown in Figure 9 (a), the edited first frame misidentifies the elephant's hind legs as the front trunk. This incorrect trunk will propagate to the next frame, resulting in suboptimal final predictions. Secondly, when the camera or objects move too fast, causing large areas of occlusion, FlowVid will guess the missing areas, even leading to illusions. As shown in Figure 9 (b), when the ballet dancer turns her body and head, the entire body part is occluded. FlowVid successfully handles the clothing but turns the back of the head into the front face, which would be quite eerie if shown in the video.

For more detailed content, please refer to the original paper.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。






