Source: New Smart Element

Image Source: Generated by Wujie AI
What happened in the open-source LLM community in 2023? Researchers from Hugging Face take you back to review and reacquaint with open-source LLM.
In 2023, the Large Language Model (LLM) has ignited the passion of almost everyone.
Now most people know what LLM is and what it can do.
People discuss its pros and cons, envision its future,
long for true AGI, and are a bit worried about their own fate.
The public debate about open source and closed source has also attracted a wide audience.
What happened in the open-source LLM community in 2023?

Next, let's follow Hugging Face researcher Clémentine Fourrier,
to review the ups and downs of open-source LLM this year.
How to train a large language model?
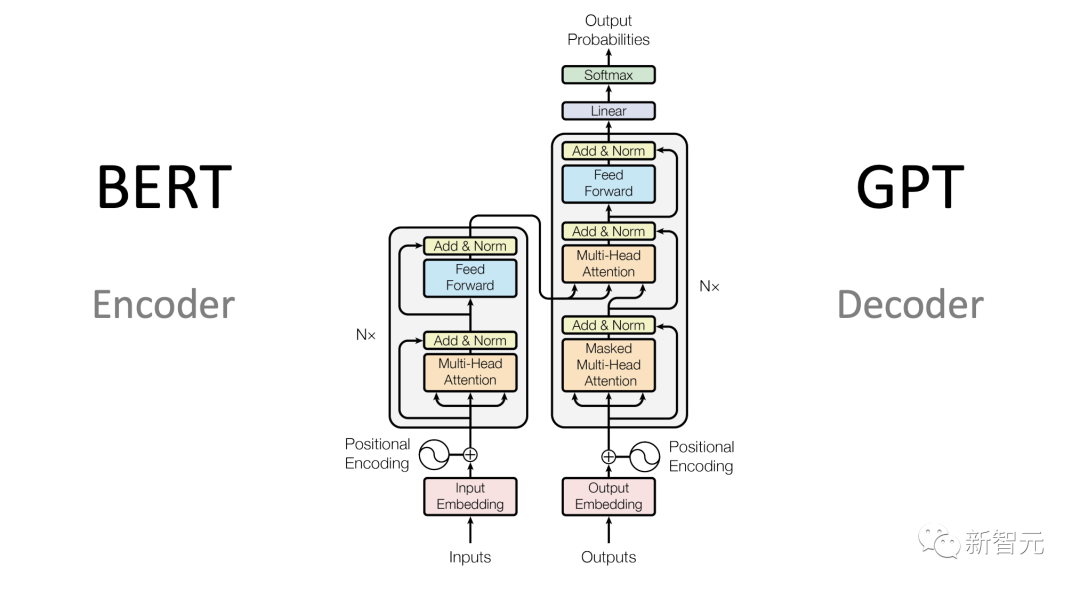
The model architecture of LLM describes the specific implementation and mathematical shape. The model is a list of all parameters and how the parameters interact with the input.
Currently, most high-performance LLMs are variants of the Transformer architecture.
The training dataset of LLM contains all the examples and documents needed to train the model.
In most cases, it is text data (natural language, programming language, or other structured data expressible as text).
The tokenizer defines how to convert the text in the training dataset into numbers (because the model is essentially a mathematical function).
The text is divided into subunits called tokens (which can be words, subwords, or characters).
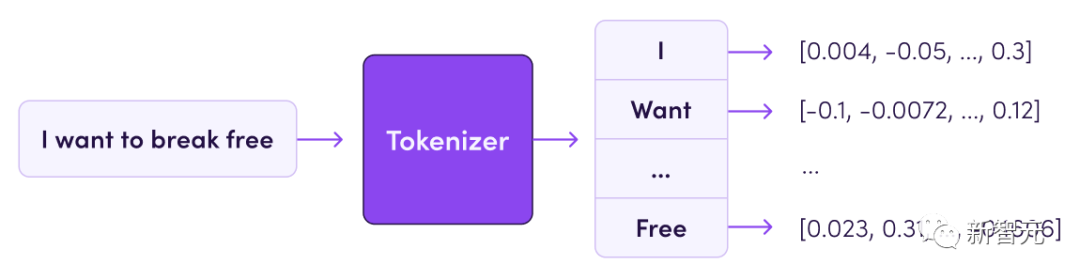
The vocabulary size of the tokenizer is usually between 32k and 200k, and the size of the dataset is usually measured by the number of tokens it contains, which can range from several billion to tens of trillions of tokens in today's datasets.
Then, use hyperparameters to define how to train the model—how much should the parameters change at each iteration? How fast should the model be updated?
Once these are sorted out, all that's left is: a lot of computing power and monitoring during the training process.
The training process involves instantiating the architecture (creating matrices on hardware) and running the training algorithm on the training dataset using hyperparameters.
The result is a set of model weights—this is the big model everyone is talking about.
These weights can be used for inference, predicting outputs for new inputs, generating text, etc.
The pre-trained LLM can also be adapted to specific tasks later through fine-tuning (especially for open-source models).
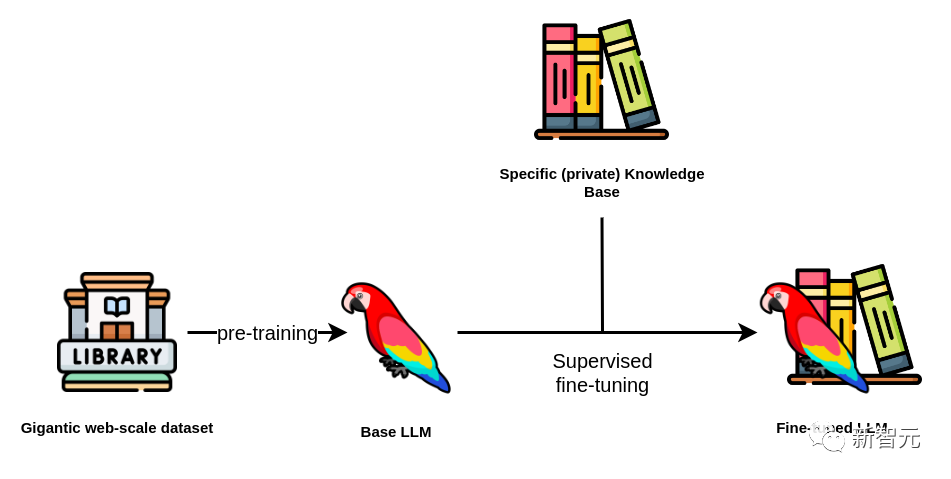
The fine-tuning process involves additional training steps on different datasets (usually more specialized and smaller) to optimize the model for specific applications.
Compared to training a large model from scratch, the cost of fine-tuning is obviously much lower—this is one of the reasons why open-source LLMs are popular.
From a scale competition to a data competition
Until early 2022, the trend in machine learning was that the larger the model, the better the performance.
And it seems that after surpassing a certain threshold, the ability of the model will leap—there are two words used to describe this phenomenon: emergent abilities and scaling laws.
Most of the pre-trained open-source models released in 2022 follow this paradigm, here are a few examples.
BLOOM (BigScience Large Open-science Open-access Multilingual Language Model) is a series of models released by BigScience, involving 1000 researchers from 60 countries and 250 institutions, in collaboration with Hugging Face and the French organizations GENCI and IDRIS. These models use decoder-only transformers and have undergone minor modifications.
The largest model in the series has 176B parameters, trained on a 350B training dataset, including 46 human languages and 13 programming languages, making it the largest open-source multilingual model to date.
The OPT (Open Pre-trained Transformer) series of models released by Meta follows the tricks in the GPT-3 paper (specific weight initialization, pre-normalization) and makes some changes to the attention mechanism (alternating dense and local banded attention layers).

The largest model in this series has 175B parameters and is trained on 180B data, mainly from books, social media, news, Wikipedia, and other information on the internet.
OPT's performance is comparable to GPT-3, using encoding optimizations to reduce computational intensity.
GLM-130B (General Language Model) is released by Tsinghua University and Zhipu.AI. It uses the complete transformer architecture and has made some changes (using DeepNorm for layer normalization, rotating embeddings).
GLM-130B is trained on 400B marked Chinese and English internet data (The Pile, Wudao Corpora, and other Chinese corpora), and its performance is also comparable to GPT-3.

In addition, there are some smaller or more specialized open-source LLMs mainly for research purposes.
For example, Meta's Galactica series; EleutherAI's GPT-NeoX-20B, etc.
Although it seems that the larger the model, the better the effect, it is also more expensive to run.
When performing inference, the model needs to be loaded into memory, and a model with 100B parameters usually requires 220GB of memory.
In March 2022, DeepMind published a paper studying the optimal ratio of the amount of data used for training to the model parameters given a computational budget.
In other words, if you only have a fixed amount of money to spend on model training, what should the model size and training data volume be?
The authors found that, overall, more resources should be allocated to training data.
Their own example is a 70B model called Chinchilla, trained on 1.4T of training data.
Open-source LLM in 2023
Model Explosion
Starting in 2023, a wave of models emerged, with new models being released every month, every week, or even every day:
LLaMA in February (Meta), Pythia in April (Eleuther AI), MPT (MosaicML) in April, X-GEN (Salesforce) and Falcon (TIIUAE) in May, Llama 2 (Meta) in July, Qwen (Alibaba) and Mistral (Mistral.AI) in September, Yi (01-ai) in November, and DeciLM (Deci), Phi-2 (Microsoft), and SOLAR (Upstage) in December.
In Meta AI's LLaMA series, researchers aimed to train a set of models of different sizes that could achieve optimal performance within a given budget.
They explicitly proposed to consider not only the training budget but also the inference cost, in order to achieve higher performance on smaller model sizes (balancing training computational efficiency).
The largest model in the Llama 1 series is a 65B parameter model trained on 1.4T data, while the smaller models (6B and 13B) are trained on 1T data.

The small 13B LLaMA model outperforms GPT-3 in most benchmark tests, while the largest LLaMA model reached the SOTA at the time. However, LLaMA is released under a non-commercial license, limiting its community application.
Subsequently, MosaicML released the MPT model, with a license allowing commercial use and details of the training combination. The first MPT model is 7B, followed by a 30B version in June, both trained on 1T of English and code data.
Before this, the training data for the models was public, but the subsequent models no longer provide any information about the training—however, at least the weights are open source.
Ubiquitous Conversational Models
Compared to 2022, almost all pre-trained models released in 2023 come with pre-trained versions and conversational fine-tuning versions.
The public is increasingly using these chat models and conducting various evaluations, and can also fine-tune the models through chat.
Instruction fine-tuning (IFT) uses instruction datasets containing a set of prompts and answers. These datasets teach the model how to follow instructions, which can be human-generated or LLM-generated.
Using LLM output as a synthetic dataset is one way to fine-tune for instruction and chat, often referred to as distillation, which involves extracting knowledge from high-performance models to train or fine-tune smaller models.
Both of these methods are relatively easy to implement: simply look up or generate relevant datasets and then fine-tune the model using the same techniques as during training.
Reinforcement Learning from Human Feedback (RLHF) is a specific method aimed at adjusting the content of model predictions to align with human preferences.
Given prompts, the model generates several possible answers, and humans rank these answers, which are used to train the so-called preference model, and then the preference model is used to fine-tune the language model through reinforcement learning.
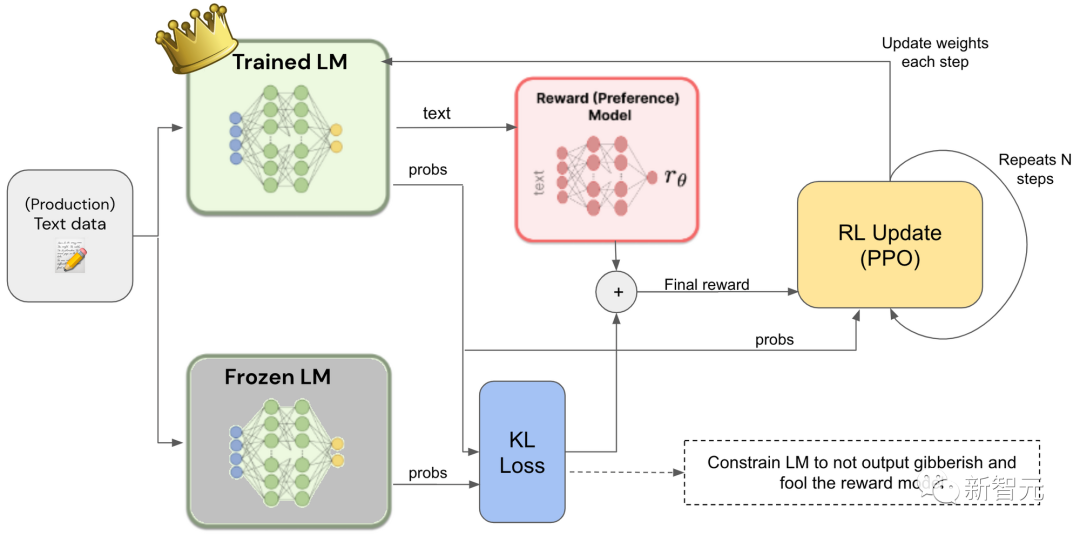
This is a costly method mainly used to adjust models to achieve safety goals.
A lower-cost variant was later developed, using high-quality LLM to rank model outputs, known as Reinforcement Learning from AI Feedback (RLAIF).
Direct Preference Optimization (DPO) is another variant of RLHF that does not require training and using a separate preference model.
DPO updates the model directly by examining the difference between the original policy and the best policy based on ranking data provided by humans or AI.
This makes the optimization process much simpler while achieving almost the same final performance.
What is the Community Doing?
In early 2023, some datasets for teaching or chat fine-tuning have been released.
For human preference, examples include OpenAI's WebGPT dataset, Anthropic's HH-RLHF dataset, and OpenAI's Summarize.
Examples of instruction datasets include BigScience's Public Pool of Prompts, Google's FLAN 1 and 2, AllenAI's Natural Instructions, Self Instruct (a framework for automatically generating instructions by researchers with different affiliations), SuperNatural Instructions (instruction benchmarks created by expert fine-tuning data), Unnatural Instructions, and more.

In January, Chinese researchers released the Human ChatGPT Instruction Corpus (HC3), containing human and model answers to various questions.
In March, Stanford University released Alpaca, the first instruction-following LLaMA model (7B), including a related dataset (52K instructions generated using LLM).
LAION (a non-profit open-source lab) released the Open Instruction Generalist (OIG) dataset, which contains 43M instructions, created with data augmentation and compiled from other pre-existing data sources.
In the same month, the LMSYS organization (University of California, Berkeley) released Vicuna, also a LLaMA fine-tuning (13B), this time using chat data—conversations between users and ChatGPT publicly shared by users on ShareGPT.
In April, BAIR (Berkeley Artificial Intelligence Research Lab) released Koala, a chat fine-tuning LLaMA model, using several previous datasets (Alpaca, HH-RLHF, WebGPT, ShareGPT), and DataBricks released the Dolly dataset, containing 15K manually generated instructions.
In May, Tsinghua University released UltraChat, a dataset containing 1.5M dialogue pairs with instructions, and UltraLLaMA, a fine-tuning on this dataset.
Microsoft subsequently released the GPT4-LLM dataset for generating instructions using GPT4.
In June, Microsoft Research shared a new method called Orca, which constructs instruction datasets (explaining their step-by-step reasoning) using the inference traces of large models.
The community used this method to create the Open Orca dataset, with millions of entries, and it has been used to fine-tune many models (Llama, Mistral, etc.).
In August, the Chinese non-profit organization OpenBMB released UltraLM (high-performance chat fine-tuning for LLaMA).
In September, they released the related preference dataset UltraFeedback, which is an input feedback dataset compared by GPT4 (with annotations).
In addition, a student team from Tsinghua University released OpenChat, an LLaMA fine-tuning model using a new RL fine-tuning strategy.
In October, Hugging Face released Zephyr, a Mistral fine-tuning using DPO and AIF on UltraChat and UltraFeedback, and Lmsys released LMSYS-Chat-1M, which involves real user conversations with 25 LLMs.
In November, NVIDIA released HelpSteer, a fine-tuning dataset alignment that provides prompts, relevant model responses, and ranked answers based on several criteria, while Microsoft Research released the Orca-2 model, a fine-tuning on the new synthetic reasoning dataset for Llama 2.
Development Approach
Merging: Ultimate Customization
In the typical open-source manner, one of the community's milestones is model or data merging.
Model merging is a method of combining the weights of different models into a single model to integrate the respective advantages of each model into a unified single model.
One of the simplest methods is to average the parameters of a group of models sharing a common architecture—however, more complex parameter combinations need to be considered, such as determining which parameters have the greatest impact on a given task (weighted average), or considering parameter interference between models during merging (parallel merging).
These technologies allow anyone to easily generate model combinations, and because most models are now variants of the same architecture, it has become particularly easy.
This is why some models on the LLM leaderboard have strange names (such as llama2-zephyr-orca-ultra—indicating a merge of the llama2 and zephyr models, fine-tuned on the orca and ultra datasets).
PEFT: Personalization at Your Fingertips
Sometimes, you may not have enough memory to load the entire model for fine-tuning. In fact, fine-tuning does not always require the use of the entire model.
With Parameter-Efficient Fine-Tuning (PEFT), a portion of the pre-trained model's parameters is first fixed, and then many new parameters called adapters are added on top of it.
Then, only the (lightweight) adapter weights used for fine-tuning the task are much smaller than the original model.
Quantization: Models Everywhere
High-performance large models require a large amount of memory at runtime, for example, a 30B parameter model may require over 66G of RAM to load, which most individual developers may not have enough hardware resources for.
One solution is quantization, which reduces the size of the model by changing the precision of the model parameters.
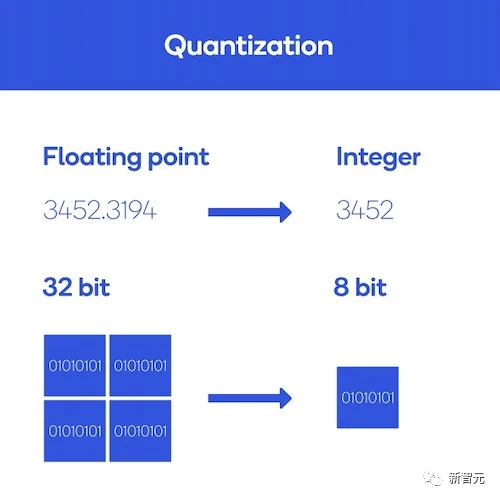
In computing, numbers are stored with a given precision (such as float32, float16, int8, etc.).
Precision indicates both the type of number (whether it is a floating-point or integer) and the amount of memory the number occupies: float32 stores floating-point numbers in a 32-bit memory space. The higher the precision, the more physical memory the number occupies.
Therefore, reducing precision reduces the memory occupied by each model parameter, thereby reducing the model size, and also means that the actual precision of the calculations can be reduced.
The performance degradation caused by this loss of precision is actually very limited.
There are many methods for transitioning from one precision to another, each with its own advantages and disadvantages. Common methods include bitsandbytes, GPTQ, and AWQ.
Reference: https://huggingface.co/blog/2023-in-llms
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。








