"Anthropic Claude2.1 has already reduced the probability of hallucinations by 50%, but in terms of implementation principles, the model design is meant to generate, so it will definitely talk nonsense." "Hallucinations are not an isolated problem. They are not only related to the model structure, but also to the data and training methods. Only when all factors are combined can the problem of hallucinations be effectively alleviated. However, I think it's difficult to fundamentally solve hallucinations, as they still belong to probabilistic models at this stage." "Hallucinations can be reduced by using effective prompts. However, prompts from users may sometimes be misleading or malicious, so semantic understanding and rewriting need to be provided at the application level. It is also possible to establish corresponding security mechanisms to exclude malicious inducements." "Nowadays, there are retrieval-enhanced RAG, fine-tuning, as well as tools for controlling output and input, all of which help reduce hallucinations. Service providers also need long-term AI engineering experience to do this."
Source: Titanium Media APP
Author: Yang Li

Image Source: Generated by Wujie AI
Recently, Titanium Media has found in communication with a large number of AI practitioners that the phenomenon of hallucinations in large models has become a serious defect that hinders enterprise applications, making it difficult to use large models in practical applications.
At the end of 2022, the appearance of ChatGPT as an automated interactive chatbot inspired the industry, leading to subsequent trains of thought in the field of natural language processing.
However, what was initially overlooked by the outside world is that this chatbot was originally named ELIZA, with the purpose of simulating a psychotherapist, by receiving user input (this process is called "understanding user intent") and then cleverly outputting replies that keep the user engaged.
However, due to the fact that the training corpus of large language models (LLM) comes from massive data sources such as the internet, books, and articles, although the chatbot has demonstrated relatively high contextual understanding ability, its limitations have been present since its inception: limited to corpus knowledge, and often generating results that are inconsistent with facts or baseless, and even fabricating some references, inadvertently spreading incorrect information. The core issue lies in the fact that large models themselves are black boxes, based on statistical logic, and will generate results that are as consistent as possible with the context's grammar and semantics, while also incorporating prompt engineering and learning instruction data.
Even the most advanced AI models are prone to lying
Researchers at OpenAI pointed out in a recent report that even the most advanced AI models are prone to lying, and they often tend to fabricate facts at uncertain times. This is particularly serious in fields that require multi-step reasoning, as a logical error is enough to affect the entire process.
A notorious example is Google Bard's statement about the Webb Telescope.
When asked "Can you tell a 9-year-old child about any new discoveries about the Webb Telescope?" Google Bard's response was: "The Webb Telescope took the first photo of an exoplanet outside the solar system."
In fact, this response is incorrect. According to NASA, the first image of an exoplanet was taken in 2004, and the Webb Telescope was not launched until 2021.
Titanium Media extracted the classification descriptions of hallucinations from TechTarget, which currently mainly include the following categories:
- Contradictory sentences.
⠀Prompt: "Use a four-character sentence to describe the scenery."
Output: "The grass was green. The mountains were blue. The river was purple. The grass was brown."
- Contradiction with the prompt. The sentence contradicts the prompt word that generated the sentence.
⠀Prompt: "Write a birthday card for my niece."
Output: "Happy anniversary, Mom and Dad!"
- Contradiction with facts. Presenting fictional information as facts.
⠀Prompt: "Name three cities in the United States."
Output: "New York, Los Angeles, Toronto."
- Irrelevance or randomness. Generating random information unrelated to the input or output.
⠀Prompt: "Please describe London."
Output: "London is a city in the UK. Cats need to be fed at least once a day."
It is worth mentioning that the difficulty of generative AI lies not only in text generation, but also in the field of image generation from the beginning.
Countering AI hallucinations began with GAN
Around 2017, the most widely used algorithm for GenAI was not GPT, but Generative Adversarial Networks (GAN). It pits two neural networks against each other to generate images that are closer to human reality from a given training dataset. The scenes you saw back then, such as generating cartoon faces/expressions, human body postures, landscape synthesis, and old photo restoration, all used different variants of GAN.
However, this algorithm has a problem. Since it generates content based on the given dataset, the generated content will only imitate and cannot truly break through to be infinitely close to reality.
The shortcomings of GAN were overcome by the later diffusion model. Its principle is similar to removing noise from photos, by learning the denoising process to understand how a meaningful image is generated. Therefore, the images generated by the Diffusion model have higher precision compared to the GAN model, and are more in line with human visual and aesthetic logic. With the accumulation of sample quantity and deep learning time, the model has shown better imitation ability of artistic styles.
From Disco Diffusion to the popular Stable Diffusion, DALL-E2, MidJourney in 2023, they are all typical representatives of applications for generating images from text, based on the transformation of Diffusion.
Recently, OpenAI proposed a new strategy to counter AI "hallucinations," which is to reward each correct reasoning step, rather than simply rewarding the correct final answer. This method is called "process supervision" and aims to manipulate the model's prompt decomposition into steps.
There are several factors that lead to AI models producing hallucinations, including biased training data, insufficient training data, overfitting of training data, limited contextual understanding, and lack of domain knowledge.
In fact, solving the problem of hallucinations in large models has always been a prominent issue. Titanium Media has summarized the different solutions currently being applied or developed by enterprises:
- Data augmentation
Starting from the source, most companies are attempting to improve training data. This is because the quality of data, including biased or erroneous information in the source data, or insufficient training data, can lead to limited understanding of the data accessed by the model, resulting in hallucinations. High-quality training data or the addition of domain knowledge can help prevent the generation of inaccurate or misleading results.
- Enhanced user understanding
At the same time, there is a lack of understanding of the context. If the input prompts are unclear, inconsistent, or described with contradictions, it may also produce content that is disconnected from the context or irrelevant. Users can continue to improve by using clear and specific prompts, as well as multi-shot prompts, providing the desired output format or context examples, further guiding the model to achieve the expected results, or by increasing filtering and ranking strategies, adjusting parameters, and controlling the randomness of output results.
- Retrieval enhancement
The knowledge required by large models cannot only be obtained at the user prompt stage. Traditionally, AI neural networks adapt to specific contextual scenes or proprietary domain information through fine-tuning models. Although fine-tuning techniques based on instruction data are very effective, they consume a lot of computation and require matching real-time professional knowledge to adapt to changing outputs, which is not very flexible.
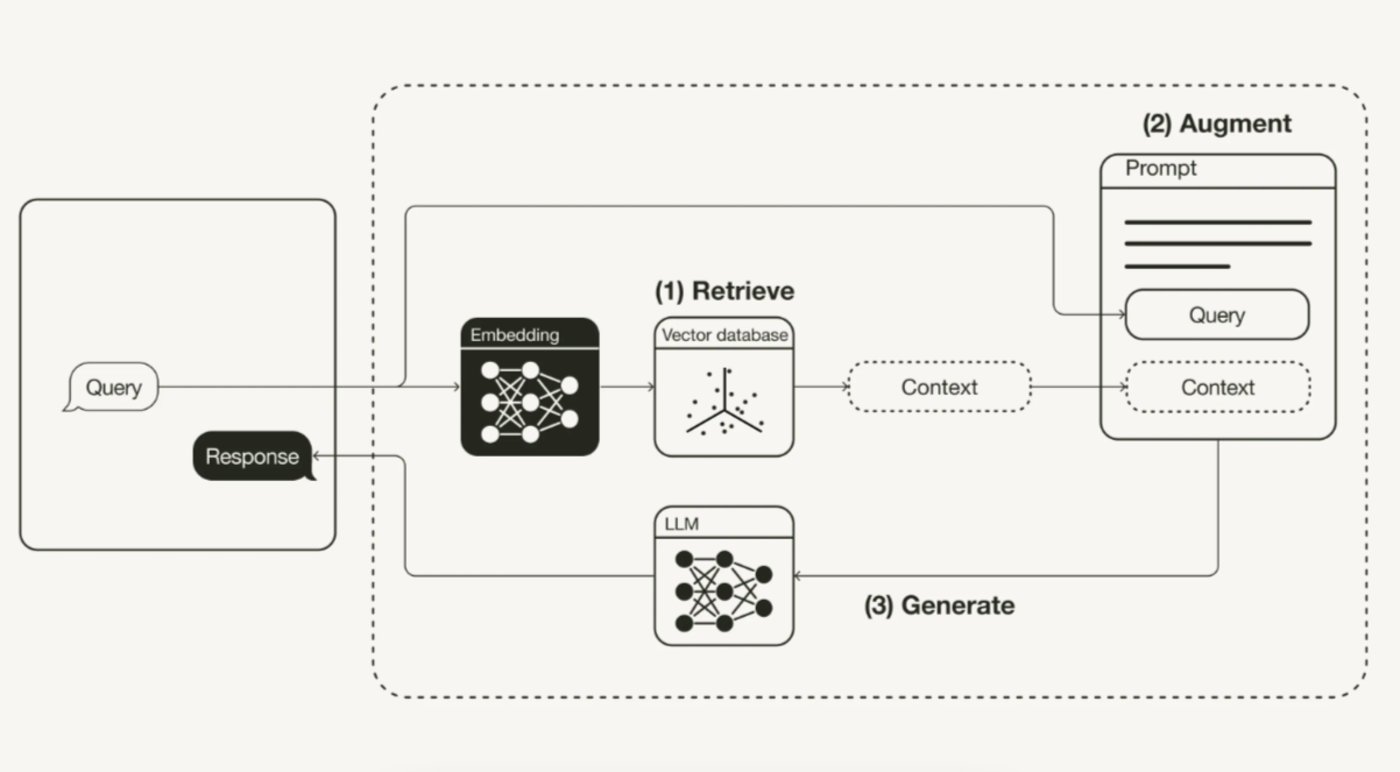
In 2020, researchers in the Natural Language Processing department of Facebook AI, led by Lewis, proposed Retrieval-Augmented Generation (RAG) in a paper, which combines the generator with an external knowledge base using a retriever to make real-time information more easily accessible. This process does not affect the underlying model's reasoning ability, and the knowledge acquired during training is saved in the neural network weights, while some non-parameterized knowledge is stored in vector databases and other external knowledge bases.
To use a more illustrative analogy, it's like allowing a large model to take an open-book exam, where it can bring textbooks, notes, and other reference materials to look up relevant information for answers. The concept of an open-book exam is to focus on testing the students' reasoning ability rather than their ability to memorize specific information. The information that users query and retrieve is also filled into the prompt template to provide a stronger contextual answer.
Industry practice of large models takes the lead
It is worth noting that large models have already entered some traditional industries, including the industrial manufacturing sector. Regardless of the lack of preparation in the data foundation and application scenarios of the manufacturing industry, due to the high requirements for decision explanation and interpretability in the manufacturing industry, especially in key decision-making and quality control, large models are often considered black box models, making it difficult to explain their decision-making process and reasoning logic. This may not meet the requirements of the manufacturing industry.
A recent practice shared by a global enterprise in the field of power automation is to combine operations research with deep learning. In the intelligent scheduling process, not only algorithms for operations optimization solvers are used, but also some heuristic algorithms. Optimization problems are solved by using deep learning to find an initial solution, which is then given to the solver to find a precise solution.
Constrained by the basic model, large models cannot self-diagnose errors, and the problem of hallucinations cannot be fundamentally eliminated at present. However, the industry's attempts have already indicated that the growth of artificial intelligence applications also requires finding scenarios first and then adjusting the models based on the development of technology.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







