Original Source: AIGC Open Community

Image Source: Generated by Wujie AI
Researchers from the University of California, Berkeley, Toyo University, Tokyo Institute of Technology, Massachusetts Institute of Technology, and Tsukuba University jointly open-sourced an innovative real-time interactive image generation framework - Stream Diffusion.
The technical innovation of Stream Diffusion lies in transforming traditional sequential denoising into stream batch processing denoising, eliminating long waits and interactive generation methods, and achieving a smooth and high-throughput image generation method.
It also introduces the "residual classifier-free guidance" method, further improving the efficiency and image quality of stream batch processing.
According to the project submission history of Stream Diffusion on Github, it took only 8 days to receive 6100 stars and become a popular open-source product, demonstrating its performance and popularity. It allows commercial use.
Open-source address: https://github.com/cumulo-autumn/StreamDiffusion
Paper address: https://arxiv.org/abs/2312.12491
Demo display: https://github.com/cumulo-autumn/StreamDiffusion/blob/main/assets/demo_03.gif
Currently, diffusion models have been widely used in image generation and have successfully achieved commercialization, such as the benchmark product Midjourney in this field.
However, they perform poorly in real-time interaction and require long waits, especially in scenarios involving continuous input.
To solve these problems, researchers have designed a novel output and input method, which is to transform the original sequential denoising into batch denoising process.
In simple terms, Stream Diffusion is equivalent to mechanized assembly line work in the large model field, replacing the single and tedious denoising and reasoning process with batch processing.
Stream Batch Denoising Method
Stream batch denoising is one of the core functions of Stream Diffusion and is the key to achieving real-time interaction.
Traditional interactive diffusion models are executed sequentially: one image is input at a time, and after completing all denoising steps, an output image is generated. This process is then repeated to generate more image processing.
This creates a major problem where speed and quality are difficult to guarantee simultaneously. To generate high-quality images, a large number of denoising steps need to be set, resulting in slow image generation efficiency, making it difficult to achieve both speed and quality.
The core idea of stream batch denoising is: when denoising the first image, there is no need to wait for it to complete before receiving the second image, enabling batch processing.
In this way, U-Net only needs to be continuously called to process a batch of features, efficiently achieving batch advancement of the image generation pipeline.
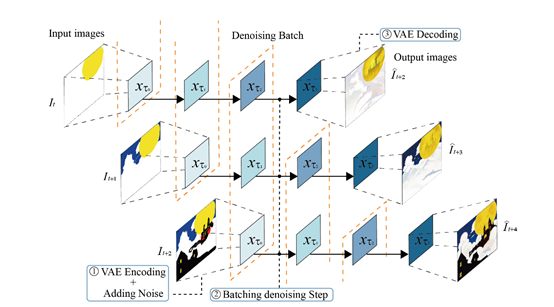
In addition, the benefit of the stream batch denoising method is that each call to U-Net can advance multiple images at the same time, and U-Net's batch operation is very suitable for GPU parallel computing, so the overall computing efficiency is very high.
Ultimately, it can significantly shorten the generation time of a single image while ensuring quality.
Residual Classifier-Free Guidance
To strengthen the influence of the prompting conditions on the results, diffusion models typically use a strategy called "classifier-free guidance".
In traditional methods, calculating the negative conditional vector requires pairing a negative conditional embedding with each input latent vector, and each inference requires a huge amount of U-Net computing power.
To solve this problem, researchers proposed the "residual classifier-free guidance" method. Its core method is to assume the existence of a "virtual residual noise" vector to approximate the negative conditional vector.
First, calculate the "positive condition" vector, and then use the positive condition vector to reverse infer this virtual negative condition vector. This avoids the need to call U-Net to calculate the real negative condition vector each time, thereby greatly reducing computing power.
In simple terms, it uses the original input image encoding as the negative sample, without the need to call U-Net for calculation. A slightly more complex "one-time negative condition" is to use U-Net to calculate a negative vector in the first step, and then use this vector to approximate all subsequent negative vectors.
Assembly Line Operation
The function of this module is to make the bottleneck of the entire system no longer the data format conversion, but the inference time based on the model itself.
Usually, the input image needs to be scaled, and the format needs to be converted for preprocessing to become a tensor that the model can use; the output tensor also needs to be post-processed to restore it to image format, consuming a lot of time and computing power in the entire process.
The assembly line operation completely separates the pre/post-processing from the model inference and executes them in different threads in parallel. The input image enters the input queue buffer after preprocessing;
The output tensor is sent from the output queue and then post-processed into an image. In this way, they do not need to wait for each other, optimizing the overall process speed.
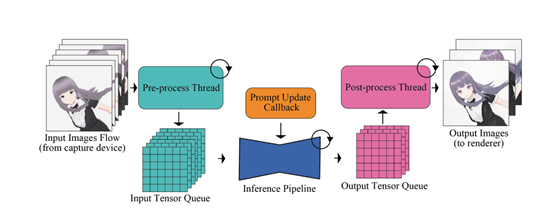
In addition, this method also serves to smooth the data flow. When the input source fails or communication errors temporarily prevent new images from being input, the queue can continue to provide previously cached images, ensuring the smooth operation of the model.
Random Similarity Filtering
The function of this module is to significantly reduce GPU computing power consumption. When the input images are continuously the same or highly similar, repeated inference is meaningless.
Therefore, the similarity filtering module calculates the similarity between the input image and the historical reference frame. If it exceeds the set threshold, it will skip the subsequent model inference with a certain probability;
If it is below the threshold, the model inference will proceed normally and update the reference frame. This probability sampling mechanism allows the filtering strategy to smoothly and naturally throttle the system, reducing the average GPU usage.

The filtering effect is significant under static input, and the filtering rate automatically decreases when there is a large dynamic change, allowing the system to adapt to dynamic scenes.
In this way, under continuous flow input with dynamically changing complexity, the system can automatically adjust the model's inference load, saving GPU computing power consumption.
Experimental Data
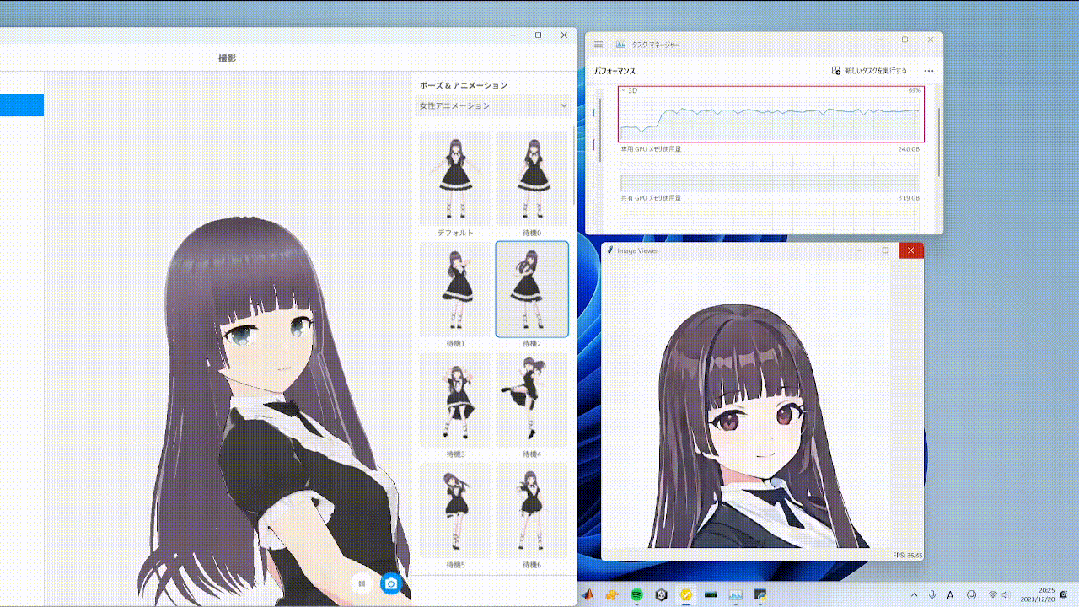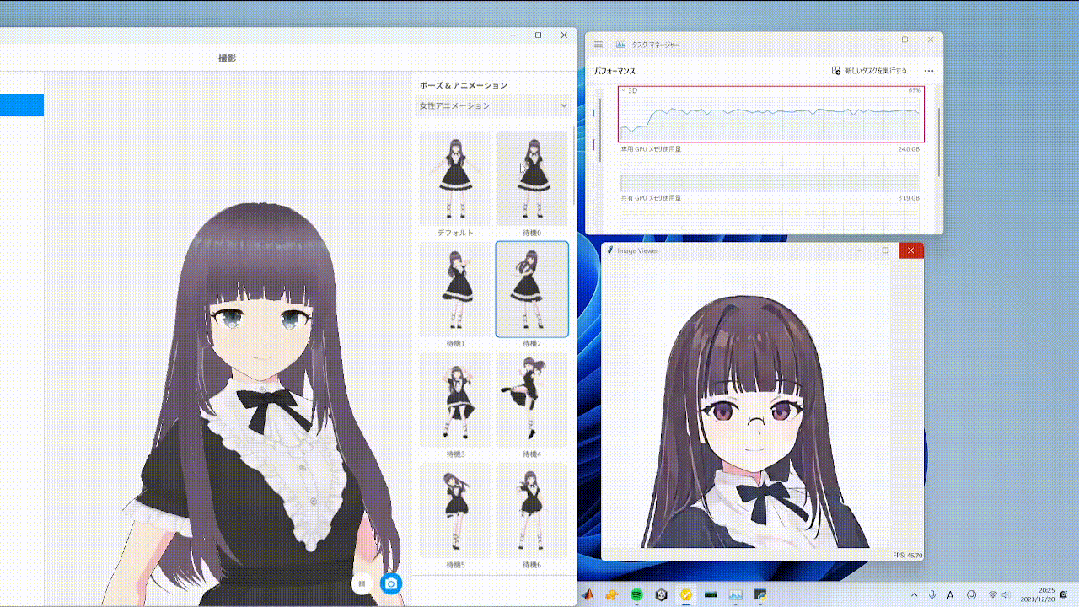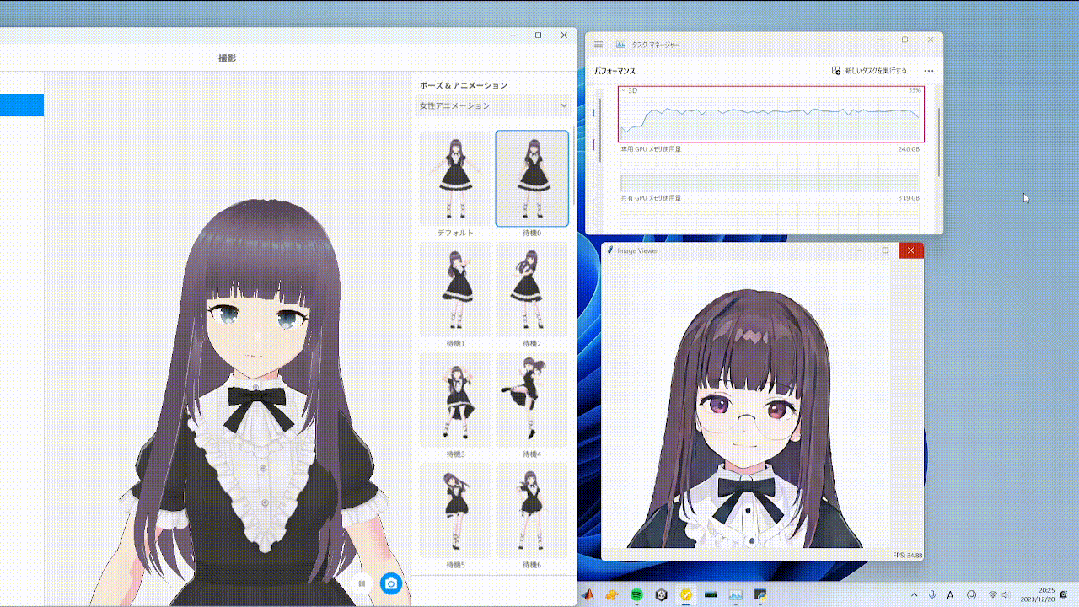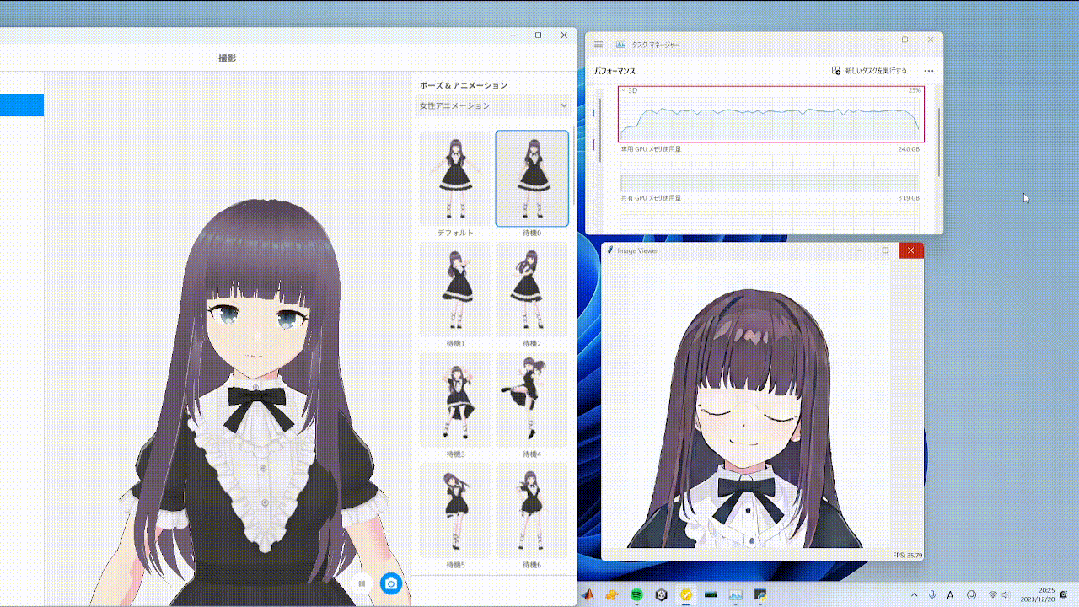
To test the performance of Stream Diffusion, researchers conducted tests on RTX3060 and RTX4090.
In terms of efficiency, it achieved a frame rate of over 91 FPS, which is nearly 60 times that of the most advanced AutoPipeline, and greatly reduced the denoising steps.
In terms of power consumption, under static input, the average power of RTX3060 and RTX4090 was reduced by 2.39 times and 1.99 times, respectively.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







