DePin, short for Decentralized Physical Infrastructure Networks, aims to utilize token incentives to encourage users to deploy hardware devices in order to provide real-world goods and services or digital resources such as computing power, storage, and network bandwidth. According to Messrai, the current valuation of the entire track is approximately around 9 billion US dollars, with an expected growth to a scale of 35 trillion US dollars by 2028.
There are also many projects that fit the concept of DePin, among which UtilityNet (referred to as Utility) is a prominent one that focuses on distributed AI computing power scheduling. After a year of development, Utility recently launched an AI container cloud testing platform based on TPU (AI-specific acceleration chip) and related smart computing servers. Interested AI developers can apply to participate in the testing of Utility's AI container cloud through the email address published on Utility's official Twitter account, in order to obtain a certain amount of AI cloud computing power for deploying and reasoning large models. The chips and devices behind this cloud computing power are provided by the Utility miners participating in the current closed testing period.
Utility has innovatively proposed a new Proof Of Computation Integrity (POCI) consensus mechanism, which is based on the security engine module inside the AI-specific chips and combines the principles of encryption on the chain, allowing the chips to self-prove and achieve the goal of obtaining incentives without consuming computing power. This is in contrast to the traditional Proof of Work (POW) consensus, which exhausts device computing power during the mining process, making it incompatible with the DePin concept. When computing power is consumed in mining, it cannot be circulated to the real demand side. Therefore, Utility's innovative POCI consensus mechanism provides a practical solution for the real circulation of computing power from miners to renters.
As an AI developer who has been following the Utility project for some time, I have applied through official channels and tried the beta version of the Utility AI container cloud. I will now share a trial report related to this.
Based on the decentralized mining incentive principle of Utility, the user interface of the Utility AI container cloud is designed with a miner management end and a chip user end, distinguishing different users and operating logics, allowing different types of users in the Utility AI container cloud platform to coordinate and cooperate excellently to achieve the circulation of computing power from miners to computing power renters.
I. Utility AI Container Cloud Miner Management End
1. Miner Management End Description
The Utility AI container cloud miner management end has an independent access entry page, and the current test version access address is https://cloud.utlab.io/admin/#/. The login page is as follows:
2. Platform Monitoring
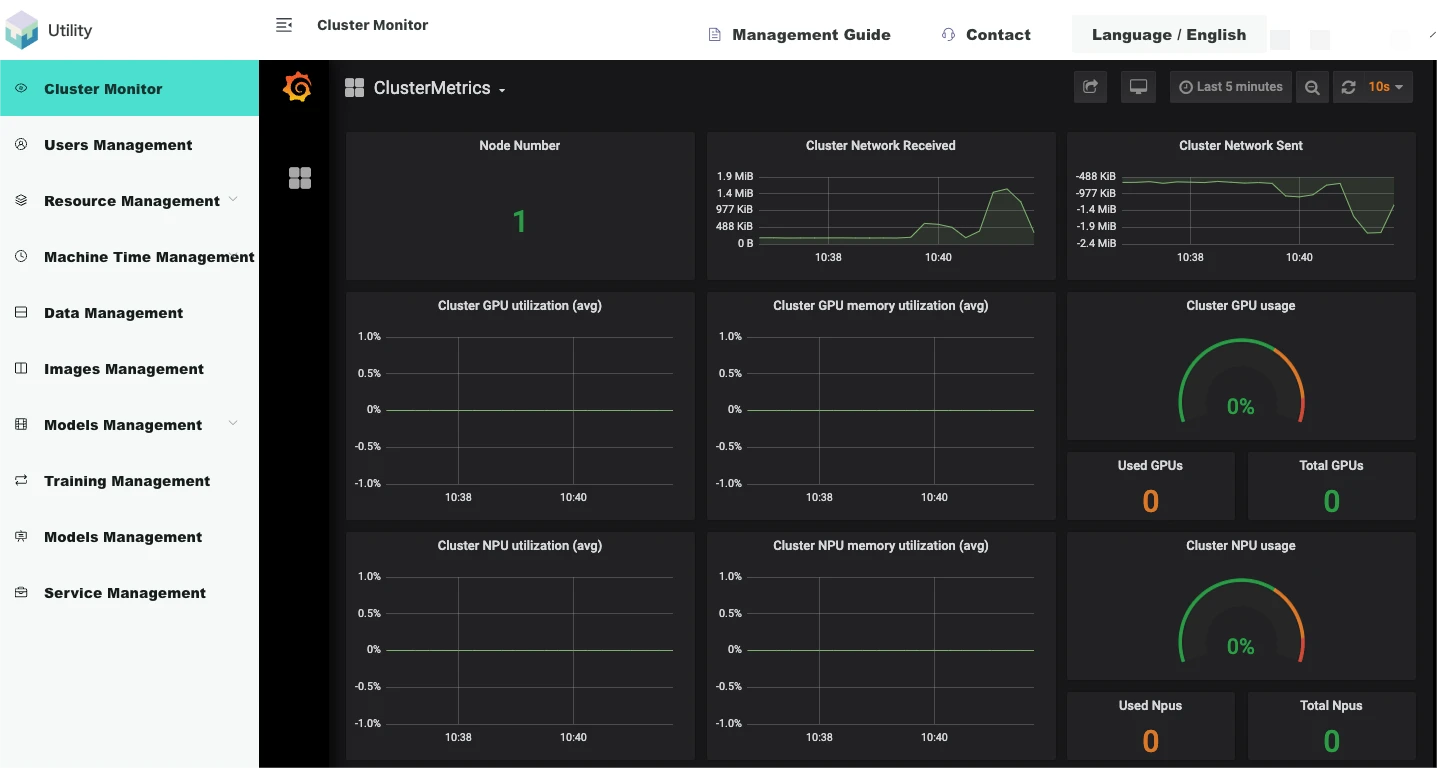
The monitoring architecture of the Utility AI container cloud consists of NodeExporter+Prometheus+Grafana, which is oriented towards cluster monitoring and training task monitoring, presented in the form of Grafana web pages. NodeExporter can collect various resource information and usage of nodes, and store it in the data format supported by Prometheus in local files. Prometheus, in a pull manner, aggregates the local data of NodeExporter services of each node into a central database. The Grafana web front-end service is configured with the API call path of Prometheus' database before startup, and can dynamically display the metrics data of the tasks running by all AI chip users in the cluster and platform to miners.
Cluster Monitoring
Cluster monitoring is embedded in the management end web page in the form of Grafana web pages.
As shown in the figure below, [Login to the management network end/Cluster monitoring] displays cluster information:
3. Resource Management
The Utility AI container cloud miner management end supports convenient management of platform hardware resources. The platform resource management module can be divided into server nodes, system resources, custom resources, resource specifications, and resource pools.
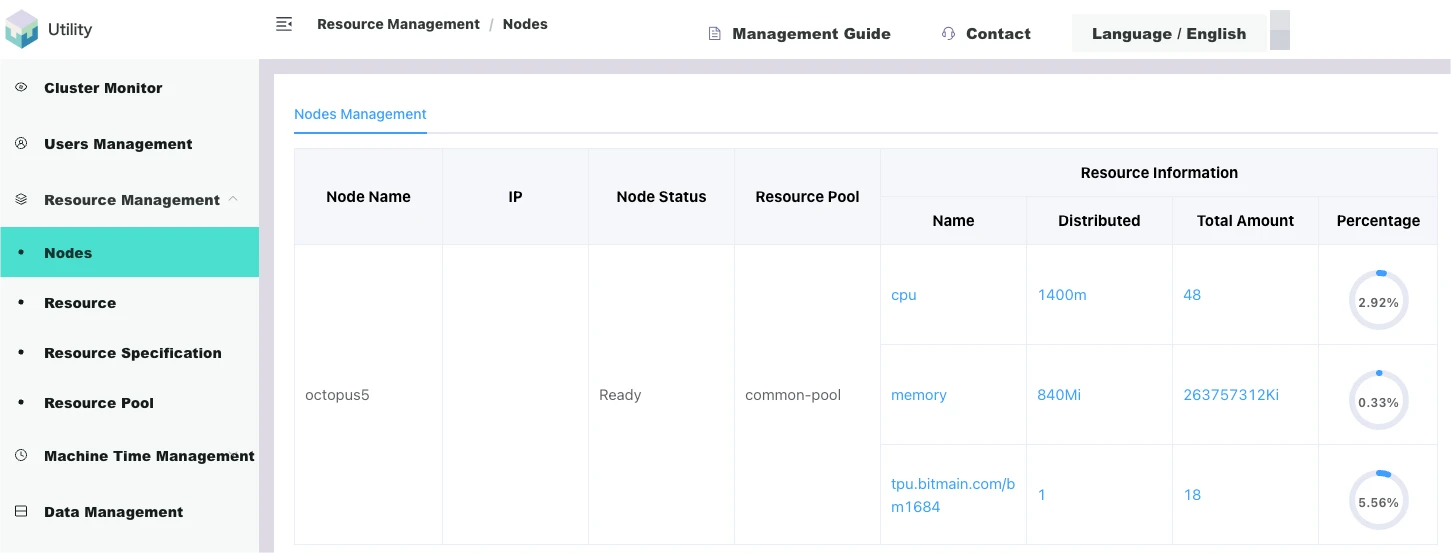
Nodes
Nodes refer to servers, and the underlying cluster system of the platform will automatically discover the servers that have formed the cluster when it starts, and discover their various attributes, such as IP, Hostname, assigned labels, readiness status, and details of resources possessed.
As shown in the figure below, [Login to the miner management end/Resource management/Nodes] displays the list of nodes automatically discovered by the system:
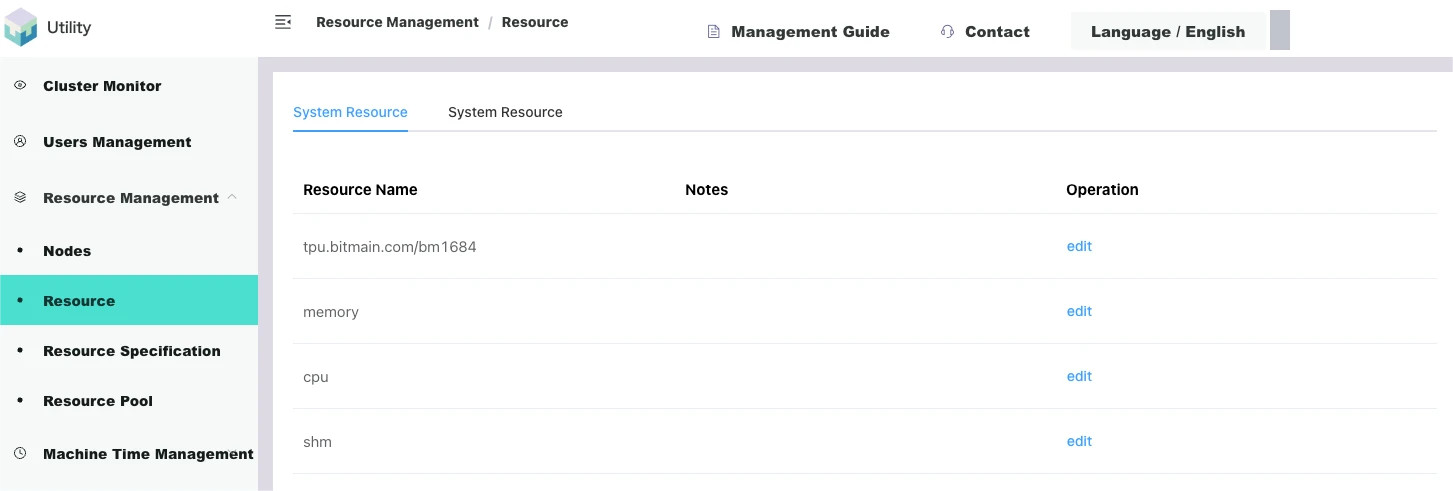
Resources
Physically, all resources are assembled on server nodes and automatically discovered by the platform system, which are system resources. System resources have various names and distinguishing forms, and can be logically divided according to various criteria.
As shown in the figure below, [Login to the miner management end/Resource management/Resources] displays the list of automatically discovered system resources:
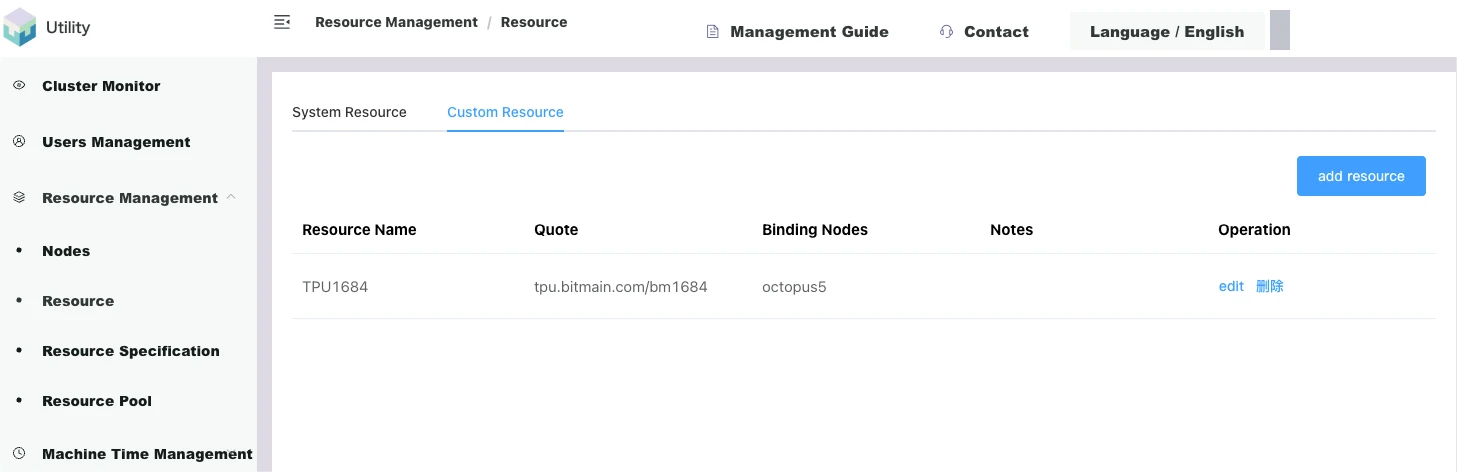
For ease of management, friendly display, and intuitive use, the platform has designed a custom resource function, allowing miners to redefine existing system resources as a new custom resource based on different logics.
As shown in the figure below, [Login to the miner management end/Resource management/Resources/Custom resources] can add custom resources such as TPU1684 or TPU1684X (1684 series is the name of the AI chip):
Resource Specifications
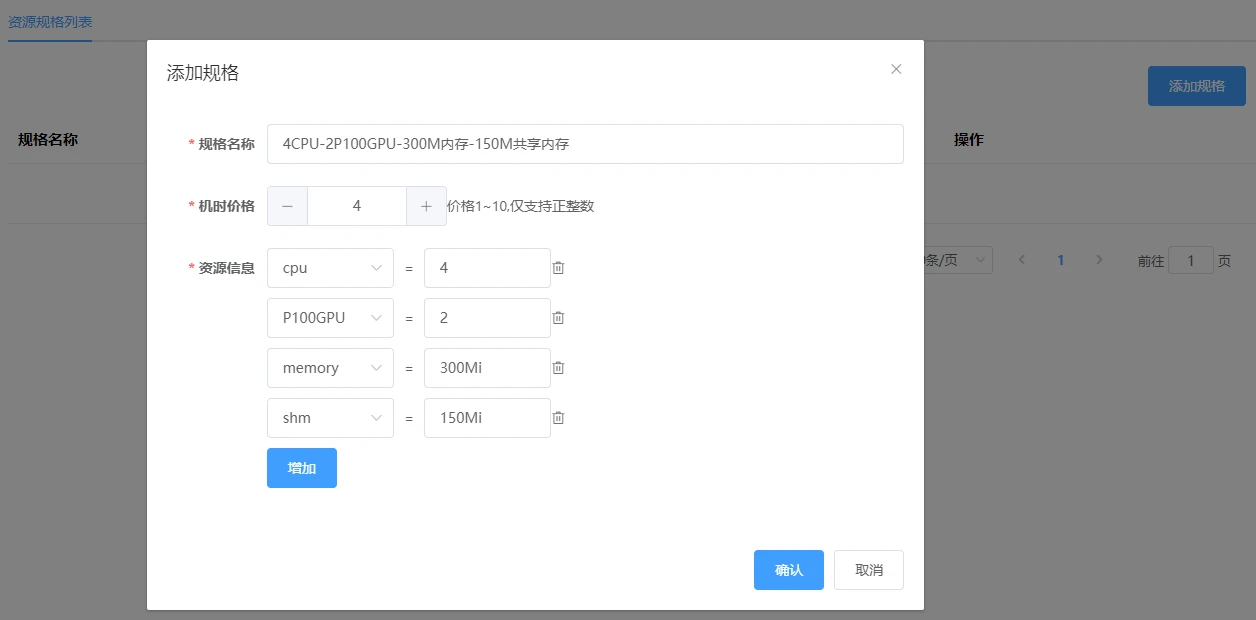
In order to better display the resources owned by the platform and better track the usage of resources by users, the platform groups different types of resources assembled on servers into one group, which is the function of resource specifications. Administrators define the names of resource specifications, and users can intuitively obtain information about resources from the names of resource specifications and select the resource group they want to use for running their tasks.
As shown in the figure below, [Login to the management web end/Resource management/Resource specifications] can create resource specifications for all resources (4CPU-2GB-2TPU1684):
Resource Pool
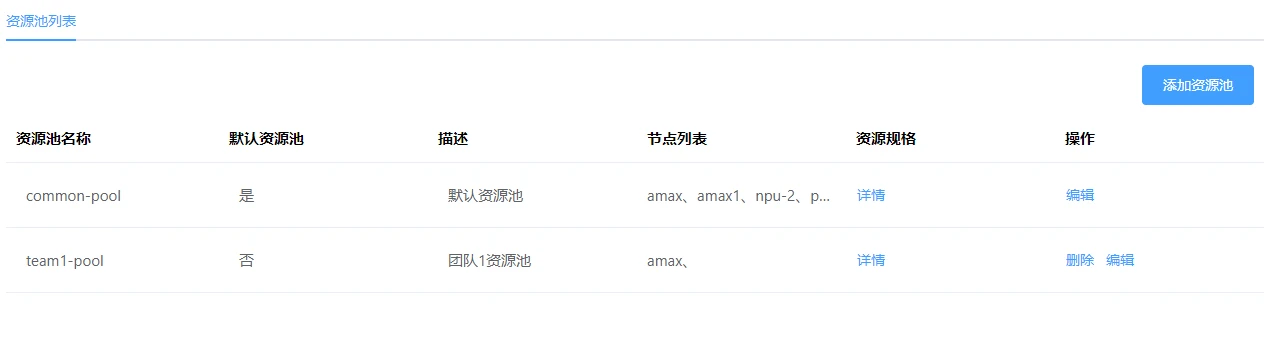
The resource pool is used to isolate the server resources of the cluster. Vertically, resources are granular at the level of server nodes. Horizontally, resources are granular at the level of resource specifications. Servers nodes are for administrators, while resource specifications are for users. Naturally, in order to better decouple and isolate resources from users, the concept of a resource pool is needed. The resource pool logically re-segments resources, and in the Utility AI container cloud, resources are divided into different resource pools as a whole in the form of server nodes, and different resource pools can be bound to user groups. In this way, the resources of the cluster can be well isolated, and different resources can be allocated to different user groups.
As shown in the figure below, [Login to the miner management end/Resource management/Resource pool], the system's default resource pool initializes with all resource nodes, and new resource pools can be created by clicking the button based on different business logics:
The miner management end supports convenient management of platform hardware resources. The platform resource management module can be divided into server nodes, system resources, custom resources, resource specifications, and resource pools.
4. Time Management
Miners can set the prices of UNC/hour for renting various AI chips. When computing power rental users purchase chip rental orders, the platform will deduct the corresponding machine hours when the AI chip container task starts. The platform sets the unit price of UNC/hour according to the resource specifications. The billing rules are as follows:
AI chip container task machine hours = Subtask 1 hours + Subtask 2 hours + … + Subtask n hours
Subtask hours = Replica 1 hours + Replica 2 hours + … + Replica n hours
Replica hours = Resource specifications * (Replica end time - Replica start time)
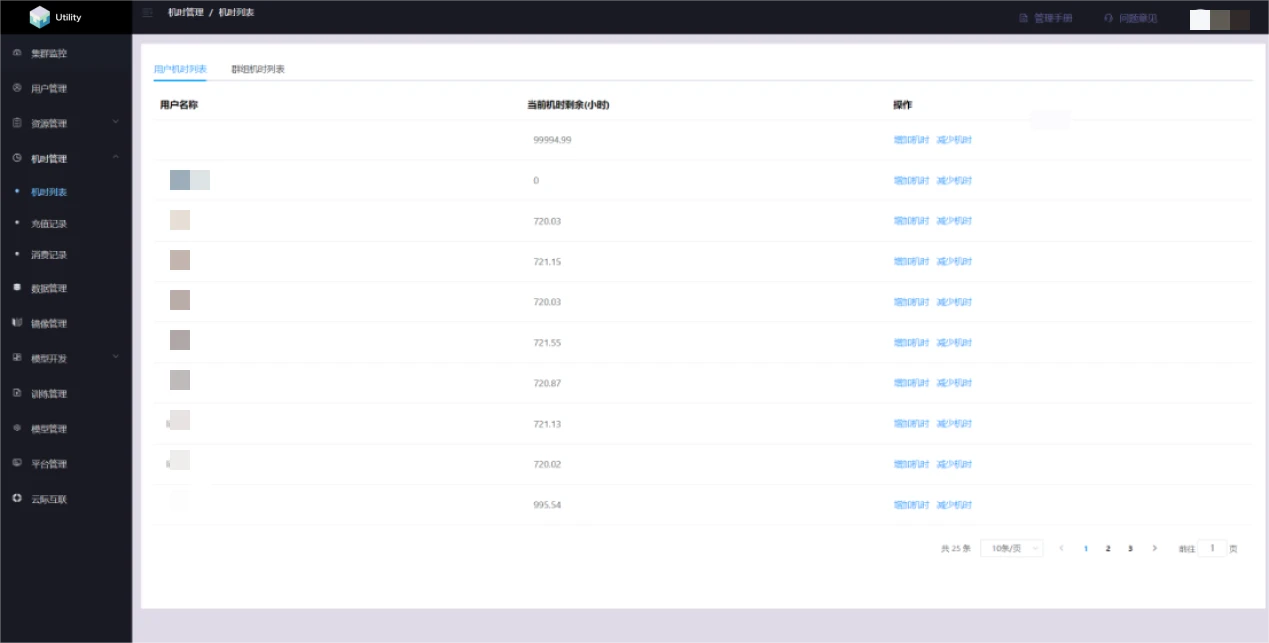
Time management includes a list of machine hours, recharge records, and consumption records.
User machine hours list
II. AI Container Cloud Chip User End
1. User Instructions
The access address for the Utility AI container cloud chip user end is https://console.utlab.io/utnetai/, and the login page is as follows:
2. Overview
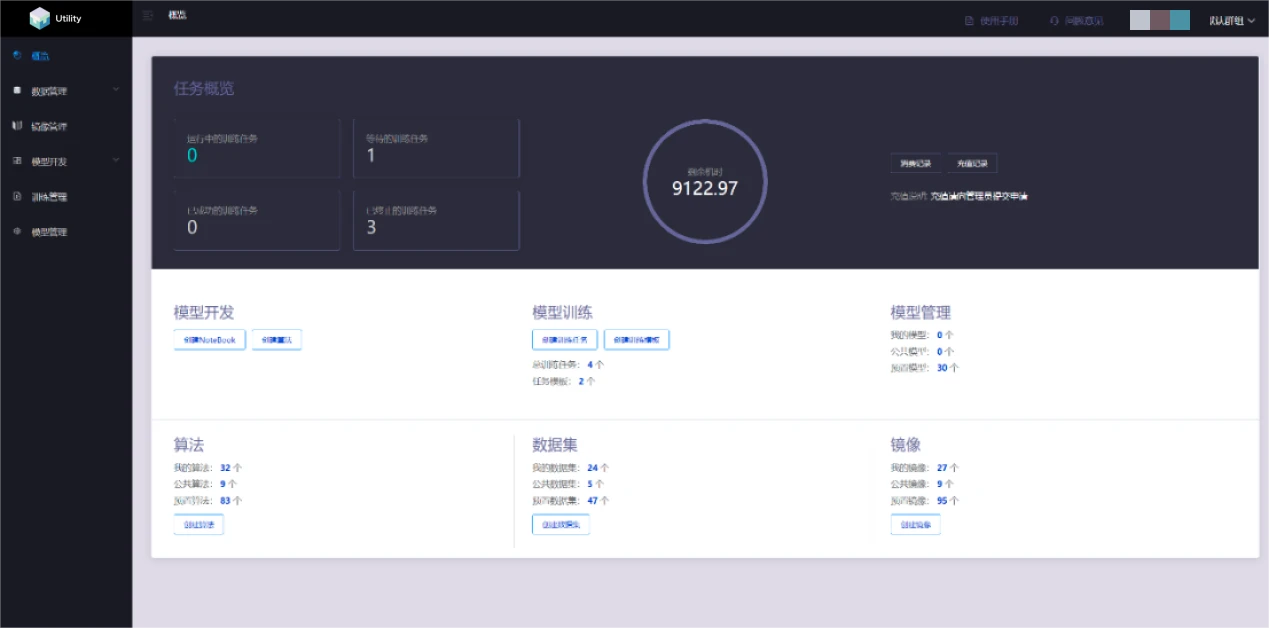
The overview page displays information about the number of training tasks in different states, remaining machine hours, consumption and recharge records, and also provides users with quick access to create Jupyter notebooks, algorithms, training tasks, task templates, algorithms, datasets, and image functions.
3. Model Development
Jupyter Notebook Management
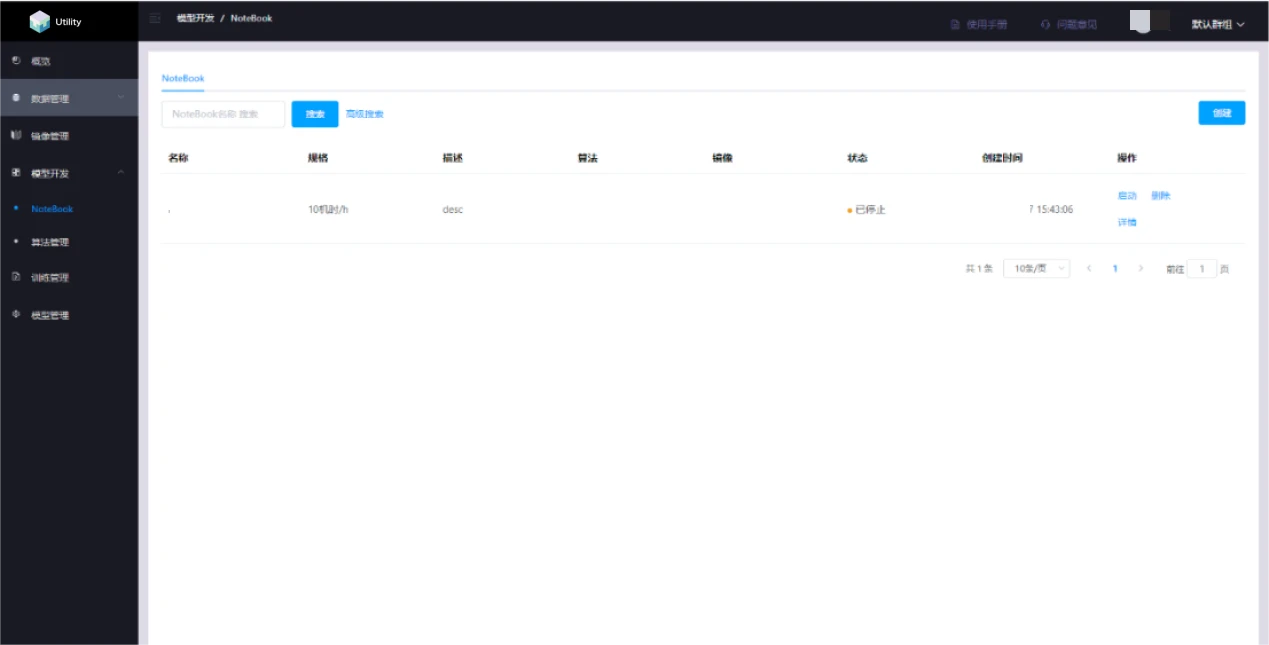
Jupyter Notebook management provides an online programming environment for debugging, running, and saving algorithms to support subsequent model training. This module supports the open-source JupyterLab, and users need to create an image containing the JupyterLab program in advance. Users can create, open, start, stop, and delete notebooks, and any algorithm edited in JupyterLab will be automatically saved.
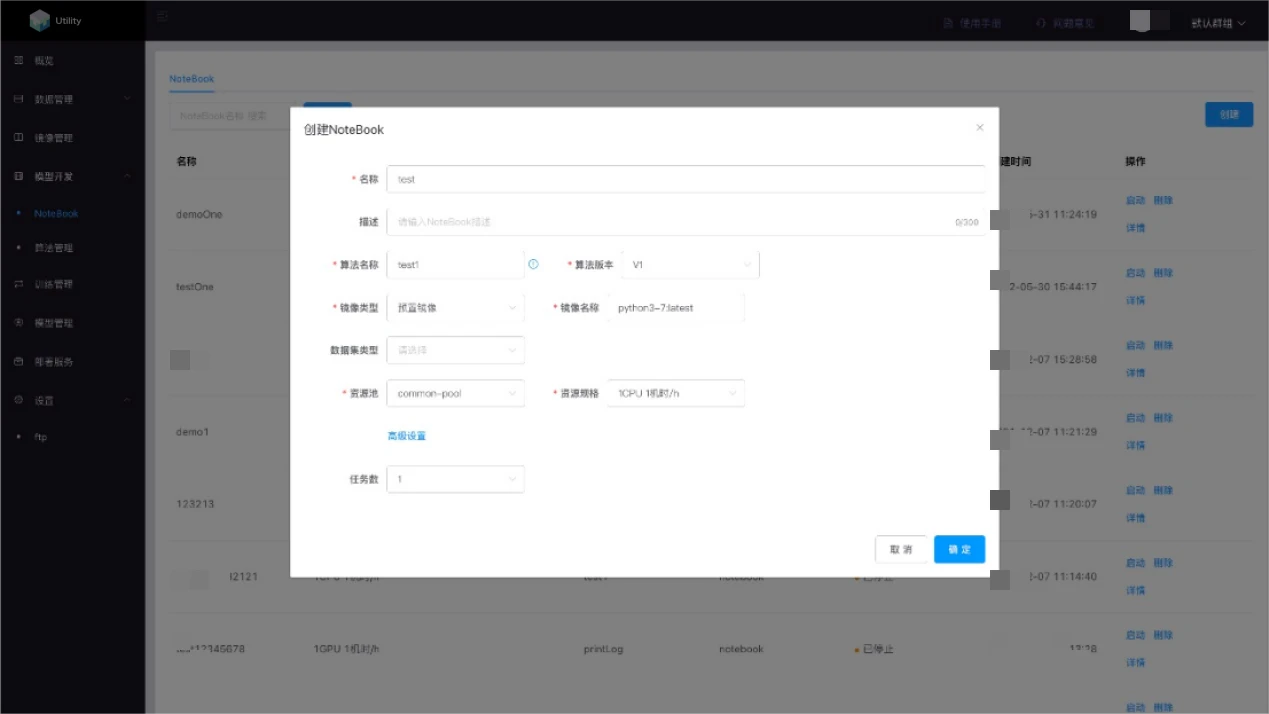
Create notebook
Click the create button, select the corresponding algorithm, image, dataset (optional), and resources, and in "Advanced Settings," select the number of tasks, then click OK to create the notebook.
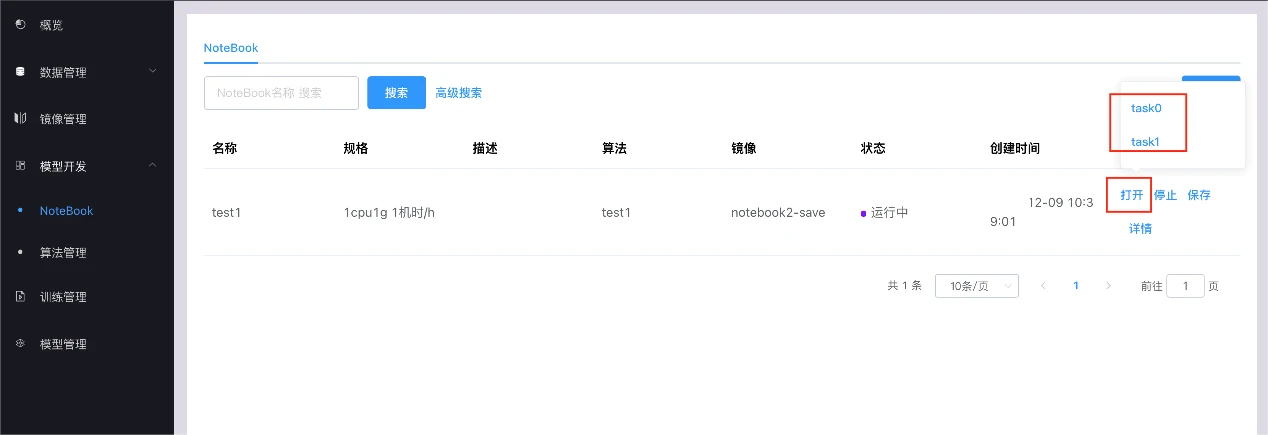
Open notebook
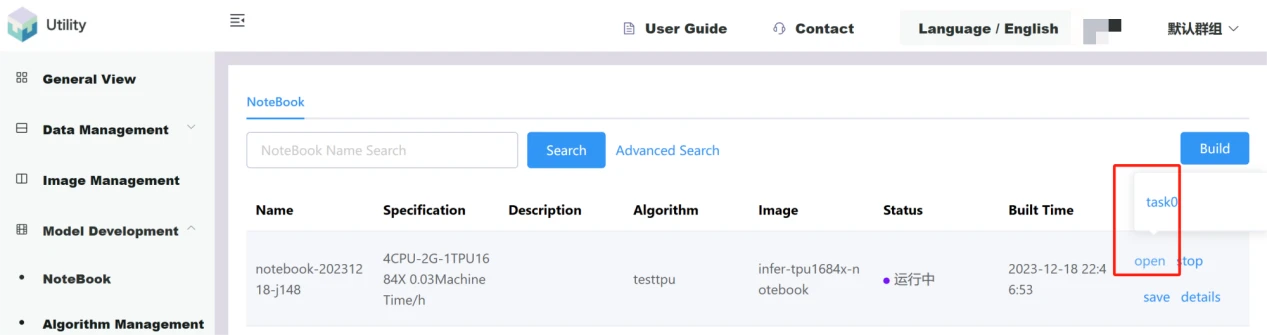
Click the open button, a floating window will pop up, select the corresponding subtask, and open the notebook.
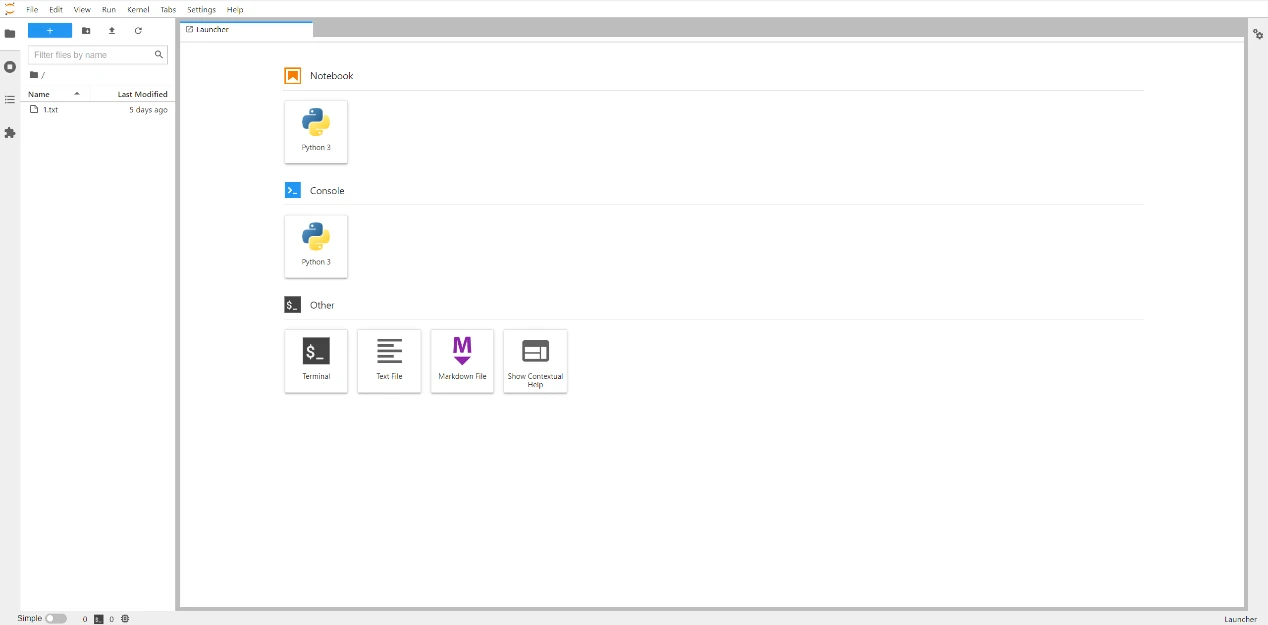
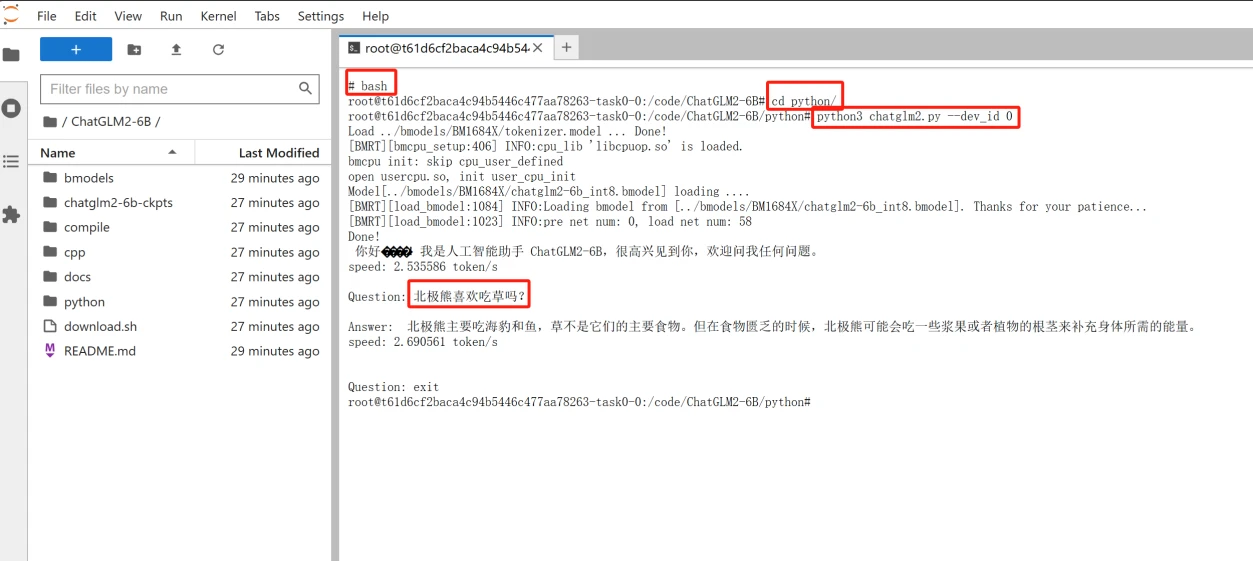
This time, I deployed an ONNX model, which was converted from Tsinghua GLM-6B, and the related inference was successfully deployed on the Nvidia Tesla A100 40G. Now, I am trying to perform inference in the infer container environment with the officially provided 4CPU2G + 1 1684x chip. As shown in the figure below:
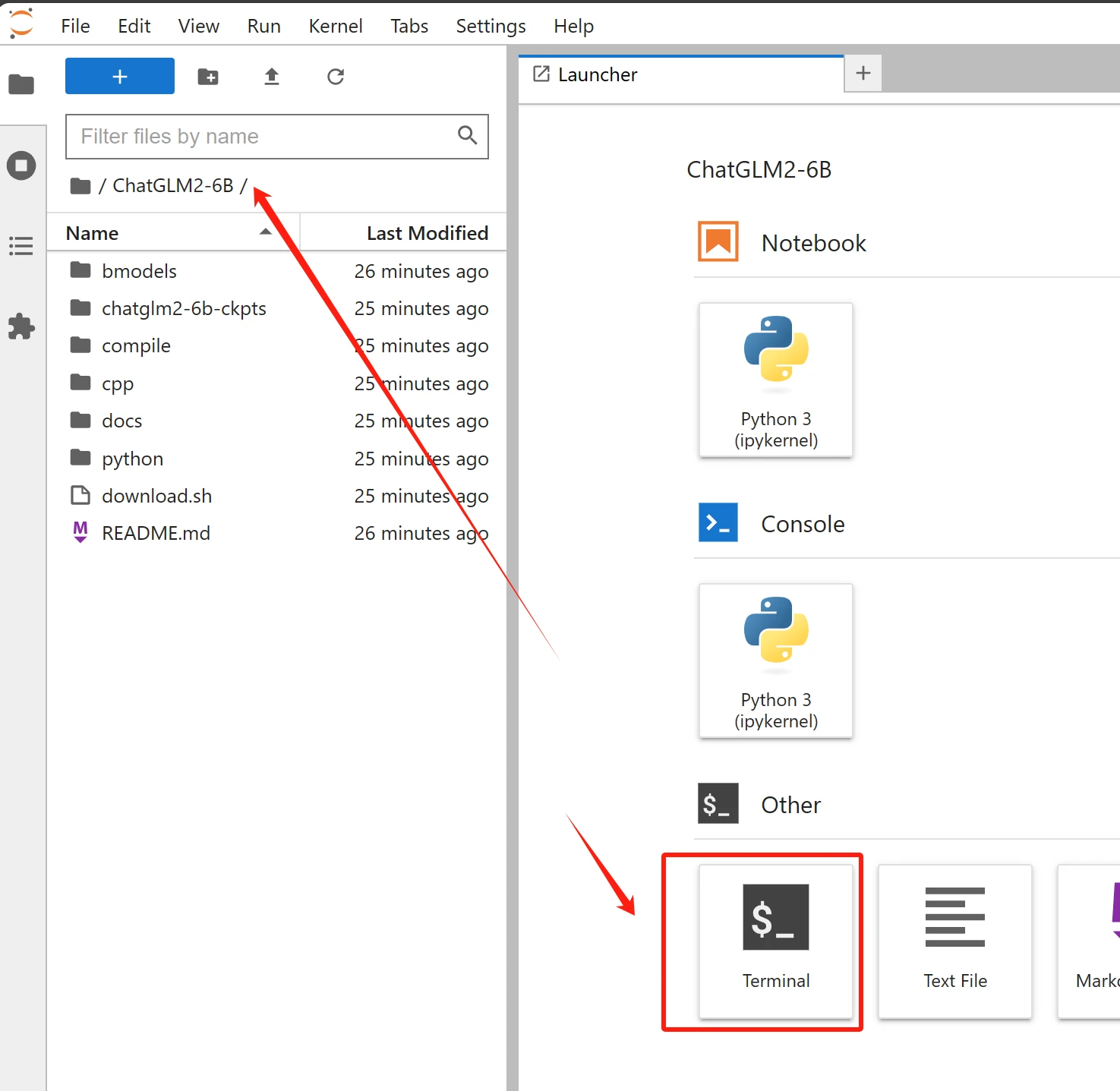
After uploading the compiled model and confirming the directory, I tried to open it in the notebook and successfully loaded the directory and console. I must say that the experience in this container is almost identical to the traditional AI engineer workflow, which demonstrates the professionalism and dedication of the UtilityNet team. The compatibility with Jupyter's full environment is very user-friendly for developers who need plot monitoring and professional output. In the notebook, you can see the relevant loading in the directory as shown in the figure below:
Next, entering the container console, the experience is almost perfect, possibly because the trial server cluster is located in Asia, so the latency is almost the same as the AWS Hong Kong server previously purchased. Due to the pre-compiled nature, we directly ran it with Python3, and dev0 is the first chip allocated to me in the SC7 three-chip BM1684X card. After specifying and running the command, there was a brief delay before successful inference. Therefore, a single card can run three ChatGLMs in parallel, providing a parallel experience by distributing to three users. This makes us full of expectations for the extensive use of BM1684x in UtilityNet. The relevant test can be seen in the figure below:
Stop notebook
Finally, click the stop button to stop the notebook, ending the experience and machine hours.
III. Conclusion
Through the entire experience, from applying for the container, to being allocated a 2CPU4G single 1684x chip container, to deploying and compiling in the infer environment, to easily opening Jupyter in the notebook, to the successful inference of the directory and GLM in the console, the entire process was incredibly smooth and very user-friendly for related AI developers and computing power users. I have to express my endless anticipation for such a powerful container cloud to be open-source and deployed on the computing power provider nodes of UtilityNet with one-click. This has also given me more confidence in the future of the public test network and distributed computing power of UtilityNet, which is expected to be launched in February or March next year.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







