Source: Alpha Community

Image Source: Generated by Wujie AI
Currently, the two largest model startups that have received the most financing are OpenAI and Anthropic. The biggest investors in these two companies are Microsoft and Amazon, who have invested a large portion of not just funds, but also equivalent cloud computing resources. This effectively "ties" these two top closed-source model companies to the "chariots" of tech giants.
In addition to closed-source large models, there is another camp of open-source large models, with MetaAI's llama series being a representative. Meta also leads the formation of the AI Alliance, aiming to promote the open-source development in the field of artificial intelligence and counteract closed-source giants such as OpenAI and NVIDIA.
Most startups using open-source large models for applications also hope to maintain their independence and will employ a multi-cloud strategy. Therefore, a powerful and cost-effective AI cloud platform is in great demand.
together.ai is a company that provides cloud platform services for AI startups for training and inference. In fact, it is also a full-stack AI company that embraces the open-source ecosystem, possessing its own models and datasets, and has deep accumulation in AI underlying technology.

Recently, together.ai secured a Series A financing of $102.5 million led by Kleiner Perkins, with participation from investors such as NVIDIA and Emergence Capital. Other investors in this round include NEA, Prosperity7, Greycroft, 137 Ventures, Lux Capital, Definition Capital, Long Journey Ventures, SCB10x, and SV Angel, among others who were seed round investors for Together.
In addition to institutional investors, its seed round investors also include Scott Banister, co-founder of IronPort, Jeff Hammerbacher, co-founder of Cloudera, Dawn Song, founder of Oasis Labs, and Alex Atallah, co-founder of OpenSea. This round of financing is five times the size of the company's previous financing, with a total financing amount of $120 million.
Vipul Ved Prakash, co-founder and CEO of together.ai, stated, "Today, it is extremely challenging to train, fine-tune, or productize open-source generated AI models. Current solutions require enterprises to have significant expertise in artificial intelligence while being able to manage large-scale infrastructure. The together.ai platform addresses these two major challenges in a one-stop manner, providing easy-to-use and accessible solutions. Our goal is to help create open models that surpass closed models and make open source the default way to integrate artificial intelligence."
Former Apple Executives and University Professors Build an AI Open Source Cloud Platform
together.ai was founded in June 2022, with co-founders including Vipul Ved Prakash, Ce Zhang, Chris Re, and Percy Liang.

Prakash previously founded the social media search platform Topsy, which was acquired by Apple in 2013, after which he became a senior director at Apple.
Ce Zhang is an associate professor of computer science at the Swiss Federal Institute of Technology in Zurich, leading research on "decentralized" artificial intelligence.
Percy Liang is a professor of computer science at Stanford University, leading the Center for Research on Foundation Models (CRFM) at the university.
Chris Re co-founded several startups, including SambaNova, which builds hardware and integrated systems for artificial intelligence.
Prakash stated, "When Chris, Percy, Ce, and I came together last year, we all clearly felt that AI foundational models represent a generational shift in technology and may be the most important one since the invention of the transistor. At the same time, the leading open-source community in AI innovation over the past few decades has limited capabilities in shaping the upcoming AI world. We see these models tending to centralize in a few companies (OpenAI, Anthropic, Google) due to the enormous expense of high-end GPU clusters required for training. This is what together.ai is trying to change, by creating an open and decentralized alternative to challenge existing cloud systems (such as AWS, Azure, and Google Cloud), which will be 'crucial' for future business and society. As enterprises define their generative AI strategies, they are looking for privacy, transparency, customization, and ease of deployment. Current cloud services, due to their closed-source models and data, cannot meet their needs."
Chinese Scholar Joins the Team as Chief Scientist with FlashAttention Technology and Mamba Model

In July of this year, Tri Dao joined the company team as Chief Scientist. Tri Dao obtained a Ph.D. in computer science from Stanford University, under the guidance of Christopher Ré and Stefano Ermon, and is also about to become an assistant professor at Princeton University. His research won the runner-up award at the 2022 International Conference on Machine Learning (ICML).
Tri Dao is also the author of FlashAttention v2, a leading and open-source tool for large language models that can accelerate the training and inference speed of large language models. FlashAttention-2 has increased the training and fine-tuning speed of large language models (LLMs) by up to 4 times and achieved a 72% model FLOPs utilization rate on NVIDIA A100.
FlashAttention-2 has achieved a 2x acceleration in core attention operations and a 1.3x acceleration in end-to-end training of Transformers. Given the high training cost of large language models, which can reach tens of millions of dollars, these improvements could save millions of dollars and enable models to handle contexts twice as long.
Currently, various large language model companies, including OpenAI, Anthropic, Meta, and Mistral, are using FlashAttention.
Recently, Tri Dao also participated in a research project called "Mamba" and proposed a new architecture called "selective state space model." Mamba can match or even outperform Transformers in language modeling and achieve linear expansion with increasing context length, improving performance to handle sequences of up to a million tokens and achieving a 5x increase in inference throughput.
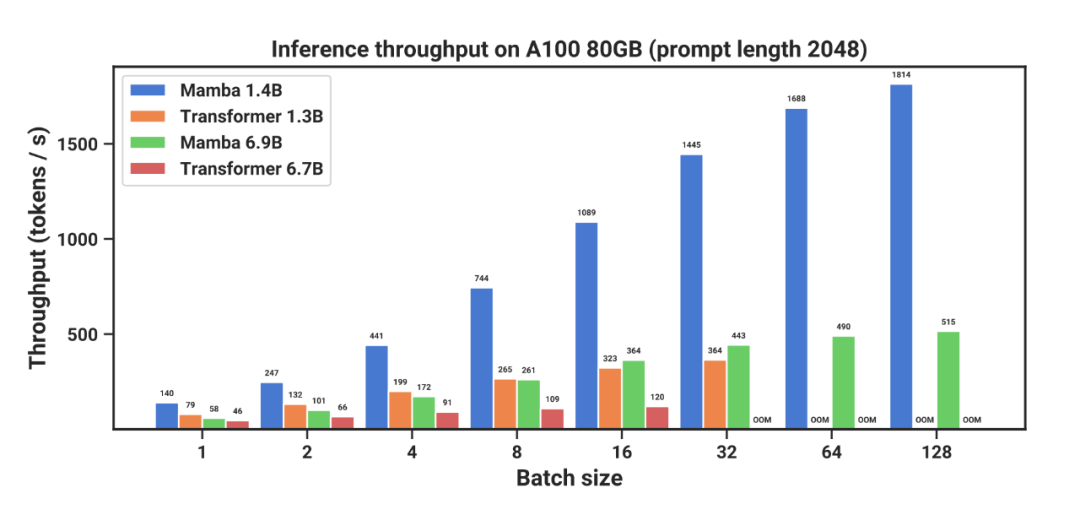
Mamba, as the backbone of a universal sequence model, has achieved state-of-the-art performance in multiple modalities such as language, audio, and genomics. In terms of language modeling, the Mamba-3B model outperforms equivalent-sized Transformer models in both pre-training and downstream evaluation, and can compete with Transformer models twice its size.
With the support of a strong technical team, together.ai has consistently innovated in inference. In addition to FlashAttention-2, they have also utilized technologies such as Medusa and Flash-Decoding, forming the fastest inference technology stack for Transformer models. Through the Together Inference API, this stack allows rapid access to over 100 open models for fast inference.
Regarding this financing, Bucky Moore, a partner at Kleiner Perkins, commented, "Artificial intelligence is a new infrastructure layer that is changing the way we develop software. To maximize its impact, we need to make it accessible to developers everywhere. We expect that as open-source model performance approaches that of closed-source models, they will be widely adopted. together.ai enables any organization to build fast and reliable applications on its infrastructure."
Brandon Reeves, from Lux Capital, one of the seed round investors of Together AI, stated in an interview, "By providing an open ecosystem with cross-computing and first-class foundational models, together.ai is leading the 'Linux moment' of artificial intelligence. The together.ai team is committed to creating a vibrant open ecosystem that allows anyone from individuals to enterprises to participate."
Not Only the Fastest Open-Source AI Cloud Platform for Inference, but also Own Datasets and Models
together.ai not only has the AI computing power cloud platform Together GPU Clusters, but also offers specially optimized inference, training, and fine-tuning services. They can also customize AI models for clients using their own datasets and have introduced their own exemplary open-source AI models.
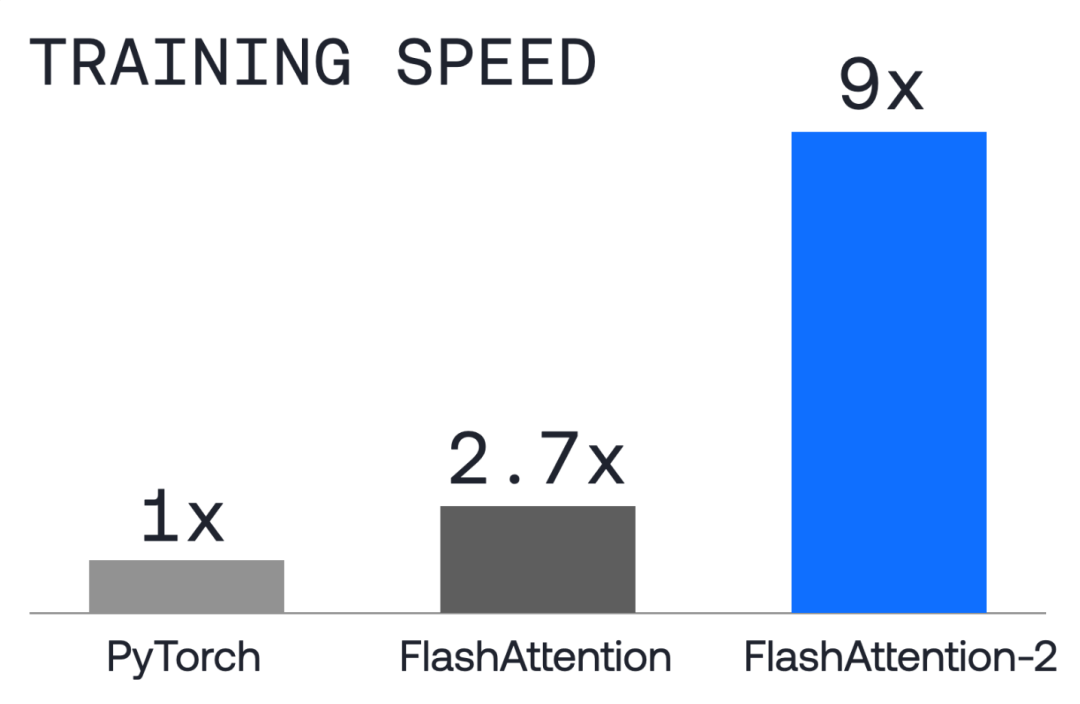
Together GPU Clusters: 9x Faster Training Speed than Standard PyTorch
Together GPU Clusters (formerly Together Compute) is a GPU computing cluster specially optimized for AI model training. It has extremely fast model training speed and high cost efficiency. Customers can train and fine-tune models on the platform.
together.ai has equipped this cluster with a training software stack, allowing users to focus on optimizing model quality rather than adjusting software settings.
In terms of speed, it is 9 times faster than using standard PyTorch, and in terms of cost, it reduces costs by 4 times compared to AWS. It uses NVIDIA's high-end GPUs A100 and H100.
In addition, it has excellent scalability, allowing users to choose computing power scales from 16 GPUs to 2048 GPUs, corresponding to different sizes of AI models. For customers, it also provides expert-level support services, and its renewal rate currently exceeds 95%. The company has established preliminary data center networks in the United States and Europe, with data center partners including Crusoe Energy and Vultr.
Together Fine-Tuning: Fine-Tuning with Private Data
together.ai also provides model fine-tuning services, allowing customers to customize open-source models using their own private data. together.ai gives users complete control over hyperparameters during fine-tuning, and its platform is integrated with Weights & Biases, making model fine-tuning more controllable and transparent for customers.
Finally, once the model fine-tuning is completed, customers can host their models on the platform and perform inference.
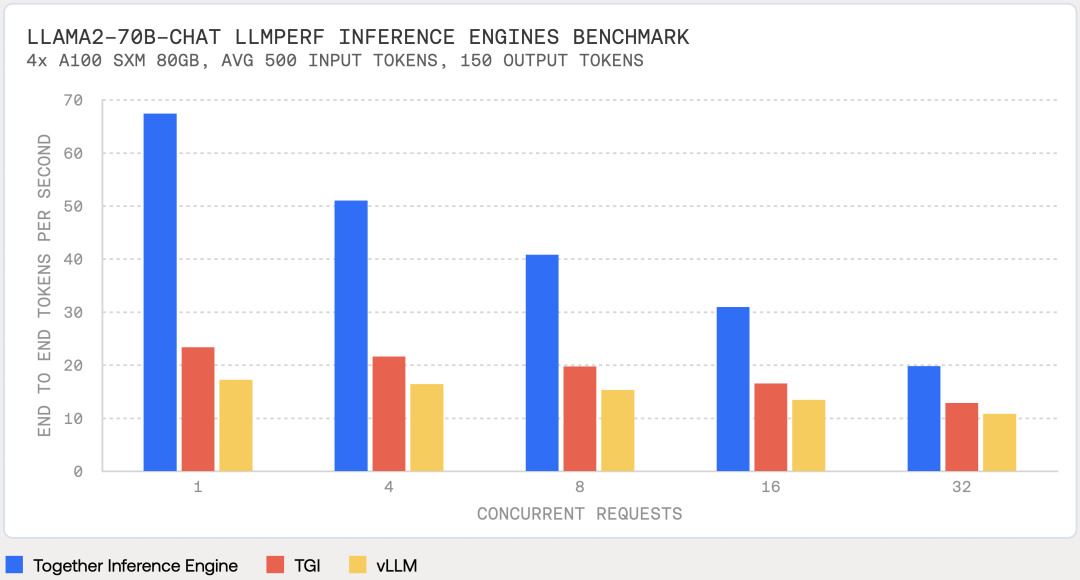
Together Inference Engine: 3x Faster than TGI or vLLM
The Together Inference Engine is built on NVIDIA's CUDA and runs on NVIDIA Tensor Core GPUs. The Together team has optimized inference performance using a series of technologies, including FlashAttention-2, Flash-Decoding, and Medusa (mostly open-source). The speed of the Together inference engine is 3 times faster than other inference acceleration frameworks or services when running on the same hardware as TGI or vLLM (large model inference acceleration framework). This means that generative AI applications based on large models can now provide faster user experiences, higher efficiency, and lower costs.
For example, using the same hardware, the Llama-2-70B-Chat model was tested for inference (500 input tokens, 150 output tokens) using the open-source LLM Perf benchmarking tool, with the results shown in the following image.
In addition to ultra-fast speed, the Together inference engine does not sacrifice any quality. The table below shows the results of several accuracy benchmark tests. The results of the Together inference engine are consistent with the referenced Hugging Face implementation.
Together Custom Models: Training with Free and Open Datasets
For enterprise users, together.ai has also launched Together Custom Models, which essentially is a consulting service to help enterprises build models from scratch.
They have an expert team to help enterprises design and build customized AI models for specific workloads, trained based on together.ai's RedPajama-v2 dataset (30T tokens) and the enterprise's proprietary data.
It is reported that the open-source RedPajama-V2 dataset has been downloaded 1.2 million times.
together.ai will provide the training infrastructure, training techniques (such as FlashAttention-2), model architectures (both Transformer-based and non-Transformer-based), and training recipe selection. After the model is trained, they also provide tuning and alignment services.
Once the model training is completed, ownership of the model belongs entirely to the client enterprise, which is attractive for industries and large enterprises with a focus on data security. At a previous DevDay by OpenAI, they also launched model customization services based on the GPT model, recognizing this aspect.
In fact, together.ai has accumulated a lot in open-source models. In addition to the RedPajama-v2 dataset, they also include GPT-JT (a branch of the open-source text generation model GPT-J-6B released by the research group EleutherAI) and OpenChatKit (similar to ChatGPT chatbot).
In terms of clients, in addition to Pika Labs, which recently raised $55 million, there are also well-known startups such as Nexusflow, Voyage AI, and Cartesia.
Open Source Ecosystem Breaks the Closed and Centralized Model
Currently, in the development of AI large models, especially foundational models, the industry (big companies, startups) has clearly taken the lead over universities and academic research institutions. Closed-source large models also outperform open-source large models in terms of performance.
The main reason for this gap is the massive cost required to train large models (computing cost, manpower cost, time cost), which makes it difficult for schools and research institutions to use relatively small-scale models (6B or 7B parameters) for relatively marginal research, or to challenge the basic theory in an attempt to disrupt the existing landscape.
The surpassing of closed-source large models over open-source large models is a reality, but if this trend continues, it will make the rights of AI more and more centralized, forming a pattern of a few giants (Microsoft, Google) + a few new giants (OpenAI + Anthropic). This is not conducive to the overall development of the AI entrepreneurial ecosystem. This is also the underlying reason for the huge impact caused by the release of llama2.
This is where together.ai comes in. On the one hand, they build computing platforms to provide enterprises with cheap and fast model training and inference services, while also helping enterprises create their own custom models, giving enterprises a third-party choice.
In terms of open source, they also provide their own datasets, their own training and inference technology stack, and exemplary open-source models, all of which are efforts to break the "monopoly".
The reason together.ai has this capability is also inseparable from its own technical strength. The combination of serial entrepreneurs and university professors allows them to understand the pain points of enterprises and have the ability to solve and optimize from the ground up.
In fact, this is also a very good example of university professors embracing entrepreneurship, using social capital for research, and making their research results impact more people. We also look forward to seeing more entrepreneurial teams consisting of professors/scholars and industry professionals/serial entrepreneurs.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。








