Source: Synced

Image Source: Generated by Wujie AI
Writing a good prompt has become a required course for LLM.
With the emergence of large language models such as ChatGPT and GPT-4, prompt engineering has become increasingly important. Many people consider prompts as an incantation for LLM, and their quality directly affects the model's output.
How to write a good prompt has become a required course in LLM research.
Leading the trend of large models, OpenAI recently released an official prompt engineering guide, which shares strategies for obtaining better results with models like GPT-4. OpenAI states that these methods can sometimes be combined for better effects.

Guide link: https://platform.openai.com/docs/guides/prompt-engineering
Six strategies for better results
Strategy 1: Clearly state instructions
First, users need to clearly state instructions because the model cannot read your mind. For example, if you want the model's output to not be too simple, then write the instruction as "Request expert-level writing"; or if you don't like the current writing style, change the instruction to be more specific. The fewer times the model guesses what you want, the greater the likelihood of getting satisfactory results.
As long as you do the following, there shouldn't be a big problem:
First, include more detailed query information in the prompt to obtain more relevant answers. For example, using a prompt like "Summarize the meeting minutes in a paragraph. Then write down the speaker's Markdown list and each key point. Finally, list the recommended follow-up steps or action items from the speakers (if any)." will yield better results.
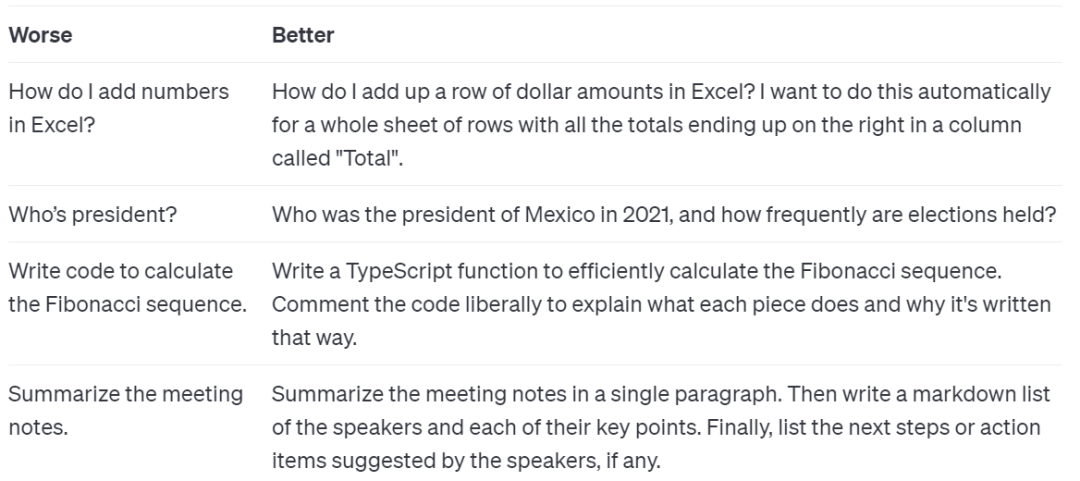
Second, users can provide examples. For instance, when you want the model to mimic a difficult-to-describe response style, you can provide a few examples.
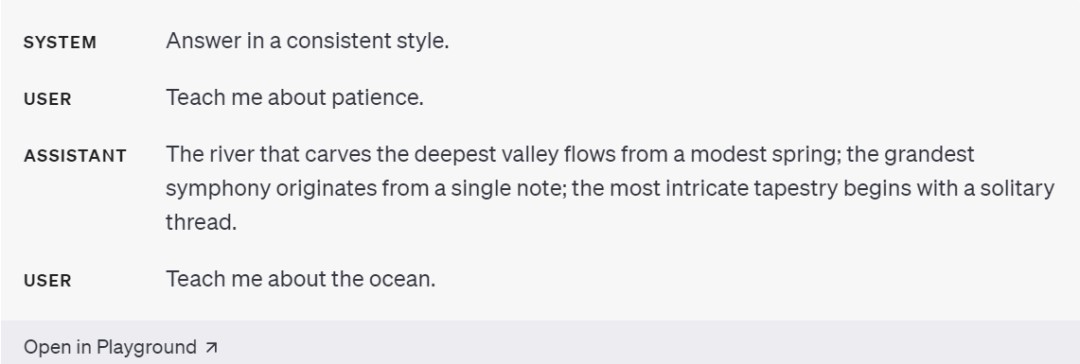
The third point is to specify the steps the model needs to complete the task. For some tasks, it's best to specify steps such as Step 1, 2, explicitly writing out these steps can make it easier for the model to follow the user's intentions.

The fourth point is to specify the length of the model's output. Users can request the model to generate output of a given target length, which can be specified in terms of words, sentences, paragraphs, etc.

The fifth point is to use separators to clearly delineate different parts of the prompt. Separators such as """, XML tags, section headings, etc., can help distinguish text parts that need to be treated differently.

The sixth point is to have the model play different roles to control the content it generates.
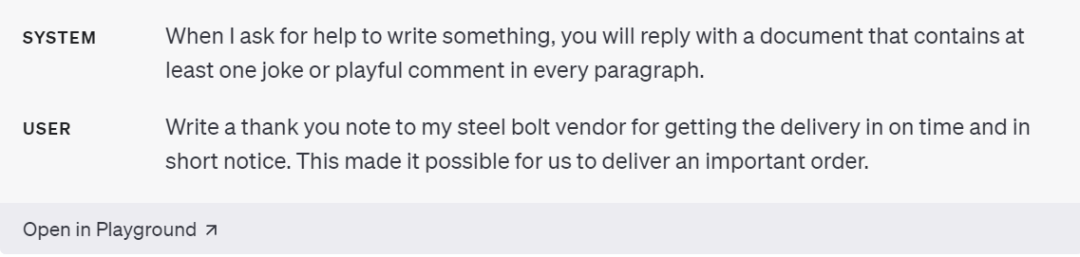
Strategy 2: Provide reference text
Language models occasionally produce hallucinations and invent answers on their own, providing reference text for these models can help reduce incorrect outputs. Two things need to be done:
First, instruct the model to use reference text to answer questions. If we can provide the model with credible information related to the current query, we can instruct the model to use the provided information to compose its answer. For example: use text enclosed by triple quotes to answer questions. If the answer cannot be found in the text, write "I cannot find the answer."

Second, instruct the model to quote answers from the reference text.
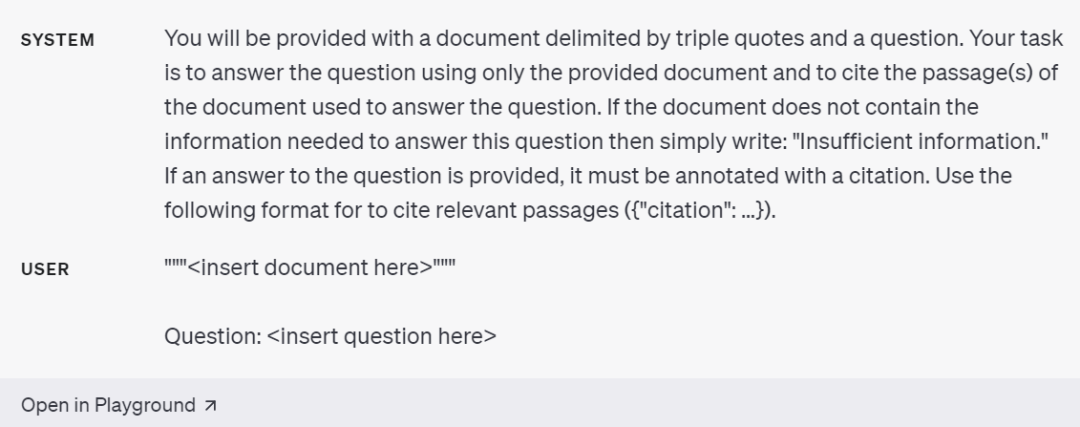
Strategy 3: Break down complex tasks into simpler subtasks
Just as in software engineering, where complex systems are broken down into a set of modular components, the tasks submitted to language models are the same. Complex tasks often have a higher error rate than simple tasks, and complex tasks can often be redefined as workflows of simpler tasks. This includes three points:
- Use intent classification to identify the most relevant instructions for the user query;
- For dialogue applications that require long conversations, summarize or filter previous dialogues;
- Summarize long documents in segments and recursively build a complete summary.
Since the model has a fixed context length, to summarize a very long document (such as a book), we can use a series of queries to summarize each part of the document. Chapter summaries can be linked and summarized to generate a summary of the summary. This process can be done recursively until the entire document is summarized. If it is necessary to use information from earlier parts to understand later parts, another useful technique is to include a running summary of the text (such as a book) before any given point, while summarizing the content at that point. OpenAI has already studied the effectiveness of this process using a variant of GPT-3 in previous research.
Strategy 4: Give the model time to think
For humans, if asked to give the result of 17 X 28, you wouldn't immediately provide the answer, but over time, you could still figure it out. Similarly, if the model immediately answers without taking time to find the answer, it may make more reasoning errors. Using a chain of thought before providing an answer can help the model reason more reliably to arrive at the correct answer. Three things need to be done:
First, instruct the model to find its solution before rushing to a conclusion.
Next is to use inner monologue or a series of queries to hide the model's reasoning process. The previous strategies indicate that detailed reasoning by the model before answering specific questions is important. For certain applications, the model's reasoning process used to arrive at the final answer may not be suitable to share with the user. For example, in a tutoring application, we may want to encourage students to arrive at their own answers, but the model's reasoning process about the student's solution may reveal the answer to the student.
Inner monologue is a strategy that can be used to mitigate this situation. The idea of inner monologue is to instruct the model to put the parts of the output that were originally hidden from the user into a structured format for parsing. Then, the parsed output is presented to the user, making only parts of the output visible before presenting it to the user.
Finally, ask the model if it has missed anything in the previous process.
Strategy 5: Use external tools
Compensate for the model's weaknesses by providing the model with the output of other tools. For example, a text retrieval system (sometimes called RAG or retrieval-augmented generation) can inform the model about relevant documents. OpenAI's Code Interpreter can help the model perform mathematical calculations and run code. If a task can be completed more reliably or effectively using a tool rather than a language model, it may be worth considering using both.
- First, use embedding-based search to efficiently retrieve knowledge;
- Call external APIs;
- Grant the model access to specific functionalities.
Strategy 6: Systematic testing of changes
In some cases, modifications to the prompt may result in better performance but may cause an overall decrease in performance on a more representative set of examples. Therefore, to ensure that the changes have a positive impact on the final performance, it may be necessary to define a comprehensive testing suite (also known as an evaluation), such as using system messages.
For more details, please refer to the original blog.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







