A superficial view is that LLM has created AI applications
Only through deep thinking can we realize that it is AI applications that have redeemed LLM
Ultimately, it is because LLM is not powerful enoughWill become the mainstream in the future, and there will be no standard products in the future, only customization
Source: NextDimension
Author: Xiao Fu
AI applications are emerging in an explosive manner. After deep consideration of the moat, market players are all turning to AI agents.
Is it the continuous improvement of model capabilities? Or is it the pressure from the capital side? Essentially, everyone wants AI to solve specific tasks.
After exploring the core values of algorithms, engineering, data, and other elements, what can AI application designers really grasp?
What does the continuous exploration of scenarios bring? What is the market more optimistic about in the impossible triangle?
Rating of Generative AI - @ZhenFund

Fig.1. Rating of Generative AI products
Based on the intelligent capabilities and problem-solving abilities of AI apps, we can approximately obtain the above ability classification and overall description. As the level of intelligence increases, the range of problems that the app can solve gradually expands.
Transitional state of LLM:
Tool Operator➡Suggester➡Executor➡Controller (Decision Maker)➡Advanced Intelligent Entity
The change in roles is driven by the enhancement of intelligent attributes, and of course, it is also a trend in the development of AI capabilities. If such a development trend is valid, then Microsoft Copilot, which has already achieved PMF, is already considered a top-level application at L3. Its moat essentially lies in the scenarios and years of deep cultivation of B-end resources.
When the value of the scenario weakens, the engineering depth needs to be increased in "thickness" or technological enhancement to establish the overall application, in order to ensure that the moat of such AI applications is deep enough.
After the demo of AutoGPT, BabyGPT, and GPT-Engineer became popular, using LLM as the core controller to build L4 agents has become a cool concept. The imagination space of application scenarios has been opened up, and we have discovered that the potential of LLM is not limited to generating well-written copies, stories, articles, and programs; it can also serve as a powerful tool to solve general problems.
Agent System Overview - @Lilian Weng
Weng, Lilian. (Jun 2023). "LLM-powered Autonomous Agents". Lil’Log. https://lilianweng.github.io/posts/2023-06-23-agent/. Autonomous Agent systems are driven by LLM, with LLM as the brain of the agent, supplemented by several key components.
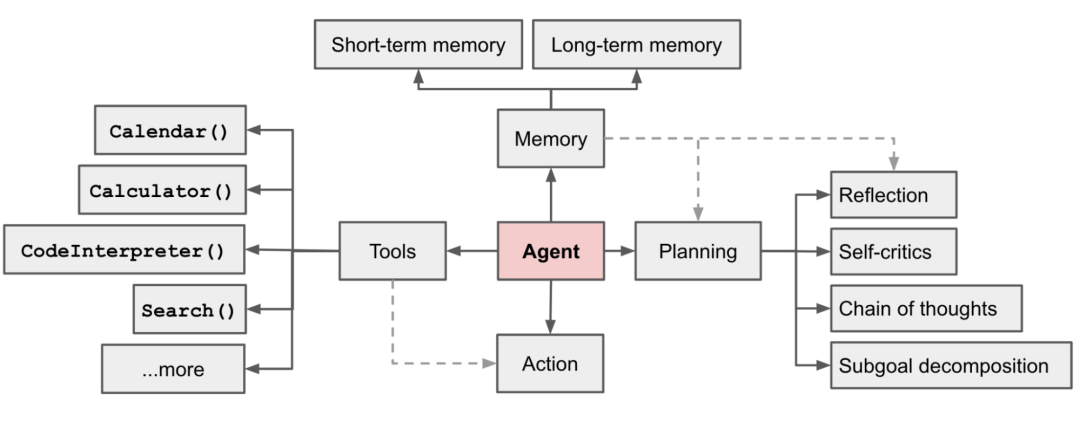
Fig.2. LLM-driven Autonomous Agent System
Planning
- Decomposition of sub-goals and task breakdown: The agent can break down large tasks into smaller, more manageable sub-goals, thus efficiently handling complex tasks.
- Self-check and self-correction: The agent can self-criticize and reflect on past actions, learn from mistakes, and improve the quality of the final results (essentially generating RL data, which does not require HF).
Memory
- Short-term memory: All in-context learning is done using the model's short-term memory. (Prompt Engineering is the main support behind this)
- Long-term memory: Provides the agent with the ability to retain and recall (indefinitely) information over a longer period, usually using external vector storage and fast retrieval (leveraging the power of vector databases) [The recall rate directly determines the effectiveness of the agent's complex content memory and retrieval]
Tool Use
- The agent learns to call APIs of external applications to obtain "additional information" missing from the model training data weights (task-related, difficult to change after pre-training), including current information, code execution capability, and access to proprietary information sources. (The emergence of code interpreters is essentially OpenAI's further exploration of agents after plugins)
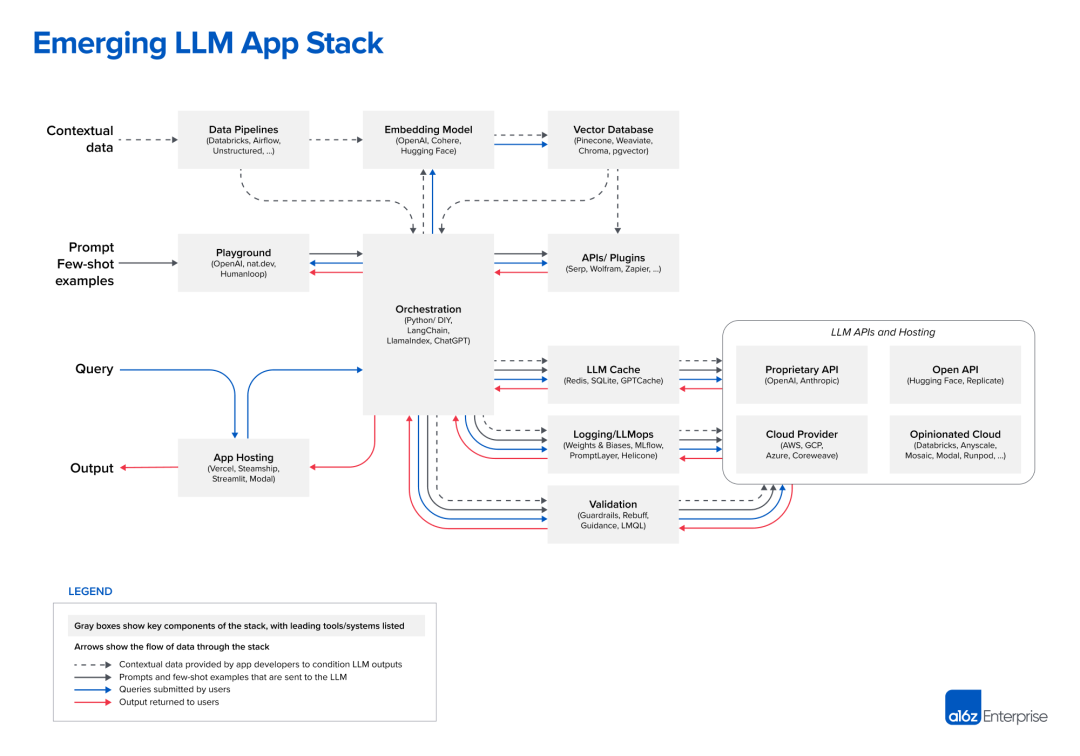
The new architecture of LLM App proposed by a16z is consistent with the introduction in the paper. Essentially, it is a biological development process and the result of overall analogy, positioning LLM as the central nervous system and collaborating in division of labor. The design of GPT4 leaked in early July also has a similar shadow, as well as the existence of MOE.
Part One: Planning
A complex task usually involves many steps, and the agent needs to understand what these steps are and plan ahead.
Task Decomposition:
Chain of thought (CoT; Wei et al. 2022) has become a standard prompting technique to improve the model's performance in complex tasks. The model is asked to "think step by step" and spend more time on calculations, breaking down difficult tasks into smaller, simpler steps. CoT transforms large tasks into manageable tasks and explains the model's thinking process.
Tree of Thoughts (Yao et al. 2023) further extends CoT by exploring multiple possibilities of reasoning at each step. It first decomposes the problem into multiple thinking steps and generates multiple thoughts at each step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search), and each state is determined by a classifier (through a prompt) or a majority vote.
Task decomposition can be achieved in the following ways:
Graph of Thoughts (Besta et al. 2023) supports prompt schemes for multiple chains, tree structures, and arbitrary graph structures, supporting various graph-based thinking transformations, such as aggregation, backtracking, and looping, which cannot be expressed in CoT and ToT. Modeling complex problems as operation graphs (GoO), with LLM as the engine for automatic execution, provides the ability to solve complex problems. To some extent, GoT encompasses the single-line CoT and the multi-branch ToT.
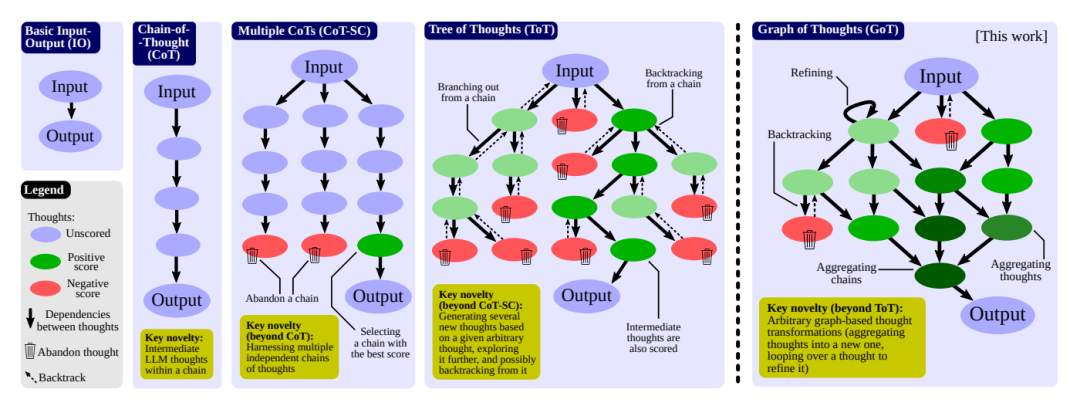
Fig.4. Comparison of GoT with other Prompt strategies
No matter CoT or ToT, it essentially triggers the model's inherent Metacognition through carefully designed prompts. It's just about how to more precisely mobilize the part of the brain that is best at Planning through clues from a certain neuron.
Another completely different approach, LLM+P (Liu et al. 2023), uses an external classical Planner to perform a more extended overall planning of sequences. This method uses the Planning Domain Definition Language (PDDL) as an intermediate interface to describe planning problems. In the entire process, LLM first translates the problem into "problem PDDL," then requests the classical Planner to generate a PDDL Plan based on the existing "domain PDDL," and finally translates the PDDL plan back into natural language (done by LLM). Fundamentally, the Planning Step is outsourced to an external tool, with the prerequisite being the need for specific domain PDDL and a suitable Planner.
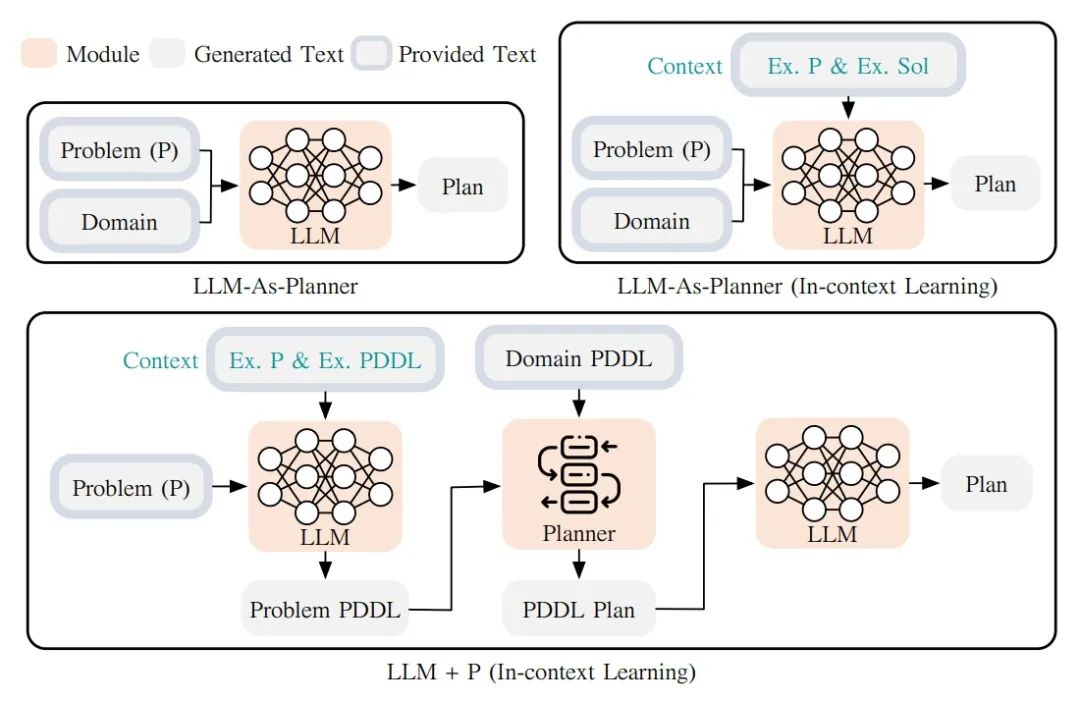
Fig.5. LLM+P uses a large language model (LLM) to generate a PDDL description of a given problem, then uses a classical planner to find the best plan, and then uses LLM again to translate the original plan back into natural language.
Model Self-Reflection:
Self-reflection is a crucial aspect that allows the agent to continuously improve by perfecting past action decisions and correcting previous mistakes. In real-world tasks, trial and error is still unavoidable, and self-reflection plays a crucial role in it.
ReAct (Yao et al. 2023), also known as Reson+Act, integrates reasoning and action within LLM by expanding the Action Space to a combination of discrete actions for specific tasks and language space. The former allows LLM to interact with the environment (e.g., using the Wikipedia Search API), while the latter enables LLM to use natural language to generate the overall reasoning process based on prompts.
The ReAct prompt template includes explicit steps for LLM's thinking, roughly in the format shown below:
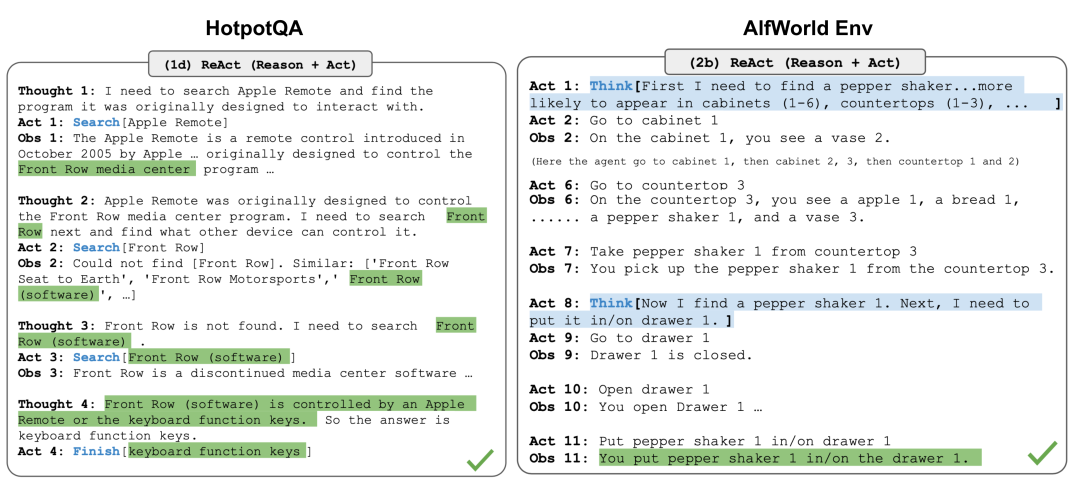
Fig.6. Example of reasoning trajectories for knowledge-intensive tasks (such as HotpotQA, FEVER) and decision-making tasks (such as AlfWorld Env, WebShop)
In two experiments involving knowledge-intensive tasks and decision tasks, ReAct's performance was superior to the single Act... approach without Thought....
Reflexion (Shinn & Labash 2023) is a framework that enables the agent to have dynamic memory and self-reflective capabilities to enhance reasoning. Reflexion uses a standard RL setup, where the reward model provides simple binary rewards, and the Action Space adopts the settings from ReAct, i.e., adding language to the action space for specific tasks to achieve complex reasoning steps. After each Actionat, the agent calculates a heuristic functionht and decides whether to reset the environment to start a new cycle based on the results of self-reflection.
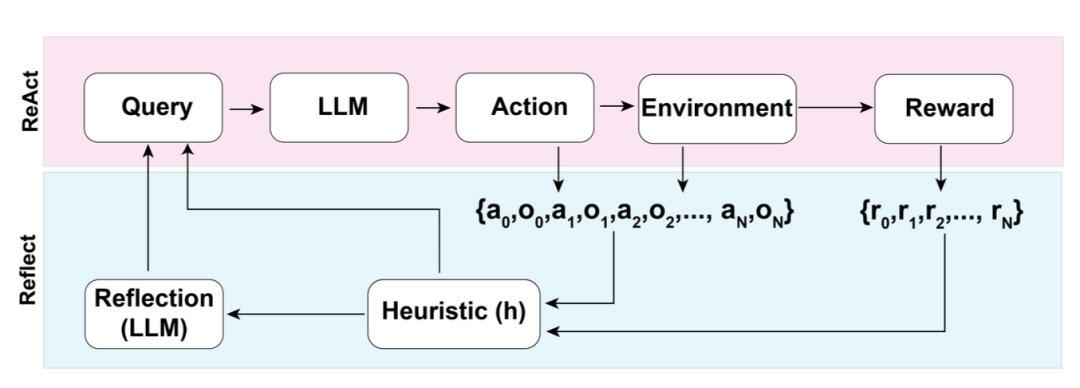
Fig. 7. Architecture diagram of Reflexion
The heuristic function determines when the entire cycle trajectory is inefficient or when it needs to stop due to containing illusions. Inefficient planning refers to a time-consuming yet unsuccessful cycle trajectory. Illusions refer to encountering a series of identical actions in the environment, leading to the same observation results.
The self-reflection process is created by giving LLM a two-shot example, each of which is a pair (failed trajectory, ideal reflection guiding further changes in the plan). Subsequently, reflections will be added to the agent's working memory as contexts for querying LLM, up to three at most.
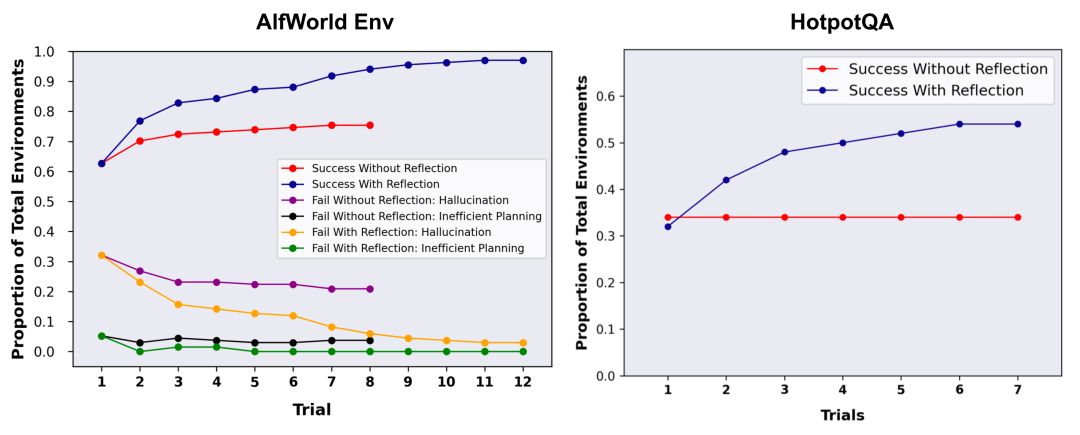
Fig. 8. Experiments in AlfWorld Env and HotpotQA. In AlfWorld, illusions are a more common failure factor than inefficient planning.
Chain of Hindsight (CoH; Liu et al. 2023) encourages the model to improve its output by explicitly showing a series of past output results. Human feedback data collection includes prompts, each being a text generated by the model, representing human ratings, which are feedback from humans on past output results. Assuming the feedback sources are sorted by reward value. This process is essentially supervised fine-tuning, where the data is a sequence, as shown below. The model is fine-tuned to predict based on the content of the previous sequence, allowing the model to self-reflect based on the feedback sequence to produce better outputs. During testing, the model can choose to accept multi-round guidance from human annotators.
To avoid overfitting, CoH adds a regularization term to maximize the log-likelihood probability of the pre-training dataset. To avoid shortcuts and replication (as there are many common words in the feedback sequence), they randomly mask 0%-5% of past tokens during the training process.
Their training dataset in the experiments includes WebGPT comparisons, summarization from human feedback, and a human preference dataset.
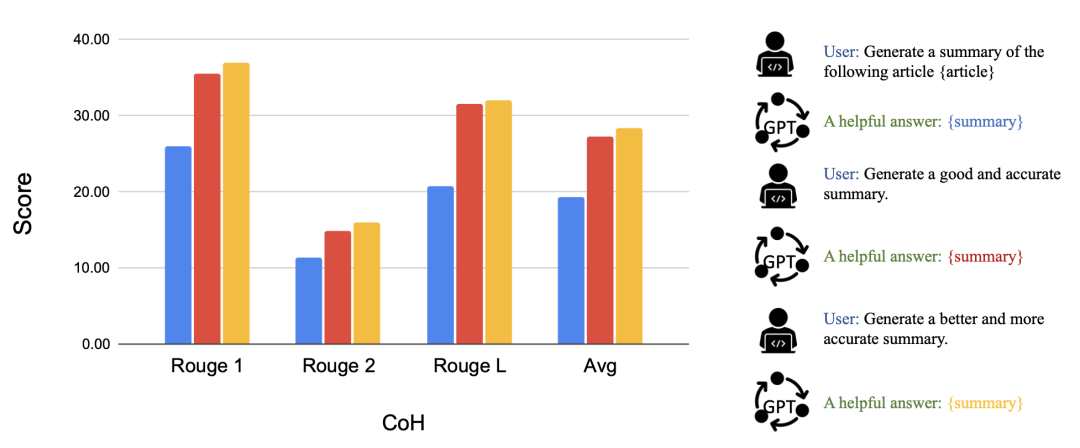
Fig. 9. After fine-tuning using CoH, the model can progressively produce improved output results according to instructions.
The concept of CoH combines real-world situations, displays historical results of continuous improvement, and trains the model to adapt to trends and produce better output results. Algorithm Distillation (AD; Laskin et al. 2023) applies the same concept to cross-epoch trajectories in reinforcement learning tasks, encapsulating the algorithm in a long historical conditional policy. Considering that the agent will interact with the environment multiple times, and the agent will improve within each epoch, AD connects these learning histories and feeds them into the model. Therefore, we should expect the next predicted action to achieve better results than previous experiments. The goal is for AD to learn the process of RL algorithms, rather than training specific task strategies.

Fig. 10. Schematic diagram of how Algorithm Distillation (AD) works.
This paper assumes that any algorithm capable of generating a set of learning histories can distill a neural network through action cloning. The historical data is generated by a set of source policies, each trained for a specific task. During the training phase, a random task is selected each time RL is run, and a subsequence of multiple historical data sets is used for training to make the learned policy task-agnostic.
In reality, the model's context window length is limited, so each subsection should be short enough to construct more historical subsections. It requires 2-4 subsections of multi-subcontext to learn a near-optimal contextual reinforcement learning algorithm. The appearance of contextual reinforcement learning requires a sufficiently long context.
Compared to three other baselines, a) ED (Expert Distillation, replacing learning history with expert trajectories), b) source policy (used to generate UCB distilled trajectories), c) (Duan et al. 2017; used as an upper bound, but requires online RL), AD demonstrated performance in contextual reinforcement learning close to RL^2, despite using only offline reinforcement learning, and learned faster than other baselines. When adjusting the training history based on the source policy, AD also improved much faster than the ED baseline.

Fig. 11. Comparison of AD, ED, source policy, and RL^2 in environments requiring memory and exploration. Only binary rewards are allocated. A3C is used to train the source policy in the "dark" environment, and DQN is used to train the source policy in the "water maze" environment.
There is only a better plan, not the best plan.
Learning from the river of history while thinking forward and seeking outward.
Part Two: Memory
Types of Memory:
Memory can be defined as the process of acquiring, storing, retaining, and subsequently retrieving information. There are multiple types of memory in the human brain.

Fig. 12. Classification of human memory
Mapping these memory contents roughly to LLM:
- Sensory memory as learning embedded representations of the original input (including text, images, or other modalities)
- Short-term memory as context learning. It is transient and limited due to the context window length of the transformer structure
- Long-term memory as an external vector storage that the agent can focus on when querying, accessible through fast retrieval
Maximum Inner Product Search (MIPS)
Using external memory can alleviate the limitation of a limited attention span. A standard approach is to store the embedding representation of information in a vector database that supports fast maximum inner product search (MIPS). To optimize retrieval speed, a common choice is approximate nearest neighbors (ANN) algorithms, which return approximately the top k nearest neighbors, sacrificing a small amount of accuracy for a huge speed improvement.
Several common ANN algorithm choices for fast MIPS:
- LSH (Locality-Sensitive Hashing): It introduces a hash function that maximally maps similar input items to the same bucket, where the number of buckets is much smaller than the number of input contents.
- ANNOY (Approximate Nearest Neighbors Oh Yeah): The core data structure is a random projection tree, which is a collection of binary trees, with each non-leaf node representing a hyperplane that divides the input space into two halves, and each leaf node storing a data point. These trees are independently constructed randomly and to some extent simulate the role of a hash function. ANNOY searches occur in all trees, iteratively searching the closest half to the query and then aggregating the results. Its concept is very relevant to KD trees, but with greater scalability.
- HNSW (Hierarchical Navigable Small World): The design of HNSW is inspired by small world networks, where each node can be connected to any other node in a few steps. For example, the "six degrees of separation" theory in social networks. HNSW constructs a multi-layer small world network structure, with the bottom layer containing actual data points. The middle layer creates some "shortcuts" to accelerate the search process. During the search, HNSW starts from a random node in the top layer and navigates step by step towards the target node. If it cannot approach the target in one layer, it descends to the next layer until it reaches the bottom layer. Each navigation step in the upper layer potentially spans a large distance in the data space, while each navigation step in the lower layer can improve the quality of the search.
- FAISS (Facebook AI Similarity Search): It is based on the assumption that in a high-dimensional space, the distance between nodes follows a Gaussian distribution, so there should be data clustering. FAISS achieves this through vector quantization, first dividing the vector space into several clusters, and then performing finer quantization within each cluster. During the search, it first uses coarse-grained quantization to find possible cluster candidates, and then uses finer quantization within each candidate cluster for further search.
- ScaNN (Scalable Nearest Neighbors): The main innovation of the ScaNN algorithm is the use of anisotropic vector quantization. It vectorizes the data points, making the inner product as similar as possible to the original distance ∠q, rather than choosing the closest quantization centroid.
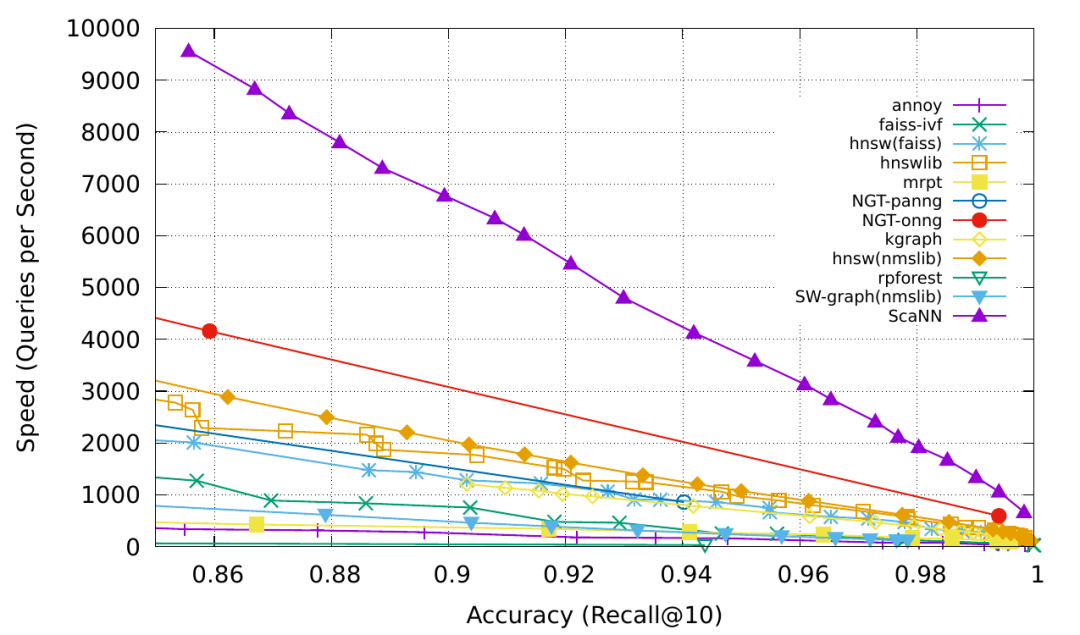
Fig. 13. Comparison of MIPS algorithms, measured by recall@10. (Image source: Google Blog, 2020)
For more MIPS algorithms and performance comparisons, visit ann-benchmarks.com.
Acquiring memory to some extent will improve the overall quality of planning, but it will also lengthen the overall service delay, so it is crucial to capture relevant memories quickly and accurately. The balance between Vector Search and Attention Mechanism is also a balance between speed and accuracy.
Of course, it's all because there is no infinite context learning.
Part Three: Tool Use
The use of tools is a significant characteristic of humans. We create, modify, and utilize external objects to surpass our physical and cognitive limits. Equipping LLM with external tools can greatly expand the model's capabilities.

Fig. 14. Seal using tools
Classification of tools:
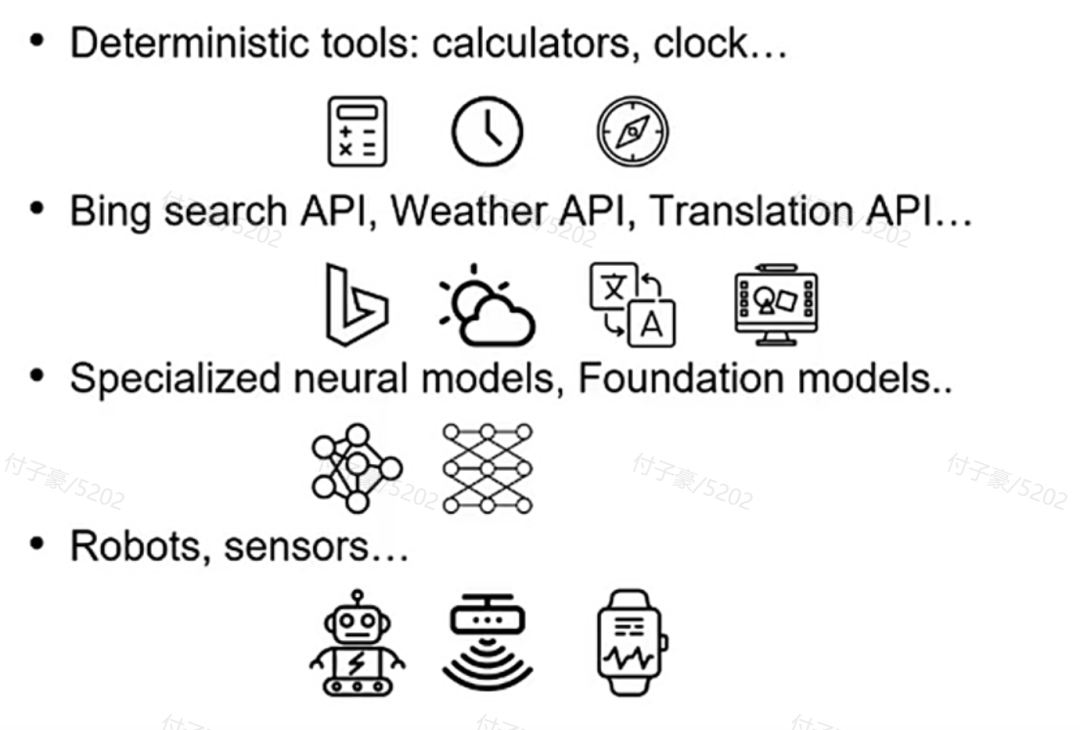
Fig. 15. Four classifications of tools
Deterministic tools - API tools - Expert models - Physical world tools
Let the language model do only what a language model should do, delivering logic through text generation.
Complete logic execution with a variety of tools.
Methods of Tool Use:
MRKL (Karpas et al. 2022), short for "Modular Reasoning, Knowledge and Language," is a neural-symbolic architecture for autonomous agents. The MRKL system is proposed to include a series of "expert" modules, with a general-purpose LLM acting as a router to route queries to the most suitable expert module. These modules can be neural modules (such as deep learning models) or symbolic modules (such as a calculator, currency converter, weather API).
They conducted an experiment using arithmetic as a test case, fine-tuning the LLM to invoke a calculator. Their experiment showed that due to the inability of the LLM (7B Jurassic1-large model) to reliably extract the correct arguments for basic arithmetic, solving mental math problems is more challenging than solving explicitly stated math problems. These results highlight the importance of understanding when and how to use these tools when external symbolic tools can reliably function, depending on the LLM's capabilities.
TALM (Tool Augmented Language Models; Parisi et al. 2022) and Toolformer (Schick et al. 2023) both fine-tuned LMs to learn to use external tools. The expansion of the dataset depends on whether the newly added API call annotations can improve the quality of the model's output. For more details, refer to the "External APIs" section of Prompt Engineering.
ChatGPT Plugins and OpenAI API function calls are good examples of LLMs with enhanced tool use capabilities in practice. The tool application interface collection can be provided by other developers (such as plugins) or defined independently (such as function calls).
HuggingGPT (Shen et al. 2023) is a framework that uses ChatGPT as a task planner to select models available on the HuggingFace platform based on the model description and summarize the response based on the execution result.
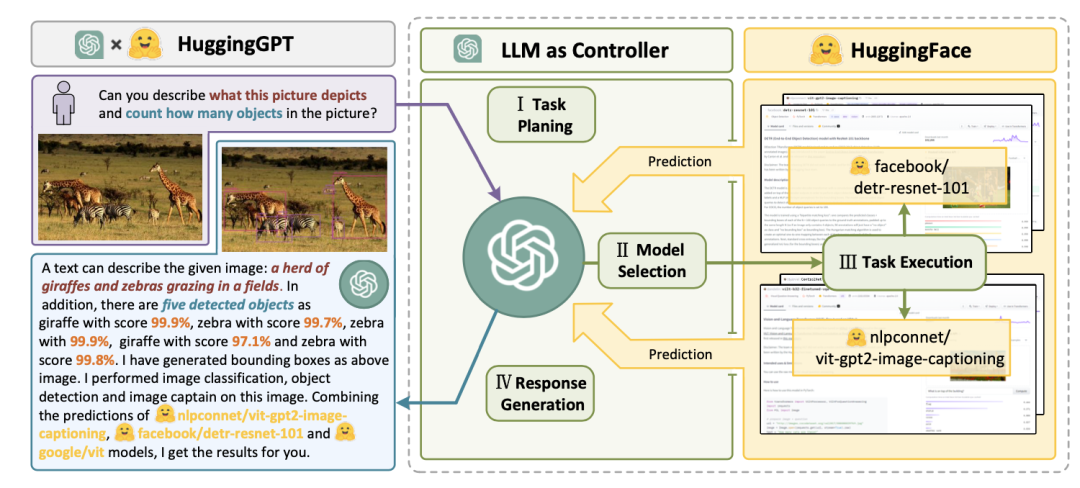
Fig. 16. Schematic diagram of the working principle of HuggingGPT
The system consists of 4 stages:
(1) Task planning: LLM acts as the brain, parsing user requests into multiple tasks. Each task has four related attributes: task type, ID, dependencies, and parameters. They use a small number of examples to guide LLM in task parsing and planning.
(2) Model selection: LLM assigns tasks to expert models, where the requirement is a multiple-choice question. LLM receives a list of models to choose from. Due to the limited context length, filtering based on the task type is required.
(3) Task execution: Expert models execute specific tasks and record the results.
(4) Response generation: LLM receives the execution results and provides a summary to the user.
Several challenges need to be addressed to put HuggingGPT into practical use:
Model Evaluation:
API-Bank (Li et al. 2023) is a benchmark for evaluating the performance of tool-augmented LLMs. It includes 53 commonly used API tools, a complete workflow for tool-augmented LLMs, and 264 annotated dialogues involving 568 API calls. There is a wide variety of API types to choose from, including search engines, calculators, calendar queries, smart home control, schedule management, health data management, account authentication workflows, and more. With a large number of APIs, LLM can first access an API search engine to find the correct API to call and then use the corresponding documentation for the call.

Fig. 17. Pseudocode of how LLM calls APIs in API-Bank
In the API-Bank workflow, LLM needs to make several decisions, and we can evaluate the accuracy of these decisions at each step.
Decisions include:
The benchmark evaluates the agent's tool use ability from three levels:
- Level 1 - Evaluating the ability to call APIs. Based on the API description, the model needs to determine whether to call the given API, call the API correctly, and respond to the API's return correctly.
- Level 2 - Checking the ability to retrieve APIs. The model needs to search for APIs that may address user needs and learn how to use these APIs by reading the documentation.
- Level 3 - Evaluating the ability to plan APIs in addition to retrieval and calling. For ambiguous user requests (such as scheduling group meetings, booking travel tickets/hotels/restaurants), the model may need to call multiple APIs to resolve.
AgentBench (Liu et al. 2023) is a multidimensional and evolving Agent Benchmark, currently selecting 8 different scenarios (operating systems, databases, knowledge graphs, digital card games, lateral thinking puzzles, household management, online shopping, and web browsing) to evaluate LLM's reasoning and decision-making abilities as an agent in multi-turn open-ended generative environments. The performance of 25 LLMs in eight environments was systematically tested, with GPT4 leading by a wide margin in overall scores. It also showed potential in complex task handling scenarios such as databases, card games, and knowledge graphs.
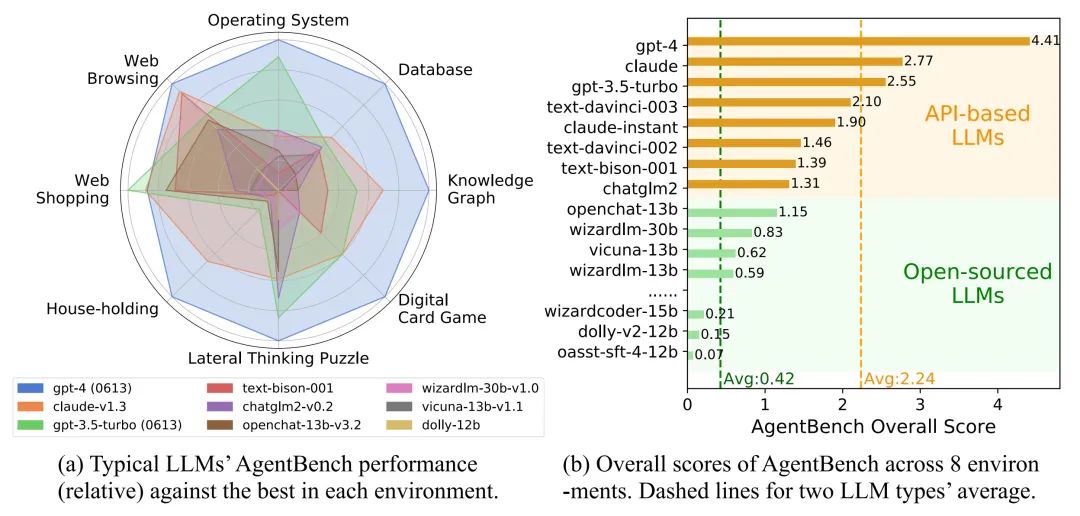
Fig. 18. Overview of different LLMs in AgentBench, showing the capabilities of LLMs as agents, but there is still a huge gap between open-source and closed-source commercial models
Case Studies:
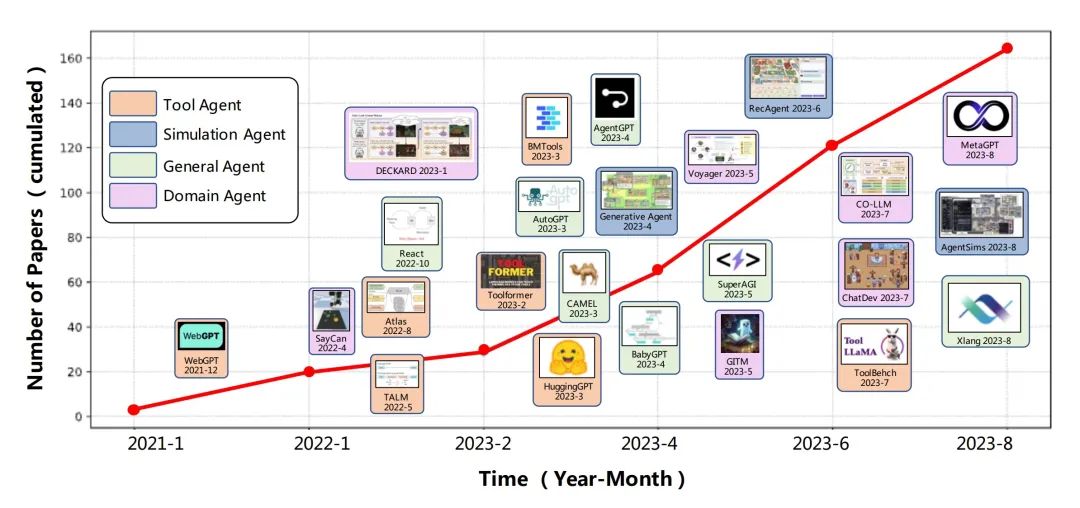
Fig. 19. Development trends of Autonomous Agents based on LLMs
Since the popularity of ChatGPT, research in the field of agents has been flourishing, with a total of 160 papers related to agents. Agents are divided into four categories based on their respective capabilities:
- Tool Agent: Utilizes various external tools (such as search engines, knowledge bases, etc.) to assist in completing tasks, represented by papers such as WebGPT, Toolformer, etc.
- Simulation Agent: Used to build simulation environments, typically involving multiple agents for multi-role interaction, dialogue, etc. Represented by papers such as Social Simulacra, Generative Agents, etc.
- General Agent: Aims for generality and can be applied to tasks in multiple domains. Represented by papers such as AutoGPT, LangChain, etc.
- Domain Agent: Optimally designed for specific domains or tasks. Represented by papers such as ChemCrow (chemistry), ChatDev (software development), etc.
Scientific Research Agents:
ChemCrow (Bran et al. 2023) is an example of a domain-specific application, where LLM uses 13 expert-designed tools to accomplish tasks such as organic synthesis, drug discovery, and material design. This workflow is implemented in Langchain, using the previously described ReAct and MRKL content, and combines CoT reasoning with task-relevant tools:
- LLM receives a list of tool names, tool descriptions, and detailed information on expected inputs/outputs.
- It then instructs it to use the provided tools to respond to prompts from the user when necessary. The instruction suggests that the model follows the ReAct format: Thought-Action-Action Input-Observation
An interesting phenomenon is that while the LLM-based evaluation found that GPT-4 and ChemCrow's performance was almost equal, manual evaluations by experts of solution completeness and chemical correctness showed that ChemCrow's performance far exceeded GPT-4. This indicates potential issues in evaluating LLM's performance in domains requiring deep domain knowledge. Lack of domain expertise may lead to LLM not being aware of its own shortcomings, thus unable to judge task results accurately.
Boiko et al. (2023) also studied LLM-empowered Agents for scientific discovery, handling autonomous design, planning, and execution of complex scientific experiments. This type of agent can use tools to browse the internet, read documents, execute code, call robot experiment APIs, and utilize other LLMs.
For example, when asked to "develop a new anti-cancer drug," the model went through the following reasoning steps:
The article also discusses various risks, particularly the risks of illegal drugs and bioweapons. They developed a test set containing a series of known chemical weapon formulations and asked the Agent to synthesize these formulations. Out of 11 requests, 4 (36%) were accepted for synthesis solutions, and the Agent attempted to consult documents to carry out the procedures. Of the 7 rejected examples, 5 were rejected after a web search, and 2 were rejected directly after prompt submission.
Generative Agent Simulation:
Generative Agents (Park, et al. 2023) is a super interesting experiment inspired by "The Sims," where 25 virtual characters live and interact in a sandbox environment, each controlled by an LLM-driven agent. The generative agent creates believable human behavior simulations for interactive applications.
The design of generative agents combines LLM with memory, planning, and reflection mechanisms, conditioning the agent's behavior on past experiences and interactions with other agents.
Memory stream: This is a long-term memory module (external database) that records a series of Agent experiences in natural language.
- Each element is an observation result provided directly by the Agent. Interactions between agents can trigger new natural language statements.
Retrieval model: Retrieves context to provide information for the Agent's behavior based on relevance, proximity, and importance.
- Proximity: Recent events score higher.
- Importance: Distinguishes between regular memory and core memory. Directly asks LM.
- Relevance: Based on its relevance to the current situation/query.
Reflection mechanism: Synthesizes memories into higher-level reasoning over time to guide the Agent's future behavior. These are higher-level summaries of past events (note, this is different from self-reflection in context).
- Prompt LM presents the 100 latest observation results and asks LM to answer 3 prominent high-level questions based on a set of observation results/statements.
Planning & Reacting: Transforms reflection and environmental information into action.
- Planning is essentially to optimize credibility for the present and future.
- Prompt template:
{Intro of an agent X}. Here is X's plan today in broad strokes: 1) - Relationships between agents and one agent's observation results of another agent are taken into consideration for planning and reacting.
- Environmental information is presented in a tree structure.
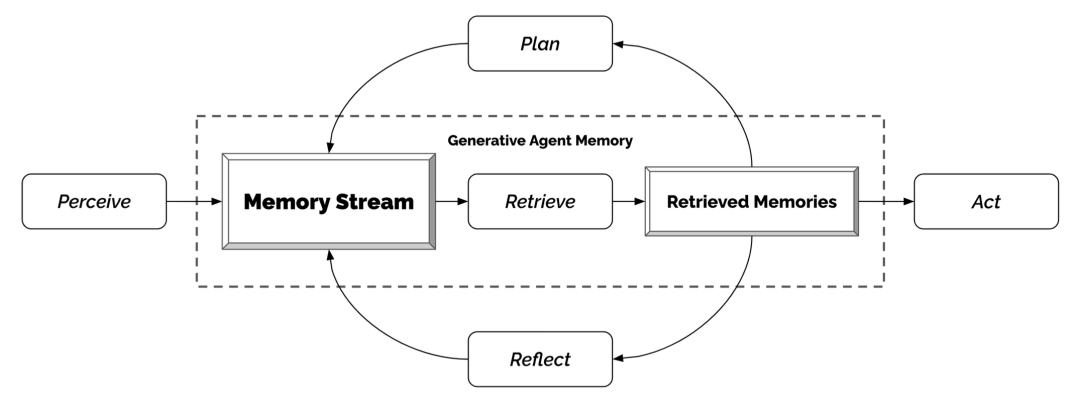
Fig. 20. Framework of Generative Agents
This interesting simulation has led to new social behaviors such as information diffusion, relationship memory (e.g., two agents continuing a conversation topic), and social event coordination (e.g., hosting a party and inviting many others).
Opportunity
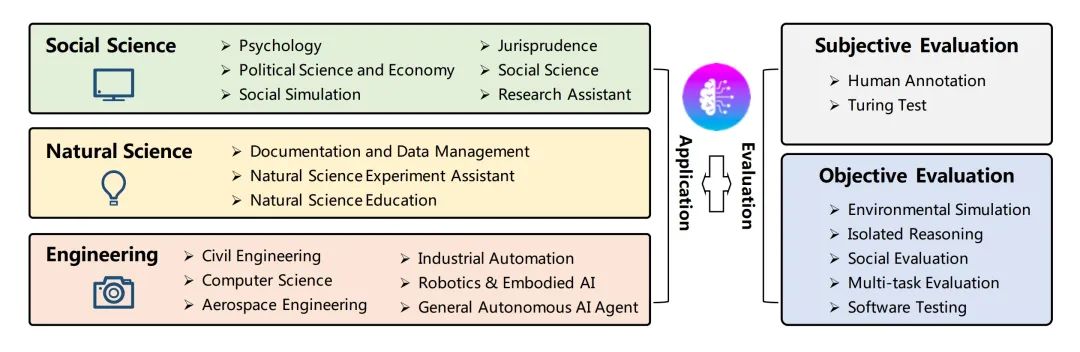
Fig. 21. Applications (left) and evaluation strategies (right) of LLM Agents.
Challenge
After understanding the main ideas and demos of building LLM-centered Agents, some common limitations have also been discovered.
- Finite context length: The limited context capacity restricts the inclusion of historical information, detailed instructions, API call context, and responses. The system's design must take into account limited communication bandwidth, while mechanisms for self-reflection drawing from past mistakes would benefit greatly from a longer or unlimited context window. While vector storage and retrieval can provide access to larger knowledge bases, their representational power is not as strong as attention.
- Challenges in long-term planning and task decomposition: Long-term planning and effective exploration of solution spaces still pose challenges. LLMs find it difficult to adjust plans when encountering unexpected errors, making their robustness not as strong as that of humans who learn from trial and error.
- Reliability of natural language interface: The current Agent System relies on natural language as the interface linking LLM to external components such as memory and tools. However, the reliability of model output is questionable, as LLM may exhibit formatting errors and occasional rebellious behavior (e.g., refusing to execute instructions). Therefore, most Agent demo code focuses on parsing model output.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







