Article Source: Quantum Bit

Image Source: Generated by Wujie AI
Research shows that the order of Chinese characters does not necessarily affect reading (for English, it is the order of letters in each word).
Now, an experiment at the University of Tokyo has found that this "theorem" also applies to GPT-4.
For example, when faced with a "mysterious code" in which almost every letter of every word is scrambled:
oJn amRh wno het 2023 Meatsrs ermtnoTuna no duySan taatgsuAu ntaaNloi Gflo bClu, gnelcinhi ish ifsrt nereg ecatkjnad ncedos raecer jroam。
But GPT-4 actually perfectly restored the original sentence (highlighted in red):

It turns out that a person named Jon Rahm won the 2023 Masters (golf) tournament.
And if you directly ask GPT-4 about this jumble, it can understand and provide the correct answer without affecting reading at all:

Researchers were very surprised by this:
In theory, scrambled words would seriously disrupt the model's tokenization process, but GPT-4 is unaffected, just like humans, which is a bit counterintuitive.

It is worth mentioning that this experiment also tested other large models, but they all failed—only GPT-4 succeeded.
What does this mean?
Word order does not affect GPT-4 reading
To test the ability of large models to resist text scrambling interference, the authors created a specialized test benchmark: Scrambled Bench.
It includes two types of tasks:
One is scrambled sentence restoration (ScrRec), which tests the ability of large models to restore scrambled sentences.
Its quantitative indicator includes something called the restoration rate (RR), which can be simply understood as the proportion of words restored by large models.
The second is scrambled question-answering (ScrQA), which measures the ability of large models to correctly understand and answer questions when words in the context material are scrambled.
Since the abilities of each model are different, it is not appropriate to directly evaluate this task using accuracy, so the authors used a quantitative indicator called relative performance gain (RPG).
The specific test materials are selected from three databases:
One is RealtimeQA, which publishes the latest news each week that LLM is unlikely to know;
The second is DREAM (Sun et al., 2019), a dialogue-based multiple-choice reading comprehension dataset;
Finally, AQuARAT, a mathematical problem dataset that requires multi-step reasoning to solve.
For each dataset, the authors selected questions and applied different degrees and types of interference, including:
Random scrambling (RS), which randomly selects a certain proportion (20%, 50%, 100%) of words in each sentence and scrambles all the letters in these words (excluding numbers).
Keeping the first letter of each word unchanged, and rearranging the rest randomly (KF).
Keeping the first and last letters of each word unchanged, and randomly scrambling the rest (KFL).
Many models participated in the test, and the main text of the article mainly reports the following:
text-davinci-003, GPT-3.5-turbo, GPT-4, Falcon-180b, and Llama-2-70b.
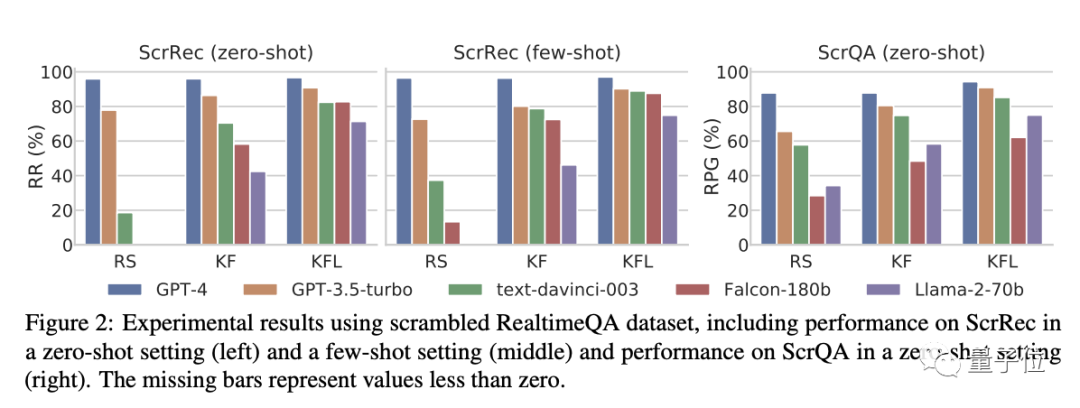
First, let's look at the impact of different types of interference.
As shown in the figure below:
In the KFL setting (i.e., keeping the first and last letters unchanged), the performance difference between models is not significant for both the scrambled sentence restoration and scrambled question-answering tasks.
However, as the interference difficulty increases (changing to KF and RS), the performance of the models all experiences a significant decline—except for GPT-4.
Specifically, in the scrambled sentence restoration (ScrRec) task, GPT-4's restoration rate remains above 95%, and in the scrambled question-answering (ScrQA) task, GPT-4's relative accuracy also remains around 85%-90%.
In comparison, some other models dropped to less than 20%.
Next is the impact of different scrambling rates.
As shown in the figure below, in the scrambled sentence restoration (ScrRec) task, as the number of scrambled words in a sentence increases, until reaching 100%, only the performance of GPT-3.5-turbo and GPT-4 did not change significantly. Of course, GPT-4 still outperformed GPT-3.5 by a large margin.
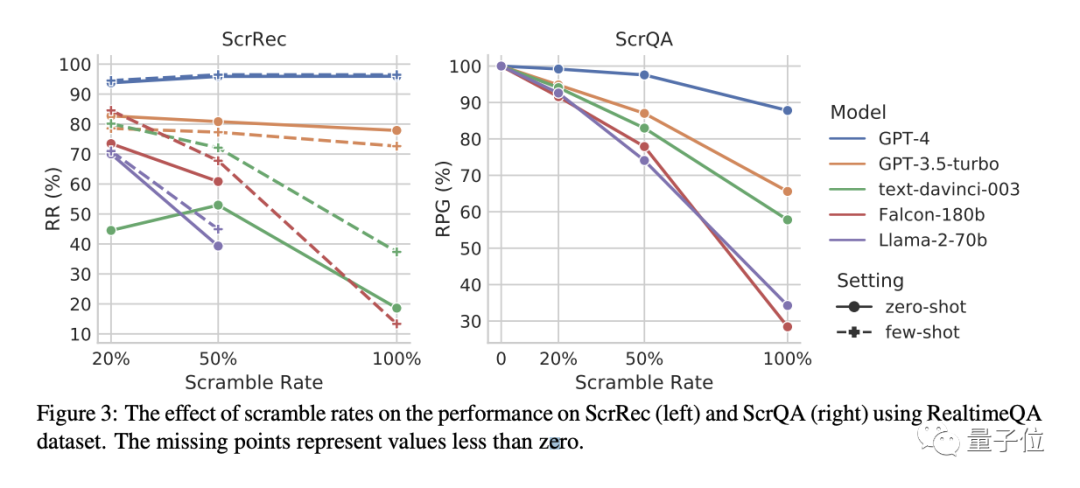
In the scrambled question-answering (ScrQA) task, as the number of scrambled words in a sentence increases, the performance of all models experiences a significant decline, and the performance gap becomes larger.
However, among them, GPT-4 still maintains a leading position with a score of 87.8%, and the decline is also the most slight.
So, to sum it up:
Most models can handle a certain proportion of scrambled text, but when it reaches an extreme level (such as completely scrambled words), only GPT-4 performs the best. When faced with completely scrambled word order, GPT-4 is hardly affected.
GPT-4 is also good at word segmentation
At the end of the article, the author points out:
In addition to scrambling the order of letters in words, the impact of inserting letters, replacing letters, and other situations can also be studied.
The only problem is that since GPT-4 is closed source, it is difficult for everyone to investigate why GPT-4 is not affected by word order.
Some netizens have found that in addition to the situation proven in this article, GPT-4 is also very good at connecting the following completely continuous English passage:
UNDERNEATHTHEGAZEOFORIONSBELTWHERETHESEAOFTRA
NQUILITYMEETSTHEEDGEOFTWILIGHTLIESAHIDDENTROV
EOFWISDOMFORGOTTENBYMANYCOVETEDBYTHOSEINTHEKN
OWITHOLDSTHEKEYSTOUNTOLDPOWER
Correctly separated:
Underneath the gaze of Orion’s belt, where the Sea of Tranquility meets the edge of twilight, lies a hidden trove of wisdom, forgotten by many, coveted by those in the know. It holds the keys to untold power.
In theory, this kind of word segmentation operation is a very troublesome thing, usually requiring dynamic programming and other operations.
The ability demonstrated by GPT-4 once again surprised this netizen.
He also put this content into OpenAI's official tokenizer tool and found that the tokens seen by GPT-4 were actually like this:
UNDER NE AT HT HE GA Z EOF OR ION SB EL TW HER ET HE SEA OF TRA
Except for "UNDER", "SEA", and "OF", almost all the remaining tokens look "illogical", which is even more puzzling.

What do you think about this?
Reference links:
[1]https://arxiv.org/abs/2311.18805
[2]https://news.ycombinator.com/item?id=38506140
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







