Source: Synced

Image Source: Generated by Wujie AI
This article is a tutorial blog on the use of Llama2 launched by Meta's official website, teaching you how to use Llama2 in 5 simple steps.
In this blog, Meta discusses the five steps of using Llama 2, so that users can fully utilize the advantages of Llama 2 in their own projects. It also provides a detailed introduction to the key concepts of Llama 2, setup methods, available resources, and provides a step-by-step process for setting up and running Llama 2.
The open-source Llama 2 released by Meta includes model weights and initial code, with parameter ranges from 7B to 70B. Llama 2's training data is 40% more than Llama, and the context length is doubled. Additionally, Llama 2 is pre-trained on publicly available online data sources.

Llama2 Parameter Description Chart
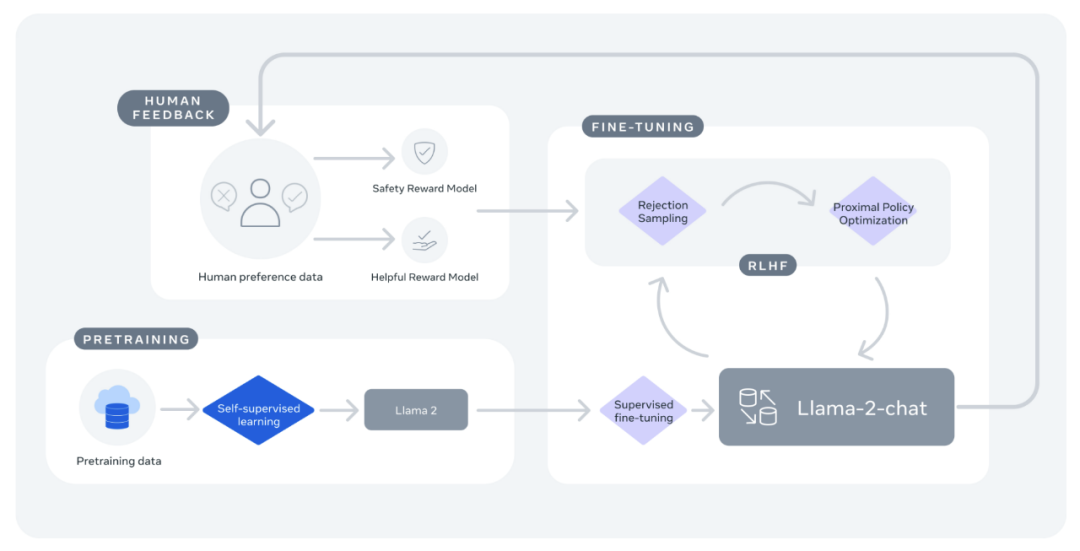
Llama2 Process Description Chart
In multiple external benchmark tests such as inference, encoding, proficiency, and knowledge testing, Llama 2 outperforms other open language models. Llama 2 can be used for research and commercial purposes for free.
The next section will introduce the 5 steps of using Llama 2. There are various methods for setting up Llama 2 locally, and this article discusses one of them, which allows you to easily set up and quickly start using Llama.
Getting Started with Llama2
Step 1: Prerequisites and Dependencies
This article will use Python to write scripts to set up and run pipeline tasks, and use the Transformer model and acceleration library provided by Hugging Face.
Step 2: Download Model Weights
The model used in this article can be found in Meta's Llama 2 Github repository. To download the model from this Github repository, two steps need to be completed:
- Visit the Meta website, accept the license, and submit the form. Only after the request is approved will you receive a pre-signed URL in an email;
- Clone the Llama 2 repository to your local machine.
Run the download.sh script (sh download.sh). When prompted, enter the pre-signed URL received in the email.
- Choose the model version to download, such as 7b-chat. Then you can download tokenizer.model and the llama-2-7b-chat directory containing the weights.
Run ln -h ./tokenizer.model ./llama-2-7b-chat/tokenizer.model to create a link to the tokenizer needed for the next transformation.
Transform the model weights to run with Hugging Face:
Meta provides the converted Llama 2 weights on Hugging Face. To use the download on Hugging Face, you must apply for the download as described above and ensure that the email address used matches your Hugging Face account.
Step 3: Write Python Script
- Next, create a Python script that will contain all the code needed to load the model and run inference using the Transformer.
- Import necessary modules
- First, import the following necessary modules in the script: LlamaForCausalLM is the model class for Llama 2, LlamaTokenizer prepares the prompt required for the model, pipeline is used to generate the model's output, and torch is used to introduce PyTorch and specify the data type to be used.
Load the model
Next, load the Llama model with the downloaded and transformed weights (stored in ./llama-2-7b-chat-hf in this example).
Define and instantiate the tokenizer and pipeline tasks
Before using the model, ensure that the input is prepared for the model by loading the tokenizer associated with the model. Add the following to the script to initialize the tokenizer from the same model directory:
Next, a method is needed to empower the model for inference. The pipeline module specifies the task type required for pipeline task execution (text-generation), the model required for inference (model), defines the precision to be used with the model (torch.float16), the device for pipeline task execution (device_map), and various other configurations.
Add the following to the script to instantiate the pipeline task for running the example:
Run the pipeline task
After defining the pipeline task, provide some text prompts as input for the pipeline task to generate responses (sequences) during execution. The pipeline task in the following example sets dosample to True, allowing the specification of a decoding strategy to select the next token from the probability distribution of the entire vocabulary. The example script uses topk sampling.
By changing maxlength, you can specify the desired length of the generated response. Setting the numreturn_sequences parameter to greater than 1 can generate multiple outputs. Add the following to the script to provide input and information on how to run the pipeline task:
Step 4: Run Llama
Now, this script is ready to run. Save the script, return to the Conda environment, enter
and press Enter to run the script.
As shown in the figure below, the model starts downloading, the progress of the pipeline task is displayed, and the input question and the generated answer after running the script are shown:
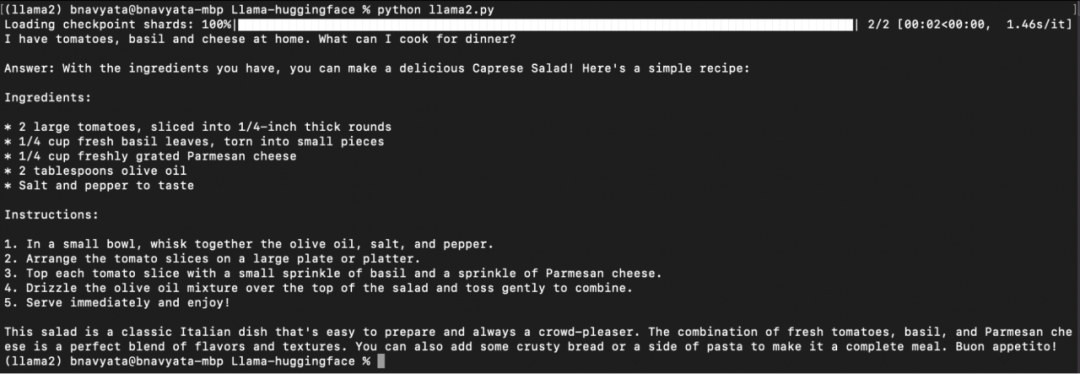
Local run 2-7b-chat-hf
Now you can set up and run Llama 2 locally. Try different prompts by providing different prompts in the string parameter. You can also load other Llama 2 models by specifying the model name when loading the model. Other resources mentioned in the next section can help you understand more about how Llama 2 works and provide various resources to help you get started.
Step 5: Level Up
To learn more about the working principles, training methods, and hardware used for Llama 2, please refer to Meta's paper "Llama 2: Open Foundation and Fine-Tuned Chat Models," which provides a more detailed overview of these aspects.
Paper link: Llama 2: Open Foundation and Fine-Tuned Chat Models
Get the model source code from Meta's Llama 2 Github repo, where the source code demonstrates how the model works and provides the simplest examples of loading the Llama 2 model and running inference. You can also find steps for downloading, setting up the model, and examples of running text completion and chat models.
Repo link: Llama 2 Github Repository
Refer to the model card to learn more about the model, including model architecture, expected use cases, hardware and software requirements, training data, results, and licensing information.
Model card link: Llama 2 Model Card
The Meta llama-recipes Github repo provides examples of how to quickly start fine-tuning and run inference for fine-tuned models.
Repo link: Llama Recipes Github Repository
Check out Meta's recently released Code Llama, an AI tool for coding built on the foundation of Llama 2, fine-tuned for the ability to generate and analyze code.
Code Llama link: Code Llama - AI for Coding
Read the "Responsible Use Guide," which provides best practices and considerations for building products supported by Large Language Models (LLM) in a responsible manner, covering various development stages from inception to deployment.
Guide link: Responsible Use Guide
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







