Original Source: SenseAI

Image Source: Generated by Wujie AI
Technological changes will affect the mechanism of information collection and distribution. After the invention of printing, people used indexes and catalogs to find books. After the emergence of the Internet, people used keywords to find links. The PageRank algorithm invented by Google co-founder Larry Page, as well as algorithmic strategies such as intent recognition, are aimed at helping users find better web links through an algorithm-centered task-based distribution mechanism.
AI makes information search no longer a one-way match of keywords and links, but a intuitive and precise two-way dialogue. Perplexity AI was the first to turn this vision into reality, with a valuation of 500 million US dollars within a year of its establishment. It is a conversational search engine created by former OpenAI employees, offering a glimpse into a future where search is not just about discovery, but also about understanding. This article starts from the historical development of search under technological changes, and delves into the top AI+ search product Perplexity AI, exploring the boundaries of search and search engines.
Product Priority: In the early stages, Perplexity used a large number of APIs to build the product. The team focused on optimizing the product, compensating for potential issues caused by the model's capabilities through profound product insights, and then developing its own infrastructure to reduce costs.
Information Interaction: With the assistance of LLM and external information interaction, Perplexity is a good example of minimizing illusions. This form is not limited to search engines; any scenario that requires interaction with external information can expect the reconstruction of LLM.
Boundaries of Search: Platforms such as Xiaohongshu and WeChat restrict the migration and closure of content, limiting the development of global search engines. However, the search itself, which used to rely on the search subject for collecting, filtering, summarizing, and integrating a large amount of information, can now externalize the search process in an interactive manner through AI. Search engines have become a new type of content platform.
AI Native Product Analysis
Perplexity AI
1. Product: Perplexity AI
2. Product Launch Time: December 2022
3. Founders:
- Aravind Srinivas: CEO, studied reinforcement learning and image recognition at UCB for his Ph.D. During his doctoral studies, he interned at OpenAI, DeepMind, and Google, and after graduating in 2021, he joined OpenAI to research language models and diffusion models.
- Denis Yarats: CTO, previously worked as a machine learning engineer at Quora and conducted research on reinforcement learning, optimal control, and robotics at Meta AI Research Institute.
- Andy Konwinski: Co-founder, also a co-founder of Databricks.
- Johnny Ho: Chief Strategy Officer, previously a quantitative trader.
4. Product Introduction:
Perplexity is a Swiss Army knife for information discovery and satisfying curiosity. It helps users summarize content, explore new topics, and inspire creativity by answering questions.
5. Development History
- In August 2022, Srinivas left OpenAI and founded Perplexity.
- In September 2022, received $3.1 million in seed funding.
- In November 2022, ChatGPT was launched.
- In December 2022, Perplexity AI was launched.
- In March 2023, Perplexity raised $25.6 million in Series A funding, with a valuation of $150 million.
- In October 2023, after launching a subscription service, achieving an ARR of $3 million, completed a new round of financing led by IVP, with a valuation of $500 million.
01. Evolution of Search
The development of search can be traced back to the evolving demand for information and the distribution methods for finding it.
The concept of search can be traced back to the emergence of printing, when people began using catalogs and indexes to help them find books and literature. In the mid-1990s, early search engines such as Yahoo! began to appear, using keyword matching to help users find web pages, but the search results were not always accurate or complete.
In 1998, Google was founded, and one of its co-founders, Larry Page, invented the PageRank algorithm, which ranks the weight and importance of a given web page by evaluating the number and quality of links between web pages. Subsequently, website owners needed to understand the PageRank algorithm and other search engine ranking factors in order to optimize their websites to improve their ranking in search engines.
Search engine optimization (SEO) experts began studying strategies such as keyword selection and usage, website content optimization, external link building, and improving user experience to adapt to Google's development. They worked to use technical means and optimization methods to make websites achieve higher visibility and ranking on search engine results pages (SERPs).
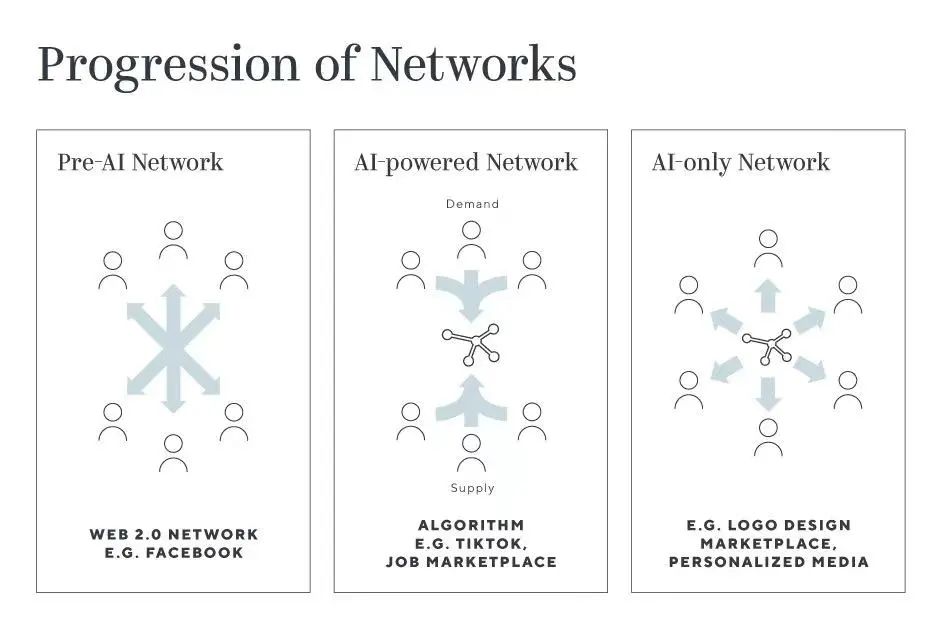
Referencing our previous article "Top Venture Capital Greylock: High-Potential Markets Reshaped First by AI," Greylock proposes that AI transforms the algorithm-centered information distribution network into a decentralized two-way network of people. For search, it is expected to no longer be a one-sided information query and SEO strategy optimization, but to become a two-way information interaction.
02. What is Perplexity AI?
Perplexity is almost the earliest generative search engine, or answer engine. Leveraging the power of large models, users can directly ask questions, and Perplexity will summarize information from various filtered sources, providing accurate and direct answers while providing source references.
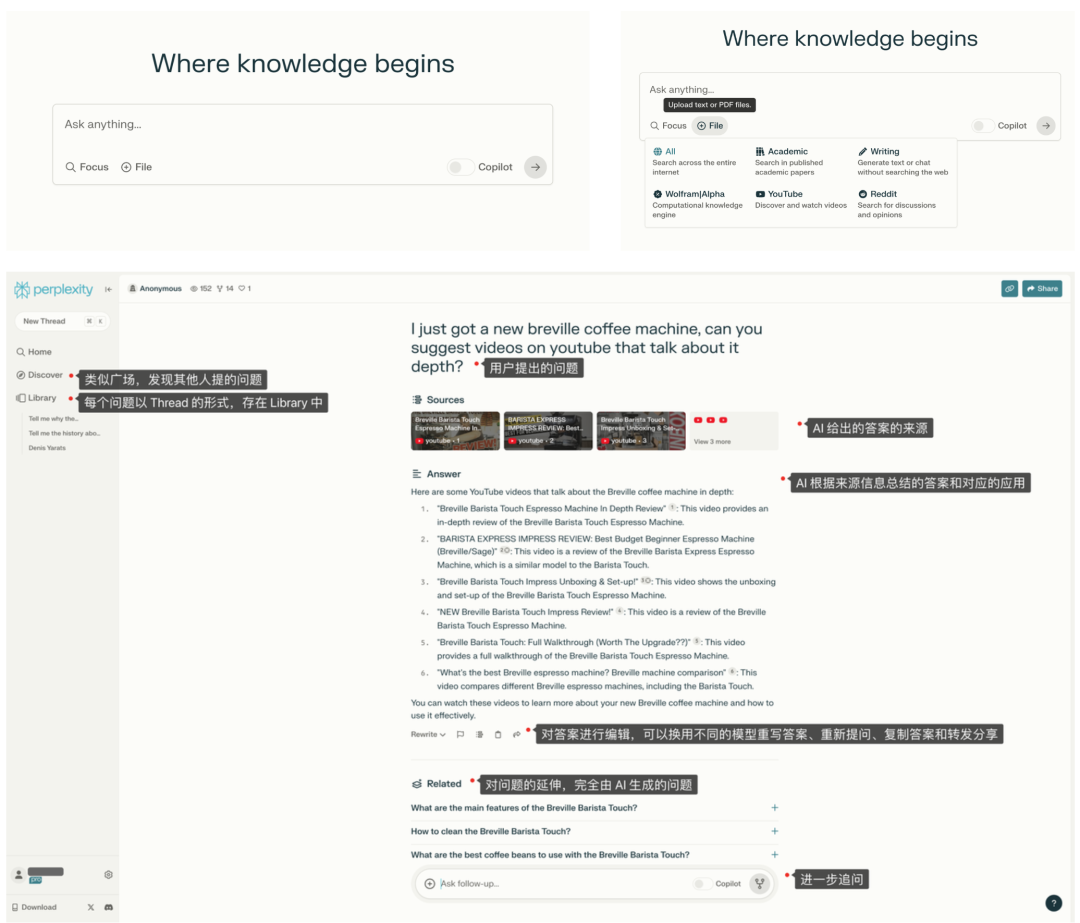
When ChatGPT was first launched, its excellent natural language understanding and rich answer generation capabilities led people to believe that generative AI might replace traditional search engines. However, as the phenomena of illusions in user experience, inability to connect to the internet, and lagging knowledge updates gradually became apparent, people began to return to reality and turn to search engines enhanced by large models, such as Perplexity and Bing Chat. These "answer engines" use Retrieval Augmented Generation (RAG) technology to process search engine results, reducing misleading information and improving the timeliness of information. In addition to Perplexity and Bing Chat, other platforms that attempted to challenge Google's dominance in the search engine market, such as You.com and Neeva, also shifted to AI-enhanced answer generation models.
Compared to traditional search engines, answer engines have been optimized in several key areas: the ability to understand user queries, the ability to summarize search results, the ability to retain search result indexes, and the ability to expand on user queries. These optimizations aim to lower the user's threshold for use, save time spent searching and browsing on different web pages, ensure the reliability of search results, and provide the ability for users to delve deeper into their queries.
It is because of these characteristics that when Bing Chat was officially launched in February of this year, Microsoft CEO Nadella had high hopes for it, seeing it as a significant milestone in opening a new era of search. He viewed it as an unprecedented challenge to Google's 20-year dominance in the search engine market. However, by the time of the antitrust case against Google in October, Nadella showed a change of heart, acknowledging that Bing Chat still had many unresolved issues and had not achieved the expected results in market share competition. Globally, the landscape of the search engine market remains stable.
Even though Perplexity still lags far behind mainstream search engines in terms of traffic, and there are many criticisms that view it as just superficial packaging, since its launch, Perplexity has maintained steady growth, maintaining the highest visit time among similar products, even surpassing You.com, which has years of experience in combining AI with search engines. In the top 50 monthly traffic GenAI products released by a16z, PerplexityAI ranks tenth. In the six months from March to October, Perplexity AI's daily search request volume has grown 6-7 times, currently processing millions of search requests every day.
Even as other large models have introduced connectivity, Perplexity continues to maintain a strong development momentum. Therefore, this article will combine actual user experiences to explore the unique features of Perplexity, which many people see as a "shell" product of GPT.
03. How Does Perplexity Stand Out? Perplexity's three major advantages: fast iteration speed, good performance, and innovative features.
Fast iteration speed, with a small update every week
As shown in the figure below, since its launch, Perplexity's important updates and milestone events are clear at a glance. In less than a year, Perplexity has achieved multiple key version iterations. Especially during the period of frequent updates, new features are released almost every week, mainly focusing on product functionality, until October of this year, when Perplexity quietly launched a large model aimed at reducing operating costs.
Analyzing the content details and data related to version updates filtered by Perplexity in tweets, including the release dates of each version and the number of likes for related tweets, it can be seen that the most liked update was the Twitter search engine launched at the end of last year. The team has keen product insights into search, and within half a month of the launch of GPT-3.5, they launched a Twitter-based SQL search analysis engine. The second most liked update is the launch of a new model, while the Perplexity team pays less attention to content updates and iterations that are more important and invested in product updates.
It can be speculated that the public's understanding of AI+ search products is still in the stage of trying out similar products, and has not yet entered into a deep experience of product functionality or formed significant user stickiness.
Innovative features, addressing the shortcomings of answer engines
"Devil in the details." Perplexity's outstanding search experience is due to its many innovative features, especially Source Edit, Focus Search, and Perplexity Copilot.
Perplexity is not always performing well. For example, when querying "Who is the CEO of Twitter," although similar products can correctly answer Linda Yaccarino, Perplexity sometimes gives the wrong answer. This error is due to its reference to outdated Wikipedia entries. To address such errors, the Source Edit feature provides an effective solution.
Source Edit allows users to edit reference sources and re-search. Currently, this feature only supports deletion rather than addition of sources, effectively reducing the interference of irrelevant sources on the results and correcting potential instability through manual means. It can be seen that after excluding the Wikipedia entry containing incorrect information, Perplexity can provide the correct answer.
In addition, users can use the Focus Search feature to limit the search scope before starting a new search, improving search effectiveness. This feature has been specially optimized for academic searches, mathematical calculations, YouTube videos, and Reddit forum searches. In particular, for YouTube video searches, it directly links to the accurate time points of relevant content in the video.
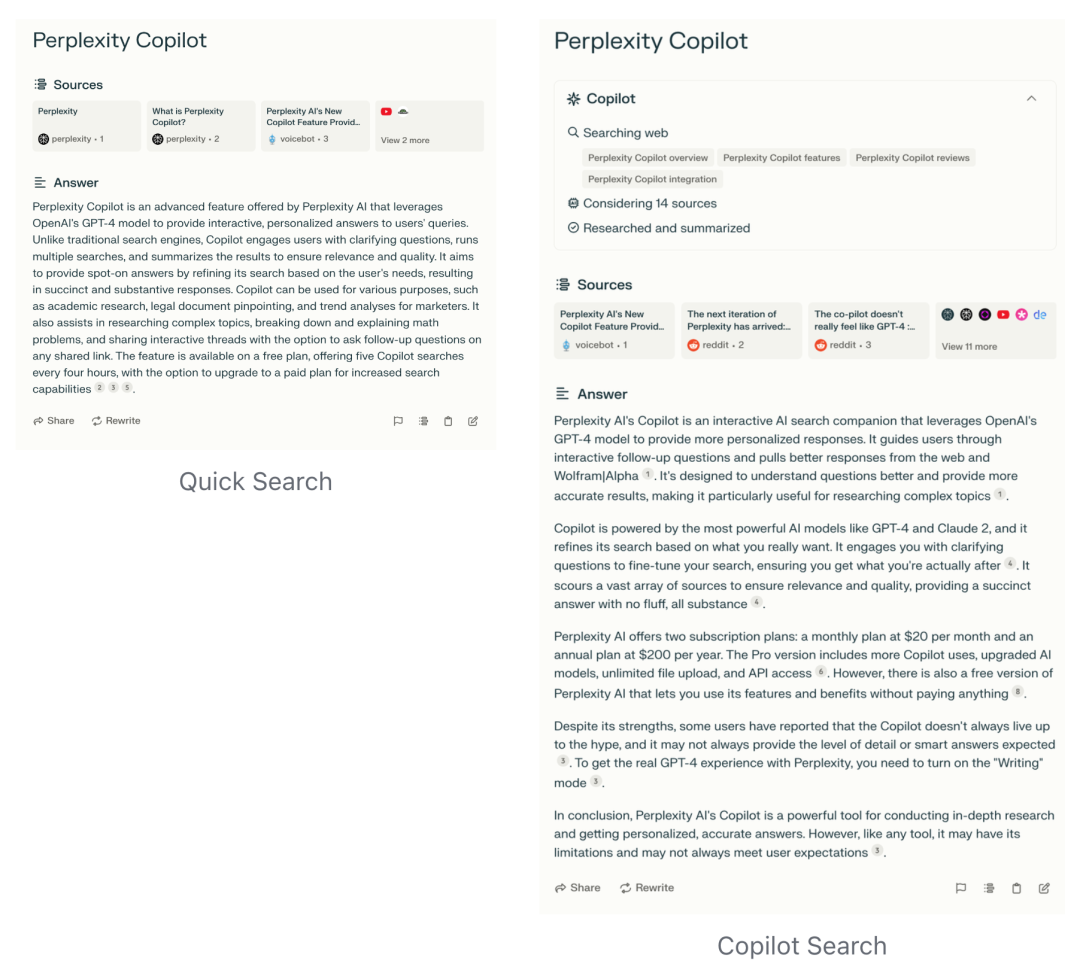
Perplexity Copilot enhances the accuracy and credibility of search results. As a user's search assistant, Copilot provides more detailed, in-depth, and personalized answers.
For the same query, Copilot Search typically references more sources, provides longer answers, and presents the information in a more structured manner. Additionally, during the search process, Copilot extends the meaning of the user's query, effectively conducting multiple searches for different keywords in a single user search. As shown in the figure below, when using Copilot to search for the same keywords, Copilot automatically extends the user's intent, conducts searches using different keywords, and ultimately summarizes the results.
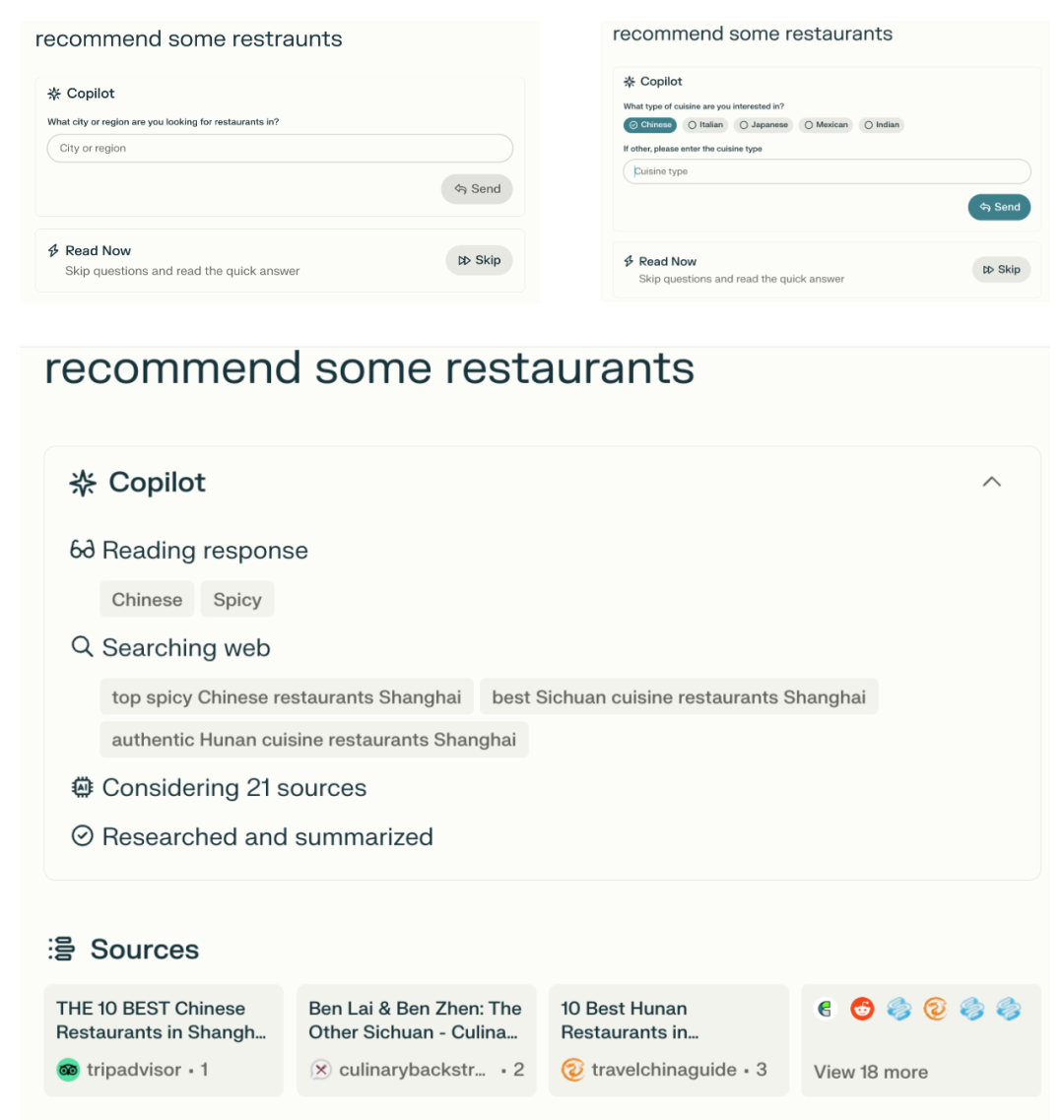
Personalized search. Perplexity Copilot not only deeply understands user intent but also provides customized content based on the user's personal situation. For example, when asking for restaurant recommendations, it will automatically request necessary information from the user, such as the location of the restaurant. At the same time, Copilot will request additional information based on the user's AI Profile. As seen in the image on the right, the author has set their city in the AI Profile in advance, so Perplexity Copilot no longer requires the user to provide address information. Finally, when Copilot requests additional information, it uses a more LLM Native interaction method, choosing the most suitable way for the user to input information, as shown in the image on the right, where it automatically generates a set of checkboxes.
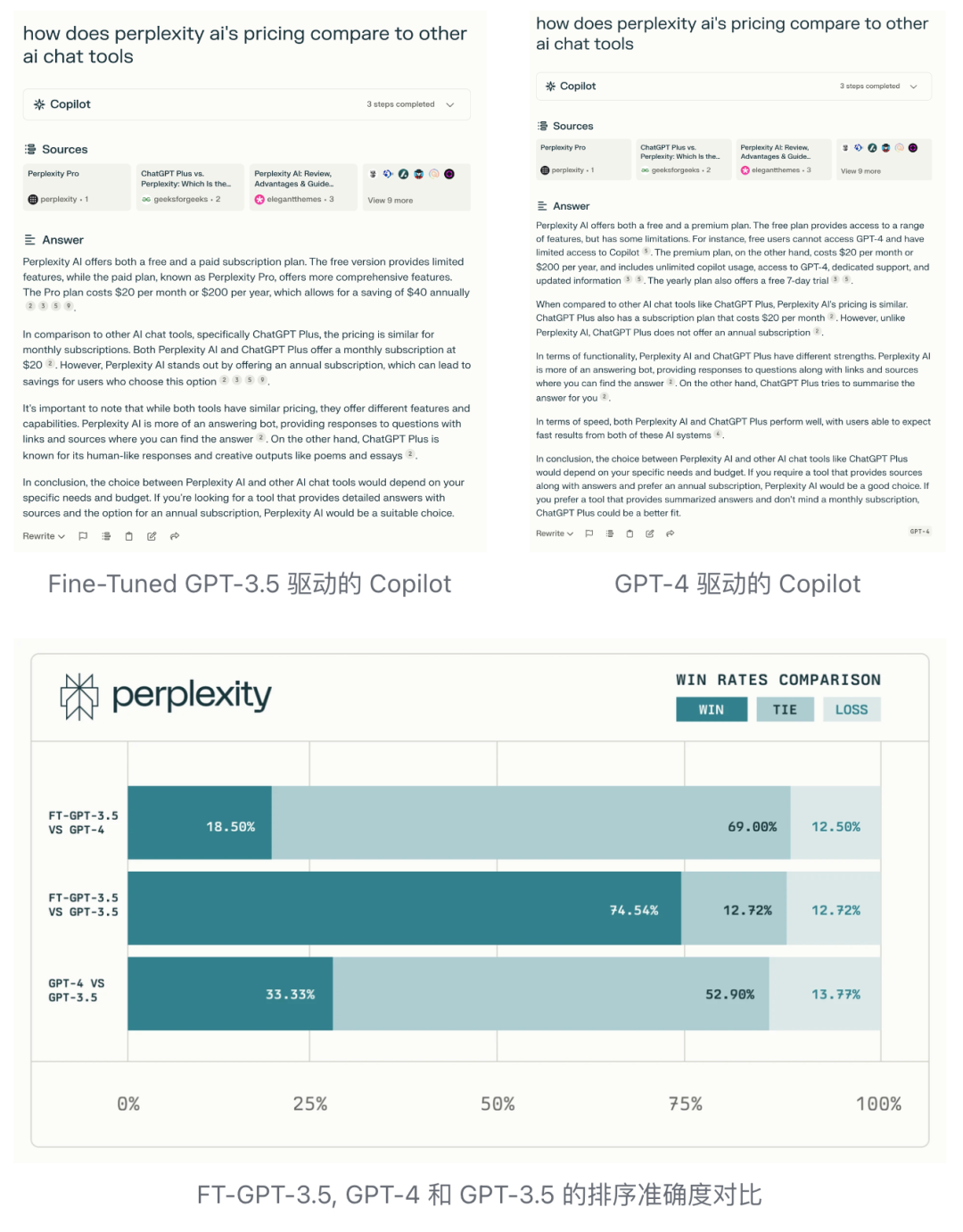
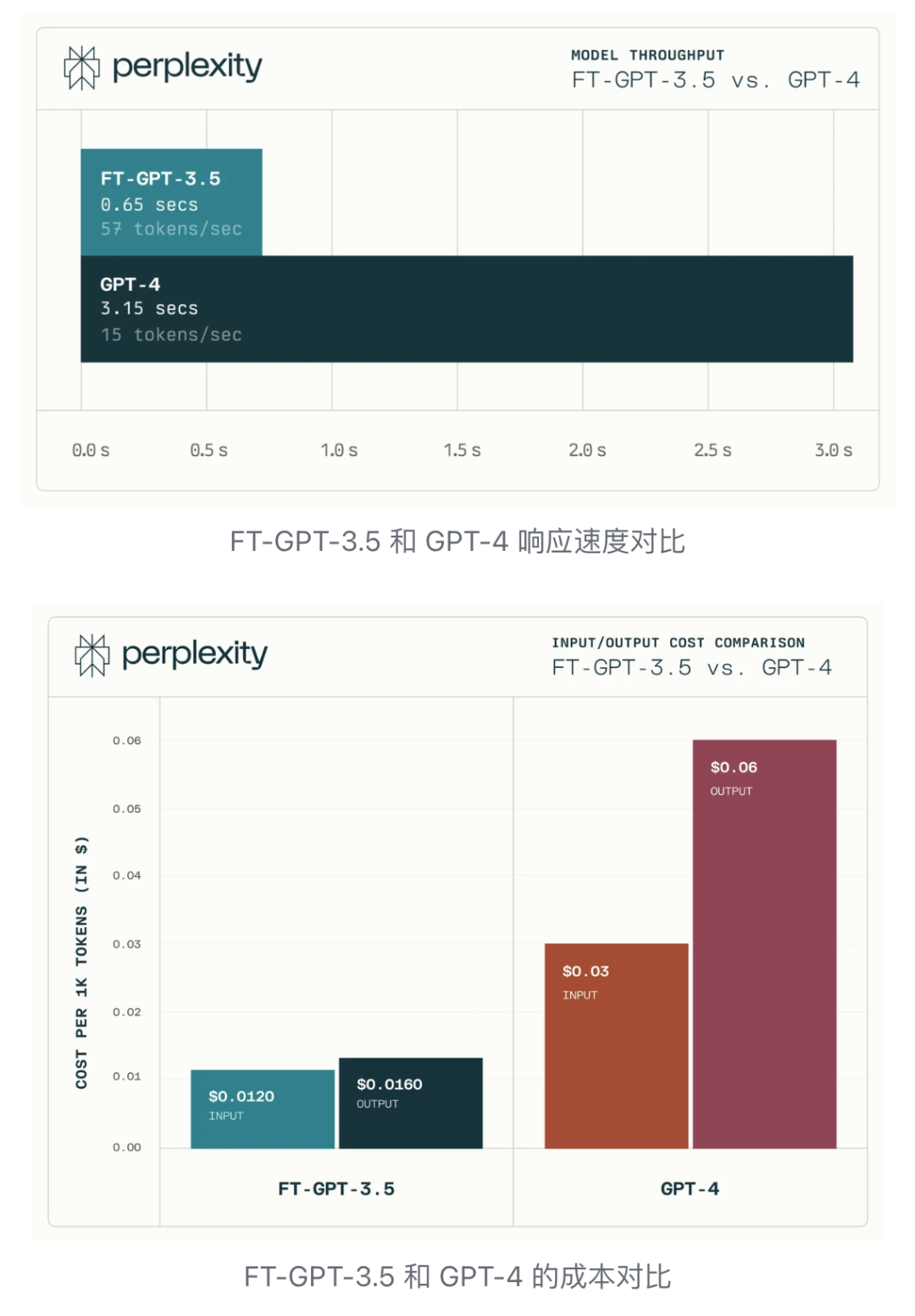
Perplexity Copilot uses Fine-tuned GPT-3.5 instead of GPT-4. According to tests, Fine-tuned GPT-3.5 can provide equivalent or even better performance than GPT-4 in most cases (69%), and in some cases, it can outperform GPT-4.
Perplexity's vision is not just to be a better search engine, but to create a comprehensive knowledge center to help users easily learn new knowledge. To achieve this, Perplexity has focused on optimizing its reference sources and divergent problem-solving capabilities from the beginning.
In September, Perplexity launched the "Collections" feature around this vision. In Perplexity, each query conversation is considered a thread, and Collections are containers for threads, similar to bookmarks. Collections not only organize threads but also expand new questions around a topic, inviting collaborators to build a knowledge community.
Excellent performance, fast, accurate, and reliable
Perplexity demonstrates outstanding performance in several aspects, especially in the reliability of content, richness of reference sources, speed of response, and stability of content.
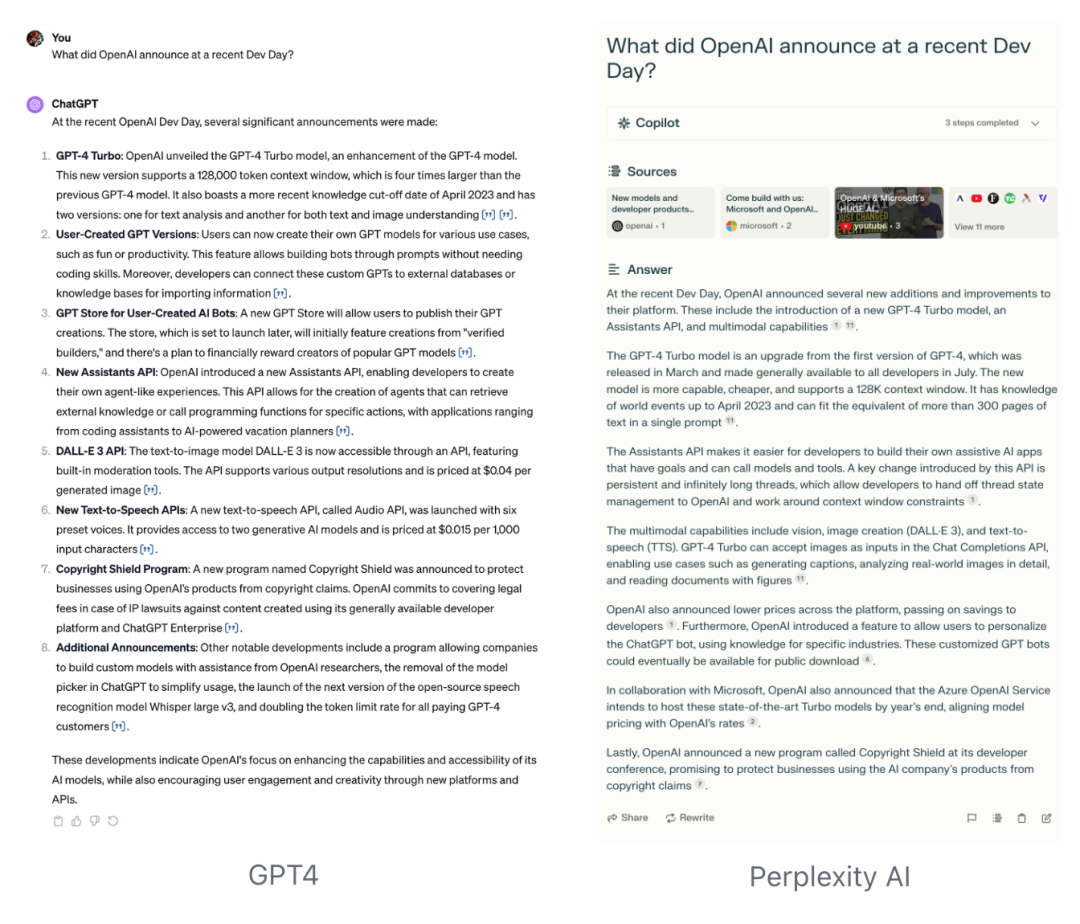
Firstly, its content reliability and richness of reference sources are particularly significant. For example, when searching for the latest Dev Day updates from OpenAI in Bard, Perplexity, GPT4, and You.com, Perplexity shows the most comprehensive reference sources and the best search results in both Chinese and English. While GPT4 depends on the correct keywords, its result quality closely follows, and Bard and You.com do not perform comprehensively in both Chinese and English searches.
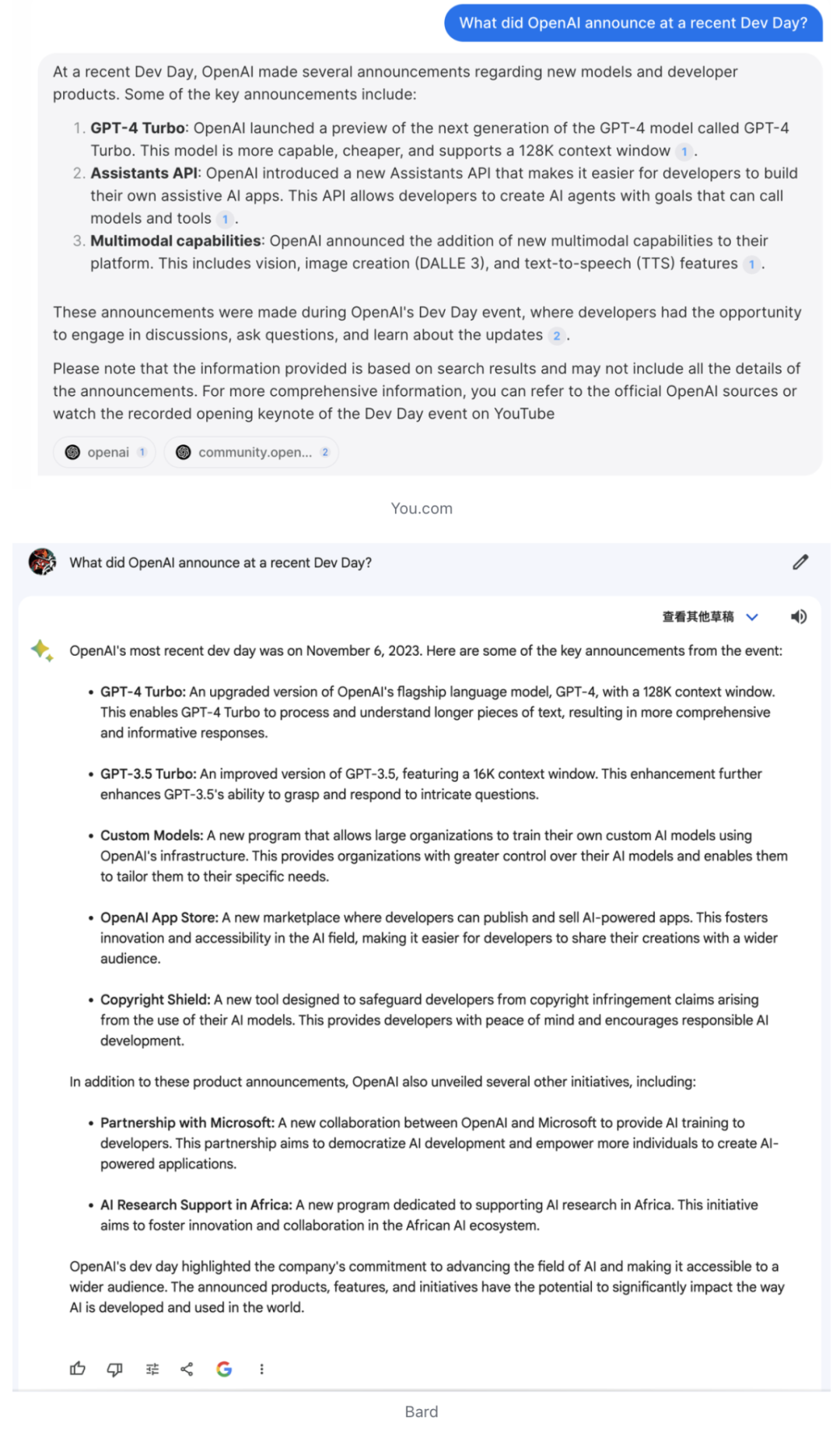
Additionally, Perplexity also demonstrates excellent stability in results and generation speed. Compared to other competitors, when repeatedly querying the same question, Perplexity can provide consistent answers based on the same reference sources, effectively reducing the uncertainty of large models. Furthermore, its answer generation speed is the fastest among all similar products.
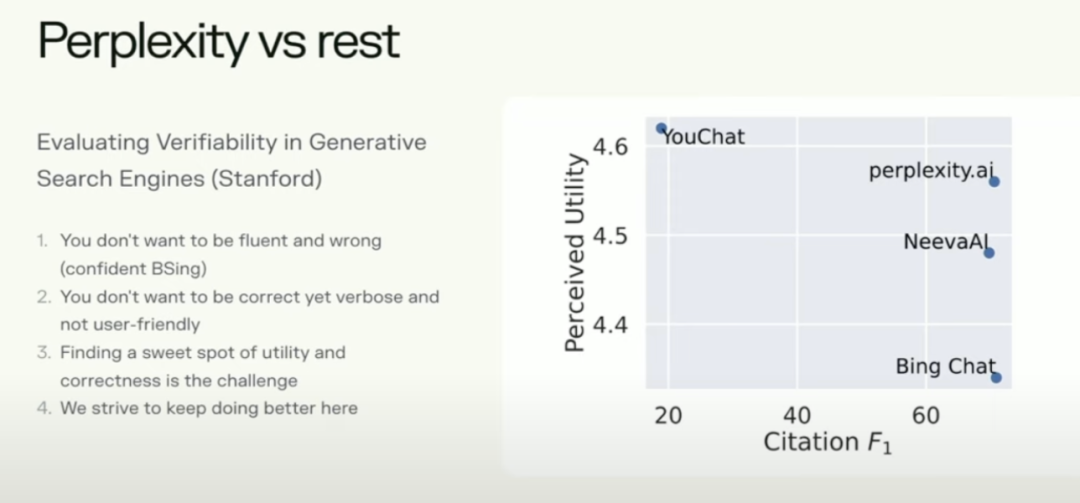
In addition to qualitative analysis from a user experience perspective, scholars have also attempted to quantitatively evaluate the effectiveness of answer engines. In April of this year, Stanford's Nelson F. Liu published a paper titled "Evaluating Verifiability in Generative Search Engines," evaluating several major search engines including Bing Chat, Perplexity, YouChat, and Neeva. This paper tested text fluency, perceived effectiveness, citation recall, and citation accuracy. Overall, Perplexity performed the best in this evaluation.
04. Shortcomings of the Perplexity AI Experience
Based on the various advantages mentioned above, some users believe that Perplexity AI can completely replace traditional search engines, while others have the opposite opinion, stating that it lacks reference sources, provides low-value results, and is difficult to replace traditional search engines.
The disparity in evaluations may stem from high expectations of answer engines and a lack of adaptation to usage habits.
High expectations
Nelson F. Liu, the author of the paper "Evaluating Verifiability in Generative Search Engines," believes that overall, these types of answer engines have far from reached their expected performance. Existing answer engines generally generate results that are very fluent and "look" informative, but they perform poorly in citation recall and citation accuracy—only 51% of the generated statements are adequately supported by cited content, and only 74.5% of citations correctly support the generated results.
The author also found a clear negative correlation between the accuracy and effectiveness of citations in the generated content. This is likely a cost to reduce illusions, reflected in the fact that the generated results often directly copy cited content or paraphrase cited content. When the cited content is not actually relevant to the user's query, this problem becomes very apparent.
For example, when a user asks "Is the driving force behind social evolution cooperation or competition?" an answer engine may cite content related to cooperation and competition in animal evolution. The author also believes that the research results cannot fully evaluate the effectiveness of answer engines because the research focuses on the verifiability of answer engine results, not their practicality, with an emphasis on citations worthy of secondary verification and citation accuracy, assuming that users want to verify search results based on the generated results. However, users should ideally receive answers without the need for secondary verification, and this expectation often falls short because answer engines are good at summarizing but not good at stitching together.

For the vast majority of factual questions, Perplexity AI performs very well and can achieve search goals without the need for external links, such as searching for OpenAI Dev Day updates, SpaceX rocket launches, or strategies for a specific temple in The Legend of Zelda: Breath of the Wild. These types of questions typically yield answers from a single webpage using traditional search methods, but answer engines like Perplexity reference multiple sources to summarize the most important information, making the response more concise.
However, sometimes the generated results may seem logical but not very useful. The reason for not finding genuinely useful information may be due to the low density of that information, which even AI cannot efficiently extract from the data. Frequently mentioned information is also more likely to be considered important and learned first by the AI. This seems to align with the logic of the current transformer's autoregressive model, where frequently occurring high-frequency information increases the probability of being predicted as the next word. When Perplexity's answer does not seem more meaningful than what is already known, it appears as if Perplexity cannot find the answer or that the answer does not exist. However, when searching on Google, deeper and more meaningful information can still be found on the first page.
In summary, users expect different levels of granularity in answers for different search queries, but Perplexity AI does not fully consider this when providing answers. The product attempts to overcome this issue by offering options such as changing models, introducing Copilot, and editing search keywords, but further optimization is still needed.
Different Usage Habits
Search Engine Optimization (SEO) research has been around for a long time and aims to improve a website's ranking in search engine results by optimizing its content. Some interesting statistics about search include:
- 69.6% of search keywords are 4 words or less in length.
- In 65% of cases, users choose a page to navigate to from search results within 10 seconds.
- In 25.6% of cases, users do not click on any search results.
- Less than 1% of cases involve users browsing the second page of search results.
- Around 59% of users can solve their problem with just one click.
Note: These statistics are approximate.
In most search scenarios, users use simple keywords and quickly filter through search results to solve their problem within one page or less. This habit does not translate well to answer engines, as these engines rely on accurately describing the problem, prompting engineering, and optimizing results through multi-turn conversations. Additionally, generating results takes longer than traditional search engines. Perplexity AI attempts to mitigate this issue by displaying reference sources before generating results, but it is still slower than traditional methods.
High expectations and different usage habits lead to the need for more detailed search criteria and longer time to obtain similar results from answer engines for quick search queries that can be solved by opening a single page in traditional search. For complex search queries that rely on cross-verification from multiple pages, answer engines may appear to have incomplete reference sources or insufficient capabilities, unable to provide valuable information, requiring users to use traditional search engines to re-search.
05. Can Answer Engines Disrupt Search Engines?
Although answer engines are highly anticipated, disrupting traditional search engines remains a distant goal.
For example, Neeva, founded in 2019, aimed to challenge Google by investing heavily in building its own index and ranking system to provide a better user experience without ads. Neeva's user research and internal metrics were close to Google's level, but just two years later, it closed its consumer-facing business due to a lack of sufficient users. This indicates that improving user experience alone is difficult to change the landscape of the search engine market.
In the past, search engines have established strong barriers. Microsoft's CEO Nadella and Neeva's co-founder Ramaswamy have both stated that the search engine market is one of the most difficult to penetrate, as the vast majority of users do not change their default search engine. Additionally, the more users use the default search engine (Google), the more it can continuously optimize search results through a large amount of user data, making its leading position seemingly unshakable.
In addition to the barriers established by traditional search engines, answer engines also face common issues based on large models, such as cost and feedback mechanisms.
Most current answer engines are built on traditional search engines and large model APIs, focusing more on optimizing models and RAG (Retrieval-Augmented Generation). Additionally, answer engine products generally have not found a reasonable business model. Many competing products of Perplexity AI are still completely free, and relying solely on subscription revenue makes it difficult to meet the high demand for APIs, preventing the possibility of answer engines completely replacing traditional search engines at this stage. Currently, Perplexity AI is attempting to build its own WebCrawler, Search index, and LLM to reduce costs in response to the growing number of query requests.
Furthermore, answer engines have not found a way to integrate user feedback into the product's normal usage, similar to search engines or information flow recommendations. This makes it difficult to build a data flywheel based on first-mover advantage and user accumulation. According to CEO Aravind Srinivas, only about 10% of users provide feedback, and users may not like AI-generated results for various reasons. Disliking the results does not necessarily mean they are not good; it may simply be because the AI's summary has missed some of the results the user hoped for. As mentioned earlier, user expectations for summaries are not stable and consistent, and what AI considers good may not be what humans consider good. In this regard, Perplexity AI cannot use every click or like from users to further optimize the product, as Google or TikTok can. It still relies on external contractors to annotate user data to further optimize the model.
06. More Than Just Search Engines
The real threat to search engines may not be another tool, but the centralized migration and closure of content.
Over the past decade, user-generated content has shifted from open forums and blogs that are well-indexed by search engines to platforms like WeChat Official Accounts, Xiaohongshu, Douyin, Instagram, Twitter, and even Amazon, which are not as well-indexed by search engines. These platforms have become the preferred search tools for many people in specific scenarios. In the future, these ecosystems are likely to have their own AI search assistants. Not only content platforms, but knowledge management platforms like Feishu and Notion also plan to launch their own AI search assistants, with similar experiences and usage methods to answer engines, but with a focus on private databases.
In any scenario, AI-driven search is an assistant for user and external information interaction. Ideally, AI-driven search will help facilitate an intuitive two-way dialogue between users and information, rather than a one-way match based on keywords.
In addition to the model's understanding and processing capabilities of information, the size of the database will also be an important factor limiting the ceiling of products like answer engines. The impact of closed platforms like content platforms on search engines will also affect the future of answer engines. How to build a unique database or access more external databases may be a focus of development beyond product and model capabilities. For example, to some extent, can Rewind AI be considered a search product based on user screen recording data?
The team at Perplexity AI is also aware of the barriers of search engines and the trend of content changes. Therefore, they have not chosen to compete in the direction of vertical fields, such as shopping assistants or lifestyle assistants, because they cannot compete with Amazon and TikTok in terms of data. Instead, they have chosen to explore the direction of becoming a knowledge content platform.
By allowing users to share and save their multi-turn conversations with Perplexity AI, they are attempting to build a content community. Although AI currently performs well in terms of expressive ability, the potential of becoming a knowledge platform is limited by the large amount of seemingly reliable but impractical content generated by AI.
However, the good news is that search engines still help users solve practical problems in many scenarios, and both search engines and answer engines can still provide reliable value. It is often said that search itself is a capability that requires a lot of information gathering, filtering, summarizing, and integrating. These processes of information processing were previously part of the workflow of the search subject but could not be disseminated, as most of it was done in the search subject's mind and personal knowledge base. As AI replaces users in processing and presenting information, the search process itself also has the potential to become an interactive form of content. This may be the potential for Perplexity AI to become a content platform.
Reference Material
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







