ZK Rollup and coprocessors can increase the number of available transactions and reduce costs. ZK proofs may become the dominant mode of access to trustless computation, moving towards the paradigm of "don't trust, verify."
Author: Emperor, 0xkrane
Translation: Lynn, Mars Finance
Blockchain is a globally distributed ledger that can achieve consensus on the global state. Some blockchains are equipped with Turing-complete execution environments, enabling programmability on this global state. Programs targeting the blockchain execution environment are called smart contracts, and the underlying blockchain is called a smart contract platform. Ethereum, Solana, and Avalanche are the most well-known smart contract platforms. We can view smart contract platforms as distributed computers, with the execution environment (or virtual machine) acting as the CPU and the state acting as storage.
This framework of viewing the blockchain as a computer is crucial for explaining why coprocessors/off-chain computing is inevitable, especially in the context of blockchain. In traditional computing, coprocessors originated from microarchitecture, aiming to improve performance. Similarly, coprocessors on Ethereum promise access to historical data and high-performance offline computation to enhance the functionality and design space of the underlying protocol. Refer to this introductory article on coprocessors for more information.
This article starts from the basic principles to explore coprocessors, aiming to clarify their importance and meta-properties. Then, we compare them with rollups, demonstrating that although these two concepts are different, they are closely related. We also provide examples of when rollups and coprocessors can be used together. For example, even an all-powerful rollup or L1 may still require coprocessors to perform heavy tasks.
We conclude this article by observing that blockchains are moving towards a future of computational centralization while verification remains decentralized. Rollups, coprocessors, and any other form of verifiable off-chain computation are just different instances of this future.
How did we get here:
Vitalik mentioned in "The Limits to Blockchain Scalability" that it is very important for decentralization of blockchains that ordinary users can run nodes.
As mentioned earlier, Ethereum can be conceptualized in many ways as a decentralized global computer. It is a network of nodes running software, providing computational resources for executing smart contracts. The Ethereum blockchain stores state information and code, similar to the storage and memory of a computer. The Ethereum Virtual Machine (EVM) runs on each node, processing transactions and executing code like a CPU. However, Ethereum is permissionless and decentralized, using consensus among untrusted nodes. If some nodes go offline, the network continues to operate. To ensure the correctness of EVM operations, validators on proof-of-stake (PoS) networks like Ethereum must execute all state transitions to verify them. This limits the speed of PoS networks to the slowest nodes, restricting the computational capacity available to application developers.
Unlike regular computers, Ethereum restricts computation and storage to prevent network abuse. Fees are charged for each operation, making infinite loops economically impractical. This approach lowers the barrier to entry, allowing everyday hardware like Raspberry Pi to run network nodes. These limitations make it possible to create an inclusive system where anyone can help operate the decentralized Ethereum network.
Due to these computational limitations of Ethereum nodes, complex applications such as machine learning models, games, or scientific computing applications cannot currently run directly on Ethereum.
To make Ethereum widely accessible, secure, and sustainable as the foundation for basic applications, this is a trade-off. However, it is inevitable that there are some limitations compared to unrestricted computing. Even compared to ancient processors like the Pentium 5, it has limitations:
- No complex floating-point math - EVM only supports basic math and logical operations. Advanced numerical calculations like neural networks are not feasible. (An interesting note is that the inability to handle floating points has made it more difficult for assets like Ampleforth to be traded in recent history, sometimes even incompatible with certain DEXs).
- Limited computation per block - Gas fees are calculated, so complex software like games will be very expensive. The gas limit per block is 30M Gas.
- Limited memory - Permanent storage for smart contracts is small, making large programs difficult.
- No persistent file storage - Unable to store files such as graphics, audio, or video on the blockchain.
- Slow speed - Transaction speed on Ethereum is currently about 15 TPS, many orders of magnitude slower than a CPU.
Ultimately, limited storage and computation restrict the freedom available to applications (these limitations vary by blockchain, but they always exist). People compare blockchain to the computing-constrained environment of the 1970s and 1980s, but we believe there are some significant differences between the two:
- In the 1970s and 1980s, computing technology developed rapidly (the number of transistors in microprocessors increased from about 1,000 to about 1,000,000 during this period). However, this growth did not necessarily mean that people frequently purchased or updated their computers. Due to the constraints of the slowest nodes, the acceleration of cutting-edge computers does not necessarily lead to a proportional increase in blockchain computing speed. Only updating the benchmark requirements of nodes on the blockchain can achieve acceleration.
- There is also a clear trade-off between continuously updating the minimum hardware requirements for nodes and decentralization. Individual stakers may not want to upgrade hardware every few years (they certainly do not want to monitor performance every day), leading to only professional infrastructure providers being viable for running blockchain infrastructure.
All of this indicates that over the years, CPUs have improved, and we have gained more CPU cores on every device, allowing us to perform increasingly complex tasks. If we believe that the speed of blockchain computers will not be as fast as traditional computing (due to benchmark node requirements), it makes sense to try to find alternative sources of computation. Here's an interesting analogy: CPUs in traditional computing are not good at graphics processing tasks, leading to the rise of GPUs in almost every computer. Similarly, since blockchains focus on being secure state storage enabling simple computation batteries, off-chain computing clearly has the opportunity to expand the application design space. Today, blockchains only make sense for low-computation applications that require open access, self-sovereignty, resistance to censorship, and composability. To put more types of applications on the chain, we need to remove restrictions on application developers. The premise of what we are saying is that these restrictions are also beneficial for experimentation. For example, due to computational limitations, CLOB cannot run effectively on Ethereum, so AMM has been adopted, with its trading volume reaching trillions of dollars.
There are two common ways to provide more computational power for blockchain applications:
Relatively frequently increase the baseline node requirements. This is roughly the path taken by integrated high-performance blockchains like Solana and Sui. The high baseline of nodes allows them to build very fast blockchains and also eliminates some design restrictions in application design. Phoenix is a limit order book DEX on Solana that cannot currently be built on Ethereum (or any L2). The flip side of the continuously increasing baseline requirements is that if they continue to grow, running nodes may only be feasible for professional infrastructure providers. The historical RAM requirements nicely demonstrate how hardware requirements on Solana have continued to grow:
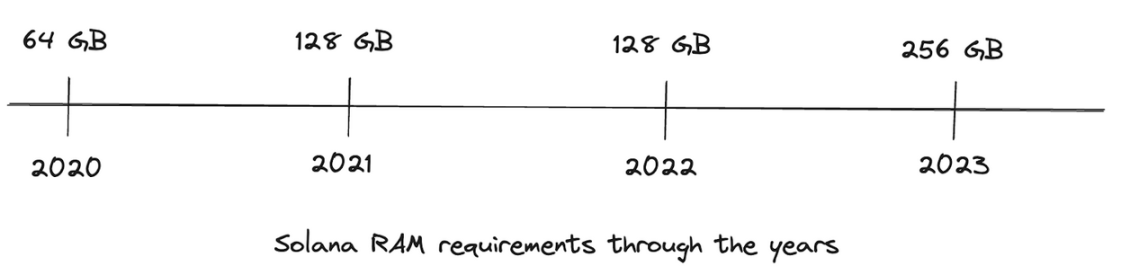
Archive (Note: We use the 2020 median RAM requirements) moves computation to third parties off-chain. This is the strategy adopted by the Ethereum ecosystem. These third parties can themselves be blockchains (in the case of aggregation), off-chain verifiable computing devices (i.e., coprocessors), or trusted third parties (such as dydx order books for specific off-chain computing cases).
Unified Move Towards Off-Chain Computing
Recently, there has been an increased discussion about coprocessors, which provide off-chain verifiable computation. Coprocessors can be implemented in various ways, including but not limited to zero-knowledge proofs or trusted execution environments (TEEs). Some examples are:
- ZK Coprocessors: Axiom, Bonsai by Risc Zero.
- TEE: Marlin’s Oyster.
At the same time, in terms of offloading computation, Ethereum's rollup-centric roadmap unloads computation to various aggregations on Ethereum. Over the past few years, developers and users have been migrating to rollups due to their cheaper, faster transactions, and incentives. In an ideal world, rollups allow Ethereum to expand its overall computational capacity through off-chain execution without adding trust assumptions. More computation not only refers to executing more transactions but also means more expressive computation for each transaction. New transaction types expand the design space available to applications, and higher throughput reduces the cost of executing these expressive transactions, ensuring access to more advanced applications in an economical manner.
Before delving further, let's briefly define aggregation and coprocessors to avoid confusion:
Rollups: Rollups maintain persistent partitioned states different from their base/host chain but still inherit their base's security properties by publishing data/proofs to it. By moving the state off the host chain, aggregations can use additional computation to execute state transitions before publishing integrity proofs of these transitions to the host. Rollups are most useful for users who want to access Ethereum's security properties without paying high Ethereum fees.
Before delving into coprocessors, let's first understand the limitations of smart contract development on Ethereum. Ethereum has persistent state storage in its global state - account balances, contract data, etc. This data is retained on the blockchain indefinitely. However, there are some limitations:
- The maximum size of contract data is limited (e.g., currently 24KB per contract, set in EIP 170). Storing large files would exceed this limit. (*Coprocessors cannot solve this either)
- Reading/writing contract storage is slower than a file system or database. Accessing 1KB of data may cost millions of Gas.
- While the global state persists, individual nodes only retain the most recent state locally in "pruned" mode. Full state history requires archival nodes.
- There are no native file system primitives for handling images, audio, and documents. Smart contracts can only read/write basic data types to storage.
The solutions around this problem are:
- Large files can be split into smaller parts to fit within contract storage limits.
- File references can be stored on-chain, and files can be stored in off-chain systems such as IPFS.
Coprocessors: Coprocessors themselves do not maintain any state; their behavior is similar to lambda functions on AWS, where applications can send computational tasks to them, and they return results with computational proofs. Coprocessors fundamentally increase the available computational capacity for any given transaction, but using them will be more expensive than aggregations, as proofs on coprocessors are also done on a per-transaction basis. Considering the cost, coprocessors may be useful for protocols or users who want to execute complex one-time tasks in a verifiable manner. Another benefit of coprocessors is that they allow applications using off-chain computation to access Ethereum's complete historical state without adding any trust assumptions to the application itself, which is not possible in today's regular smart contracts.
To further understand the differences between rollups and coprocessors, let's refer to the ZK-style of these two primitives. ZK rollups can access verifiability and compression aspects of zero-knowledge proofs, fundamentally increasing the ecosystem's throughput. On the other hand, coprocessors only access the verifiability property of zk proofs, meaning the overall throughput of the system remains unchanged. Additionally, ZK rollups require the construction of circuits to prove programs for the virtual machine of the rollup (e.g., zkEVM has been built for contracts targeting EVM on Ethereum). In contrast, ZK coprocessors only need to build circuits for the tasks they are meant to execute.
Therefore, the two biggest differences between rollups and coprocessors seem to be:
- Rollups maintain persistent partitioned states, while coprocessors do not maintain (they use the state of the host chain).
- Rollups (as the name suggests) batch multiple transactions together, while coprocessors are typically used for complex tasks as part of a single transaction (at least in the current example).
Recently, Booster Rollups have been proposed, which execute transactions as if running directly on the host chain and can access the complete state of the host. However, Booster Rollups also have their own storage, allowing them to extend computation and storage across the host and rollup. The Booster Rollup proposal points out the spectrum in off-chain computation design space, with traditional rollups and coprocessors at the two ends of that spectrum. Rollups, Booster Rollups, and Coprocessors all provide access to more computation, with the only difference being that they retain the amount of state from the underlying L1 partition.
In a talk titled "Shielded Transactions are Rollups" at the 2023 Modular Summit, Henry De Valence discussed this exact concept and presented a very simple image to define rollups:
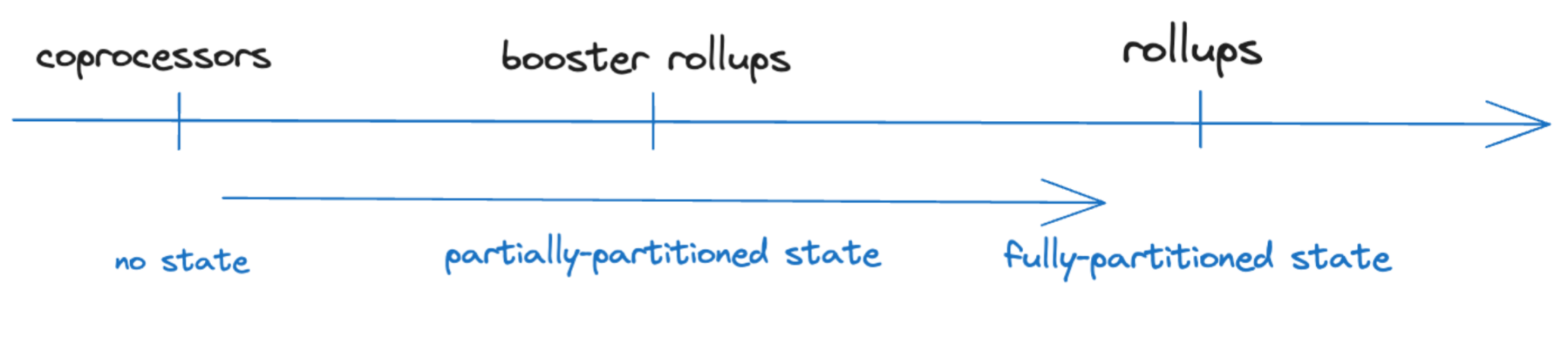
The talk assumes that any execution offloaded to third parties from the base chain is a rollup. According to his definition, coprocessors would also be rollups. This slightly differs from the view of unifying rollups and coprocessors under the banner of off-chain verifiable computing, but the overall sentiment remains the same!
In his Endgame vision, Vitalik discusses a future of centralized block production, untrusted and highly decentralized block validation. We believe this is roughly the right model for thinking about what is happening now. In zk-rollup, block production and state transition computation are centralized. However, proofs make validation cheap and decentralized. Similarly, zk coprocessors do not have block production; they only access historical data and compute the state transitions of that data. Computation on zk coprocessors may always be executed on centralized machines; nevertheless, the validity proofs returned with the results allow anyone to verify them before using the results. Perhaps restating Vitalik's vision correctly: "The future of computation is centralized, but the validation of centralized computation is untrusted and highly decentralized."
Familiar Yet Different
Although similar overall, rollups and coprocessors now serve vastly different markets. One might ask, "If we can use coprocessors on ETH L1 and access their liquidity, why do we need rollups?" While this is a fair question, we believe there are several reasons to explain why rollups still make sense (and provide a larger market opportunity than coprocessors today):
- As mentioned earlier, coprocessors allow you to access more computation than L1 in the same transaction. But they do not help change how many transactions the blockchain calling the coprocessor can execute (if you're thinking about batching, well, you've already reached rollup). By maintaining persistent partitioned states, rollups can increase the number of transactions available to those who want to access block space with Ethereum's security properties. This is possible because rollups only publish to Ethereum every n blocks and not all Ethereum validators need to verify if state transitions have occurred. Interested parties can rely on evidence.
- Even if you use coprocessors, you still need to pay fees of the same order of magnitude as any other transaction on L1. On the other hand, batching through rollup can reduce costs by several orders of magnitude.
Furthermore, since rollup provides the ability to run transactions on this separate state, their behavior still resembles a blockchain (a faster, less decentralized blockchain, but still a blockchain), so they also have explicit limitations on the amount of computation accessible from the rollup. In this case, coprocessors are very useful for rollup if users want to execute arbitrarily complex transactions (now you are executing verifiable transactions on rollup, so you just need to comply with the physical laws of rollup).
Another point to note here is that currently, most liquidity resides on ETH L1, so it may still be a wise choice to launch on the Ethereum mainnet for many protocols that rely on liquidity to improve their products. Applications on the Ethereum mainnet can access more computation by intermittently executing transactions on coprocessors. For example, DEXs like Ambient or Uniswap v4 can use hooks with coprocessors to execute complex logic to determine how to change fees, and even modify the shape of liquidity curves based on market data.
An interesting analogy compares the interaction between rollups and coprocessors to imperative programming and functional programming. Imperative programming focuses on mutable state and side effects, specifying how tasks are executed step by step. Functional programming emphasizes immutable data and pure functions, avoiding state changes and side effects. Similarly, rollup is like imperative programs that modify the state they hold, while coprocessors are like functional programs that do not change the state but produce results and computational proofs. Additionally, just like imperative programming and functional programming, rollups and coprocessors also have their own use cases and should be used accordingly.
Evidence-Based Future
If we eventually enter a centralized world of computation, but the validation of centralized computation is untrusted and highly decentralized, where will Ethereum go? Will the world computer be simplified to a database? Is that a bad thing?
Ultimately, Ethereum's goal is to enable users to access computation and storage without trust. In the past, the only way to access trustless computation on Ethereum was for all nodes to execute and verify the computation. With the advancement of proof technology (especially zero-knowledge proofs), we can move most of the computation happening on validator nodes to off-chain computation, and only have validators verify the results on-chain. This essentially turns Ethereum into an immutable public bulletin board. Computational proofs allow us to verify if transactions are completed correctly, and by publishing them to Ethereum, we can obtain timestamps and immutable historical storage of these proofs. With zero-knowledge proofs becoming more efficient on arbitrary computations, at times, the cost of computation in ZK may be significantly lower than on the blockchain (even possibly on a CometBFT chain with 100 validators). In such a world, it is hard to imagine ZK proofs not becoming the dominant mode of access to trustless computation. David Wong recently expressed a similar idea:
In the future, any computation can be proven, which also allows us to build infrastructure for various trustless applications with user demand, rather than trying to retrofit the Ethereum base layer to be the home for these applications. Ideally, customized infrastructure will create a more seamless user experience and will also scale with the applications built on top of it. This is expected to enable web3 applications to compete with web2 applications and usher in the trustless, evidence-based future that cypherpunks have always dreamed of.
In conclusion, we believe we are moving towards the following paradigm:
Don't Trust, Verify.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。





