Source: AIGC Open Community

Image source: Generated by Wujie AI
The "MIT Technology Review" once published an article on its official website, stating that with the continuous popularity of large models such as ChatGPT, the demand for training data is increasing. Large models are like a "network black hole" constantly absorbing, which will eventually lead to insufficient data for training.
The well-known AI research institution Epochai directly addressed the issue of data training in a paper, pointing out that by 2026, large models will deplete high-quality data; by 2030-2050, all low-quality data will be depleted;
By 2030-2060, all image training data will be depleted. (Here, data refers to raw data that has not been marked or contaminated)
Paper link: https://arxiv.org/pdf/2211.04325.pdf

In fact, the problem of training data has already surfaced. OpenAI stated that the lack of high-quality training data will become one of the major challenges in developing GPT-5. It's like when a person's knowledge reaches the level of a doctorate, showing them knowledge from junior high school would be of no help.
Therefore, in order to enhance the learning, reasoning, and general AGI capabilities of GPT-5, OpenAI has established a "data alliance," hoping to extensively collect private, ultra-long text, video, audio, and other data to allow the model to deeply simulate and learn human thinking and working methods.
Currently, organizations such as Iceland and the Free Law Project have joined the alliance, providing various data to OpenAI to help accelerate model development.
In addition, as AI content generated by models such as ChatGPT, Midjourney, and Gen-2 enters the public network, this will seriously pollute the public data pool created by humans, leading to homogeneity, single logic, and other features, accelerating the consumption of high-quality data.
High-quality training data is crucial for the development of large models
From a technical standpoint, large language models can be seen as "language prediction machines," which establish patterns of association between words by learning a large amount of text data, and then use these patterns to predict the next word or sentence in the text.
The Transformer is one of the most famous and widely used architectures, which ChatGPT and others have drawn inspiration from.
In simple terms, large language models mimic human language. So, when you use models like ChatGPT to generate text, you may feel that the narrative patterns of these texts are familiar.
Therefore, the quality of training data directly determines whether the structure learned by the large model is accurate. If the data contains a large number of grammatical errors, improper wording, inaccurate punctuation, false content, etc., then the content predicted by the model will naturally contain these issues.
For example, if a translation model is trained using low-quality fabricated content, the AI's translation output will naturally be very poor.
This is also why we often see many models with very few parameters but stronger performance and output capabilities than high-parameter models, one of the main reasons being the use of high-quality training data.
In the era of large models, data is king
Due to the importance of data, high-quality training data has become a precious resource that OpenAI, Baidu, Anthropic, Cohere, and other manufacturers must compete for, becoming the "oil" of the era of large models.
As early as March of this year, while the domestic industry was still fervently researching large models, Baidu had already taken the lead in releasing a generative AI product, Wenxin Yiyansheng, which is benchmarked against ChatGPT.
In addition to its strong R&D capabilities, Baidu's massive Chinese language corpus data accumulated through its search engine over more than 20 years has played an important role in multiple iterations of Wenxin Yiyansheng, far ahead of other domestic manufacturers.
High-quality data typically includes published books, literary works, academic papers, school textbooks, authoritative media news reports, Wikipedia, Baidu Baike, etc., and data such as text, video, and audio that have been verified by humans over time.
However, research institutions have found that the growth of such high-quality data is very slow. For example, in the case of published books, it takes several months or even years to publish a book after going through market research, initial drafts, editing, and re-review. This data production speed is far behind the growing demand for training data for large models.
Looking at the development trend of large language models over the past 4 years, the annual training data volume has grown by more than 50%. In other words, every year, twice the amount of data is needed to train the model in order to achieve performance and functionality improvements.
Therefore, you will see many countries and companies strictly protecting data privacy and enacting relevant regulations. On the one hand, this is to protect users' privacy from being collected by third-party organizations and prevent theft and misuse;
On the other hand, it is to prevent important data from being monopolized and hoarded by a few organizations, leaving no data available for technical development.
By 2026, high-quality training data may be depleted
In order to study the issue of training data consumption, Epochai's researchers simulated the language and image data produced globally each year from 2022 to 2100, and then calculated the total amount of this data.
They also simulated the consumption rate of data by large models such as ChatGPT. Finally, they compared the growth rate of data and the rate of consumption, leading to the following important conclusions:
Under the current rapid development trend of large models, by 2030-2050, all low-quality data will be depleted; high-quality data is highly likely to be depleted by 2026.
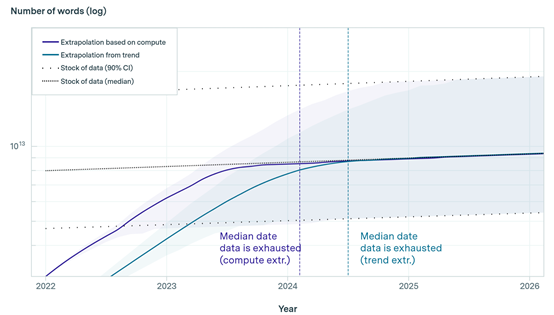
By 2030-2060, all image training data will be depleted; by 2040, due to the lack of training data, there may be signs of a slowdown in the functional iteration of large models.
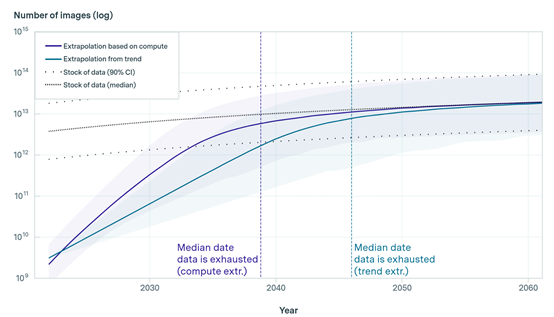
The researchers used two models for calculation: The first model extrapolated the growth trends of actual datasets in the two domains of large language and image models, and then used historical statistical data to predict when they would reach their peak consumption and average consumption.
The second model: Predicted how much new data would be produced globally each year in the future. This model is based on three variables: the global population, internet penetration rate, and the average amount of data produced per internet user per year.
At the same time, the researchers used United Nations data to fit the population growth curve, used an S-curve function to fit the internet usage rate, and made a simple assumption that the amount of data produced per person per year remains constant, and the product of these three can estimate the global annual new data volume.
This model has accurately predicted the data produced by Reddit (a well-known forum) each month, so its accuracy is very high.
Finally, the researchers combined the two models to draw the above conclusions.
The researchers stated that although this data is simulated and estimated, there is a certain degree of uncertainty. However, it has sounded the alarm for the large model community, as training data may soon become a significant bottleneck restricting the expansion and application of AI models.
AI manufacturers need to lay out effective methods for data regeneration and synthesis in advance to avoid a cliff-like shortage of data during the development of large models.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







