- Original Source: Guangzhou Intelligent

Image Source: Generated by Wujie AI
Before deciding to build a vector database, Tencent Cloud also struggled.
"Should we choose the RAG (Retrieval-Augmented Generation) technology route, or build a vector database?" "Will the vector database be replaced by large models?" "Does the vector database really have a future?"
In April, even OpenAI did not make a choice and explored both the RAG and vector database directions.
After more than a month of in-depth industry research, Tencent Cloud found that enterprises face many difficulties in building vector databases from vectorization to deployment.
The person in charge of the large model company Baichuan Intelligence stated that before the vector database, we used some open-source tools. For example, the vector index, as a kernel, can be used, but once the data volume reaches a certain scale, it will encounter bottlenecks related to distributed data and distributed systems.
"Do it! There is demand in the market, and there are demands within the group. Why not do it?" Tencent Cloud's product manager for vector databases, Zou Peng, gave a positive suggestion.
The project was initiated in May, officially launched in the cloud in August, and the functionality was upgraded in November. Tencent Cloud's vector database is now on the fast track.
There is no good or bad technology, only different paths to choose from. Whether it can be truly used still awaits market validation. But now, what is more important is whether there is the courage to make a firm decision at the crossroads.
In the era of large models, cloud service providers are not only providers of MaaS services, but also builders of infrastructure.
To truly enable the use of large models, algorithms and computing power alone are far from enough. There must be efficient and low-cost methods for data usage.
"In the AGI era, an intelligent data scheduling paradigm is also needed, and the vector database is the core of the data," said Luo Yundao, deputy general manager of Tencent Cloud Database.
However, becoming a solid foundation is not easy. Domestic large model development has been ongoing for a year, still mainly focusing on internal development.
The reason why large models have not been fully implemented so far is that although the capabilities of large models have made significant progress, the technology related to data is still lagging behind.
And this lag and gap present a huge opportunity for domestic manufacturers. Whether it is the industrial application of large models or the future construction and implementation of agents, it is driving further upgrades in data technology and productization.
Vector database, the "best partner" of large models
"Memory, illusion, freshness, and data security" are the four main problems that large models still face when actually being implemented.
To solve these four major problems, data optimization and model fine-tuning need to be carried out together. At this point, how to store massive data and how to retrieve it becomes a major challenge.
Luo Yundao believes that "computing and storage must be separated. Large models are computing engines that change the way calculations are performed, and storage needs to be handled by other products. We believe that is the vector database."

This is like a large model being a calculator, and the vector database being the ledger. An accountant first uses the calculator to do the math, and then records it in the ledger.
Vector database + large model, the two are the "best partners."
The vector database itself is the "external brain" of the large model. Although the large model has limitations on contextual tokens and is good at reasoning and content generation, it lacks long-term memory. With the addition of vector data, the large model gains memory, can remember the historical content of user conversations, and can analyze and reason through multiple rounds of dialogue.
There is almost a consensus on the "illusion" of large models. Although large models have accumulated a large amount of knowledge through pre-training, it is still far from enough, and there are serious deficiencies in addressing problems in some specific fields. With vector data, the large model can instantly be infused with various professional knowledge and define the scope of problem answers.
The update speed of large models is also quite lagging. Even GPT-4 Turbo has only been updated to April 2023. With the vector database, the large model is connected to the network and can be updated dynamically at any time.
Data security is the most important concern for enterprises. For enterprises, it is impossible to trust large models with core business data, contract documents, and other confidential information. However, through the vector database approach, enterprises can complete local deployment, and the large model only performs analysis and processing functions without uploading or backing up data.
There are many methods to solve the problems of large models, in addition to using vector databases, there are also methods such as fine-tuning large models and using RAG technology.
The method of fine-tuning large models is like providing a child with education from elementary school to university or even graduate school; the vector database is like an open-book exam, where the large model does not need to learn and understand, it just needs to be able to produce answers; RAG is a more practical scenario that requires the combination of a vector database to be effective.
The difference is clear. Compared to fine-tuning large models and RAG, the vector database is obviously faster and more cost-effective.
Furthermore, based on the underlying capabilities of large models, creating AI native applications and building AI agents also cannot do without the vector database.
As SalesEasy puts it, "With the vector database, it is equivalent to first optimizing the enterprise's database and supporting documents in the vector database for priority preprocessing, unlocking the combination with the large model to answer user questions. Based on this foundation, enterprise applications can be developed, which is equivalent to the vector database being the foundation of enterprise-level application data."
How will the vector database be productized?
The vector database is not a new thing, but the question is, how to truly enable large models to use massive unstructured data?
The vector database has two meanings, first "vector," and second "database."
Luo Yundao believes that "vector" is the "intermediate data format" of the AGI era. "Through vectors, differences between different data formats can be smoothed out. It can convert images and videos into vectors, and also utilize historical accumulated data. In the AGI era, how to quickly recognize information and data also depends on vectors."
If vectors are the intermediate process, then the database is the destination. It can only be used when there is a place to store and retrieve data.
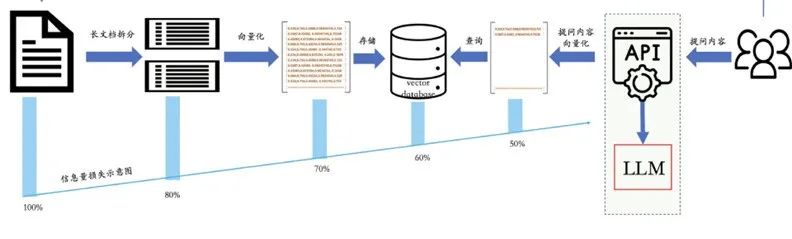
The operation process of "large model + vector database" is as follows: first, long documents are split, and each segment is vectorized and stored as reserve knowledge in the vector database; when a user asks a question, the question content is vectorized again, and similarity retrieval is performed in the vector database. After finding the answer, it is output by the large model. The biggest challenge in this process is how to reduce information loss and improve recall rate.
Rome was not built in a day, and neither was the vector database. Currently, Tencent Cloud's vector database has gone through several stages, including establishing the foundation, promoting internal search, opening up business applications in the cloud, and iterative upgrades.
According to Zou Peng, the core foundation of Tencent Cloud's vector database was already established in 2019 and has been widely used in search, recommendation, and advertising-related businesses, involving multiple applications such as QQ Browser, Tencent Video, Tencent News, and Tencent Maps.
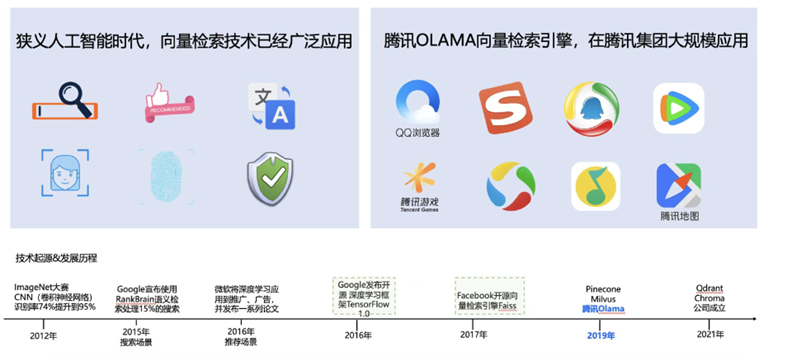
In other words, until May 2023, Tencent Cloud had been running the vector database on various internal BGs for four years, which is one of the reasons why it only took three months to go online and provide external services after the formal project initiation.
It is based on the accumulated experience in vectorization and databases that Tencent Cloud was able to directly launch an enterprise-level vector database.

In terms of enterprise capabilities, since its official release in July, Tencent Cloud's vector database has undergone multiple iterative upgrades, supporting a maximum vector scale of hundreds of billions and a peak capacity of 5 million QPS, with a availability of 99.99%. The same memory can store 5-10 times more data.
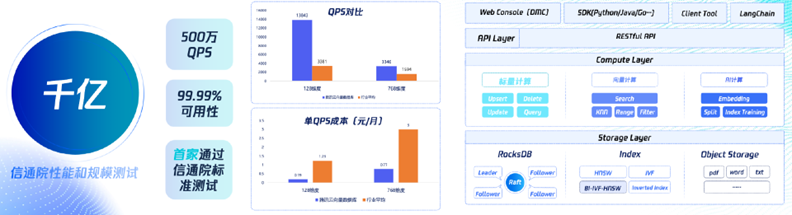
High performance and low cost have made Tencent Cloud's vector database competitive in the industry. In terms of performance, whether it is 128 dimensions or 768 dimensions, the QPS peak capacity of Tencent Cloud's vector database is far higher than the industry average, with a more than fourfold advantage in 128 dimensions and more than a twofold advantage in 768 dimensions. However, in terms of the specific cost per QPS, Tencent Cloud's vector database has made the price affordable, with the cost per QPS in 128 dimensions only one-seventh of the industry average, and in 768 dimensions only one-fourth of the industry average.
At the same time, as an AI-native database, it has undergone intelligent upgrades from the access layer, computing layer, to the storage layer, with the core being the ability to enable natural language interaction with data.
To address the pain points of information loss and recall, Tencent Cloud has launched the first end-to-end vector database solution in China, which improves end-to-end recall rates by 30% and shortens the time for data to be accessed by AI.
While vectorization and encapsulation as a database are important, continuing to develop it into a productized vector database presents a challenge for many manufacturers. Compared to emerging database manufacturers, large companies are obviously more experienced in productization.
Tencent has always adhered to the product concept of "ready to use," and a one-stop productization naturally becomes the solution for building a vector database.
In the research, the team found that enterprises are very urgent but have no idea what kind of data can be vectorized, how to vectorize and store it, how to use a vector database, and how to integrate it with large models.
"The biggest pain point is how to bridge the industry know-how of enterprises and the entire technical stack of AI," said Luo Yundao.
The functionality of the vector database is not achieved overnight. The client's data processing flow is very complex, involving solving various issues such as segmentation, vectorization, and secondary vectorization.
Based on this, Tencent Cloud's end-to-end vector database solution includes services such as intelligent text segmentation, selection of vectorization models, helping clients build indexes, intelligent sorting, and end-to-end data access. Using Tencent Cloud's AI intelligent suite, an enterprise-level local knowledge base can be quickly built with just 100 lines of code.
Baichuan Intelligence stated, "The vector database is a one-stop end-to-end complete technical stack. The first part is to help with data segmentation. Our daily data volume is about 200 million. Before Tencent Cloud's vector database, processing was relatively slow because it was not a concurrent task, and we could only do it in a single-threaded manner. The second part, such as data import and batch updates, has also become much faster."
"By intervening throughout the process, not only have we solved the problems that enterprises have, but we have also ensured the effectiveness of using the vector database," summarized Zou Peng, highlighting the one-stop advantages.
Practicality of technology is greater than path selection
Although the development of the vector database is still in its early stages, there are still many issues in the implementation process, and it is far from being widely replicated on a large scale. However, Tencent Cloud has made deeper considerations and placed it in a strategic development position.
"From programming languages to natural language, large models have reshaped the way computing resources are scheduled. In the AGI era, an intelligent data scheduling paradigm is also needed. In the AGI era, the data platform, the vector database is the core of the data. Tencent Cloud's vector database hopes to become this data core and help various industries move towards AGI through enterprise-level and intelligent capabilities," said Luo Yundao.
Correspondingly, the OpenAI Developer Conference introduced the new concept of Assistants, canceled some purely vector database applications, and once again strengthened the RAG route.
Whether it is the vector database, fine-tuning, or RAG, for any technology path to become mainstream, it is often not about how strong the pure technical capabilities are, but about how many people are ultimately using it. After all, the scenario is the sharpest whetstone for technology.
However, in the specific usage process, as a relatively new data usage paradigm, the vector database also has many issues: high cost, lack of unified standards, and more.
Since there is a strategic determination to lay out in the vector database, Tencent has also put in a lot of effort to solve practical problems.
In terms of pricing, compared to foreign companies like Microsoft, which charges per vectorization step, Tencent Cloud has single-handedly reduced the overall enterprise usage cost. In terms of time efficiency, Tencent Cloud has achieved the integration of enterprise data access, with efficiency improved by 10 times.
In addition, Tencent Cloud is also using the influence of large companies to enable more enterprises to use the vector database. It is reported that Tencent Cloud's vector database has already served more than 40 internal businesses at Tencent, with a daily request volume of 160 billion, and has served over 1,000 external customers including Bosch, SalesEasy, Sohu, TAL Education, and Lianjia.
For example, in the SaaS field, it helps enterprise customers quickly build private domain knowledge bases and intelligent customer service systems; in the e-commerce industry, it uses the vector database to improve the recommendation, search, and advertising business; in the transportation industry, it uses the vector database to accelerate the training of autonomous driving models. In addition, it has wide applications in the education industry and cultural and creative industries.
SalesEasy stated, "In the future, based on cooperation with Tencent Cloud's vector database, we will reshape some existing core scenarios, such as internal knowledge retrieval in the sales management system, as well as recommendations for potential customers and building schedules, orders, or querying CRM systems, and building customer robots and intelligent ticketing systems. In the future, we also want to use the PaaS platform to help enterprises generate application platforms in an intelligent way."
Large models + vector databases will pave a data highway for the application landing in the AGI era.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。






