Original Source: Quantum Bit

Image Source: Generated by Wujie AI
The highly anticipated contestant in the battle of large models has finally made its official debut!
It is the first open-source large model from Dr. Kai-Fu Lee's AI 2.0 company 01W - the Yi series large models:
Yi-34B and Yi-6B.

Although the Yi series large models debuted relatively late, their performance is undoubtedly ahead of the curve.
They immediately achieved multiple global firsts:
- Ranked first in the Hugging Face English test list, surpassing Llama-2 70B and Falcon-180B with the size of 34B;
- The only domestically developed large model to top HuggingFace;
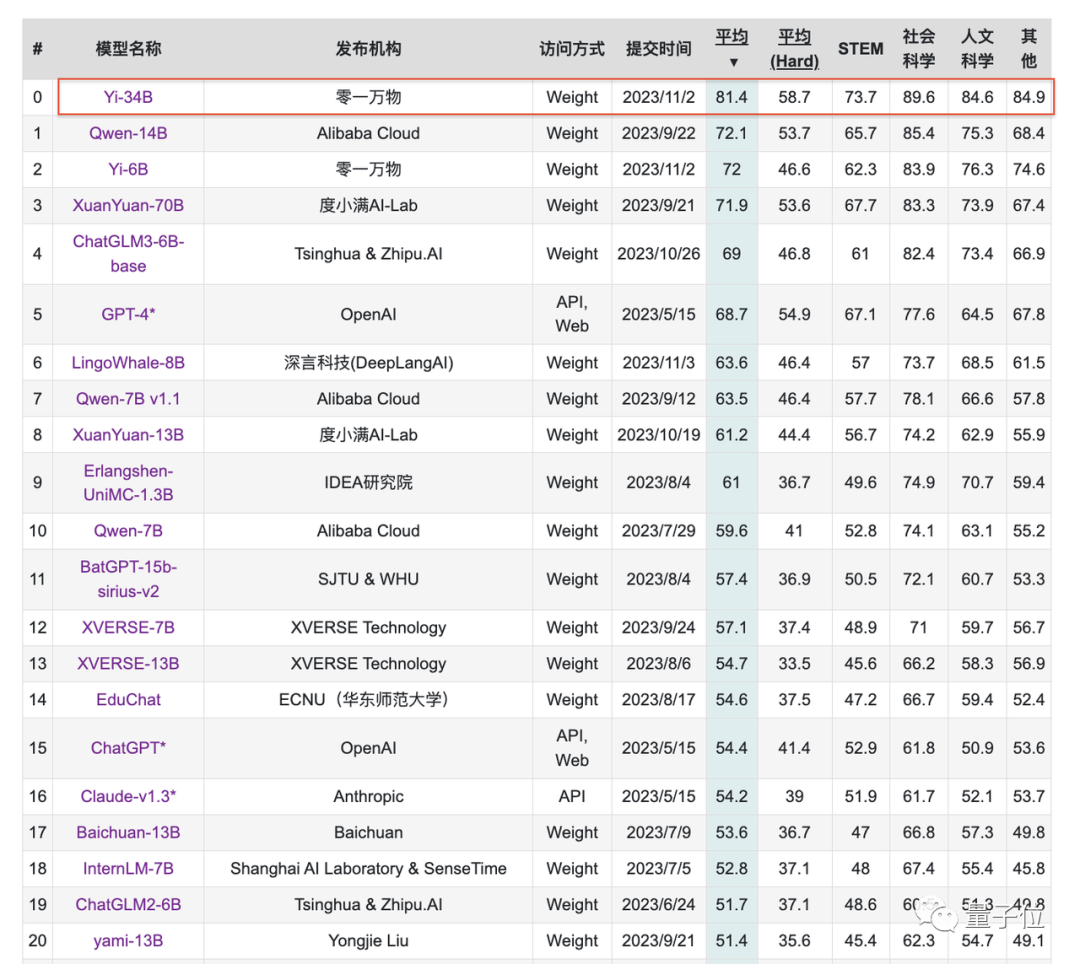
- Ranked first in the C-Eval Chinese language ability list, surpassing all global open-source models;
- Won in all eight comprehensive ability evaluations such as MMLU and BBH;
- Secured the title of the world's longest context window, reaching 200K, capable of directly processing super long texts of 400,000 Chinese characters.
- ......
It is worth noting that the development of 01W and its large models took more than half a year.
This inevitably raises many questions:
For example, why did they hold back their big move for so long and choose to make their move near the end of the year?
And how did they manage to achieve so many firsts as soon as they debuted?
With these questions in mind, we had an exclusive interview with 01W to uncover the answers.
Defeating Hundred-Billion-Parameter Large Models
Specifically, the latest open-source Yi series large models from 01W have two main highlights:
- "Small but powerful" to defeat hundred-billion-parameter models
- Support for the world's longest context window of 400,000 characters
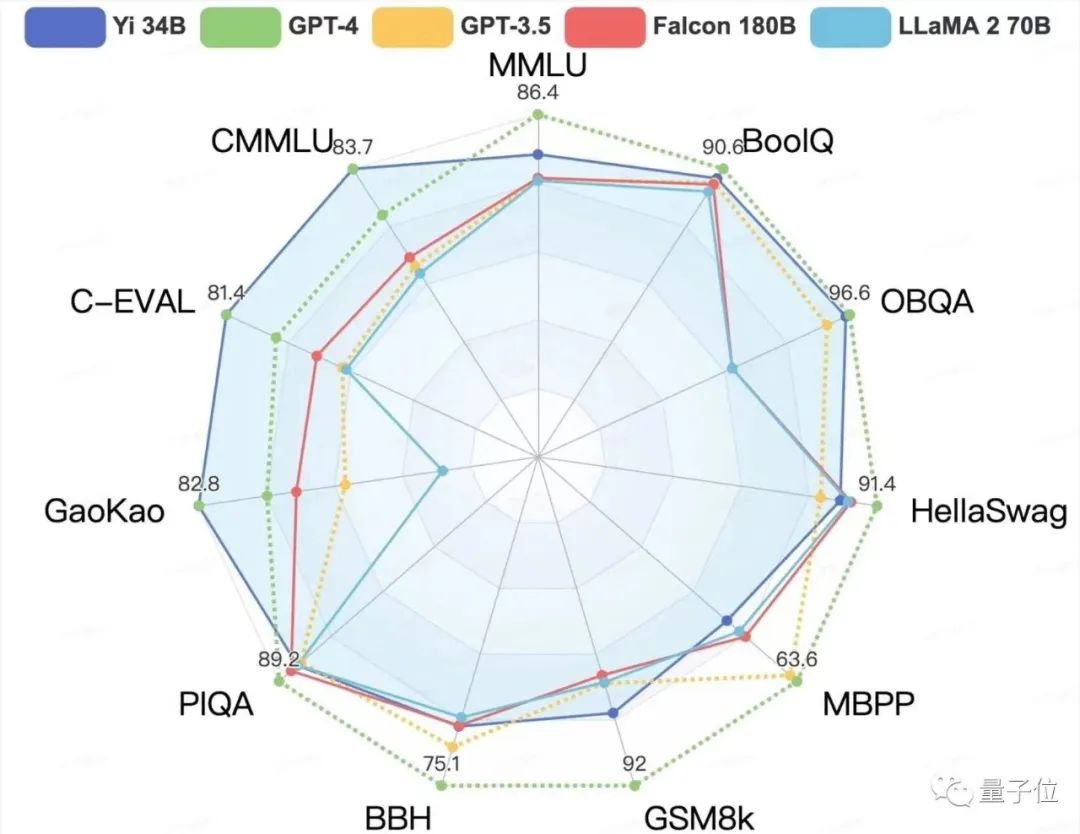
In the Hugging Face English test public single Pretrained model ranking, Yi-34B ranks first in the world with a score of 70.72, surpassing LLaMA-70B and Falcon-180B.
It's important to note that Yi-34B's parameters are only 1/2 and 1/5 of the latter two. Not only did it top the list with "small but powerful" capabilities, but it also achieved a cross-level reversal, defeating billion-scale models with hundred-billion-scale ones.
In both MMLU (Massive Multitask Language Understanding) and TruthfulQA benchmarks, Yi-34B significantly outperformed other large models.

Focusing on Chinese language capabilities, Yi-34B surpassed all open-source models in the C-Eval Chinese language ability ranking.
Similarly, the open-source Yi-6B also outperformed all open-source models of the same scale.
In the CMMLU, E-Eval, and Gaokao three main Chinese benchmarks, it clearly outperformed GPT-4, demonstrating its strong advantage in Chinese, providing a more thorough understanding for us.

.
In the BooIQ and OBQA two question-and-answer benchmarks, it performed equally to GPT-4.

Additionally, in the most critical evaluation indicators of large models, MMLU (Massive Multitask Language Understanding) and BBH, which reflect the comprehensive capabilities of the model, Yi-34B comprehensively outperformed in multiple indicators such as general ability, knowledge reasoning, and reading comprehension, consistent with the Hugging Face evaluation.

However, in the release, 01W also stated that the Yi series models did not perform as well as GPT models in the mathematical and code evaluations of GSM8k and MBPP.
This is because the team hopes to retain the model's general ability as much as possible during the pre-training phase, so they did not include too much mathematical and code data in the training data.
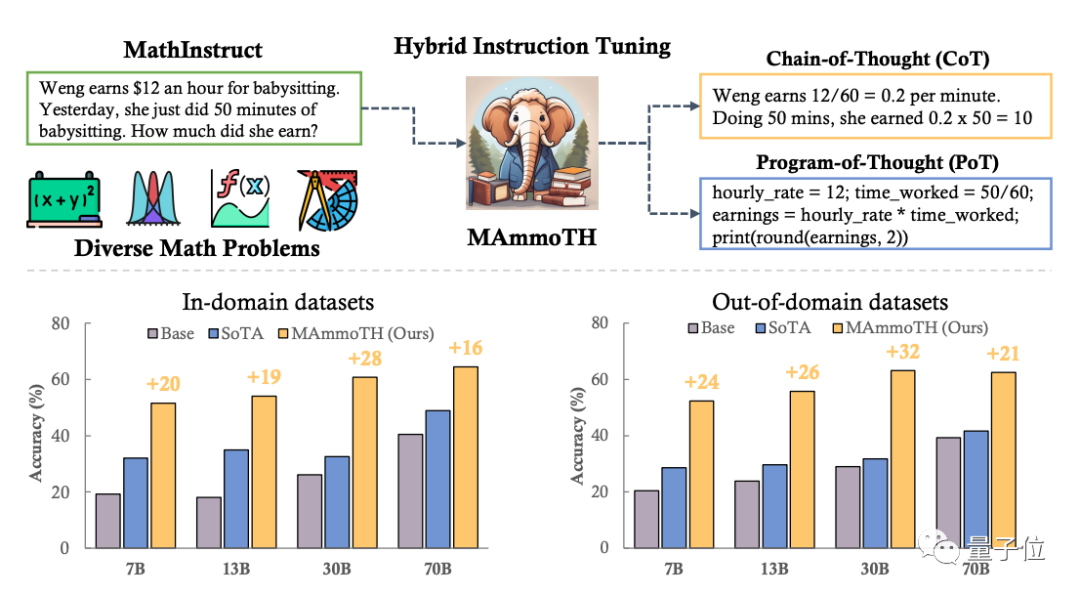
Currently, the team is conducting research on mathematics and has proposed a large model, MammoTH, which can solve general mathematical problems, outperforming SOTA models on various scales and internal and external test sets. MammoTH-34B achieved an accuracy of 44% on MATH, surpassing GPT-4's CoT results.
Subsequent Yi series models will also introduce continued training models specialized in code and mathematics.
In addition to impressive rankings, Yi-34B also refreshed the length of the large model's context window to 200K, capable of processing approximately 400,000 Chinese characters of super long text input.
This is equivalent to being able to process two copies of "The Three-Body Problem" novel at once, understand over 1000 pages of a PDF document, and even replace many scenarios that rely on building external knowledge bases with vector databases.

The ability to handle super long context windows is an important dimension to demonstrate the strength of large models. Having a longer context window allows for processing richer knowledge base information, generating more coherent and accurate text, and supporting large models to better handle tasks such as document summarization and question answering.
Currently, in many vertical industry applications of large models (such as finance, law, and finance), document processing capability is essential.
For example, GPT-4 can support 32K, approximately 25,000 Chinese characters, and Claude 2 can support 100K, approximately 200,000 characters.
01W not only refreshed the industry record, but also is the first company to open-source a large model with an ultra-long context window.
So, how was the Yi series developed?
Superior Infra+Self-developed Training Platform
01W stated that the secret to developing the Yi series comes from two aspects:
- Self-developed scalable training experimental platform
- Superior Infra team
When combined, they make the large model training process more efficient, accurate, and automated. In the current multi-model melee, it saves valuable time, computing, and manpower costs.
These are some of the reasons why the Yi series large models are "slow," but also because of them, "slow is fast."
First, let's look at the model training part.
This is the foundation of the large model's capabilities, and the quality and method of training data directly affect the model's final performance.
Therefore, 01W has built a smart data processing pipeline and a scalable training experimental platform.
The smart data processing pipeline is efficient, automatic, evaluable, and scalable, led by former Google big data and knowledge graph experts.
The "scalable training experimental platform" can guide model design and optimization, improve model training efficiency, and reduce computing resource waste.
Based on this platform, the prediction error of each node in Yi-34B is controlled to be within 0.5%, and data ratio, hyperparameter search, and model structure experiments can all be conducted on it.
As a result, compared to the past "crude alchemy" training, the training of the Yi series large models has advanced to "scientific training": becoming more meticulous and scientific, with more stable experimental results, and the speed of further expanding the model scale in the future can also be faster.

Now, let's look at the Infra part.
AI Infra refers to the basic framework technology of artificial intelligence, which includes various underlying technical facilities for large model training and deployment, including processors, operating systems, storage systems, network infrastructure, cloud computing platforms, etc.—absolute hard technology in the large model field.
If the training phase lays the foundation for model quality, then AI Infra provides guarantees for this phase, making the foundation more solid, and directly affecting the underlying part of the large model.
The 01W team used a more vivid metaphor to explain:
If large model training is like climbing a mountain, Infra's capabilities define the ability boundaries of large model training algorithms and models, which is the "ceiling" of the mountain climbing height.
Especially in the current industry where computing resources are scarce, how to advance large model development faster and more stably is crucial.
This is why 01W attaches so much importance to the Infra part.
Kai-Fu Lee has also stated that people who have worked on large model Infra are even rarer than those who work on algorithms.
And the Infra team of 01W has previously supported the training of multiple hundred-billion-scale large models.
With their support, the training cost of the Yi-34B model decreased by 40%, and the simulated training cost of the hundred-billion-scale model can decrease by as much as 50%. The actual training completion time domain prediction error is less than 1 hour—it is worth noting that the industry generally reserves several days as an error margin.
The team stated that as of now, the fault prediction accuracy of 01W's Infra capability has exceeded 90%, the fault early discovery rate has reached 99.9%, the fault self-healing rate without human intervention has exceeded 95%, and it can effectively ensure the smooth progress of model training.
Kai-Fu Lee revealed that while completing the pre-training of Yi-34B, 01W has officially started the training of a hundred-billion-parameter model.
And it hinted that the speed of the appearance of even larger models may well exceed everyone's expectations:
01W's data processing pipeline, algorithm research, experimental platform, GPU resources, and AI Infra are all ready, our actions will become faster and faster.
01W, the Latecomer
Finally, let's answer the questions we mentioned at the beginning.
01W's choice to enter the game at the end of the year is closely related to its own goals.
As Kai-Fu Lee stated in this release:
01W is determined to advance into the world's top tier, from recruiting the first person, writing the first line of code, and designing the first model, it has always held the original intention and determination to become the "World's No.1."
To achieve the top position, one must have patience, focus on solid training, and be able to make a stunning debut.
Moreover, at the time of 01W's establishment, its starting point was fundamentally different from other large model manufacturers.
The "01" represents the entire digital world, from zero to one, and even the universe, the so-called "Tao gives birth to one...gives birth to all things," implying the ambition of "01 Intelligence, empowering all things."

This is also consistent with Kai-Fu Lee's consistent thinking and judgment about AI 2.0. After ChatGPT sparked the trend of large models, he publicly stated:
The AI 2.0 era, driven by large base models, will revolutionize technology, platforms, and applications at multiple levels. Similar to how Windows drove PC popularity and Android fostered the mobile internet ecosystem, AI 2.0 will create a platform opportunity ten times larger than the mobile internet, rewriting existing software, user interfaces, and applications, giving rise to a new wave of AI-first applications, and fostering AI-led business models.
The concept is AI-first, the driving force is technological vision, backed by China's outstanding engineering heritage, the breakthrough point is the large base model, covering multiple levels from technology, platforms to applications.
For this reason, 01W's entrepreneurial route since its establishment has been to self-develop large models.
Although the release time was relatively late, the speed is definitely not slow.
For example, within the first three months, 01W had already achieved the internal testing of a hundred-billion-parameter model; and after another three months, it unlocked the global first with a 34B parameter scale.
With such speed and high goals, it is certainly also due to the strong team behind 01W.
Dr. Kai-Fu Lee personally leads as CEO of 01W.

In the early stages, 01W had already gathered a team of dozens of core members, focusing on large model technology, artificial intelligence algorithms, natural language processing, system architecture, computing architecture, data security, and product development.
Among the founding team members are former vice presidents of Alibaba, former vice presidents of Baidu, former executives of Google China, former vice presidents of Microsoft/SAP/Cisco, and the backgrounds of the algorithm and product teams are from both domestic and international major companies.
As an example, among the algorithm and model team members, there are algorithm experts whose papers have been cited by GPT-4, outstanding researchers who have won internal research awards at Microsoft, and super engineers who have won special awards from the CEO of Alibaba, with a total of more than 100 academic papers related to large models published at well-known academic conferences such as ICLR, NeurIPS, CVPR, ICCV.
Furthermore, 01W began building an experimental platform at the time of its establishment, constructing a GPU cluster of thousands of cards for training, tuning, and inference. In terms of data, it focuses on increasing the effective parameter quantity and using high-quality data density.
From this, it is clear that 01W's Yi series large models have the confidence to be a latecomer.
It is understood that 01W will continue to iterate and open-source more quantized versions, dialogue models, mathematical models, code models, and multimodal models based on the Yi series large models in the future.
In conclusion, with the entry of this dark horse 01W, the battle of large models has become even more intense and lively.
It is worth looking forward to how many more "global firsts" the Yi series large models will overturn in the future.
One More Thing
Why the name "Yi"?
The name comes from the pinyin of "one," with the "Y" in "Yi" upside down, cleverly resembling the Chinese character "人" (person), combined with the "i" in AI, representing Human + AI.
01W believes that AI empowerment drives human society forward, and AI should create tremendous value for humanity with a spirit that is centered on people.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。






