Original Source: AIGC Open Community

Image Source: Generated by Wujie AI
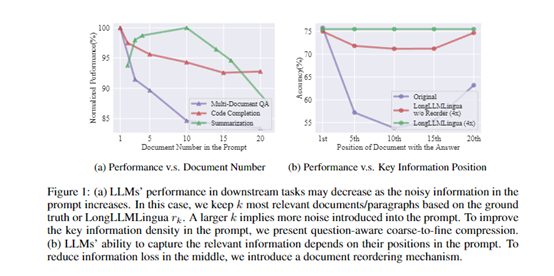
In the context of long texts, large language models such as ChatGPT often face higher computational costs, longer delays, and poorer performance. To address these three major challenges, Microsoft has open-sourced LongLLMLingua.
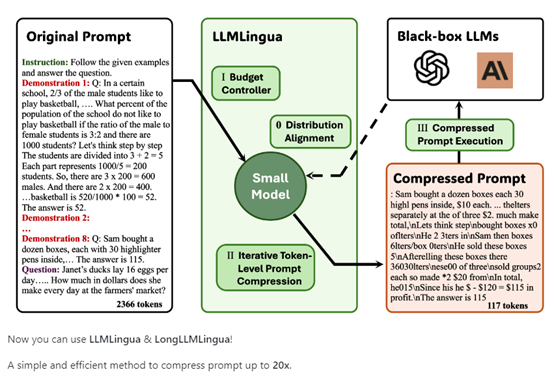
It is reported that the core technological principle of LongLLMLingua is to achieve up to 20 times extreme compression of "text prompts," while accurately assessing the relevance of the content in the prompt to the question, eliminating irrelevant content and retaining key information to achieve cost reduction and efficiency improvement.
Experimental results show that the performance of prompts compressed by LongLLMLingua has improved by 17.1% compared to the original prompts, while the number of tokens input into GPT-3.5-Turbo has been reduced by 4 times. In LongBench and ZeroScrolls tests, it was shown that cost savings of $28.5 and $27.4 per 1,000 samples were achieved.
When compressing prompts of about 10k tokens, the end-to-end latency can be reduced by 1.4-3.8 times within a compression ratio range of 2-10 times, significantly accelerating the inference rate.
Paper Link: https://arxiv.org/abs/2310.06839
Open Source Link: https://github.com/microsoft/LLMLingua
From the introduction of the paper, LongLLMLingua is mainly composed of four modules: problem-aware coarse-grained compression, document reordering, dynamic compression ratio, and compressed subsequence recovery.
Problem-Aware Coarse-Grained Compression Module
The design idea of this module is to use the problem text for conditioning, evaluate the relevance of each paragraph to the question, and retain paragraphs with higher relevance.
Specifically, by calculating the conditional perplexity of the problem text and each paragraph, the logical correlation between the two is judged, with lower conditional perplexity indicating higher relevance.
Based on this, a threshold is set to retain paragraphs with lower perplexity, filtering out paragraphs that are not relevant to the question. This achieves coarse-grained compression that quickly removes a large amount of redundant information based on the question.
Document Reordering Module
Research has shown that in prompts, the content near the beginning and end has the greatest impact on the language model. Therefore, this module reorders paragraphs based on their relevance to ensure that key information appears in positions more sensitive to the model, reducing information loss in the middle.
By using the relevance of each paragraph calculated by the coarse-grained compression module to reorder the paragraphs, the most relevant paragraphs are placed at the beginning. This further enhances the model's perception of key information.
After obtaining the reordered relevant paragraphs, it is necessary to further compress the word count within each paragraph. At this point, the dynamic compression ratio module finely controls the prompt.
Dynamic Compression Ratio Module
Lower compression ratios are used for more relevant paragraphs, allocating more budget to retain words, while higher compression ratios are used for less relevant paragraphs.
By using the paragraph relevance from the coarse-grained compression results, the compression ratio for each paragraph is dynamically determined. The paragraph with the highest relevance has the lowest compression ratio, and so on.
This achieves adaptive, fine-grained compression control, effectively retaining key information. After compression, the reliability of the results needs to be improved, which requires the following compressed subsequence recovery module.
Compressed Subsequence Recovery Module
During the compression process, some key words may be excessively deleted, affecting the integrity of the information, and this module can detect and recover these key words.
The working principle is to use the subsequence relationship between the source text, compressed text, and generated text to restore complete key noun phrases from the generated results, repairing information loss caused by compression and improving the accuracy of the results.
The entire process is somewhat similar to quickly browsing an article, filtering information, and integrating key points, allowing the model to quickly capture the key information in the text and generate high-quality summaries.
Experimental Data of LongLLMLingua
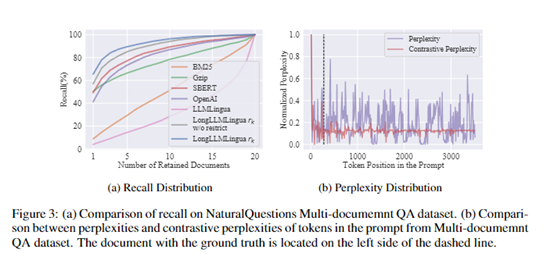
Researchers constructed a multi-document question-answering dataset based on Natural Questions, where each example contains a question and 20 relevant documents, and the answer needs to be found from these 20 documents.
This dataset simulates real search engine and question-answering scenarios and can evaluate the model's performance in answering questions in long documents.
In addition, researchers also used more general long text understanding benchmark datasets, including LongBench and ZeroSCROLLS, to evaluate the method's effectiveness in a wider range of scenarios.
Among them, LongBench covers tasks such as single-document question-answering, multi-document question-answering, text summarization, and few-shot learning, including English datasets. ZeroSCROLLS includes typical language understanding tasks such as text summarization, question-answering comprehension, and sentiment analysis.
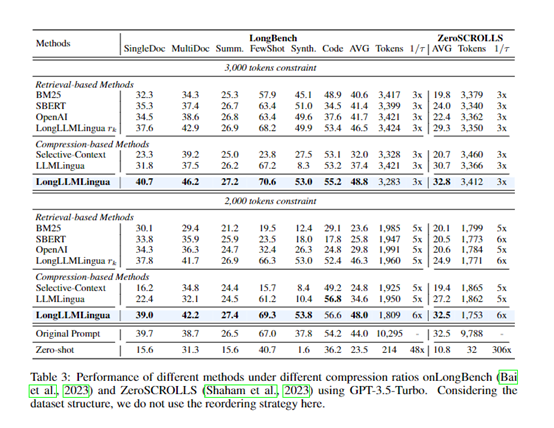
On these datasets, researchers compared the performance of LongLLMLingua-compressed prompts with original prompts on large language models. They also compared LongLLMLingua with other prompt compression methods, such as perplexity-based LLMLingua and retrieval-based methods, to evaluate the effectiveness of LongLLMLingua.
Experimental results show that LongLLMLingua-compressed prompts generally outperform original prompts in question-answering accuracy, text generation quality, and other metrics.
For example, on NaturalQuestions, a 4x compressed prompt improved question-answering accuracy by 17.1%. When compressing prompts of about 10k tokens within a compression ratio range of 2-10 times, the end-to-end latency can be reduced by 1.4-3.8 times. This fully demonstrates that LongLLMLingua can improve key information extraction while compressing prompts.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







