Source: Quantum Bit

Image source: Generated by Wujie AI
Google's human-machine verification can no longer stop AI!
The latest multimodal large model can easily find all traffic lights in the picture and accurately outline their specific locations.

Its performance surpasses that of GPT-4V.

This is the multimodal large model "Ferret" brought by the research team from Apple and Columbia University.

It has stronger visual-textual correlation capabilities, improving the accuracy of large models in the "see, say, and answer" task.
For example, in the very small component in the image below (region 1), it can also distinguish that it is a shock absorber.
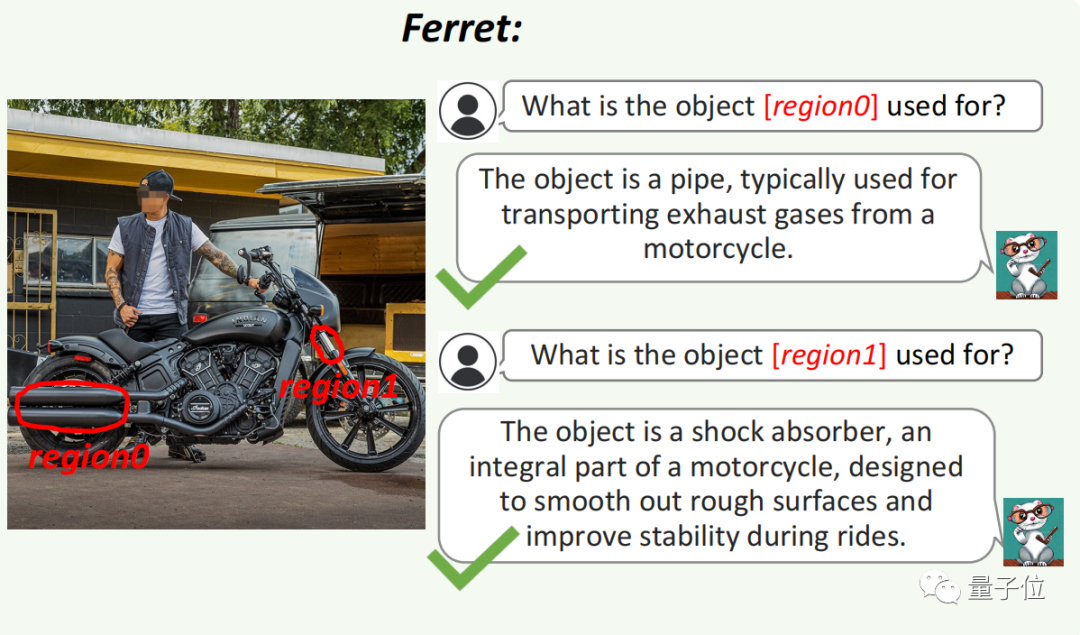
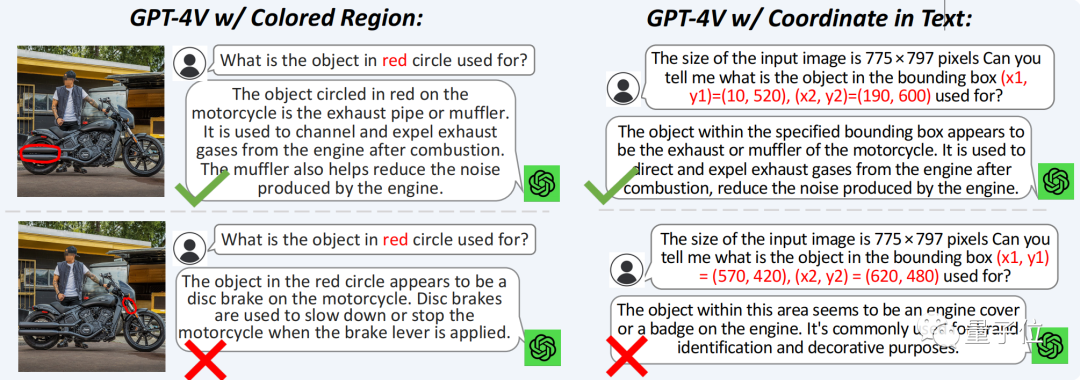
GPT-4V failed to answer correctly and performed poorly on small parts.
So, how does Ferret achieve this?
"A little touch" and the image large model understands
The core problem solved by Ferret is to make the spatial understanding capabilities of reference and grounding more closely integrated.
Reference refers to accurately understanding the semantics of a given area by the model, that is, it knows what a position is.
Grounding, on the other hand, gives semantics and allows the model to find the corresponding target in the image.
For humans, these two abilities are naturally combined, but many existing multimodal large models only use reference and grounding separately.
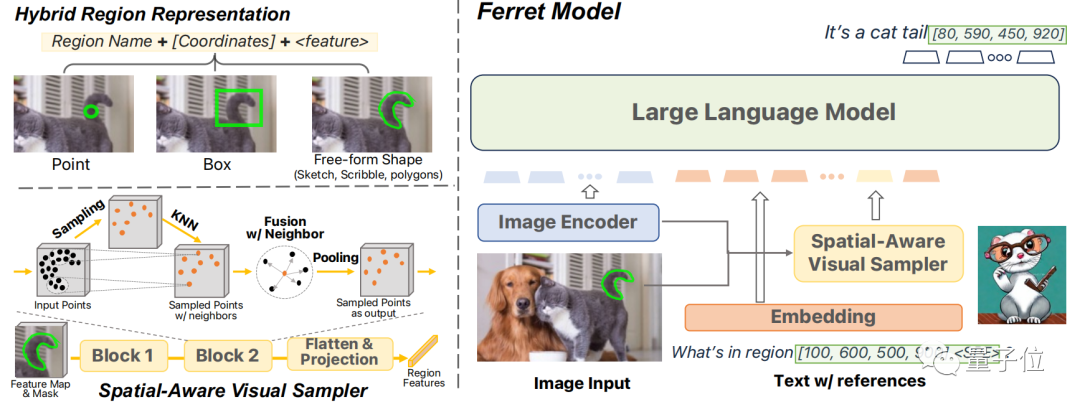
Therefore, Ferret proposes a new type of hybrid region representation method, which can combine discrete coordinates and continuous features to represent regions in the image.
As a result, the model can distinguish objects with almost identical bounding boxes.
For example, in the situation of the two objects in the image below, if only discrete bounding boxes are used, the model would feel very "confused". Combining with a representation of continuous free shapes can solve this problem well.

To extract continuous features of diverse regions, the paper proposes a spatial-aware visual sampler that can handle sparsity differences between different shapes.
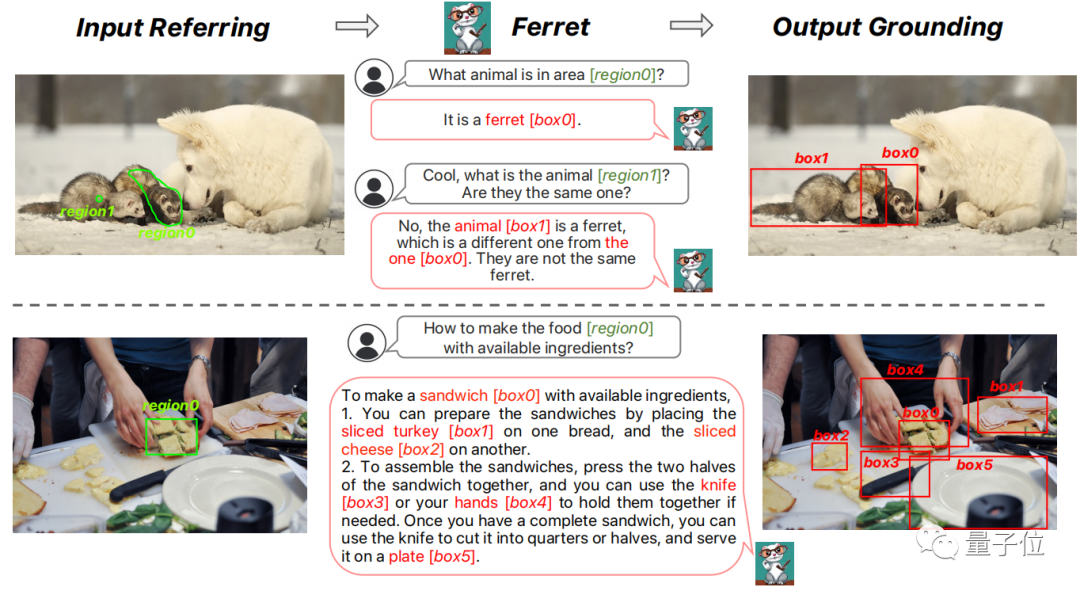
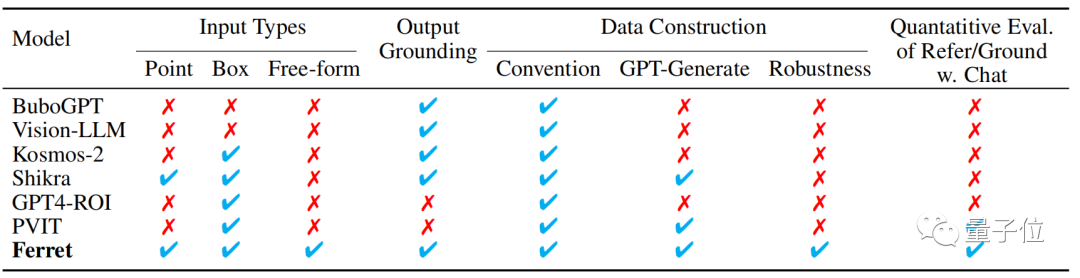
Therefore, Ferret can accept various region inputs, such as points, bounding boxes, and free shapes, and understand their semantics.
In the output, it can automatically generate the coordinates of each located object based on the text.
To achieve this goal, the architecture of the Ferret model includes an image encoder, spatial-aware visual sampler, and language model (LLM) as its components.
Ferret combines discrete coordinates and continuous features to form a hybrid region representation.
This representation method aims to address the challenge of representing regions of various shapes and formats, including points, bounding boxes, and free shapes.
Each coordinate in the discrete coordinates is quantized into a discrete coordinate of a target box, which ensures the model's robustness to different image sizes.
The continuous features are extracted by the spatial-aware visual sampler, which uses binary masks and feature maps to randomly sample points within the ROI and obtain features through bilinear interpolation.
These features, after being processed by a spatial-aware module inspired by a 3D point cloud model, are condensed into a single vector and mapped to a large language model (LLM) for further processing.
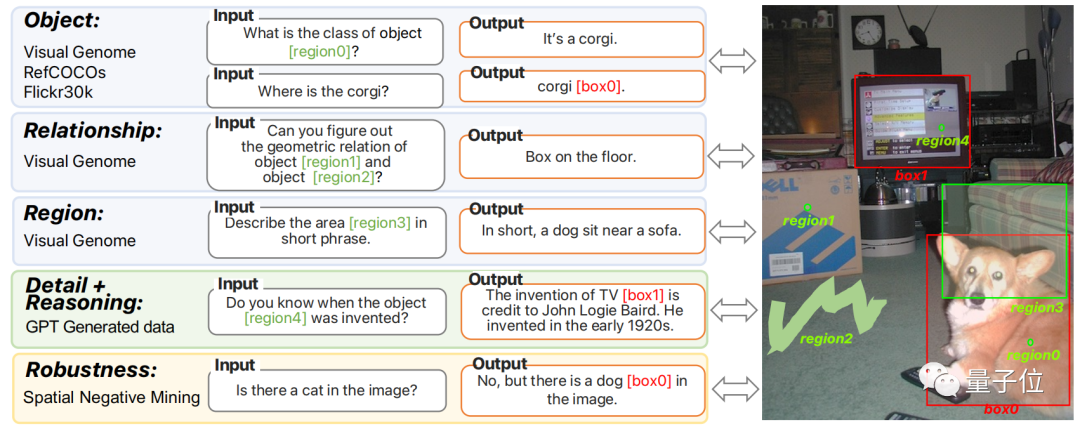
To enhance Ferret's capabilities, the paper also created a dataset called GRIT.
This dataset contains 1.1 million samples, covering four main categories: individual objects, relationships between objects, descriptions of specific regions, and region-based complex reasoning.
The GRIT dataset includes data transformed from public datasets, instruction-adjusted data generated by ChatGPT and GPT-4, and an additional 95,000 difficult negative samples to improve the model's robustness.
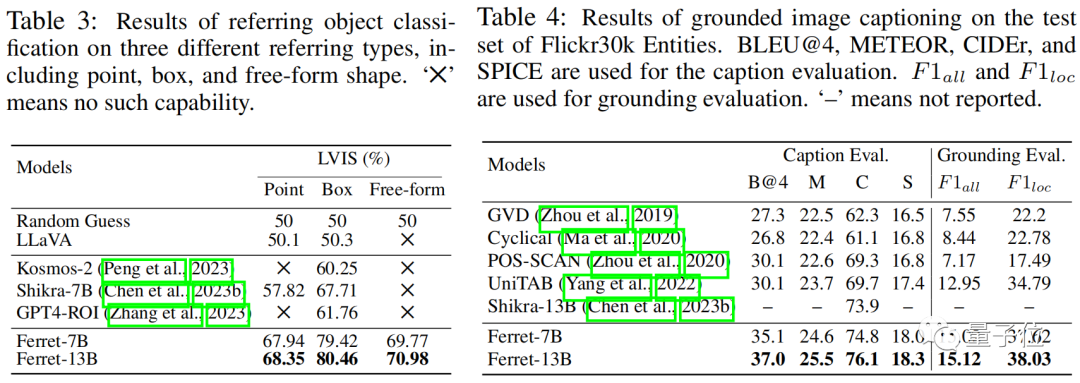
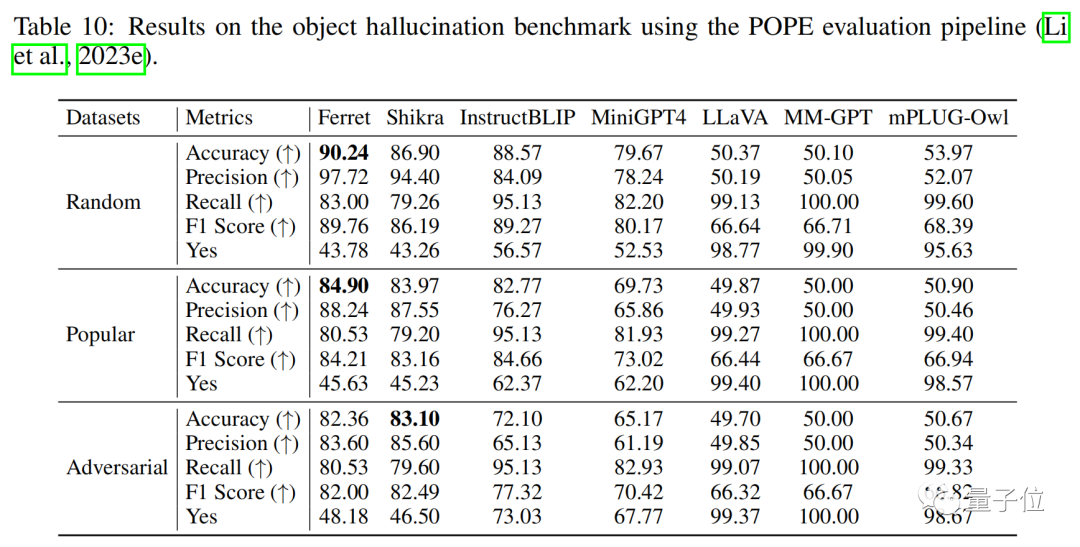
Experimental results show that the model not only demonstrates superior performance in classic reference and grounding tasks, but also far surpasses other existing MLLM models in region-based and location-dependent multimodal dialogues.
In addition, the study also proposed Ferret-Bench, which can evaluate the reference/grounding, semantic, knowledge, and reasoning capabilities of local regions in images.
The Ferret model was evaluated on LLaVA-Bench and Ferret-Bench, performing well in all tasks, especially in three new tasks that require reference and visual grounding, where Ferret excelled.
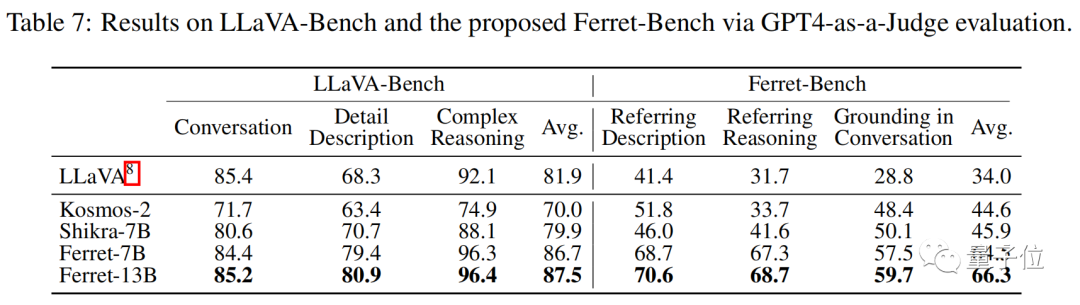
Moreover, there was a significant improvement in describing image details, with a noticeable decrease in illusions.
All-Chinese team
The Ferret large model is jointly brought by the Apple AI/ML and Columbia University research team, with an all-Chinese lineup.
Haohuan and Haotian Zhang are co-first authors.
Haohuan is currently a computer science Ph.D. graduate from Columbia University and will join the Apple AI/ML team after graduation. He graduated from Xidian University with a bachelor's degree in 2018.
His main research interests include visual language understanding, text-image generation, and visual language.
Haotian Zhang is currently a visual intelligence researcher at the Apple AI/ML team.
Before joining Apple, Haotian Zhang obtained his Ph.D. from the University of Washington and graduated from Shanghai Jiao Tong University with a bachelor's degree.
He is one of the main authors of GLIP/GLIPv2, and GLIP was nominated for the Best Paper Award at CVPR 2022.

In addition, team members include several outstanding multimodal large model researchers from Google and Microsoft, such as Zhe Gan, Zirui Wang, Liangliang Cao, and Yifei Yang.
Paper link: https://arxiv.org/abs/2310.07704
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







