Source: New Wisdom

Image Source: Generated by Wujie AI
The "GPU poor" are about to bid farewell to their plight!
Just now, Nvidia released an open-source software TensorRT-LLM, which can accelerate the inference of large language models on H100.

So, how much can it specifically improve?
After adding TensorRT-LLM and a series of optimization features (including In-Flight batch processing), the total throughput of the model increased by 8 times.
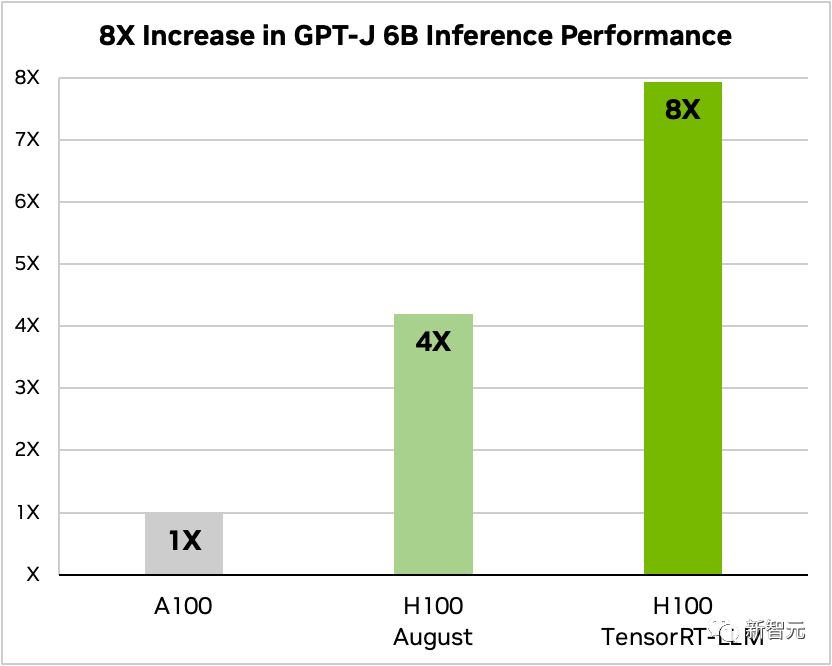
Comparison of GPT-J-6B A100 and H100 with and without TensorRT-LLM
In addition, taking Llama 2 as an example, compared to using A100 alone, TensorRT-LLM can increase the inference performance by 4.6 times.
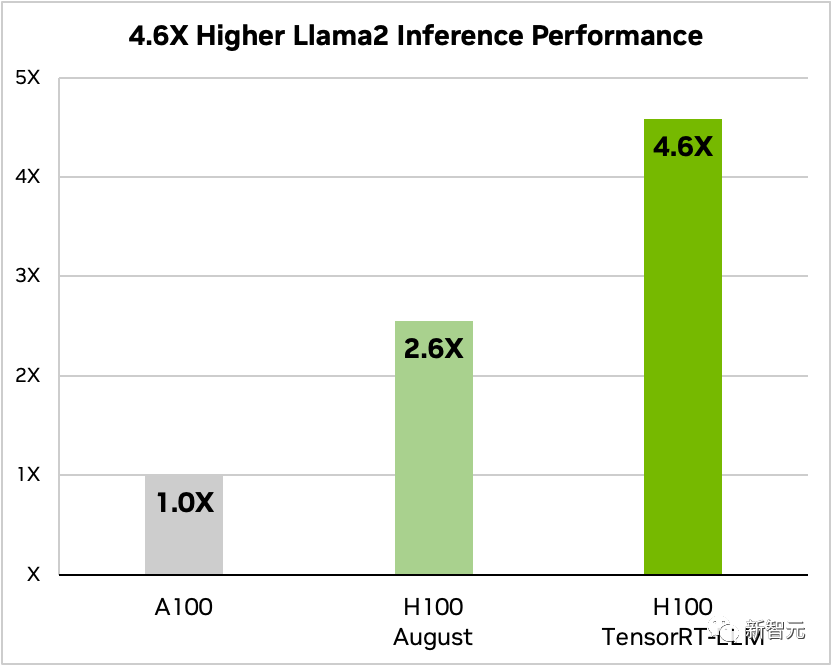
Comparison of Llama 2 70B, A100, and H100 with and without TensorRT-LLM
Netizens expressed that the super H100, combined with TensorRT-LLM, will undoubtedly completely change the current state of large language model inference!
TensorRT-LLM: Accelerator for Large Model Inference
Currently, due to the huge parameter scale of large models, the difficulty and cost of "deployment and inference" have always been high.
Nvidia's developed TensorRT-LLM aims to significantly increase the LLM throughput and reduce costs through GPUs.

Specifically, TensorRT-LLM encapsulates TensorRT's deep learning compiler, FasterTransformer's optimized kernel, preprocessing and post-processing, and multi-GPU/multi-node communication in a simple open-source Python API.
Nvidia has further enhanced FasterTransformer to make it a productized solution.
It can be seen that TensorRT-LLM provides an easy-to-use, open-source, and modular Python application programming interface.
Developers do not need in-depth knowledge of C++ or CUDA, and can deploy, run, debug various large language models, and obtain top performance, as well as fast customization features.

According to Nvidia's official blog, TensorRT-LLM optimizes LLM inference performance on Nvidia GPUs in four ways.
First, for the current 10+ large models, TensorRT-LLM is introduced to allow developers to run immediately.
Second, as an open-source software library, TensorRT-LLM allows LLM to perform inference on multiple GPUs and multiple GPU servers simultaneously.
These servers are connected through Nvidia's NVLink and InfiniBand.
Third, there is "In-flight batch processing," which is a new scheduling technique that allows different model tasks to enter and exit the GPU independently of other tasks.
Finally, TensorRT-LLM is optimized to use the H100 Transformer Engine to reduce memory usage and latency during model inference.
Next, let's take a closer look at how TensorRT-LLM improves model performance.
Support for Rich LLM Ecosystem
TensorRT-LLM provides very good support for the open-source model ecosystem.
The largest and most advanced language models, such as Meta's Llama 2-70B, require multiple GPUs to work together to provide real-time responses.
Previously, to achieve the best performance of LLM inference, developers had to rewrite AI models, manually split them into multiple segments, and coordinate their execution across GPUs.

TensorRT-LLM uses tensor parallelism to allocate weight matrices to various devices, simplifying this process and enabling large-scale efficient inference.
Each model can run in parallel on multiple GPUs and multiple servers connected via NVLink, without developer intervention or model changes.
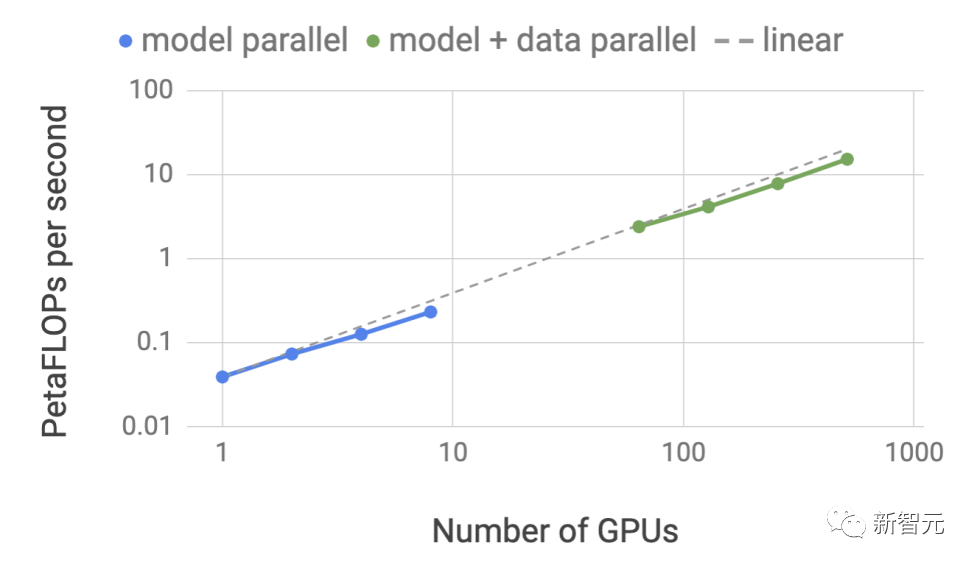
With the introduction of new models and model architectures, developers can use the latest open-source NVIDIA AI kernels in TensorRT-LLM to optimize models.
Supported kernel fusion includes cutting-edge FlashAttention implementation and masked multi-head attention for context and generation stages in GPT model execution.
In addition, TensorRT-LLM also includes fully optimized, ready-to-run versions of many popular large language models.
These features can help developers build customized large language models faster and more accurately to meet the diverse needs of various industries.
In-flight Batch Processing
Today, the use of large language models is extremely widespread.
A model can be used for multiple tasks that appear completely different—from simple Q&A responses in chatbots to document summaries or generating long code blocks. The workload is highly dynamic, and the output size needs to meet the needs of tasks at different scales.
The diversity of tasks may make it difficult to effectively batch requests and execute them efficiently in parallel, potentially resulting in some requests being completed earlier than others.

To manage these dynamic workloads, TensorRT-LLM includes an optimization scheduling technique called "In-flight batch processing."
Its core principle is that the entire text generation process of a large language model can be decomposed into multiple iterations of execution on the model.
Through in-flight batch processing, TensorRT-LLM runtime immediately releases completed sequences from the batch processing, rather than waiting for the entire batch to complete before continuing to process the next set of requests.
When executing new requests, other requests from the previous batch that have not yet been completed are still being processed.
In-flight batch processing and additional kernel-level optimizations can increase GPU utilization, potentially doubling the throughput of LLM requests on H100.
Using FP 8 H100 Transformer Engine
TensorRT-LLM also provides a feature called the H100 Transformer Engine, which effectively reduces memory consumption and latency during large model inference.
Because LLMs contain billions of model weights and activation functions, they are usually trained and represented using FP16 or BF16 values, with each value occupying 16 bits of memory.
However, during inference, most models can effectively represent weights and activations with lower precision, such as 8-bit or even 4-bit integers (INT8 or INT4).
Quantization is the process of reducing the precision of model weights and activations without sacrificing accuracy. Using lower precision means smaller parameters, and the model occupies less space in GPU memory.

This allows larger models to be inferred using the same hardware, while spending less time on memory operations during execution.
Through the H100 Transformer Engine technology, combined with the H100 GPU of TensorRT-LLM, users can easily convert model weights to the new FP8 format and automatically compile the model to utilize the optimized FP8 kernel.
And this process doesn't require any code! The introduction of the FP8 data format in H100 allows developers to quantize their models and significantly reduce memory consumption without sacrificing model accuracy.
Compared to other data formats such as INT8 or INT4, FP8 quantization retains higher precision while achieving the fastest performance and is the most convenient to implement.
How to Get TensorRT-LLM TensorRT-LLM has not been officially released yet, but users can now apply for early access.
The application link is as follows:
https://developer.nvidia.com/tensorrt-llm-early-access/join
Nvidia also mentioned that they will soon integrate TensorRT-LLM into the NVIDIA NeMo framework.
This framework is part of Nvidia's recently launched AI Enterprise, providing enterprise customers with a secure, stable, and highly manageable enterprise AI software platform.
Developers and researchers can access TensorRT-LLM through the NeMo framework on Nvidia's NGC or the project on GitHub.
However, it is important to note that users must register for the Nvidia Developer Program to apply for the early access version.
Netizens' Hot Discussion On Reddit, netizens have engaged in intense discussions about the release of TensorRT-LLM.
It's hard to imagine how much improvement there will be after optimizing hardware specifically for LLM.

However, some netizens believe that the significance of this thing is to help Nvidia sell more H100.
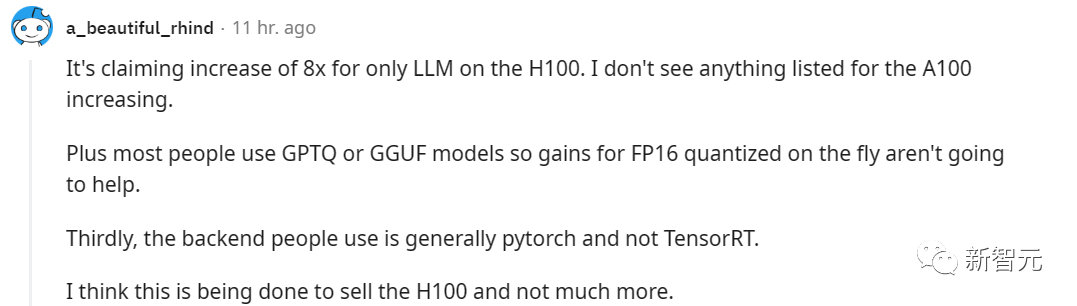
But some netizens also disagree, as they believe that TensorRT is helpful for users deploying SD locally, so as long as there is an RTX GPU, it should be possible to benefit from similar products in the future.

From a more macro perspective, perhaps there will be a series of hardware-level optimizations specifically for LLM, and even in the future, there may be hardware designed specifically for LLM to improve its performance. This situation has already appeared in many popular applications, and LLM will be no exception.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







