Title: Make ChatGPT See Again: This AI Approach Explores Link Context Learning to Enable Multimodal Learning
Source: MarkTechPost

Image Source: Generated by Wujie AI
Language models are able to generate coherent and contextually relevant text, fundamentally changing the way we communicate with computers. Large language models (LLMs) have always been at the forefront of this progress, learning patterns and subtle differences in human language through training on massive amounts of text data. ChatGPT, as a pioneer of the LLM revolution, is extremely popular among professionals in various disciplines.
The superpower of LLMs makes various tasks easier to handle. We use them to summarize text, write emails, automatically complete programming tasks, interpret documents, and more. All of these tasks used to be quite time-consuming a year ago, but can now be completed in just a few minutes.
However, with the growing demand for multimodal understanding, models need to handle and generate content of different modalities such as text, images, and even videos. This has led to a demand for multimodal large language models (MLLMs). MLLMs combine the powerful capabilities of language models with visual understanding, enabling machines to understand and generate content in a more comprehensive and context-aware manner.
After the hype of ChatGPT has subsided, MLLMs have sparked a storm in the field of artificial intelligence, enabling machines to understand and generate content of different modalities such as text and images. These models have performed well in tasks such as image recognition, visual grounding, and instruction understanding. However, effectively training these models remains a challenge. The biggest challenge is that when MLLMs encounter completely unfamiliar scenarios, both the images and labels are unknown.
Furthermore, MLLMs often "get lost" when dealing with longer contexts. These models heavily rely on the beginning and middle positions, which is also the reason why accuracy plateaus with an increase in sample size, leading to a temporary pause or decline in the learning or skill formation process. Therefore, MLLMs struggle when dealing with longer inputs.
Now, let's get to know the Link Context Learning (LCL) that addresses various challenges in MLLMs.

Proposed demonstration of link-context learning; Source: https://arxiv.org/abs/2308.07891
In MLLMs, there are two key training strategies: Multimodal Prompt Tuning (M-PT) and Multimodal Instructional Tuning (M-IT). M-PT fine-tunes only a small portion of the model's parameters while keeping the rest unchanged. This method helps achieve results similar to full fine-tuning while minimizing computational resources. On the other hand, M-IT enhances the zero-shot capability of MLLMs by fine-tuning them on a dataset containing instructional descriptions. This strategy improves the model's ability to understand and handle new tasks without prior training. These methods are effective but come with trade-offs.
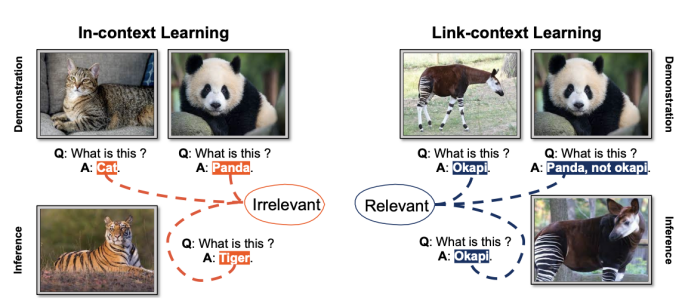
Difference between context learning and link context learning. Source: https://arxiv.org/abs/2308.07891
LCL explores different training strategies: mixed strategy, bidirectional strategy, bidirectional random strategy, and bidirectional weighted strategy. The prominent feature of the mixed strategy is its significant improvement in zero-shot accuracy, achieving impressive results when the sample size reaches 6. However, its performance slightly declines when the sample size is 16. In contrast, the accuracy of the bidirectional strategy gradually increases from 2 samples to 16 samples, indicating its closer alignment with the training pattern.
Unlike traditional context learning, LCL goes further by empowering the model to establish mappings between the source and target, thereby improving its overall performance. By providing demonstrations with causal connections, LCL enables MLLMs to not only recognize analogies but also identify potential causal connections between data points, thus more effectively identifying unseen images and understanding new concepts.
Additionally, LCL introduces the ISEKAI dataset, a novel and comprehensive dataset specifically designed to evaluate the capabilities of MLLMs. The ISEKAI dataset consists of fully generated images and fabricated concepts. It challenges MLLMs to absorb new concepts from ongoing conversations and retain this knowledge to accurately answer questions.
In conclusion, LCL provides valuable insights into the training strategies adopted by multimodal language models. The mixed strategy and bidirectional strategy offer different approaches to improving the performance of multimodal language models, each with its own strengths and limitations. Context analysis reveals the challenges faced by multimodal language models when dealing with longer inputs and emphasizes the importance of further research in this field.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







