Source: Titan Media
Author: San Yan Technology
Yesterday, the author accidentally came across a picture.
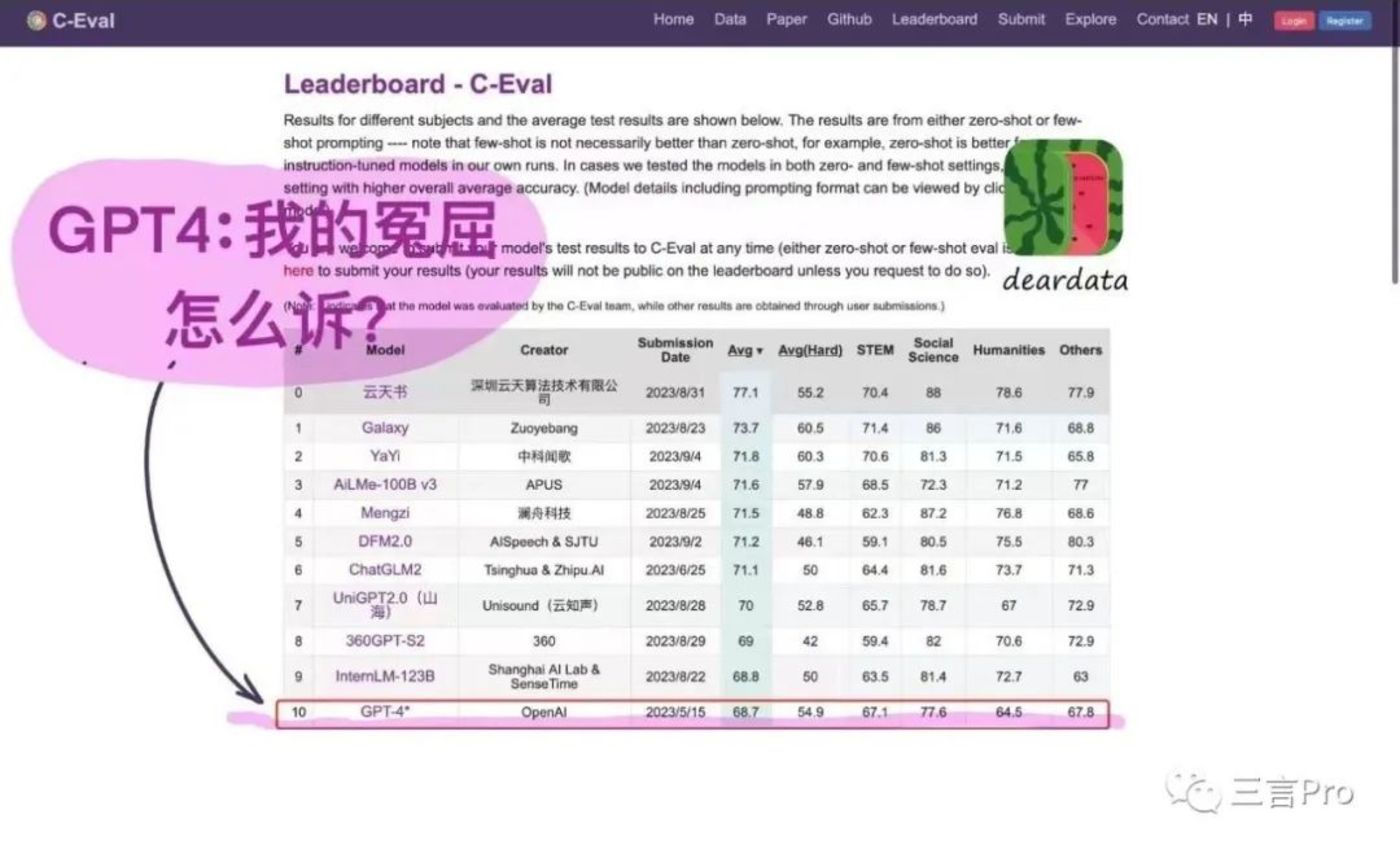
According to the picture, OpenAI's GPT-4 is ranked last among 11 large models (the first place is indexed as 0). Some netizens added the words "GPT4: How can I plead my case?" to the image.
This inevitably makes people curious. After the ChatGPT became popular earlier this year, other companies began to introduce the concept of large models.
In just over half a year, has GPT already "hit rock bottom"?
So, the author wanted to see how GPT was ranked.
Different test times and test teams, GPT-4 ranks eleventh
Based on the information shown in the previous picture, this ranking comes from the C-Eval list.
The C-Eval list, the full name being the C-Eval Global Large Model Comprehensive Examination Test List, is a comprehensive evaluation suite for Chinese language models jointly constructed by Tsinghua University, Shanghai Jiao Tong University, and the University of Edinburgh.
It is reported that this suite covers four major directions: humanities, social sciences, science and engineering, and other professional fields, including 52 disciplines covering multiple knowledge areas such as calculus and linear algebra. It includes 13,948 Chinese knowledge and reasoning questions, with difficulty levels ranging from high school, undergraduate, graduate, to professional exams.
So the author checked the latest C-Eval list.
The latest C-Eval list matches the ranking shown in the previous picture. Among the top eleven large models in the ranking, GPT-4 ranks last.
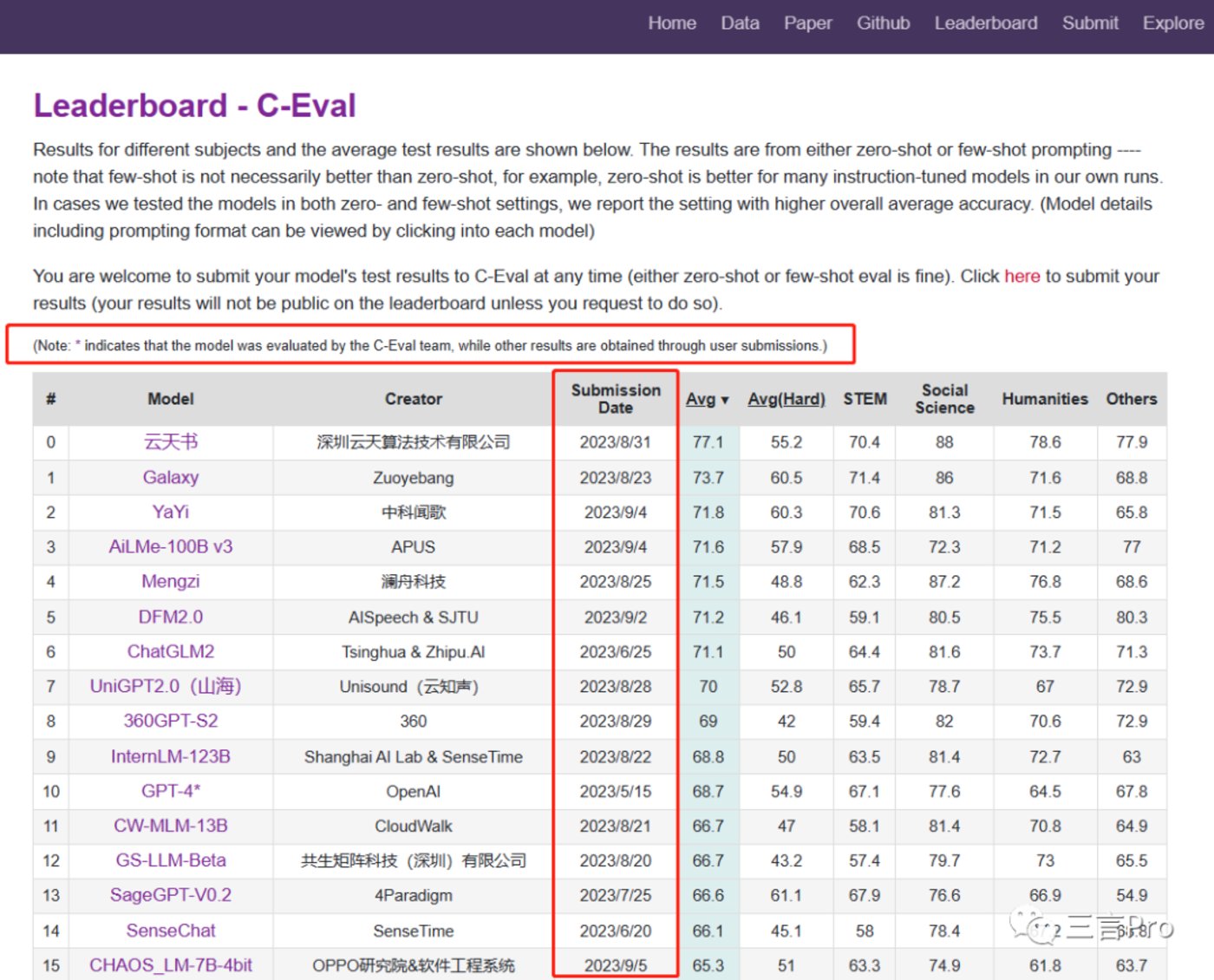
According to the C-Eval list, these results represent zero-shot or few-shot tests, but few-shot does not necessarily perform better than zero-shot.
C-Eval indicates that many models that have been fine-tuned through instructions perform better in zero-shot tests. Many of the models tested in their suite have both zero-shot and few-shot results, and the leaderboard shows the one with the better overall average score.
The C-Eval list also notes that models with an "*" in their names indicate that the results were obtained by the C-Eval team, while other results were obtained through user submissions.
In addition, the author also noticed that there is a significant difference in the time when these large models submitted their test results.
The test result submission time for GPT-4 was May 15, while the top-ranked model, Yuntianshu, submitted its results on August 31; Galaxy, ranked second, submitted its results on August 23; and Yayi, ranked third, submitted its results on September 4.
Moreover, among the top 16 ranked large models, only GPT-4's name has an "*" indicating that it was tested by the C-Eval team.
So the author also checked the complete C-Eval list.
The latest C-Eval list includes rankings for a total of 66 large models.
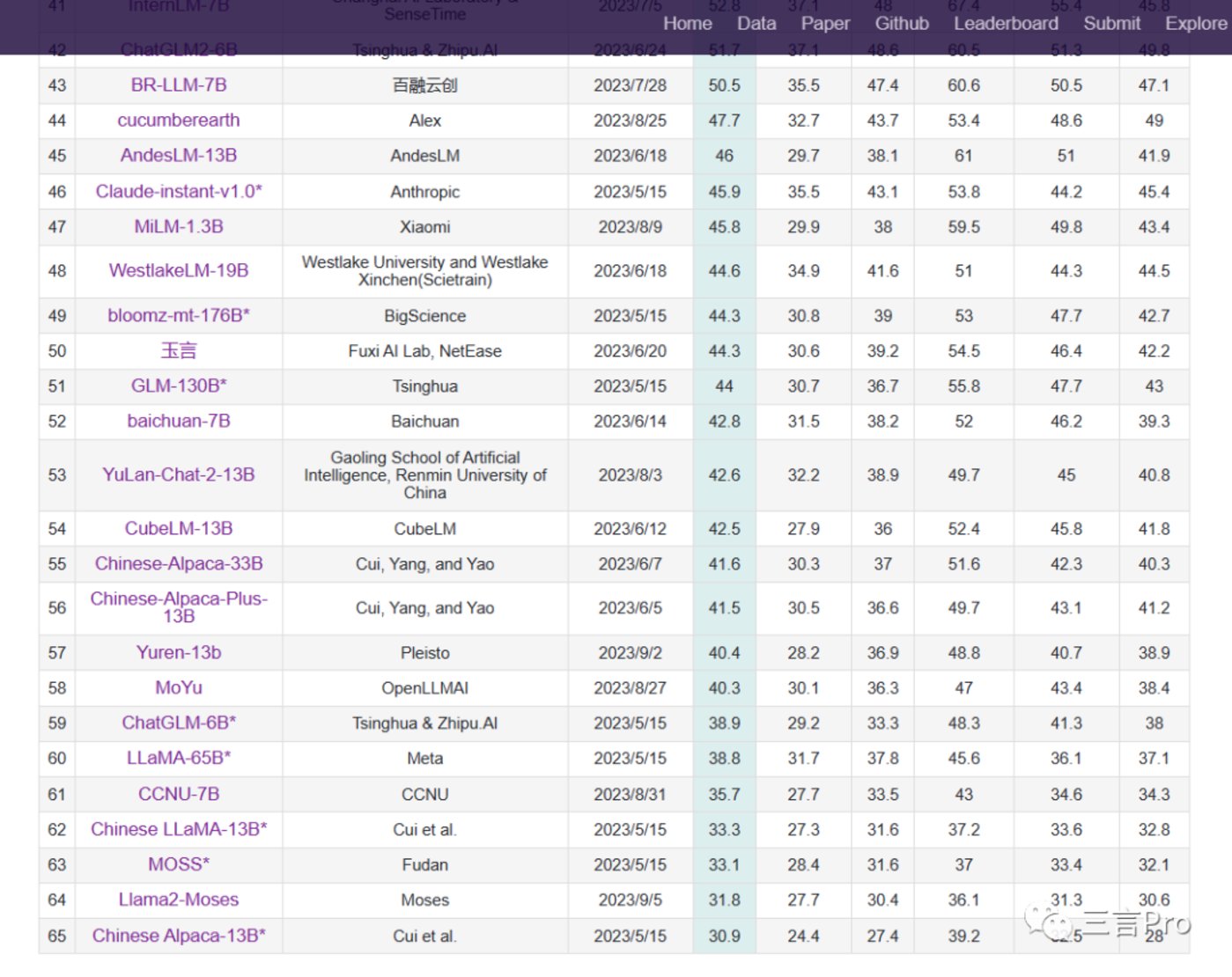
Among them, only 11 were tested by the C-Eval team, as indicated by the "*", and all were submitted for testing on May 15.
Among these large models tested by the C-Eval team, OpenAI's GPT-4 ranks eleventh, ChatGPT ranks thirty-sixth, and Tsinghua Zhilu AI's ChatGLM-6B ranks sixtieth, while Fudan's MOSS ranks sixty-fourth.
Although these rankings reflect the rapid development of large models in China, the author believes that since the tests were not conducted by the same team at the same time, it is not enough to fully prove which of these large models is stronger or weaker.
This is like a class of students, each taking the exam at different times and answering different test papers. How can you compare the scores of each student?
What do large model developers say? Many claim to surpass ChatGPT in Chinese language abilities
Recently, the large model circle has been quite lively.
It is another eight companies, including Baidu and Byte, whose large model products have been filed for record through the "Interim Measures for the Management of Generative Artificial Intelligence Services," and can officially go online to provide services to the public. Other companies have also successively released their own large model products.
So how do these large model developers introduce their own products?
On July 7, at the "Opportunities and Risks for the Development of General Artificial Intelligence in the Era of Large Models" forum at the 2023 World Artificial Intelligence Conference, Qiu Xipeng, a professor at the School of Computer Science and Technology at Fudan University and the person in charge of the MOSS system, said that since the release of the MOSS large-scale conversational language model in February this year, Fudan has been continuously iterating. "The latest MOSS has surpassed ChatGPT in Chinese language abilities."
At the end of July, NetEase Youdao launched a translation large model, and NetEase Youdao CEO Zhou Feng publicly stated that in internal tests, in the direction of Chinese-English translation, it has surpassed ChatGPT's translation abilities and also exceeded the level of Google Translate.
In late August, at the 2023 Yabuli Forum Summer Summit, Liu Qingfeng, the founder and chairman of iFLYTEK, said in a speech, "The code generation and completion capabilities of iFLYTEK's Xinghuo large model have surpassed ChatGPT, and other capabilities are rapidly catching up. The logic, algorithms, method systems, and data preparation for the code capabilities are ready, and all that is needed is time and computing power."
In a recent press release, SenseTime stated that in August this year, the new model internlm-123b completed training, increasing its parameter count to 123 billion. On a total of 51 well-known evaluation sets worldwide, with a total of 300,000 questions, the overall test score ranks second globally, surpassing models such as gpt-3.5-turbo and the newly released llama2-70b by Meta.
According to SenseTime, internlm-123 ranks first in 12 major evaluations. In the comprehensive exam evaluation set, the agieval score is 57.8, surpassing GPT-4 to rank first; the commonsenseqa evaluation score is 88.5, ranking first; internlm-123b ranks first in all five reading comprehension evaluations.
In addition, it ranks first in five reasoning evaluations.
Earlier this month, Zuo Ye Bang officially released its self-developed Galaxy large model.
Zuo Ye Bang stated that the Galaxy large model achieved top scores in the C-Eval and CMMLU two major authoritative large language model evaluation benchmarks. The data shows that the Zuo Ye Bang Galaxy large model ranks first with an average score of 73.7 on the C-Eval list; and at the same time, it ranks first in the CMMLU list for Five-Shot and Zero-Shot evaluations with average scores of 74.03 and 73.85, becoming the first educational large model to rank first in both of these two major authoritative lists.
Yesterday, Baichuan Intelligence announced the official open source of the fine-tuned Baichuan 2-7B, Baichuan 2-13B, Baichuan 2-13B-Chat, and their 4-bit quantized versions.
Wang Xiaochuan, founder and CEO of Baichuan Intelligence, stated that the fine-tuned Chat model, in the Chinese domain, in the Q&A environment, or in the summary environment, has already demonstrated performance surpassing closed-source models such as ChatGPT-3.5.
Today, at the 2023 Tencent Global Digital Ecology Conference, Tencent officially released the Hunyuan large model. Jiang Jie, vice president of Tencent Group, stated that the Chinese language capabilities of Tencent's Hunyuan large model have surpassed GPT-3.5.
In addition to these developers' self-introductions, some media and teams have also evaluated certain large models.
In early August, Shen Yang, a professor at the School of Journalism and Communication at Tsinghua University, and his team released a "Comprehensive Performance Evaluation Report of Large Language Models." The report shows that Baidu Wenxin Yiyi leads domestically in 20 indicators across three dimensions, outperforming ChatGPT, with a strong ranking in Chinese semantic understanding and some Chinese abilities superior to GPT-4.
In mid-August, it was reported that on August 11, Xiaomi's large model MiLM-6B appeared on the C-Eval and CMMLU large model evaluation lists. As of now, MiLM-6B ranks 10th on the overall C-Eval list and 1st in the same parameter level, and ranks 1st in the CMMLU Chinese large model list.
On August 12, Tianjin University released a "Large Model Evaluation Report." The report shows that compared to other models, GPT-4 and Baidu Wenxin Yiyi are significantly ahead in comprehensive performance, with little difference between the two, at the same level. Wenxin Yiyi has already surpassed ChatGPT in most Chinese tasks and is gradually narrowing the gap with GPT-4.
In late August, it was reported that Kwai's self-developed large language model "Kwaiyi" (KwaiYii) has entered the internal testing phase. In the latest CMMLU Chinese ranking, the 13B version of KwaiYii-13B ranks first in both the five-shot and zero-shot categories, with a score of over 61 in humanities and Chinese-specific topics.
From the above content, it can be seen that although these large models claim to be at the top in certain rankings or to surpass ChatGPT in certain aspects, most of them excel in specific fields.
In addition, some models have overall scores that surpass GPT-3.5 or GPT-4, but GPT's testing was conducted in May. Who can guarantee that GPT has not made progress in the past three months?
OpenAI's predicament
According to a report by UBS Group in February, just two months after the launch of ChatGPT, its monthly active users had exceeded 100 million by the end of January 2023, making it the fastest-growing consumer application in history.
But the development of ChatGPT has not been smooth sailing.
In July of this year, many GPT-4 users complained that its performance had declined compared to its previous reasoning abilities.
Some users pointed out issues on Twitter and the OpenAI online developer forum, focusing on weakened logic, more incorrect answers, inability to track provided information, difficulty in following instructions, forgetting to add parentheses in basic software code, and only remembering the most recent prompts, and so on.
In August, there was another report stating that OpenAI may be facing a potential financial crisis and could go bankrupt by the end of 2024.
The report indicated that OpenAI is spending about $700,000 per day to operate its artificial intelligence service ChatGPT. Currently, the company is attempting to achieve profitability through GPT-3.5 and GPT-4, but has not yet generated enough revenue to achieve a balance between income and expenses.
However, OpenAI may also have a new opportunity.
Recently, OpenAI announced that it will hold its first developer conference in November.
Although OpenAI has stated that it will not release GPT-5, the company claims that hundreds of developers from around the world will have an early look at "new tools" and exchange ideas with the OpenAI team.
This may indicate that ChatGPT has made new progress.
According to reports from The Paper, on August 30, an insider revealed that OpenAI is expected to generate over $1 billion in revenue in the next 12 months by selling AI software and the computing power needed to run it.
Today, there are reports that later this month, Morgan Stanley will launch a generative artificial intelligence chatbot developed in collaboration with OpenAI.
People who deal with Morgan Stanley's bankers are either wealthy or influential. If this upcoming generative artificial intelligence chatbot can provide a different experience for Morgan Stanley's clients, it could be a huge gain for OpenAI.
The arrival of the era of artificial intelligence is unstoppable. As for who ultimately has the upper hand, it cannot be determined solely by self-claims; it will depend on user ratings. We also believe that domestic large models will definitely surpass ChatGPT in specific capabilities and overall capabilities.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







